از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
این راهنما قسمت دوم از سه راهنما در مورد ماشین های بردار پشتیبانی (SVM) است. در این راهنما، ما به کار خود ادامه خواهیم داد روی اسکناسهای جعلی از حروف استفاده میکنند، بدانید چه پارامترهای SVM در حال حاضر توسط Scikit-Learn تنظیم شدهاند، فراپارامترهای C و Gamma چیست و چگونه آنها را با استفاده از اعتبارسنجی متقاطع و جستجوی شبکه تنظیم کنید.
در سری کامل راهنمای SVM، علاوه بر فراپارامترهای SVM، با SVM ساده، مفهومی به نام ترفند هستهو انواع دیگر SVM ها را بررسی کنید.
اگر میخواهید همه راهنماها را بخوانید، به اولین راهنما نگاهی بیندازید، یا ببینید کدام یک بیشتر به شما علاقه دارند، جدول موضوعات زیر در هر راهنما آمده است:
- پیاده سازی SVM و Kernel SVM با Scikit-Learn پایتون
- مورد استفاده: اسکناس را فراموش کنید
- پس زمینه SVM ها
- مدل SVM ساده (خطی).
- درباره مجموعه داده
- وارد کردن مجموعه داده
- کاوش مجموعه داده
- پیاده سازی SVM با Scikit-Learn
- تقسیم داده ها به مجموعه های قطار/آزمون
- آموزش مدل
- پیشگویی
- ارزیابی مدل
- تفسیر نتایج
2. درک فراپارامترهای SVM
- فراپارامتر C
- فراپارامتر گاما
- پیاده سازی دیگر طعم های SVM با Scikit-Learn پایتون
- ایده کلی SVM ها (یک خلاصه)
- هسته (ترفند) SVM
- پیاده سازی SVM هسته غیر خطی با Scikit-Learn
- واردات کتابخانه ها
- وارد کردن مجموعه داده
- تقسیم داده ها به ویژگی های (X) و هدف (y)
- تقسیم داده ها به مجموعه های قطار/آزمون
- آموزش الگوریتم
- هسته چند جمله ای
- پیشگویی
- ارزیابی الگوریتم
- هسته گاوسی
- پیش بینی و ارزیابی
- هسته سیگموئید
- پیش بینی و ارزیابی
- مقایسه عملکردهای غیر خطی هسته
بیایید یاد بگیریم که چگونه اعتبار متقاطع را پیاده سازی کنیم و یک تنظیم هایپرپارامتر انجام دهیم.
فراپارامترهای SVM
برای مشاهده تمام پارامترهای مدل که قبلاً توسط Scikit-Learn تنظیم شده اند و مقادیر پیش فرض آن، می توانیم از get_params() روش:
svc.get_params()
این روش نمایش می دهد:
{'C': 1.0,
'break_ties': False,
'cache_size': 200,
'class_weight': None,
'coef0': 0.0,
'decision_function_shape': 'ovr',
'degree': 3,
'gamma': 'scale',
'kernel': 'linear',
'max_iter': -1,
'probability': False,
'random_state': None,
'shrinking': True,
'tol': 0.001,
'verbose': False}
توجه داشته باشید که در مجموع 15 فراپارامتر در حال حاضر تنظیم شده است، این اتفاق می افتد زیرا الگوریتم SVM دارای تغییرات زیادی است. ما از هسته خطی برای به دست آوردن یک تابع خطی استفاده کردهایم، اما هستههایی نیز وجود دارند که انواع دیگر توابع را توصیف میکنند و آن هستهها به روشهای مختلفی پارامتری میشوند.
این تغییرات اتفاق می افتد که مدل را انعطاف پذیرتر و برای یافتن جدایی بین اشکال مختلف داده ها مناسب تر می کند. اگر بتوانیم برای جدا کردن کلاسهایمان خطی بکشیم، الف هسته خطی گزینه خوبی خواهد بود، اگر به منحنی نیاز داشته باشیم، a چند جمله ای هسته ممکن است بهترین انتخاب باشد، اگر داده های ما اشکال دایره ای داشته باشند، a تابع پایه شعاعی یا RBF اگر مقادیر بالاتر و پایین تر از یک آستانه وجود داشته باشد، هسته بهتر با داده ها مطابقت دارد سیگموئید هسته ممکن است کلاس ها را بهتر از هم جدا کند. با توجه به آنچه که در دادههای خود بررسی کردهایم، به نظر میرسد که یک هسته RBF یا یک هسته چند جملهای مناسبتر از یک هسته خطی است.
اکنون که ما این ایده را داریم که 4 نوع عملکرد هسته مختلف وجود دارد، می توانیم به پارامترها برگردیم. هنگامی که الگوریتم SVM سعی می کند جدایی بین کلاس ها پیدا کند، قبلاً فهمیده ایم که یک طبقه بندی ترسیم می کند. لبه بین بردارهای پشتیبانی و خط جدایی (یا منحنی).
این حاشیه به تعبیری مانند بافری بین خط جدایی و نقاط است. اندازه حاشیه می تواند متفاوت باشد، زمانی که حاشیه باشد کوچکتر، فضای کمتری برای نقاطی که خارج از حاشیه قرار می گیرند وجود دارد و باعث می شود که جدایی بین کلاس ها واضح تر شود، بنابراین نمونه های بیشتری در حال تهیه است. به درستی طبقه بندی شده است، برعکس، زمانی که حاشیه است بزرگتر، تفکیک بین کلاس ها کمتر واضح است و نمونه های بیشتری می تواند باشد اشتباه طبقه بندی شده. به عبارت دیگر، حاشیه کوچکتر به معنای نمونه های طبقه بندی صحیح تر و همچنین بیشتر است سفت و سخت طبقهبندیکننده، در حالی که حاشیه بزرگتری دارد، نشاندهنده نمونههای اشتباه طبقهبندیشده بیشتر، اما بیشتر است قابل انعطاف طبقه بندی.
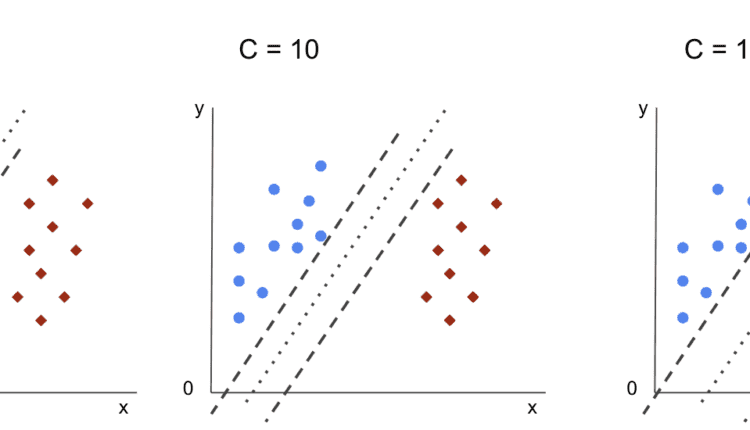
هنگامی که آن حاشیه ها انتخاب می شوند، پارامتری که آنها را تعیین می کند همان است C پارامتر.
فراپارامتر C
این C پارامتر با اندازه حاشیه نسبت معکوس دارد، به این معنی که بزرگتر ارزش C، کوچکتر حاشیه، و برعکس، کوچکتر ارزش C، بزرگتر حاشیه این C پارامتر را می توان همراه با هر هسته استفاده کرد، به الگوریتم می گوید که چقدر از طبقه بندی نادرست هر نمونه آموزشی جلوگیری کند، به همین دلیل به آن نیز معروف است. منظم سازی. SVM هسته خطی ما از a استفاده کرده است C از 1.0، که یک است بزرگ ارزش و الف می دهد حاشیه کوچکتر.

ما می توانیم با a آزمایش کنیم کوچکتر مقدار ‘C’ و در عمل درک کنید که با a چه اتفاقی می افتد حاشیه بزرگتر. برای انجام این کار، یک طبقهبندیکننده جدید ایجاد میکنیم، svc_cو فقط مقدار آن را تغییر دهید C به 0.0001. بیایید آن را نیز تکرار کنیم fit و predict مراحل:
svc_c = SVC(kernel='linear', C=0.0001)
svc_c.fit(X_train, y_train)
y_pred_c = svc_c.predict(X_test)
اکنون می توانیم به نتایج داده های آزمایش نگاه کنیم:
print(classification_report(y_test, y_pred_c))
cm_c = confusion_matrix(y_test, y_pred_c)
sns.heatmap(cm_c, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with C=0.0001')
این خروجی:
precision recall f1-score support
0 0.82 0.96 0.88 148
1 0.94 0.76 0.84 127
accuracy 0.87 275
macro avg 0.88 0.86 0.86 275
weighted avg 0.88 0.87 0.86 275

با استفاده از کوچکتر C و با به دست آوردن حاشیه بزرگتر، طبقه بندی کننده انعطاف پذیرتر و با اشتباهات طبقه بندی بیشتر شده است. در گزارش طبقه بندی، می بینیم که f1-score، قبلاً 0.99 برای هر دو کلاس، به 0.88 برای کلاس 0 و به 0.84 برای کلاس 1 کاهش یافته است. در ماتریس سردرگمی، مدل از 2 به 6 مثبت کاذب و از 2 به 31 منفی کاذب رسید.
ما همچنین می توانیم تکرار کنیم predict گام بردارید و به نتایج نگاه کنید تا بررسی کنید که آیا هنگام استفاده از داده های قطار هنوز اضافه فیت وجود دارد یا خیر:
y_pred_ct = svc_c.predict(X_train)
cm_ct = confusion_matrix(y_train, y_pred_ct)
sns.heatmap(cm_ct, annot=True, fmt='d').set_title('Confusion matrix of linear SVM with C=0.0001 and train data')
print(classification_report(y_train, y_pred_ct))
این منجر به:
precision recall f1-score support
0 0.88 0.96 0.92 614
1 0.94 0.84 0.88 483
accuracy 0.90 1097
macro avg 0.91 0.90 0.90 1097
weighted avg 0.91 0.90 0.90 1097

با نگاه کردن به نتایج با کوچکتر C و دادههای قطار، میتوانیم ببینیم که بهبودی در اضافهفیت وجود داشته است، اما هنگامی که بیشتر معیارها برای دادههای قطار هنوز بالاتر هستند، به نظر میرسد که اضافه برازش حل نشده است. بنابراین، فقط تغییر دادن C پارامتر برای انعطافپذیری بیشتر مدل و بهبود تعمیم آن کافی نبود.
توجه داشته باشید: تلاش برای یافتن تعادل بین عملکرد بسیار دور از داده، ثابت بودن یا داشتن تعصب بالا یا برعکس، تابعی که به داده ها نزدیک می شود، بیش از حد انعطاف پذیر است یا داشتن واریانس بالا معمولاً به عنوان مبادله واریانس سوگیری. یافتن این توازن بی اهمیت نیست، اما زمانی که به دست می آید، مدل به داده ها تناسب چندانی ندارد. به عنوان راهی برای کاهش واریانس و جلوگیری از برازش بیش از حد، داده ها را می توان به طور یکنواخت کوچک کرد تا هنگام بدست آوردن تابعی که آن را توصیف می کند، منظم تر و ساده تر شود. این همان پارامتر است C زمانی که در SVM استفاده می شود انجام می دهد، به همین دلیل نیز نامیده می شود تنظیم L2 یا رگرسیون ریج.
تا اینجا، ما در مورد حاشیهها در SVM و اینکه چگونه بر نتیجه کلی الگوریتم تأثیر میگذارند، فهمیدهایم، اما خط (یا منحنی) که کلاسها را از هم جدا میکند چطور؟ این خط است مرز تصمیم گیری. بنابراین، ما از قبل میدانیم که حاشیهها تأثیر دارند روی انعطاف پذیری مرز تصمیم در برابر اشتباهات، اکنون می توانیم به پارامتر دیگری که بر مرز تصمیم نیز تأثیر می گذارد نگاهی بیندازیم.
توجه داشته باشید: مرز تصمیم را می توان a نیز نامید ابر هواپیما. ابر صفحه یک مفهوم هندسی برای اشاره به تعداد ابعاد یک فضا منهای یک (dims-1) است. اگر فضا دو بعدی باشد، مانند صفحه ای با مختصات x و y، خطوط یک بعدی (یا منحنی ها) ابرصفحه ها هستند. در زمینه یادگیری ماشین، از آنجایی که تعداد ستونهای مورد استفاده در مدل، ابعاد صفحه آن است، وقتی با 4 ستون و یک طبقهبندی کننده SVM کار میکنیم، یک ابر صفحه سه بعدی را پیدا میکنیم که بین کلاسها جدا میشود.
فراپارامتر گاما
مرزهای تصمیم بی نهایت را می توان انتخاب کرد، برخی از آن مرزها کلاس ها را از هم جدا می کنند و برخی دیگر نمی توانند. هنگام انتخاب یک مرز تصمیم گیری موثر، آیا باید 10 نزدیکترین نقطه اول هر کلاس در نظر گرفته شود؟ یا باید نکات بیشتری از جمله نقاط دور را در نظر گرفت؟ در SVM، این انتخاب محدوده توسط ابرپارامتر دیگری تعریف میشود. gamma.
پسندیدن C، gamma تا حدودی با فاصله آن نسبت معکوس دارد. این بالاتر ارزش آن، نزدیک ترین نقاطی هستند که برای مرز تصمیم در نظر گرفته می شوند و پایین ترین را gamma، دورتر برای انتخاب مرز تصمیم گیری نیز امتیاز در نظر گرفته می شود.

تأثیر دیگر گاما این است که هر چه مقدار آن بیشتر باشد، دامنه مرز تصمیم به نقاط اطراف آن نزدیکتر میشود و آن را ناهموارتر و مستعد بیشبرازش میکند – و هر چه مقدار آن کمتر باشد، مرز تصمیم صافتر و منظمتر میشود. سطح، همچنین، کمتر مستعد بیش از حد است. این در مورد هر ابرصفحه ای صادق است، اما هنگام جداسازی داده ها در ابعاد بالاتر، می توان آن را راحت تر مشاهده کرد. در برخی اسناد، gamma را نیز می توان نام برد sigma.

در مورد مدل ما، مقدار پیشفرض از gamma بود scale. همانطور که در مستندات Scikit-Learn SVC، به این معنی است که ارزش آن عبارت است از:
$$
گاما = (1/ \text{n_features} * X.var())
$$
یا
$$
گاما = (1/ \text{number_of_features} * \text{features_variance})
$$
در مورد ما، باید واریانس را محاسبه کنیم X_train، آن را در 4 ضرب کنید و نتیجه را بر 1 تقسیم کنید. با کد زیر می توانیم این کار را انجام دهیم:
number_of_features = X_train.shape(1)
features_variance = X_train.values.var()
gamma = 1/(number_of_features * features_variance)
print('gamma:', gamma)
این خروجی:
gamma: 0.013924748072859962
همچنین راه دیگری برای بررسی ارزش وجود دارد gamma، با دسترسی به شی طبقه بندی کننده gamma پارامتر با ._gamma:
svc._gamma
ما می توانیم ببینیم که gamma در طبقه بندی کننده ما کم بود، بنابراین نقاط دورتر را نیز در نظر گرفت.
توجه داشته باشید: همانطور که دیده ایم، C و gamma برای برخی از تعاریف مدل مهم هستند. هایپرپارامتر دیگر، random_state، اغلب در Scikit-Learn برای تضمین درهم ریختن داده ها یا یک دانه تصادفی برای مدل ها استفاده می شود، بنابراین ما همیشه نتایج یکسانی داریم، اما این برای SVM کمی متفاوت است. به ویژه، random_state فقط در صورتی پیامدهایی دارد که هایپرپارامتر دیگری، probability، روی true تنظیم شده است. این به این دلیل است که داده ها را برای به دست آوردن تخمین های احتمال به هم می زند. اگر تخمین های احتمال را برای کلاس های خود نمی خواهیم و احتمال روی نادرست تنظیم می شود، SVM’s random_state پارامتر هیچ مفهومی ندارد روی نتایج مدل
هیچ قاعده ای وجود ندارد روی روش انتخاب مقادیر برای هایپرپارامترها، مانند C و گاما – بستگی دارد روی چه مدت و چه منابعی برای آزمایش مقادیر مختلف فراپارامتر در دسترس است، چه تغییراتی را می توان در داده ها ایجاد کرد، و چه نتایجی مورد انتظار است. روش معمول برای جستجوی مقادیر فراپارامتر، ترکیب هر یک از مقادیر پیشنهادی از طریق یک جستجوی شبکه ای همراه با رویهای که آن مقادیر فراپارامتر را اعمال میکند و معیارهایی را برای بخشهای مختلف دادههای نامیده میشود اعتبار سنجی متقابل. در Scikit-Learn، این در حال حاضر به عنوان اجرا شده است GridSearchCV روش (CV از اعتبار متقاطع).
برای اجرای یک جستجوی شبکه ای با اعتبارسنجی متقاطع، باید این کار را انجام دهیم import را GridSearchCV، دیکشنری را با مقادیر فراپارامترهایی که با آنها آزمایش می شود، تعریف کنید، مانند نوع kernel، محدوده برای C، و برای gamma، یک نمونه از SVC، تعریف کنید score یا متریک برای ارزیابی استفاده خواهد شد (در اینجا ما برای دقت و یادآوری بهینه سازی را انتخاب می کنیم، بنابراین از f1-score)، تعداد تقسیمبندیهایی که در دادهها برای اجرای جستجو در آن انجام میشود cv – پیشفرض 5 است، اما استفاده از حداقل 10 تمرین خوبی است – در اینجا، از 5 چین داده استفاده میکنیم تا هنگام مقایسه نتایج واضحتر شود.
این GridSearchCV دارد fit روشی که دادههای قطار ما را دریافت میکند و آن را در مجموعههای قطار و آزمایش برای اعتبارسنجی متقاطع تقسیم میکند. می توانیم تنظیم کنیم return_train_score درست است تا نتایج را با هم مقایسه کنید و تضمین کنید که بیش از حد مناسب نیست.
این کد برای جستجوی شبکه با اعتبارسنجی متقاطع است:
from sklearn.model_selection import GridSearchCV
parameters_dictionary = {'kernel':('linear', 'rbf'),
'C':(0.0001, 1, 10),
'gamma':(1, 10, 100)}
svc = SVC()
grid_search = GridSearchCV(svc,
parameters_dictionary,
scoring = 'f1',
return_train_score=True,
cv = 5,
verbose = 1)
grid_search.fit(X_train, y_train)
خروجی این کد:
Fitting 5 folds for each of 18 candidates, totalling 90 fits
# and a clickable GridSeachCV object schema
پس از انجام جستجوی هایپرپارامتر، می توانیم از best_estimator_، best_params_ و best_score_ خواص برای به دست آوردن بهترین مدل، مقادیر پارامتر و بالاترین امتیاز f1:
best_model = grid_search.best_estimator_
best_parameters = grid_search.best_params_
best_f1 = grid_search.best_score_
print('The best model was:', best_model)
print('The best parameter values were:', best_parameters)
print('The best f1-score was:', best_f1)
این منجر به:
The best model was: SVC(C=1, gamma=1)
The best parameter values were: {'C': 1, 'gamma': 1, 'kernel': 'rbf'}
The best f1-score was: 0.9979166666666666
با تایید حدس اولیه ما از نگاه کردن به داده ها، بهترین مدل دارای هسته خطی نیست، بلکه دارای هسته غیرخطی، RBF است.
هر دو C و gamma دارای مقدار 1 و the f1-score بسیار بالا است، 0.99. از آنجایی که مقدار زیاد است، بیایید با نگاه کردن به میانگین آزمون و نمرات قطاری که برگرداندهایم، ببینیم که آیا بیش از حد تناسب وجود دارد یا خیر. cv_results_ هدف – شی:
gs_mean_test_scores = grid_search.cv_results_('mean_test_score')
gs_mean_train_scores = grid_search.cv_results_('mean_train_score')
print("The mean test f1-scores were:", gs_mean_test_scores)
print("The mean train f1-scores were:", gs_mean_train_scores)
میانگین نمرات عبارت بودند از:
The mean test f1-scores were:
(0.78017291 0. 0.78017291 0. 0.78017291 0.
0.98865407 0.99791667 0.98865407 0.76553515 0.98865407 0.040291
0.98656 0.99791667 0.98656 0.79182565 0.98656 0.09443985)
The mean train f1-scores were:
(0.78443424 0. 0.78443424 0. 0.78443424 0.
0.98762683 1. 0.98762683 1. 0.98762683 1.
0.98942923 1. 0.98942923 1. 0.98942923 1. )
با نگاه کردن به میانگین نمرات، میتوانیم ببینیم که بالاترین آن یعنی 0.99791667 دو بار ظاهر میشود و در هر دو مورد، امتیاز در دادههای قطار 1 بود. این نشاندهنده تداوم اضافه تناسب است. از اینجا، جالب است که به آماده سازی داده ها برگردیم و بفهمیم که آیا عادی سازی داده ها، ایجاد نوع دیگری از تبدیل داده ها، و همچنین ایجاد ویژگی های جدید با مهندسی ویژگی ها منطقی است یا خیر.
ما به تازگی تکنیکی برای یافتن فراپارامترهای مدل دیدهایم و قبلاً چیزی در مورد تفکیکپذیری خطی، بردارهای پشتیبانی، مرز تصمیمگیری، حداکثر کردن حاشیهها و ترفند هسته ذکر کردهایم. SVM یک الگوریتم پیچیده است که معمولاً مفاهیم ریاضی زیادی در آن دخیل است و بخشهای کوچک قابل تنظیمی دارد که باید تنظیم شوند تا در یک کل جمع شوند.
بیایید آنچه را که تا به حال دیدهایم ترکیب کنیم، خلاصهای بسازیم روی چگونه همه بخش های SVM کار می کنند، و سپس به برخی از دیگر پیاده سازی های هسته همراه با نتایج آنها نگاهی بیندازید.
نتیجه
در این مقاله، پارامترهای پیشفرض پشت اجرای SVM Scikit-Learn را فهمیدیم. ما فهمیدیم که پارامترهای C و Gamma چیست و چگونه تغییر هر یک از آنها می تواند بر مدل SVM تأثیر بگذارد.
ما همچنین درباره جستجوی شبکه ای یاد گرفتیم تا بهترین مقادیر C و Gamma را جستجو کنیم و از اعتبار سنجی متقاطع برای تعمیم بهتر نتایج و تضمین عدم وجود نوعی نشت داده استفاده کنیم.
انجام یک تنظیم هایپرپارامتر با جستجوی شبکه و اعتبار سنجی متقاطع یک روش رایج در علم داده است، بنابراین من قویاً پیشنهاد می کنم تکنیک ها را پیاده سازی کنید، کد را اجرا کنید و پیوندهای بین مقادیر هایپرپارامتر و تغییرات پیش بینی های SVM را مشاهده کنید.
اگر میخواهید به یادگیری در مورد SVM ادامه دهید، میتوانید به بخش سوم و پایانی این مجموعه بروید، در مورد پیادهسازی سایر طعمهای SVM با Scikit-Learn پایتون.
(برچسبها به ترجمه)# python
منتشر شده در 1402-12-31 23:23:03
