از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
پایتون چیست؟ zlib
پایتون zlib کتابخانه یک رابط پایتون را برای zlib کتابخانه C، که یک انتزاع سطح بالاتر برای باد کردن الگوریتم فشرده سازی بدون تلفات قالب داده مورد استفاده توسط کتابخانه در RFC 1950 تا 1952 مشخص شده است که در آدرس موجود است. http://www.ietf.org/rfc/rfc1950.txt.
این zlib فرمت فشرده سازی برای استفاده رایگان است و تحت هیچ حق ثبت اختراعی قرار نمی گیرد، بنابراین می توانید با خیال راحت از آن در محصولات تجاری نیز استفاده کنید. این یک فرمت فشردهسازی بدون تلفات است (به این معنی که هیچ دادهای را بین فشردهسازی و رفع فشردهسازی از دست نمیدهید)، و از مزیت قابل حمل بودن در پلتفرمهای مختلف برخوردار است. یکی دیگر از مزایای مهم این مکانیسم فشرده سازی این است که داده ها را گسترش نمی دهد.
استفاده اصلی از zlib کتابخانه در برنامههایی است که نیاز به فشردهسازی و رفع فشردهسازی دادههای دلخواه دارند، خواه یک رشته، محتوای ساختار یافته در حافظه یا فایلها باشد.
از مهم ترین قابلیت های موجود در این کتابخانه می توان به فشرده سازی و رفع فشار اشاره کرد. فشردهسازی و رفع فشردهسازی هر دو میتوانند بهعنوان یک عملیات یکباره یا با تقسیم دادهها به تکههایی مانند آنچه که از یک جریان داده دیدهاید، انجام شوند. هر دو حالت کار در این مقاله توضیح داده شده است.
یکی از بهترین چیزها، به نظر من، در مورد zlib کتابخانه این است که با آن سازگار است gzip فرمت فایل/ابزار (که همچنین بر اساس روی DEFLATE) که یکی از پرکاربردترین برنامه های فشرده سازی است روی سیستم های یونیکس
فشرده سازی
فشرده سازی رشته ای از داده ها
این zlib کتابخانه در اختیار ما قرار می دهد compress تابع، که می تواند برای فشرده سازی رشته ای از داده ها استفاده شود. سینتکس این تابع بسیار ساده است و تنها دو آرگومان دارد:
compress(data, level=-1)
اینجا بحث data حاوی بایت هایی است که باید فشرده شوند و level یک مقدار صحیح است که می تواند مقادیر -1 یا 0 تا 9 را بگیرد. این پارامتر سطح فشرده سازی را تعیین می کند، جایی که سطح 1 سریعترین است و کمترین سطح فشرده سازی را ایجاد می کند. سطح 9 کندترین است، اما بالاترین سطح فشرده سازی را دارد. مقدار -1 نشان دهنده پیش فرض است که سطح 6 است. مقدار پیش فرض تعادلی بین سرعت و فشرده سازی دارد. سطح 0 هیچ فشرده سازی ایجاد نمی کند.
نمونه ای از استفاده از compress روش روی یک رشته ساده در زیر نشان داده شده است:
import zlib
import binascii
data = 'Hello world'
compressed_data = zlib.compress(data, 2)
print('Original data: ' + data)
print('Compressed data: ' + binascii.hexlify(compressed_data))
و نتیجه به شرح زیر است:
$ python compress_str.py
Original data: Hello world
Compressed data: 785ef348cdc9c95728cf2fca49010018ab043d
شکل 1
اگر سطح را به 0 (بدون فشرده سازی) تغییر دهیم، خط 5 تبدیل می شود:
compressed_data = zlib.compress(data, 0)
و نتیجه جدید این است:
$ python compress_str.py
Original data: Hello world
Compressed data: 7801010b00f4ff48656c6c6f20776f726c6418ab043d
شکل 2
ممکن است در مقایسه خروجی ها هنگام استفاده متوجه چند تفاوت شوید 0 یا 2 برای سطح فشرده سازی با استفاده از سطح 2 ما یک رشته (قالب هگزادسیمال) به طول 38 دریافت می کنیم، در حالی که با سطح 0 ما یک رشته شش گوش با طول 44 دریافت می کنیم. این تفاوت در طول به دلیل عدم فشرده سازی در استفاده از سطح است. 0.
اگر رشته را به صورت هگزادسیمال فرمت نکنید، همانطور که در این مثال انجام دادم، و داده های خروجی را مشاهده نکنید، احتمالاً متوجه خواهید شد که رشته ورودی حتی پس از فشرده شدن همچنان قابل خواندن است، اگرچه مقدار کمی اضافی دارد. قالب بندی کاراکترها در اطراف آن
فشرده سازی جریان های داده های بزرگ
جریان های داده های بزرگ را می توان با مدیریت کرد compressobj() تابع، که یک شی فشردهسازی را برمیگرداند. نحو به شرح زیر است:
compressobj(level=-1, method=DEFLATED, wbits=15, memLevel=8, strategy=Z_DEFAULT_STRATEGY(, zdict))
تفاوت اصلی بین آرگومان های این تابع و compress() تابع است (به غیر از data پارامتر) wbits آرگومان، که اندازه پنجره را کنترل می کند، و اینکه آیا هدر و تریلر در خروجی گنجانده شده است یا خیر.
مقادیر ممکن برای wbits هستند:
| ارزش | لگاریتم اندازه پنجره | خروجی |
|---|---|---|
| +9 تا +15 | پایه 2 | شامل هدر و تریلر zlib است |
| -9 تا -15 | مقدار مطلق wbits | بدون سربرگ و تریلر |
| 25+ تا 31+ | 4 بیت از مقدار کم است | شامل هدر gzip و چک جمع انتهایی است |
میز 1
این method آرگومان نشان دهنده الگوریتم فشرده سازی استفاده شده است. در حال حاضر تنها مقدار ممکن است DEFLATED، که تنها روش تعریف شده در RFC 1950 است strategy آرگومان به تنظیم فشرده سازی مربوط می شود. من توصیه می کنم از آن استفاده نکنید و فقط از مقدار پیش فرض استفاده کنید، مگر اینکه واقعاً بدانید دارید چه می کنید.
کد زیر روش استفاده از آن را نشان می دهد compressobj() تابع:
import zlib
import binascii
data = 'Hello world'
compress = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, -15)
compressed_data = compress.compress(data)
compressed_data += compress.flush()
print('Original: ' + data)
print('Compressed data: ' + binascii.hexlify(compressed_data))
پس از اجرای این کد، نتیجه این است:
$ python compress_obj.py
Original: Hello world
Compressed data: f348cdc9c95728cf2fca490100
شکل 3
همانطور که از شکل بالا می بینیم، عبارت Hello world فشرده شده است. معمولاً از این روش برای فشرده سازی جریان های داده ای استفاده می شود که به یکباره در حافظه قرار نمی گیرند. اگرچه این مثال دارای جریان بسیار زیادی از داده ها نیست، اما هدف آن نشان دادن مکانیک compressobj() تابع.
همچنین ممکن است بتوانید ببینید که چگونه در یک برنامه بزرگتر مفید است که در آن می توانید فشرده سازی را پیکربندی کنید و سپس شیء فشرده سازی را به روش ها/ماژول های دیگر منتقل کنید. سپس می توان از آن برای فشرده سازی تکه های داده به صورت سری استفاده کرد.
همچنین ممکن است بتوانید ببینید که چگونه در سناریویی که یک جریان داده برای فشرده سازی دارید مفید است. به جای اینکه مجبور باشید همه داده ها را در حافظه جمع کنید، فقط می توانید تماس بگیرید compress.compress(data) و compress.flush() روی داده های شما را تکه کرده و سپس حرکت دهید روی به قسمت بعدی در حالی که قسمت قبلی را می گذاریم تا با جمع آوری زباله پاک شود.
فشرده سازی یک فایل
ما همچنین می توانیم استفاده کنیم compress() عملکرد فشرده سازی داده ها در یک فایل. نحو مانند مثال اول است.
در مثال زیر یک فایل تصویری PNG به نام را فشرده می کنیم logo.png (که باید توجه داشته باشم که قبلاً یک نسخه فشرده از تصویر خام اصلی است).
کد نمونه به صورت زیر است:
import zlib
original_data = open('logo.png', 'rb').read()
compressed_data = zlib.compress(original_data, zlib.Z_BEST_COMPRESSION)
compress_ratio = (float(len(original_data)) - float(len(compressed_data))) / float(len(original_data))
print('Compressed: %d%%' % (100.0 * compress_ratio))
در کد بالا، zlib.compress(...) خط از ثابت استفاده می کند Z_BEST_COMPRESSION، که همانطور که از نامش پیداست، بهترین سطح فشرده سازی این الگوریتم را به ما می دهد. سپس خط بعدی سطح فشرده سازی را بر اساس محاسبه می کند روی نسبت طول داده های فشرده به طول داده های اصلی.
نتیجه به شرح زیر است:
$ python compress_file.py
Compressed: 13%
شکل 4
همانطور که می بینیم فایل 13 درصد فشرده شده است.
تنها تفاوت این مثال با نمونه اول ما منبع داده است. با این حال، من فکر می کنم مهم است که نشان داده شود تا بتوانید ایده ای در مورد اینکه چه نوع داده هایی را می توان فشرده کرد، چه فقط یک رشته ASCII یا داده های تصویر باینری باشد. به سادگی داده های خود را از فایل مانند معمول بخوانید و با آن تماس بگیرید compress روش.
ذخیره داده های فشرده در یک فایل
همچنین داده های فشرده شده را می توان در یک فایل برای استفاده بعدی ذخیره کرد. مثال زیر روش ذخیره متن فشرده شده در یک فایل را نشان می دهد:
import zlib
my_data = 'Hello world'
compressed_data = zlib.compress(my_data, 2)
f = open('outfile.txt', 'w')
f.write(compressed_data)
f.close()
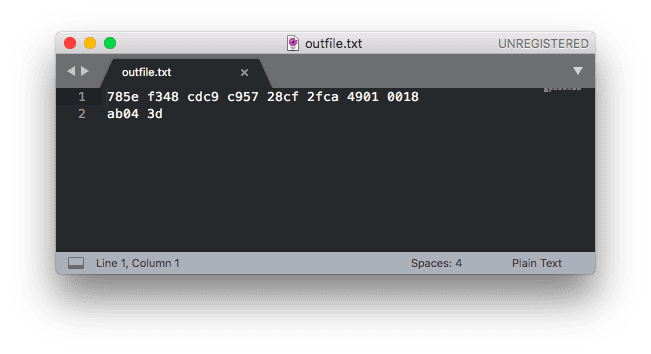
مثال بالا رشته ساده “Hello world” ما را فشرده می کند و داده های فشرده شده را در فایلی به نام ذخیره می کند. outfile.txt. این outfile.txt فایل، زمانی که با ویرایشگر متن ما باز می شود، به صورت زیر است:

شکل 5
رفع فشار
از حالت فشرده خارج کردن رشته ای از داده ها
یک رشته فشرده از داده ها را می توان به راحتی با استفاده از آن از حالت فشرده خارج کرد decompress() تابع. نحو به شرح زیر است:
decompress(data, wbits=MAX_WBITS, bufsize=DEF_BUF_SIZE)
این تابع بایت ها را از حالت فشرده خارج می کند data بحث و جدل. این wbits می توان از آرگومان برای مدیریت اندازه بافر تاریخ استفاده کرد. مقدار پیش فرض با بزرگترین اندازه پنجره مطابقت دارد. همچنین درج هدر و تریلر فایل فشرده را درخواست می کند. مقادیر ممکن عبارتند از:
| ارزش | لگاریتم اندازه پنجره | ورودی |
|---|---|---|
| +8 تا +15 | پایه 2 | شامل هدر و تریلر zlib است |
| -8 تا -15 | مقدار مطلق wbits | جریان خام بدون سرصفحه و تریلر |
| 24+ تا 31+ = 16 + (8 تا 15) | 4 بیت از مقدار کم است | شامل هدر و تریلر gzip است |
| +40 تا +47 = 32 + (8 تا 15) | 4 بیت از مقدار کم است | فرمت zlib یا gzip |
جدول 2
مقدار اولیه اندازه بافر در نشان داده شده است bufsize بحث و جدل. با این حال، جنبه مهم در مورد این پارامتر این است که نیازی به دقیق بودن آن نیست، زیرا در صورت نیاز به اندازه بافر اضافی، به طور خودکار افزایش می یابد.
مثال زیر نشان می دهد که چگونه رشته داده های فشرده شده در مثال قبلی ما را از حالت فشرده خارج کنیم:
import zlib
data = 'Hello world'
compressed_data = zlib.compress(data, 2)
decompressed_data = zlib.decompress(compressed_data)
print('Decompressed data: ' + decompressed_data)
نتیجه به شرح زیر است:
$ python decompress_str.py
Decompressed data: Hello world
شکل 5
فشرده سازی جریان های داده های بزرگ
فشردهسازی جریانهای کلان داده ممکن است به دلیل اندازه یا منبع دادههای شما نیاز به مدیریت حافظه داشته باشد. ممکن است نتوانید از تمام حافظه موجود برای این کار استفاده کنید (یا حافظه کافی ندارید)، بنابراین decompressobj() روش به شما امکان می دهد یک جریان داده را به چند تکه تقسیم کنید که می توانید به طور جداگانه آنها را از حالت فشرده خارج کنید.
نحو از decompressobj() عملکرد به شرح زیر است:
decompressobj(wbits=15(, zdict))
این تابع یک شی رفع فشار را برمیگرداند که از آن برای فشردهسازی دادههای فردی استفاده میکنید. این wbits آرگومان همان ویژگی هایی را دارد که در the decompress() عملکرد قبلا توضیح داده شد
کد زیر نشان می دهد که چگونه یک جریان بزرگ از داده ها را که در یک فایل ذخیره می شود از حالت فشرده خارج کنید. ابتدا برنامه یک فایل با نام ایجاد می کند outfile.txt، که حاوی داده های فشرده است. توجه داشته باشید که داده ها با استفاده از مقدار فشرده شده اند wbits برابر با 15+ این امر ایجاد هدر و تریلر در داده ها را تضمین می کند.
سپس فایل با استفاده از تکه های داده از حالت فشرده خارج می شود. باز هم، در این مثال، فایل حاوی مقدار زیادی داده نیست، اما با این وجود، هدف توضیح مفهوم بافر را دارد.
کد به شرح زیر است:
import zlib
data = 'Hello world'
compress = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, +15)
compressed_data = compress.compress(data)
compressed_data += compress.flush()
print('Original: ' + data)
print('Compressed data: ' + compressed_data)
f = open('compressed.dat', 'w')
f.write(compressed_data)
f.close()
CHUNKSIZE = 1024
data2 = zlib.decompressobj()
my_file = open('compressed.dat', 'rb')
buf = my_file.read(CHUNKSIZE)
while buf:
decompressed_data = data2.decompress(buf)
buf = my_file.read(CHUNKSIZE)
decompressed_data += data2.flush()
print('Decompressed data: ' + decompressed_data)
my_file.close()
پس از اجرای کد بالا، نتایج زیر را بدست می آوریم:
$ python decompress_data.py
Original: Hello world
Compressed data: x??H???W(?/?I?=
Decompressed data: Hello world
شکل 6
فشرده سازی داده ها از یک فایل
همانطور که در مثال های قبلی مشاهده کردید، داده های فشرده موجود در یک فایل را می توان به راحتی از حالت فشرده خارج کرد. این مثال بسیار شبیه به نمونه قبلی است، زیرا ما دادههایی را که از یک فایل منشأ میگیرند از حالت فشرده خارج میکنیم، با این تفاوت که در این مورد به استفاده از یکباره برمیگردیم. decompress متد، که داده ها را در یک فراخوانی متد از حالت فشرده خارج می کند. این برای زمانی مفید است که داده های شما به اندازه کافی کوچک هستند تا به راحتی در حافظه قرار بگیرند.
این را می توان از مثال زیر مشاهده کرد:
import zlib
compressed_data = open('compressed.dat', 'rb').read()
decompressed_data = zlib.decompress(compressed_data)
print(decompressed_data)
برنامه بالا فایل را باز می کند compressed.dat ایجاد شده در مثال قبلی، که شامل رشته فشرده “Hello world” است.
در این مثال، هنگامی که داده های فشرده شده بازیابی و در متغیر ذخیره می شوند compressed_data، برنامه جریان را از حالت فشرده خارج کرده و نتیجه را نشان می دهد روی صفحه نمایش از آنجایی که فایل حاوی مقدار کمی داده است، در مثال از decompress() تابع. با این حال، همانطور که در مثال قبلی نشان میدهد، میتوانیم دادهها را با استفاده از حالت فشرده خارج کنیم decompressobj() تابع.
پس از اجرای برنامه به نتیجه زیر می رسیم:
$ python decompress_file.py
Hello world
شکل 7
بسته بندی
کتابخانه پایتون zlib مجموعه ای مفید از توابع برای فشرده سازی فایل با استفاده از zlib قالب توابع compress() و decompress() به طور معمول استفاده می شوند. با این حال، هنگامی که محدودیت های حافظه وجود دارد، توابع compressobj() و decompressobj() برای ارائه انعطافپذیری بیشتر با پشتیبانی از فشردهسازی/فشردهسازی جریانهای داده در دسترس هستند. این توابع به تقسیم داده ها به تکه های کوچکتر و قابل مدیریت تر کمک می کنند، که می توان آنها را با استفاده از compress() و decompress() به ترتیب توابع
به خاطر داشته باشید که zlib کتابخانه همچنین دارای چند ویژگی بیشتر از آنچه ما در این مقاله توانستیم پوشش دهیم، دارد. به عنوان مثال می توانید استفاده کنید zlib برای محاسبه جمع کنترلی برخی از داده ها برای تأیید صحت آن در هنگام فشرده سازی. برای اطلاعات بیشتر روی ویژگی های اضافی مانند این، بررسی کنید اسناد رسمی.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-28 17:49:03
