از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
تشخیص اشیا میدان بزرگی در بینایی کامپیوتری است و یکی از مهمترین کاربردهای بینایی کامپیوتر در طبیعت است. از یک طرف، میتوان از آن برای ساخت سیستمهای مستقلی استفاده کرد که عوامل را در محیطها هدایت میکنند – چه روباتهایی که وظایف را انجام میدهند یا ماشینهای خودران، اما این نیاز به تقاطع با زمینههای دیگر دارد. با این حال، تشخیص ناهنجاری (مانند محصولات معیوب روی یک خط)، مکان یابی اشیاء درون تصاویر، تشخیص چهره و کاربردهای مختلف دیگر تشخیص اشیا را می توان بدون تلاقی فیلدهای دیگر انجام داد.
تشخیص اشیا به اندازه طبقهبندی تصویر استاندارد نیست، عمدتاً به این دلیل که بیشتر پیشرفتهای جدید بهجای کتابخانهها و چارچوبهای بزرگ، معمولاً توسط محققان، نگهداریکنندگان و توسعهدهندگان منفرد انجام میشود. بستهبندی اسکریپتهای کاربردی ضروری در چارچوبی مانند TensorFlow یا PyTorch و حفظ دستورالعملهای API که تاکنون توسعه را هدایت کردهاند، دشوار است.
این امر تشخیص اشیاء را تا حدودی پیچیدهتر، معمولاً پرمخاطبتر (اما نه همیشه) و کمتر از طبقهبندی تصویر میسازد. یکی از مهمترین مزایای حضور در یک اکوسیستم این است که راهی برای جستجو نکردن اطلاعات مفید در اختیار شما قرار می دهد. روی شیوه ها، ابزارها و رویکردهای خوب برای استفاده. با تشخیص شی – بیشتر مردم باید تحقیقات بیشتری انجام دهند روی چشم انداز میدان را به خوبی در دست بگیرید.
خوشبختانه برای توده ها – Ultralytics یک API تشخیص اشیاء ساده، بسیار قدرتمند و زیبا را پیرامون اجرای YOLOv5 خود توسعه داده است.
در این راهنمای کوتاه، تشخیص اشیا را در پایتون با YOLOv5 که توسط Ultralytics در PyTorch ساخته شده است، با استفاده از مجموعهای از وزنههای از قبل آموزشدیده شده انجام میدهیم. روی ام اس کوکو.
YOLOv5
یولو (شما فقط یک بار نگاه می کنید) یک متدولوژی و همچنین خانواده ای از مدل های ساخته شده برای تشخیص اشیا است. از زمان آغاز به کار در سال 2015، YOLOv1، YOLOv2 (YOLO9000) و YOLOv3 توسط همان نویسنده(ها) پیشنهاد شده اند – و جامعه یادگیری عمیق با پیشرفت های منبع باز در سال های ادامه دار ادامه داد.
Ultralytics’ YOLOv5 اولین پیاده سازی در مقیاس بزرگ YOLO در PyTorch است که آن را بیش از هر زمان دیگری در دسترس قرار داده است، اما دلیل اصلی که YOLOv5 چنین جایگاهی را به دست آورده است API بسیار ساده و قدرتمندی است که پیرامون آن ساخته شده است. این پروژه جزئیات غیر ضروری را حذف می کند، در حالی که امکان سفارشی سازی را فراهم می کند، که عملاً همه قابل استفاده هستند export قالببندی میکند و از شیوههای شگفتانگیزی استفاده میکند که کل پروژه را هم کارآمد و هم بهینه میکند. در واقع، این نمونه ای از زیبایی اجرای نرم افزار منبع باز است، و اینکه چگونه به دنیایی که در آن زندگی می کنیم، قدرت می بخشد.
این پروژه وزنه های از پیش آموزش دیده را ارائه می دهد روی MS COCO، مجموعه داده اصلی روی اشیاء در زمینه، که می توانند هم برای محک زدن و هم برای ساختن سیستم های تشخیص اشیاء عمومی استفاده شوند – اما مهمتر از همه، می توانند برای انتقال دانش عمومی از اشیاء در زمینه به مجموعه داده های سفارشی استفاده شوند.
تشخیص اشیا با YOLOv5
قبل از حرکت به جلو، مطمئن شوید که دارید torch و torchvision نصب شده است:
! python -m pip install torch torchvision
همانطور که نشان داده شده است، YOLOv5 مستندات دقیق و بی معنی و یک API زیبا و ساده دارد. روی خود مخزن و در مثال زیر:
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
img = 'https://i.ytimg.com/vi/q71MCWAEfL8/maxresdefault.jpg'
results = model(img)
fig, ax = plt.subplots(figsize=(16, 12))
ax.imshow(results.render()(0))
plt.show()
استدلال دوم از hub.load() روش وزن هایی را که می خواهیم استفاده کنیم را مشخص می کند. با انتخاب هر جایی بین yolov5n به yolov5l6 – ما در حال بارگیری وزنه های از پیش آموزش دیده MS COCO هستیم. برای مدل های سفارشی:
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path_to_weights.pt')
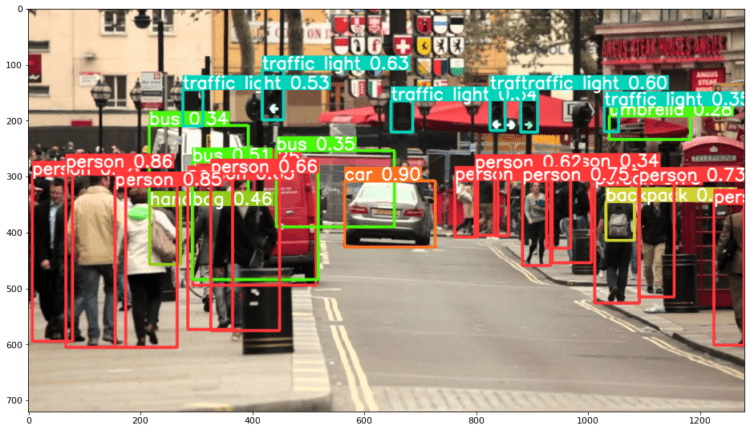
در هر صورت – هنگامی که ورودی را از طریق مدل عبور می دهید، شیء برگشتی شامل روش های مفیدی برای تفسیر نتایج می شود، و ما انتخاب کرده ایم که render() آنها، که یک آرایه NumPy را برمی گرداند که می توانیم آن را در یک chuck کنیم imshow() زنگ زدن. این منجر به یک قالب بندی خوب می شود:

ذخیره نتایج به عنوان فایل
می توانید نتایج استنتاج را به صورت فایل با استفاده از results.save() روش:
results.save(save_dir='results')
اگر دایرکتوری جدیدی وجود نداشته باشد، این یک دایرکتوری جدید ایجاد می کند و همان تصویری را که به تازگی رسم کرده ایم به عنوان یک فایل ذخیره می کند.
برش اشیاء
همچنین می توانید تصمیم بگیرید که اشیاء شناسایی شده را به عنوان فایل های جداگانه برش دهید. در مورد ما، برای هر برچسب شناسایی شده، تعدادی تصویر را می توان استخراج کرد. این به راحتی از طریق results.crop() روش، که ایجاد یک runs/detect/ دایرکتوری، با expN/crops (که در آن N برای هر اجرا افزایش می یابد)، که در آن یک فهرست با تصاویر برش داده شده برای هر برچسب ساخته می شود:
results.crop()
Saved 1 image to runs/detect/exp2
Saved results to runs/detect/exp2
({'box': (tensor(295.09409),
tensor(277.03699),
tensor(514.16113),
tensor(494.83691)),
'conf': tensor(0.25112),
'cls': tensor(0.),
'label': 'person 0.25',
'im': array((((167, 186, 165),
(174, 184, 167),
(173, 184, 164),
همچنین می توانید ساختار فایل خروجی را با استفاده از:
! ls runs/detect/exp2/crops
! ls runs/detect/exp2/crops
شمارش اشیا
بهطور پیشفرض، زمانی که تشخیص یا print را results شی – تعداد تصاویری که استنتاج انجام شده است را دریافت خواهید کرد روی برای آن results شی (YOLOv5 با دسته ای از تصاویر نیز کار می کند)، وضوح آن و تعداد هر برچسب شناسایی شده:
print(results)
این نتیجه در:
image 1/1: 720x1280 14 persons, 1 car, 3 buss, 6 traffic lights, 1 backpack, 1 umbrella, 1 handbag
Speed: 35.0ms pre-process, 256.2ms inference, 0.7ms NMS per image at shape (1, 3, 384, 640)
استنباط با اسکریپت
همچنین، میتوانید اسکریپت شناسایی را اجرا کنید، detect.py، با شبیه سازی مخزن YOLOv5:
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -r requirements.txt
و سپس دویدن:
$ python detect.py --source img.jpg
از طرف دیگر، میتوانید یک URL، فایل ویدیویی، مسیری به دایرکتوری با چندین فایل، یک گلوب در مسیری که فقط برای فایلهای خاص مطابقت دارد، یک پیوند YouTube یا هر جریان HTTP دیگری ارائه دهید. نتایج در ذخیره می شود runs/detect فهرست راهنما.
نتیجه
در این راهنمای کوتاه، نگاهی انداختهایم به اینکه چگونه میتوانید با YOLOv5 که با استفاده از PyTorch ساخته شده است، تشخیص شی را انجام دهید.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-03 22:04:05
