از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



زمان لازم برای مطالعه: 2 دقیقه
بنابراین – شما با استفاده از XGBoost یک رگرسیور درخشان را آموزش داده اید! کدام ویژگی مهم ترین در محاسبه رگرسیون است؟ اولین قدم در جعبه گشایی سیستم جعبه سیاه که یک مدل یادگیری ماشینی می تواند باشد، بررسی ویژگی ها و اهمیت آنها در رگرسیون است.
بیایید به سرعت یک ماک تمرین کنیم XGBRegressor روی مجموعه داده اسباب بازی:
from sklearn import datasets
from sklearn.model_selection import train_test_split
X, y = datasets.load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print(X_train_scaled.shape)
shape از X_train است:
(331, 10)
10 ویژگی برای یادگیری و اتصال به فرمول رگرسیون. بیایید مدل را متناسب کنیم:
xbg_reg = xgb.XGBRegressor().fit(X_train_scaled, y_train)
عالی! اکنون، برای دسترسی به امتیازهای اهمیت ویژگی، تقویت کننده اصلی مدل را از طریق get_booster()، و مفید get_score() روش به شما امکان می دهد نمرات اهمیت را بدست آورید.
طبق مستندات، میتوانید آرگومانی را که تعریف میکند، ارسال کنید کدام نوع از اهمیت امتیازی که می خواهید محاسبه کنید:
‘weight’– تعداد دفعاتی که یک ویژگی برای تقسیم داده ها در تمام درختان استفاده می شود.‘gain’– میانگین بهره در تمام تقسیمات که ویژگی در آنها استفاده می شود.‘cover’– میانگین پوشش در تمام تقسیمات که ویژگی در آنها استفاده می شود.‘total_gain’– سود کل در تمام تقسیمات که ویژگی در آنها استفاده می شود.‘total_cover’– پوشش کل در تمام تقسیمات که ویژگی در آنها استفاده می شود.
که گفته می شود – بسته به روی کدام نوع اهمیت را می خواهید بررسی کنید، امتیازهای اهمیت را به عنوان یک فرهنگ لغت دریافت خواهید کرد:
xbg_reg.get_booster().get_score(importance_type='gain')
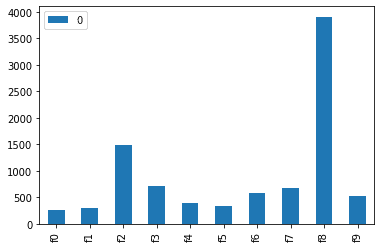
این منجر به فرهنگ لغت ویژگی ها و امتیازات آنها می شود:
{'f0': 269.0863952636719,
'f1': 289.7273254394531,
'f2': 1493.409912109375,
'f3': 708.8233642578125,
'f4': 397.26751708984375,
'f5': 336.8326110839844,
'f6': 586.3340454101562,
'f7': 680.273193359375,
'f8': 3906.28857421875,
'f9': 531.477783203125}
دیکشنری ها به راحتی به پاندا تبدیل می شوند DataFrames، که به نوبه خود با استفاده از ادغام زیربنایی با Matplotlib به راحتی قابل تجسم هستند:
import pandas as pd
f_importance = xbg_reg.get_booster().get_score(importance_type='gain')
importance_df = pd.DataFrame.from_dict(data=f_importance,
orient='index')
و اکنون برای طرح آنها:
importance_df.plot.bar()
این منجر به:

به یاد بیاورید که ما رگرسیور را با 10 ویژگی تطبیق داده ایم – اهمیت هر کدام که در نمودار نشان داده شده است.
اگر میخواهید درباره قابلیتهای ترسیم پانداها با جزئیات بیشتر بخوانید، ما را بخوانید “راهنمای تجسم داده ها در پایتون با پانداها”!
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-05 21:42:04
