از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
منابع هرگز برای برآوردن نیازهای رو به رشد در بیشتر صنایع، و در حال حاضر به ویژه در فناوری که راه خود را عمیق تر به زندگی ما می کند، کافی نیست. فناوری زندگی را آسانتر و راحتتر میکند و میتواند در طول زمان تکامل یابد و بهتر شود.
این اتکا را افزایش داد روی فناوری به قیمت از دست دادن منابع محاسباتی موجود تمام شده است. در نتیجه، رایانههای قدرتمندتری در حال توسعه هستند و بهینهسازی کد هرگز مهمتر از این نبوده است.
الزامات عملکرد برنامه بیش از آن چیزی است که سخت افزار ما بتواند با آن هماهنگی کند، در حال افزایش است. برای مبارزه با این، مردم راهبردهای زیادی برای استفاده موثرتر از منابع ارائه کرده اند. ظرف سازی، برنامه های کاربردی واکنشی (ناهمزمان).، و غیره.
اگرچه، اولین قدمی که باید برداریم، و تا حد زیادی سادهترین قدمی است که باید در نظر گرفت، این است بهینه سازی کد. ما باید کدی بنویسیم که عملکرد بهتری داشته باشد و از منابع محاسباتی کمتری استفاده کند.
در این مقاله، الگوها و رویههای رایج در برنامهنویسی پایتون را در تلاش برای افزایش عملکرد و افزایش استفاده از منابع محاسباتی موجود، بهینهسازی میکنیم.
مشکل در عملکرد
همانطور که راه حل های نرم افزاری مقیاس می شوند، عملکرد بسیار مهم تر می شود و مسائل بزرگ تر و قابل مشاهده تر می شوند. وقتی در حال نوشتن کد هستیم روی ما localhost، از دست دادن برخی از مشکلات عملکرد آسان است زیرا استفاده شدید نیست. هنگامی که همان نرم افزار برای هزاران و صدها هزار کاربر نهایی همزمان مستقر می شود، مسائل پیچیده تر می شوند.
کندی یکی از اصلیترین مسائلی است که هنگام مقیاسبندی نرمافزار ایجاد میشود. این با افزایش زمان پاسخ مشخص می شود. به عنوان مثال، سرور وب ممکن است برای ارائه صفحات وب بیشتر طول بکشد یا زمانی که درخواست ها بسیار زیاد می شود، پاسخ ها را به مشتریان ارسال می کند. هیچ کس یک سیستم کند را دوست ندارد، به ویژه از آنجایی که فناوری قرار است برخی از عملیات ها را سریعتر کند، و اگر سیستم کند باشد، قابلیت استفاده کاهش می یابد.
هنگامی که نرم افزار برای استفاده از منابع موجود به خوبی بهینه نشده باشد، در نهایت به منابع بیشتری برای اطمینان از اجرای روان نیاز دارد. به عنوان مثال، اگر مدیریت حافظه به خوبی مدیریت نشود، برنامه در نهایت به حافظه بیشتری نیاز دارد، در نتیجه منجر به ارتقاء هزینه ها یا خرابی های مکرر می شود.
ناهماهنگی و خروجی اشتباه یکی دیگر از نتایج بهینه سازی ضعیف برنامه ها است. این نکات نیاز به بهینه سازی برنامه ها را برجسته می کند.
چرا و چه زمانی بهینه سازی کنیم
هنگام ساخت و ساز برای استفاده در مقیاس بزرگ، بهینه سازی یکی از جنبه های مهم نرم افزار است که باید در نظر گرفته شود. نرم افزار بهینه شده قادر است تعداد زیادی از کاربران یا درخواست های همزمان را رسیدگی کند و در عین حال سطح عملکرد را از نظر سرعت به راحتی حفظ کند.
این منجر به رضایت کلی مشتری می شود زیرا استفاده از آن بی تاثیر است. این همچنین منجر به سردرد کمتری میشود که یک برنامه در نیمهشب از کار بیفتد و مدیر عصبانی شما با شما تماس بگیرد تا فوراً آن را برطرف کنید.
منابع محاسباتی گران هستند و بهینه سازی می تواند در کاهش هزینه های عملیاتی از نظر ذخیره سازی، حافظه یا قدرت محاسباتی مفید باشد.
اما چه زمانی بهینه سازی کنیم؟
توجه به این نکته مهم است که بهینهسازی ممکن است با پیچیدهتر کردن آن بر خوانایی و قابلیت نگهداری پایگاه کد تأثیر منفی بگذارد. بنابراین، در نظر گرفتن نتیجه بهینه سازی در برابر بدهی فنی که ایجاد می کند، مهم است.
اگر ما در حال ساختن سیستمهای بزرگی هستیم که انتظار تعامل زیاد توسط کاربران نهایی را دارند، پس ما نیاز داریم که سیستم ما در بهترین حالت کار کند و این مستلزم بهینهسازی است. همچنین، اگر منابع محدودی از نظر قدرت محاسباتی یا حافظه داشته باشیم، بهینهسازی کمک زیادی به این امر میکند که بتوانیم با منابعی که در اختیار داریم اکتفا کنیم.
پروفایل کردن
قبل از اینکه بتوانیم کد خود را بهینه کنیم، باید کار کند. به این ترتیب میتوانیم بگوییم که چگونه منابع را کار میکند و از آن استفاده میکند. و این ما را به اولین قانون بهینه سازی می رساند – نکن.
همانطور که دونالد کنوت – ریاضیدان، دانشمند کامپیوتر و استاد دانشگاه استنفورد می گوید:
“بهینه سازی زودرس این است root از همه بدی ها.”
راه حل باید کار کند تا بهینه شود.
نمایه سازی مستلزم بررسی دقیق کد ما و تجزیه و تحلیل عملکرد آن به منظور شناسایی روش عملکرد کد ما در موقعیت ها و زمینه های مختلف در صورت نیاز است. این ما را قادر می سازد تا مدت زمانی را که برنامه ما طول می کشد یا مقدار حافظه ای که در عملیات خود استفاده می کند، شناسایی کنیم. این اطلاعات در بهینه سازی حیاتی است process از آنجایی که به ما کمک می کند تصمیم بگیریم که کد خود را بهینه کنیم یا نه.
نمایه سازی می تواند یک کار چالش برانگیز باشد و زمان زیادی را صرف کند و اگر به صورت دستی انجام شود، ممکن است برخی از مسائلی که بر عملکرد تأثیر می گذارند نادیده گرفته شوند. برای این منظور، ابزارهای مختلفی که می توانند به کدنویسی پروفایل سریعتر و کارآمدتر کمک کنند عبارتند از:
- PyCallGraph – که تجسم گراف فراخوانی را ایجاد می کند که روابط فراخوانی بین زیر روال ها را برای کد پایتون نشان می دهد.
- cProfile – که توضیح می دهد چند وقت یکبار و چه مدت قسمت های مختلف کد پایتون اجرا می شود.
- gProf2dot – که کتابخانه ای است که خروجی پروفایلرها را در نمودار نقطه ای تجسم می کند.
نمایه سازی به ما کمک می کند تا مناطقی را برای بهینه سازی در کد خود شناسایی کنیم. اجازه دهید در مورد اینکه چگونه انتخاب ساختار داده یا جریان کنترل مناسب می تواند به عملکرد بهتر کد پایتون کمک کند، بحث کنیم.
انتخاب ساختارهای داده و جریان کنترل
انتخاب ساختار داده در کد یا الگوریتم پیاده سازی شده ما می تواند بر عملکرد کد پایتون ما تأثیر بگذارد. اگر ما با ساختار داده خود انتخاب های درستی داشته باشیم، کد ما عملکرد خوبی خواهد داشت.
نمایه سازی می تواند کمک بزرگی برای شناسایی بهترین ساختار داده برای استفاده در نقاط مختلف کد پایتون باشد. آیا ما درج زیادی انجام می دهیم؟ آیا ما مرتب حذف می کنیم؟ آیا ما دائماً به دنبال اقلام هستیم؟ چنین سؤالاتی می تواند به ما کمک کند تا ساختار داده صحیح را برای نیاز انتخاب کنیم و در نتیجه به کد پایتون بهینه سازی شده منجر شود.
زمان و استفاده از حافظه تا حد زیادی تحت تأثیر انتخاب ساختار داده ما خواهد بود. همچنین توجه به این نکته مهم است که برخی از ساختارهای داده در زبان های برنامه نویسی مختلف به طور متفاوتی پیاده سازی می شوند.
برای Loop vs List Comprehensions
حلقه ها هنگام توسعه در پایتون رایج هستند و به زودی با درک لیست مواجه خواهید شد که راهی مختصر برای ایجاد لیست های جدید است که شرایط را نیز پشتیبانی می کند.
به عنوان مثال، اگر بخواهیم فهرستی از مجذورات تمام اعداد زوج در یک محدوده معین را با استفاده از عدد بدست آوریم for loop:
new_list = ()
for n in range(0, 10):
if n % 2 == 0:
new_list.append(n**2)
آ List Comprehension نسخه حلقه به سادگی خواهد بود:
new_list = ( n**2 for n in range(0,10) if n%2 == 0)
درک لیست کوتاه تر و مختصرتر است، اما این تنها ترفند در آستین آن نیست. آنها همچنین در زمان اجرا سریعتر از حلقه ها هستند. ما استفاده خواهیم کرد زمان ماژولی که راهی برای زمان بندی بیت های کوچک کد پایتون فراهم می کند.
اجازه دهید درک لیست را در برابر معادل قرار دهیم for حلقه بزنید و ببینید هر کدام چقدر طول می کشد تا به نتیجه یکسانی برسید:
import timeit
def for_square(n):
new_list = ()
for i in range(0, n):
if i % 2 == 0:
new_list.append(n**2)
return new_list
def list_comp_square(n):
return (i**2 for i in range(0, n) if i % 2 == 0)
print("Time taken by For Loop: {}".format(timeit.timeit('for_square(10)', 'from __main__ import for_square')))
print("Time taken by List Comprehension: {}".format(timeit.timeit('list_comp_square(10)', 'from __main__ import list_comp_square')))
پس از اجرای 5 بار اسکریپت با استفاده از پایتون 2:
$ python for-vs-lc.py
Time taken by For Loop: 2.56907987595
Time taken by List Comprehension: 2.01556396484
$
$ python for-vs-lc.py
Time taken by For Loop: 2.37083697319
Time taken by List Comprehension: 1.94110512733
$
$ python for-vs-lc.py
Time taken by For Loop: 2.52163410187
Time taken by List Comprehension: 1.96427607536
$
$ python for-vs-lc.py
Time taken by For Loop: 2.44279003143
Time taken by List Comprehension: 2.16282701492
$
$ python for-vs-lc.py
Time taken by For Loop: 2.63641500473
Time taken by List Comprehension: 1.90950393677
در حالی که تفاوت ثابت نیست، درک لیست زمان کمتری نسبت به زمان می برد for حلقه در کدهای مقیاس کوچک، این ممکن است تفاوت چندانی ایجاد نکند، اما در اجرای در مقیاس بزرگ، ممکن است تمام تفاوت مورد نیاز برای صرفه جویی در زمان باشد.
اگر محدوده مربع ها را از 10 به 100 افزایش دهیم، تفاوت آشکارتر می شود:
$ python for-vs-lc.py
Time taken by For Loop: 16.0991549492
Time taken by List Comprehension: 13.9700510502
$
$ python for-vs-lc.py
Time taken by For Loop: 16.6425571442
Time taken by List Comprehension: 13.4352738857
$
$ python for-vs-lc.py
Time taken by For Loop: 16.2476081848
Time taken by List Comprehension: 13.2488780022
$
$ python for-vs-lc.py
Time taken by For Loop: 15.9152050018
Time taken by List Comprehension: 13.3579590321
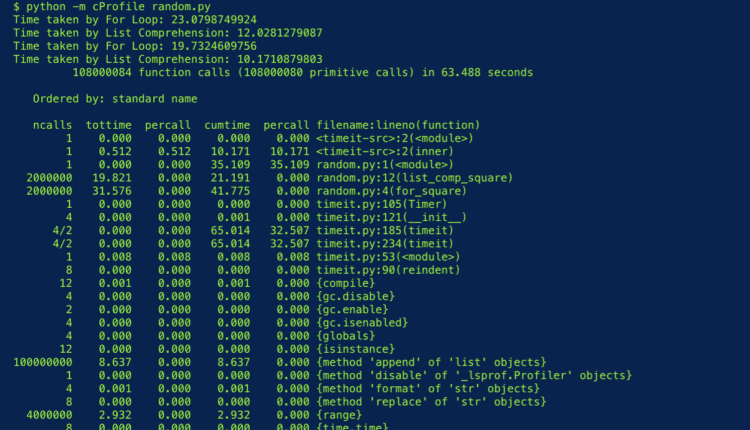
cProfile یک پروفایلر است که با پایتون ارائه می شود و اگر از آن برای پروفایل کد خود استفاده کنیم:

پس از بررسی بیشتر، ما هنوز هم می توانیم ببینیم که cProfile ابزار گزارش می دهد که ما درک لیست زمان اجرا کمتر از ما طول می کشد برای حلقه اجرا، همانطور که قبلاً ایجاد کرده بودیم. cProfile تمام توابع فراخوانی شده، تعداد دفعات فراخوانی آنها و مدت زمان صرف شده توسط هر کدام را نمایش می دهد.
اگر قصد ما این است که زمان لازم برای اجرای کدمان را کاهش دهیم، پس لیست Comprehension انتخاب بهتری نسبت به استفاده از حلقه For خواهد بود. تأثیر چنین تصمیمی برای بهینهسازی کد ما در مقیاس بزرگتر بسیار واضحتر خواهد بود و نشان میدهد که بهینهسازی کد چقدر میتواند مهم و آسان باشد.
اما اگر نگران استفاده از حافظه خود باشیم چه؟ درک لیست نسبت به یک حلقه معمولی به حافظه بیشتری برای حذف موارد در لیست نیاز دارد. درک لیست همیشه پس از تکمیل، یک لیست جدید در حافظه ایجاد می کند، بنابراین برای حذف موارد از یک لیست، یک لیست جدید ایجاد می شود. در حالی که برای یک حلقه for معمولی، می توانیم از آن استفاده کنیم list.remove() یا list.pop() برای تغییر لیست اصلی به جای ایجاد لیست جدید در حافظه.
باز هم، در اسکریپتهای مقیاس کوچک، ممکن است تفاوت چندانی نداشته باشد، اما بهینهسازی در مقیاس بزرگتر به خوبی انجام میشود، و در این شرایط، چنین ذخیرهسازی حافظه به خوبی انجام میشود و به ما امکان میدهد از حافظه اضافی ذخیرهشده برای عملیاتهای دیگر استفاده کنیم.
لیست های پیوندی
یکی دیگر از ساختارهای داده ای که می تواند برای دستیابی به صرفه جویی در حافظه مفید باشد، لیست پیوندی است. تفاوت آن با یک آرایه معمولی در این است که هر آیتم یا node دارای پیوند یا اشاره گر به بعدی است node در لیست است و به تخصیص حافظه پیوسته نیاز ندارد.
یک آرایه نیاز دارد که حافظه مورد نیاز برای ذخیره آن و آیتم های آن از قبل تخصیص داده شود و این می تواند بسیار گران یا بیهوده باشد وقتی که اندازه آرایه از قبل مشخص نباشد.
یک لیست پیوندی به شما امکان می دهد تا در صورت نیاز حافظه را تخصیص دهید. این امکان پذیر است زیرا گرههای موجود در لیست پیوندی را میتوان در مکانهای مختلف حافظه ذخیره کرد، اما از طریق اشارهگرها در لیست پیوندی گرد هم میآیند. این باعث می شود لیست های پیوندی در مقایسه با آرایه ها انعطاف پذیرتر باشند.
نکته ای که در مورد لیست پیوندی وجود دارد این است که به دلیل قرار گرفتن آیتم ها در حافظه، زمان جستجو کندتر از آرایه است. پروفایل مناسب به شما کمک می کند تشخیص دهید که آیا به حافظه بهتر یا مدیریت زمان نیاز دارید تا تصمیم بگیرید که آیا از یک لیست پیوندی یا یک آرایه به عنوان انتخاب ساختار داده هنگام بهینه سازی کد خود استفاده کنید یا خیر.
Range در مقابل XRange
زمانی که با حلقهها در پایتون سر و کار داریم، گاهی اوقات لازم است فهرستی از اعداد صحیح ایجاد کنیم تا به ما در اجرای حلقههای for کمک کنند. توابع range و xrange برای این منظور استفاده می شوند.
عملکرد آنها یکسان است اما از این نظر متفاوت هستند range برمی گرداند a list اعتراض اما xrange یک را برمی گرداند xrange هدف – شی.
این یعنی چی؟ یک xrange شی یک مولد است که لیست نهایی نیست. این توانایی را به ما می دهد تا از طریق تکنیکی به نام “بازده”، مقادیر موجود در لیست نهایی مورد انتظار را همانطور که در زمان اجرا مورد نیاز است تولید کنیم.
این واقعیت که xrange تابع لیست نهایی را بر نمی گرداند، آن را به انتخاب کارآمدتر حافظه برای تولید لیست های عظیمی از اعداد صحیح برای اهداف حلقه تبدیل می کند.
اگر نیاز به تولید تعداد زیادی اعداد صحیح برای استفاده داشته باشیم، xrange از آنجایی که از حافظه کمتری استفاده می کند، باید گزینه پیش روی ما برای این منظور باشد. اگر از range در عوض، کل لیست اعداد صحیح باید ایجاد شود و این کار حافظه فشرده می شود.
اجازه دهید این تفاوت در مصرف حافظه بین دو عملکرد را بررسی کنیم:
$ python
Python 2.7.10 (default, Oct 23 2015, 19:19:21)
(GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)) روی darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>>
>>> r = range(1000000)
>>> x = xrange(1000000)
>>>
>>> print(sys.getsizeof(r))
8000072
>>>
>>> print(sys.getsizeof(x))
40
>>>
>>> print(type(r))
<type 'list'>
>>> print(type(x))
<type 'xrange'>
ما محدوده ای از 1000000 عدد صحیح را با استفاده از آن ایجاد می کنیم range و xrange. نوع شی ایجاد شده توسط range تابع یک است List که مصرف می کند 8000072 bytes از حافظه در حالی که xrange شی فقط مصرف می کند 40 bytes از حافظه
را xrange عملکرد حافظه ما را ذخیره می کند، مقدار زیادی از آن، اما در مورد زمان جستجوی آیتم چطور؟ بیایید زمان جستجوی یک عدد صحیح را در لیست تولید شده از اعداد صحیح با استفاده از Timeit زمان بندی کنیم:
import timeit
r = range(1000000)
x = xrange(1000000)
def lookup_range():
return r(999999)
def lookup_xrange():
return x(999999)
print("Look up time in Range: {}".format(timeit.timeit('lookup_range()', 'from __main__ import lookup_range')))
print("Look up time in Xrange: {}".format(timeit.timeit('lookup_xrange()', 'from __main__ import lookup_xrange')))
نتیجه:
$ python range-vs-xrange.py
Look up time in Range: 0.0959858894348
Look up time in Xrange: 0.140854114045
$
$ python range-vs-xrange.py
Look up time in Range: 0.111716985703
Look up time in Xrange: 0.130584001541
$
$ python range-vs-xrange.py
Look up time in Range: 0.110965013504
Look up time in Xrange: 0.133008003235
$
$ python range-vs-xrange.py
Look up time in Range: 0.102388143539
Look up time in Xrange: 0.133061170578
xrange ممکن است حافظه کمتری مصرف کند، اما یافتن یک آیتم در آن زمان بیشتری نیاز دارد. با توجه به موقعیت و منابع موجود، می توانیم یکی از این دو را انتخاب کنیم range یا xrange بسته به روی جنبه ای که ما دنبالش هستیم این موضوع اهمیت پروفایل در بهینه سازی کد پایتون ما را تکرار می کند.
توجه داشته باشید: xrange در پایتون 3 منسوخ شده است range تابع اکنون می تواند همان عملکرد را ارائه دهد. ژنراتورها هنوز در دسترس هستند روی پایتون 3 و می تواند به ما در ذخیره حافظه از راه های دیگری مانند درک یا عبارات مولد.
مجموعه ها
هنگام کار با لیست ها در پایتون، باید به خاطر داشته باشیم که آنها اجازه ورودی های تکراری را می دهند. اگر مهم باشد که داده های ما دارای موارد تکراری هستند یا خیر، چه؟
اینجاست که مجموعههای پایتون وارد میشوند. آنها مانند لیستها هستند اما اجازه نمیدهند هیچ تکراری در آنها ذخیره شود. مجموعهها همچنین برای حذف مؤثر موارد تکراری از فهرستها استفاده میشوند و سریعتر از ایجاد یک لیست جدید و پر کردن آن از فهرستی با موارد تکراری هستند.
در این عملیات، میتوانید آنها را بهعنوان یک قیف یا فیلتر در نظر بگیرید که موارد تکراری را نگه میدارد و فقط به مقادیر منحصربهفرد اجازه عبور میدهد.
اجازه دهید این دو عملیات را با هم مقایسه کنیم:
import timeit
def manual_remove_duplicates(list_of_duplicates):
new_list = ()
(new_list.append(n) for n in list_of_duplicates if n not in new_list)
return new_list
def set_remove_duplicates(list_of_duplicates):
return list(set(list_of_duplicates))
list_of_duplicates = (10, 54, 76, 10, 54, 100, 1991, 6782, 1991, 1991, 64, 10)
print("Manually removing duplicates takes {}s".format(timeit.timeit('manual_remove_duplicates(list_of_duplicates)', 'from __main__ import manual_remove_duplicates, list_of_duplicates')))
print("Using Set to remove duplicates takes {}s".format(timeit.timeit('set_remove_duplicates(list_of_duplicates)', 'from __main__ import set_remove_duplicates, list_of_duplicates')))
پس از اجرای پنج بار اسکریپت:
$ python sets-vs-lists.py
Manually removing duplicates takes 2.64614701271s
Using Set to remove duplicates takes 2.23225092888s
$
$ python sets-vs-lists.py
Manually removing duplicates takes 2.65356898308s
Using Set to remove duplicates takes 1.1165189743s
$
$ python sets-vs-lists.py
Manually removing duplicates takes 2.53129696846s
Using Set to remove duplicates takes 1.15646100044s
$
$ python sets-vs-lists.py
Manually removing duplicates takes 2.57102680206s
Using Set to remove duplicates takes 1.13189387321s
$
$ python sets-vs-lists.py
Manually removing duplicates takes 2.48338890076s
Using Set to remove duplicates takes 1.20611810684s
استفاده از یک مجموعه برای حذف موارد تکراری به طور مداوم سریعتر از ایجاد فهرست دستی و افزودن موارد در حین بررسی حضور است.
این میتواند هنگام فیلتر کردن ورودیها برای یک مسابقه جایزه مفید باشد، جایی که باید ورودیهای تکراری را فیلتر کنیم. اگر فیلتر کردن 120 ورودی 2 ثانیه طول می کشد، تصور کنید 10000 ورودی را فیلتر کنید. در چنین مقیاسی، عملکرد بسیار افزایش یافته ای که با مجموعه ها ارائه می شود، قابل توجه است.
این ممکن است به طور معمول رخ ندهد، اما در صورت فراخوانی می تواند تفاوت بزرگی ایجاد کند. نمایه سازی مناسب می تواند به ما در شناسایی چنین موقعیت هایی کمک کند و می تواند در عملکرد کد ما تفاوت ایجاد کند.
الحاق رشته
رشته ها به طور پیش فرض در پایتون تغییر ناپذیر هستند و متعاقباً، الحاق رشته ها می تواند بسیار کند باشد. روش های مختلفی برای به هم پیوستن رشته ها وجود دارد که در موقعیت های مختلف کاربرد دارد.
ما می توانیم استفاده کنیم + (به علاوه) برای پیوستن به رشته ها. این برای چند شی String ایده آل است و در مقیاس نیست. اگر از + عملگر برای الحاق چند رشته، هر الحاق یک شی جدید ایجاد می کند زیرا رشته ها تغییر ناپذیر هستند. این امر منجر به ایجاد بسیاری از اشیاء رشته ای جدید در حافظه و در نتیجه استفاده نادرست از حافظه می شود.
همچنین می توانیم از عملگر concatenate استفاده کنیم += برای پیوستن به رشته ها، اما این فقط برای دو رشته در یک زمان کار می کند، بر خلاف رشته + عملگر که می تواند بیش از دو رشته را به هم بپیوندد.
اگر یک تکرار کننده مانند یک لیست داریم که دارای چندین رشته است، راه ایده آل برای الحاق آنها با استفاده از .join() روش.
اجازه دهید فهرستی از هزاران کلمه ایجاد کنیم و روش استفاده از آن را با هم مقایسه کنیم .join() و += مقایسه اپراتور:
import timeit
list_of_words = ("foo ") * 1000
def using_join(list_of_words):
return "".join(list_of_words)
def using_concat_operator(list_of_words):
final_string = ""
for i in list_of_words:
final_string += i
return final_string
print("Using join() takes {} s".format(timeit.timeit('using_join(list_of_words)', 'from __main__ import using_join, list_of_words')))
print("Using += takes {} s".format(timeit.timeit('using_concat_operator(list_of_words)', 'from __main__ import using_concat_operator, list_of_words')))
بعد از دو بار تلاش:
$ python join-vs-concat.py
Using join() takes 14.0949640274 s
Using += takes 79.5631570816 s
$
$ python join-vs-concat.py
Using join() takes 13.3542580605 s
Using += takes 76.3233859539 s
بدیهی است که .join() متد نه تنها منظمتر و خواناتر است، بلکه به طور قابل توجهی سریعتر از عملگر الحاق در هنگام اتصال رشتهها در یک تکرارکننده است.
اگر بسیاری از عملیات الحاق رشته ها را انجام می دهید، لذت بردن از مزایای رویکردی که تقریباً 7 برابر سریعتر است، فوق العاده است.
نتیجه
ما ثابت کردهایم که بهینهسازی کد در پایتون بسیار مهم است و همچنین تفاوت ایجاد شده در مقیاس آن را مشاهده کردیم. از طریق زمان ماژول و cProfile profiler، ما توانستیم بگوییم اجرای کدام پیاده سازی زمان کمتری می برد و از آن با ارقام پشتیبان تهیه کنیم. ساختارهای داده و ساختارهای جریان کنترلی که ما استفاده می کنیم می توانند عملکرد کد ما را بسیار تحت تاثیر قرار دهند و ما باید بیشتر مراقب باشیم.
نمایه سازی همچنین یک مرحله مهم در بهینه سازی کد است زیرا بهینه سازی را هدایت می کند process و آن را دقیق تر می کند. قبل از بهینهسازی کد ما باید مطمئن شویم که کد ما کار میکند و درست است تا از بهینهسازی زودهنگام جلوگیری کنیم که ممکن است نگهداری آن گرانتر باشد یا درک کد را سخت کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-24 19:34:05
