از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
تجزیه و تحلیل سری های زمانی به تجزیه و تحلیل تغییر در روند داده ها در یک دوره زمانی اشاره دارد. تحلیل سری زمانی کاربردهای مختلفی دارد. یکی از این کاربردها، پیشبینی ارزش آینده یک آیتم است روی ارزش های گذشته آن پیشبینی قیمت سهام در آینده احتمالاً بهترین نمونه از چنین کاربردهایی است. در این مقاله خواهیم دید که چگونه می توانیم تحلیل سری های زمانی را با کمک a انجام دهیم شبکه عصبی مکرر. ما قیمت سهام آینده شرکت اپل (AAPL) را پیش بینی خواهیم کرد روی قیمت سهام آن در 5 سال گذشته
مجموعه داده
داده هایی که برای این مقاله استفاده می کنیم را می توان از آن دانلود کرد یاهو فاینانس. برای آموزش الگوریتم خود، از قیمت سهام اپل از 1 ژانویه 2013 تا 31 دسامبر 2017 استفاده خواهیم کرد. برای پیش بینی، از قیمت سهام اپل برای ماه ژانویه 2018 استفاده خواهیم کرد. بنابراین به منظور ارزیابی عملکرد الگوریتم، قیمت واقعی سهام برای ماه ژانویه 2018 را نیز دانلود کنید.
حال بیایید ببینیم داده های ما چگونه به نظر می رسند. فایل آموزشی قیمت سهام اپل را که حاوی داده های پنج ساله است باز کنید. خواهید دید که شامل هفت ستون است: تاریخ، باز، بالا، پایین، بستن، تنظیم بسته و حجم. ما قیمت سهام افتتاحیه را پیش بینی خواهیم کرد، بنابراین به بقیه ستون ها علاقه ای نداریم.
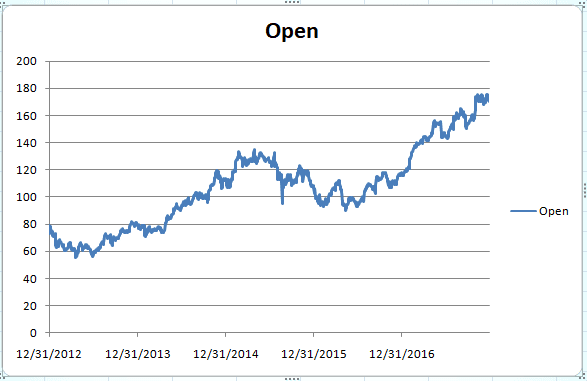
اگر قیمت سهام افتتاحیه را بر اساس تاریخ رسم کنید، نمودار زیر را مشاهده خواهید کرد:

می بینید که روند به شدت غیرخطی است و گرفتن روند با استفاده از این اطلاعات بسیار دشوار است. این جایی است که قدرت LSTM می تواند مورد استفاده قرار گیرد. LSTM (شبکه حافظه کوتاه مدت بلندمدت) نوعی شبکه عصبی بازگشتی است که قادر است اطلاعات گذشته را به خاطر بسپارد و ضمن پیش بینی مقادیر آینده، این اطلاعات گذشته را نیز در نظر بگیرد.
به اندازه کافی مقدمات، بیایید ببینیم چگونه می توان از LSTM برای تحلیل سری های زمانی استفاده کرد.
پیش بینی قیمت سهام در آینده
پیشبینی قیمت سهام مشابه هر مشکل یادگیری ماشین دیگری است که در آن مجموعهای از ویژگیها به ما داده میشود و باید مقدار مربوطه را پیشبینی کنیم. ما همان مراحلی را که انجام می دهیم برای حل هر مشکل یادگیری ماشینی انجام می دهیم. این مراحل را دنبال کنید:
واردات کتابخانه ها
قدم اول، مثل همیشه این است که import کتابخانه های مورد نیاز برای این کار اسکریپت زیر را اجرا کنید:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
وارد کردن مجموعه داده
اسکریپت زیر را اجرا کنید import مجموعه داده ها به خاطر این مقاله، داده ها در پوشه Datasets در درایو “E” ذخیره شده است. بر این اساس می توانید مسیر را تغییر دهید.
apple_training_complete = pd.read_csv(r'E:\Datasets\apple_training.csv')
همانطور که قبلاً گفتیم، ما فقط به قیمت باز شدن سهام علاقه داریم. بنابراین، ما تمام دادههای مجموعه آموزشی خود را فیلتر میکنیم و فقط مقادیر مربوط به آن را حفظ میکنیم باز کن ستون اسکریپت زیر را اجرا کنید:
apple_training_processed = apple_training_complete.iloc(:, 1:2).values
عادی سازی داده ها
به عنوان یک قاعده کلی، هر زمان که از یک شبکه عصبی استفاده می کنید، باید داده های خود را نرمال یا مقیاس کنید. ما استفاده خواهیم کرد MinMaxScaler کلاس از sklear.preprocessing کتابخانه ای برای مقیاس بندی داده های ما بین 0 و 1 feature_range پارامتر برای تعیین محدوده داده های مقیاس شده استفاده می شود. اسکریپت زیر را اجرا کنید:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range = (0, 1))
apple_training_scaled = scaler.fit_transform(apple_training_processed)
تبدیل داده های آموزشی به شکل درست
همانطور که قبلاً گفتم، در مسائل سری زمانی، ما باید یک مقدار را در زمان T بر اساس پیش بینی کنیم روی داده های روزهای TN که در آن N می تواند هر تعداد مرحله باشد. در این مقاله قصد داریم قیمت سهام افتتاحیه را بر اساس داده ها پیش بینی کنیم روی قیمت سهام افتتاحیه در 60 روز گذشته من اعداد مختلف را امتحان و آزمایش کردم و متوجه شدم که بهترین نتایج زمانی حاصل می شود که از 60 مرحله زمانی گذشته استفاده شود. می توانید اعداد مختلف را امتحان کنید و ببینید الگوریتم شما چگونه عمل می کند.
مجموعه ویژگی ما باید شامل مقادیر قیمت سهام افتتاحیه برای 60 روز گذشته باشد در حالی که برچسب یا متغیر وابسته باید قیمت سهام در روز 61 باشد. اسکریپت زیر را برای ایجاد مجموعه ویژگی و برچسب اجرا کنید.
features_set = ()
labels = ()
for i in range(60, 1260):
features_set.append(apple_training_scaled(i-60:i, 0))
labels.append(apple_training_scaled(i, 0))
در اسکریپت بالا دو لیست ایجاد می کنیم: feature_set و labels. 1260 رکورد در داده های آموزشی وجود دارد. ما یک حلقه را اجرا می کنیم که از رکورد 61 شروع می شود و تمام 60 رکورد قبلی را ذخیره می کند. feature_set فهرست رکورد 61 در ذخیره شده است labels فهرست
ما باید هر دو را تبدیل کنیم feature_set و labels قبل از اینکه بتوانیم از آن برای آموزش استفاده کنیم، به آرایه numpy فهرست کنید. اسکریپت زیر را اجرا کنید:
features_set, labels = np.array(features_set), np.array(labels)
به منظور آموزش LSTM روی داده های ما، باید داده های خود را به شکل پذیرفته شده توسط LSTM تبدیل کنیم. ما باید داده های خود را به فرمت سه بعدی تبدیل کنیم. بعد اول تعداد رکوردها یا ردیف های مجموعه داده است که در مورد ما 1260 است. بعد دوم تعداد گام های زمانی است که 60 است در حالی که بعد آخر تعداد نشانگرها است. از آنجایی که ما فقط از یک ویژگی استفاده می کنیم، یعنی باز کن، تعداد اندیکاتورها یک عدد خواهد بود. اسکریپت زیر را اجرا کنید:
features_set = np.reshape(features_set, (features_set.shape(0), features_set.shape(1), 1))
آموزش LSTM
ما داده های خود را از قبل پردازش کرده و به فرمت مورد نظر تبدیل کرده ایم. اکنون زمان ایجاد LSTM است. مدل LSTM که می خواهیم بسازیم یک مدل متوالی با چندین لایه خواهد بود. ما چهار لایه LSTM را به مدل خود اضافه می کنیم و به دنبال آن یک لایه متراکم که قیمت سهام آینده را پیش بینی می کند.
اول بیایید import کتابخانه هایی که برای ایجاد مدل خود به آنها نیاز داریم:
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
در اسکریپت بالا ما آن را وارد کردیم Sequential کلاس از keras.models کتابخانه و Dense، LSTM، و Dropout کلاس ها از keras.layers کتابخانه
به عنوان اولین قدم، ما نیاز به نمونه سازی داریم Sequential کلاس این کلاس مدل ما خواهد بود و لایه های LSTM، Dropout و Dense را به این مدل اضافه می کنیم. اسکریپت زیر را اجرا کنید
model = Sequential()
ایجاد لایه های LSTM و Dropout
بیایید لایه LSTM را به مدلی که ایجاد کردیم اضافه کنیم. برای این کار اسکریپت زیر را اجرا کنید:
model.add(LSTM(units=50, return_sequences=True, input_shape=(features_set.shape(1), 1)))
برای افزودن یک لایه به مدل ترتیبی، add روش استفاده می شود. درون add روش، لایه LSTM خود را رد کردیم. اولین پارامتر لایه LSTM تعداد نورون ها یا گره هایی است که ما در لایه می خواهیم. پارامتر دوم است return_sequences، که روی true تنظیم شده است زیرا ما لایه های بیشتری به مدل اضافه خواهیم کرد. اولین پارامتر به input_shape تعداد مراحل زمانی است در حالی که آخرین پارامتر تعداد نشانگرها است.
بیایید اکنون یک لایه حذفی به مدل خود اضافه کنیم. لایه Dropout برای جلوگیری از برازش بیش از حد اضافه می شود، که پدیده ای است که در آن مدل یادگیری ماشین بهتر عمل می کند روی داده های آموزشی در مقایسه با داده های آزمون اسکریپت زیر را برای افزودن لایه حذفی اجرا کنید.
model.add(Dropout(0.2))
بیایید سه لایه LSTM و dropout را به مدل خود اضافه کنیم. اسکریپت زیر را اجرا کنید.
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
ایجاد لایه متراکم
برای اینکه مدلمان قوی تر شود، یک لایه متراکم در انتهای مدل اضافه می کنیم. تعداد نورون ها در لایه متراکم روی 1 تنظیم می شود زیرا می خواهیم یک مقدار واحد را در خروجی پیش بینی کنیم.
model.add(Dense(units = 1))
تدوین مدل
در نهایت، قبل از اینکه بتوانیم آن را آموزش دهیم، باید LSTM خود را کامپایل کنیم روی داده های آموزشی اسکریپت زیر مدل ما را کامپایل می کند.
model.compile(optimizer = 'adam', loss = 'mean_squared_error')
متد کامپایل را صدا می زنیم روی شی مدل ترتیبی که در مورد ما “مدل” است. ما استفاده می کنیم خطای میانگین مربعات به عنوان تابع ضرر و برای کاهش تلفات یا بهینه سازی الگوریتم از آدم بهینه ساز
آموزش الگوریتم
اکنون زمان آموزش مدلی است که در چند مرحله قبل تعریف کردیم. برای انجام این کار، ما با fit روش روی را model و ویژگی ها و برچسب های آموزشی ما را مطابق شکل زیر ارسال کنید:
model.fit(features_set, labels, epochs = 100, batch_size = 32)
بسته به سخت افزار شما، آموزش مدل ممکن است کمی طول بکشد.
تست LSTM ما
ما LSTM خود را با موفقیت آموزش داده ایم، اکنون زمان آن است که عملکرد الگوریتم خود را آزمایش کنیم روی این تست با پیشبینی قیمت سهام افتتاحیه برای ماه ژانویه 2018 تنظیم شده است.
اول بیایید import داده های تست ما اسکریپت زیر را اجرا کنید:
apple_testing_complete = pd.read_csv(r'E:\Datasets\apple_testing.csv')
apple_testing_processed = apple_testing_complete.iloc(:, 1:2).values
در اسکریپت بالا، ما import دادههای آزمایشی ما و همانطور که با دادههای آموزشی انجام دادیم، همه ستونها را از دادههای آزمایشی حذف کردیم به جز ستونی که شامل قیمتهای سهام افتتاحیه است.
اگر قیمت سهام افتتاحیه برای ماه ژانویه 2018 بر اساس تاریخ ها ترسیم شود، باید نمودار زیر را مشاهده کنید.

می بینید که روند به شدت غیرخطی است. در مجموع، قیمت سهام در ابتدای ماه با افزایش اندکی همراه بوده و در پایان ماه با روند نزولی همراه با اندکی افزایش و کاهش قیمت سهام در بین آنها مواجه است. پیش بینی چنین روندی بسیار دشوار است. بیایید ببینیم آیا LSTM که ما آموزش دادیم واقعاً می تواند چنین روندی را پیش بینی کند یا خیر.
تبدیل داده های تست به فرمت مناسب
برای هر روز از ژانویه 2018، میخواهیم مجموعه ویژگیهای ما شامل قیمتهای سهام افتتاحیه برای 60 روز گذشته باشد. برای اول ژانویه به قیمت سهام 60 روز قبل نیاز داریم. برای انجام این کار، باید داده های آموزشی و داده های آزمایشی خود را قبل از پیش پردازش به هم متصل کنیم. برای این کار اسکریپت زیر را اجرا کنید:
apple_total = pd.concat((apple_training_complete('Open'), apple_testing_complete('Open')), axis=0)
حالا بیایید ورودی های آزمایشی خود را آماده کنیم. ورودی هر روز باید شامل قیمت سهام افتتاحیه برای 60 روز قبل باشد. یعنی برای 20 روز آزمون برای ماه ژانویه 2018 و 60 قیمت سهام از 60 روز گذشته برای مجموعه آموزشی نیاز داریم. اسکریپت زیر را برای واکشی آن 80 مقدار اجرا کنید.
test_inputs = apple_total(len(apple_total) - len(apple_testing_complete) - 60:).values
همانطور که برای مجموعه آموزشی انجام دادیم، باید داده های تست خود را مقیاس بندی کنیم. اسکریپت زیر را اجرا کنید:
test_inputs = test_inputs.reshape(-1,1)
test_inputs = scaler.transform(test_inputs)
ما دادههای خود را مقیاسبندی کردیم، اکنون بیایید مجموعه ورودی آزمایشی نهایی خود را آماده کنیم که شامل 60 قیمت سهام قبلی برای ماه ژانویه است. اسکریپت زیر را اجرا کنید:
test_features = ()
for i in range(60, 80):
test_features.append(test_inputs(i-60:i, 0))
در نهایت، ما باید داده های خود را به فرمت سه بعدی تبدیل کنیم که بتوان از آن به عنوان ورودی LSTM استفاده کرد. اسکریپت زیر را اجرا کنید:
test_features = np.array(test_features)
test_features = np.reshape(test_features, (test_features.shape(0), test_features.shape(1), 1))
پیشگویی
اکنون زمان دیدن جادو است. ما داده های آزمایشی خود را از قبل پردازش کردیم و اکنون می توانیم از آن برای پیش بینی استفاده کنیم. برای انجام این کار، فقط باید با شماره تماس بگیرید predict روش روی مدلی که ما آموزش دادیم اسکریپت زیر را اجرا کنید:
predictions = model.predict(test_features)
از آنجایی که ما داده های خود را مقیاس بندی کردیم، پیش بینی های انجام شده توسط LSTM نیز مقیاس بندی شده اند. ما باید پیش بینی مقیاس شده را به مقادیر واقعی آنها برگردانیم. برای این کار می توانیم از ìnverse_transform روش شی مقیاسکننده که در طول آموزش ایجاد کردیم. به اسکریپت زیر دقت کنید:
predictions = scaler.inverse_transform(predictions)
در نهایت، بیایید ببینیم الگوریتم ما چقدر قیمت سهام آتی را پیشبینی کرده است. اسکریپت زیر را اجرا کنید:
plt.figure(figsize=(10,6))
plt.plot(apple_testing_processed, color='blue', label='Actual Apple Stock Price')
plt.plot(predictions , color='red', label='Predicted Apple Stock Price')
plt.title('Apple Stock Price Prediction')
plt.xlabel('Date')
plt.ylabel('Apple Stock Price')
plt.legend()
plt.show()
خروجی به شکل زیر است:

در خروجی، خط آبی نشان دهنده قیمت واقعی سهام برای ماه ژانویه 2018 است، در حالی که خط قرمز نشان دهنده قیمت های سهام پیش بینی شده است. شما به وضوح می بینید که الگوریتم ما توانسته است روند کلی را ثبت کند. قیمتهای پیشبینیشده نیز در ابتدا یک روند صعودی و سپس یک روند نزولی یا نزولی در پایان مشاهده میکنند. شگفت انگیز است، اینطور نیست؟
نتیجه
شبکه حافظه کوتاه مدت بلند مدت (LSTM) یکی از رایج ترین شبکه های عصبی مورد استفاده برای تجزیه و تحلیل سری های زمانی است. توانایی LSTM برای به خاطر سپردن اطلاعات قبلی، آن را برای چنین کارهایی ایده آل می کند. در این مقاله دیدیم که چگونه می توانیم از LSTM برای پیش بینی قیمت سهام اپل استفاده کنیم. پیشنهاد میکنم سهام برخی سازمانهای دیگر مانند گوگل یا مایکروسافت را از Yahoo Finance دانلود کنید و ببینید آیا الگوریتم شما میتواند روندها را ثبت کند یا خیر.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-26 05:32:04
