از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
زبان نشانه گذاری توسعه پذیر (XML) یک زبان نشانه گذاری است که به دلیل روش ساخت داده ها محبوب است. این استفاده در انتقال داده ها (نمایانگر اشیاء سریالی) و پرونده های پیکربندی است.
علیرغم افزایش محبوبیت JSON ، شما هنوز هم می توانید XML را در پرونده مانیفست Android Development ، Java/Maven Build Build Tools و API های SOAP پیدا کنید روی وب. تجزیه XML از این رو هنوز یک کار مشترک است که یک توسعه دهنده باید انجام دهد.
در پایتون ، ما می توانیم XML را با استفاده از دو کتابخانه بخوانیم و تجزیه کنیم: سوپ زیبا و LXML.
در این راهنما ، ما نگاهی به استخراج و تجزیه داده ها از پرونده های XML خواهیم داشت سوپ زیبا و LXMLو نتایج را با استفاده از پاندا ذخیره کنید.
راه اندازی LXML و BeautifulSoup
ابتدا باید هر دو کتابخانه را نصب کنیم. ما یک پوشه جدید در فضای کاری شما ایجاد خواهیم کرد ، یک محیط مجازی تنظیم می کنیم و کتابخانه ها را نصب می کنیم:
$ mkdir xml_parsing_tutorial
$ cd xml_parsing_tutorial
$ python3 -m venv env
$ . env/bin/activate
$ pip install lxml beautifulsoup4
حالا که همه چیز را تنظیم کرده ایم ، بیایید برخی از تجزیه ها را انجام دهیم!
تجزیه XML با lxml و BeautifulSoup
تجزیه همیشه بستگی دارد روی پرونده اساسی و ساختاری که از آن استفاده می کند بنابراین هیچ وجود ندارد تک گلوله نقره ای برای همه فایل ها Beautifulsoup آنها را به طور خودکار تجزیه می کند ، اما عناصر اساسی وابسته به کار هستند.
بنابراین، بهتر است تجزیه را با دست یاد بگیرید-روی رویکرد. XML زیر را در یک پرونده در فهرست کار خود ذخیره کنید – teachers.xml:
<?xml version="1.0" encoding="UTF-8"?>
<teachers>
<teacher>
<name>Sam Davies</name>
<age>35</age>
<subject>Maths</subject>
</teacher>
<teacher>
<name>Cassie Stone</name>
<age>24</age>
<subject>Science</subject>
</teacher>
<teacher>
<name>Derek Brandon</name>
<age>32</age>
<subject>History</subject>
</teacher>
</teachers>
را <teachers> برچسب نشان می دهد root از سند XML، <teacher> تگ فرزند یا عنصر فرعی است <teachers></teachers>، با اطلاعاتی در مورد یک شخص مفرد. را <name>، <age>، <subject> فرزندان هستند <teacher> برچسب، و نوه های <teachers> برچسب زدن
خط اول، <?xml version="1.0" encoding="UTF-8"?>، در سند نمونه بالا an نامیده می شود XML Prolog. همیشه در ابتدای یک پرونده XML قرار می گیرد ، اگرچه شامل یک پیش نویس XML در یک سند XML کاملاً اختیاری است.
Prolog XML که در بالا نشان داده شده است ، نسخه XML مورد استفاده و نوع رمزگذاری کاراکتر را نشان می دهد. در این حالت ، شخصیت های سند XML در UTF-8 رمزگذاری می شوند.
اکنون که ساختار فایل XML را فهمیدیم – می توانیم آن را تجزیه کنیم. یک فایل جدید به نام ایجاد کنید teachers.py در فهرست کاری شما، و import کتابخانه BeautifulSoup:
from bs4 import BeautifulSoup
توجه داشته باشید: همانطور که ممکن است متوجه شده باشید، ما این کار را نکردیم import lxml! با وارد کردن BeautifulSoup، LXML به طور خودکار یکپارچه می شود، بنابراین وارد کردن آن به طور جداگانه ضروری نیست، اما به عنوان بخشی از BeautifulSoup نصب نمی شود.
حال بیایید محتویات فایل XML را که ساخته ایم بخوانیم و آن را در متغیری به نام ذخیره کنیم soup بنابراین می توانیم تجزیه را شروع کنیم:
with open('teachers.xml', 'r') as f:
file = f.read()
soup = BeautifulSoup(file, 'xml')
را soup متغیر اکنون دارای محتوای تجزیه شده فایل XML ما است. میتوانیم از این متغیر و روشهای متصل به آن برای بازیابی اطلاعات XML با کد پایتون استفاده کنیم.
فرض کنید می خواهیم فقط نام معلمان را از سند XML مشاهده کنیم. ما می توانیم آن اطلاعات را با چند خط کد بدست آوریم:
names = soup.find_all('name')
for name in names:
print(name.text)
در حال دویدن python teachers.py به ما می داد:
Sam Davis
Cassie Stone
Derek Brandon
را find_all() متد لیستی از تمام تگ های تطبیق داده شده به آن را به عنوان آرگومان برمی گرداند. همانطور که در کد بالا نشان داده شده است، soup.find_all('name') همه را برمی گرداند <name> برچسب ها در فایل XML سپس روی این تگ ها و print آنها text ویژگی که حاوی مقادیر تگ ها است.
نمایش داده های تجزیه شده در یک جدول
بیایید کارها را یک قدم جلوتر برداریم، تمام محتویات فایل XML را تجزیه می کنیم و آن را در قالب جدول نمایش می دهیم.
بیایید دوباره بنویسیم teachers.py فایل با:
from bs4 import BeautifulSoup
with open('teachers.xml', 'r') as f:
file = f.read()
soup = BeautifulSoup(file, 'xml')
names = soup.find_all('name')
ages = soup.find_all('age')
subjects = soup.find_all('subject')
print('-'.center(35, '-'))
print('|' + 'Name'.center(15) + '|' + ' Age ' + '|' + 'Subject'.center(11) + '|')
for i in range(0, len(names)):
print('-'.center(35, '-'))
print(
f'|{names(i).text.center(15)}|{ages(i).text.center(5)}|{subjects(i).text.center(11)}|')
print('-'.center(35, '-'))
خروجی کد بالا به شکل زیر خواهد بود:
-----------------------------------
| Name | Age | Subject |
-----------------------------------
| Sam Davies | 35 | Maths |
-----------------------------------
| Cassie Stone | 24 | Science |
-----------------------------------
| Derek Brandon | 32 | History |
-----------------------------------
تبریک میگم شما به تازگی اولین فایل XML خود را با BeautifulSoup و LXML تجزیه کردید! حالا که با این تئوری راحت تر شده اید process، بیایید یک مثال واقعی تر را امتحان کنیم.
ما داده ها را به عنوان یک جدول به عنوان پیشرو برای ذخیره آن در یک ساختار داده همه کاره قالب بندی کرده ایم. یعنی – در پروژه کوچک آینده، ما داده ها را در یک پاندا ذخیره می کنیم DataFrame.
اگر قبلاً با DataFrames آشنا نیستید – Python with Pandas ما را بخوانید: راهنمای DataFrames!
تجزیه یک فید RSS و ذخیره داده ها در یک CSV
در این بخش، فید RSS را تجزیه می کنیم نیویورک تایمز نیوزو آن داده ها را در یک فایل CSV ذخیره کنید.
RSS کوتاه است برای سندیکای واقعا ساده. فید RSS فایلی است که حاوی خلاصهای از بهروزرسانیهای یک وبسایت است و به زبان XML نوشته شده است. در این مورد، فید RSS از مجله نیویورک تایمز شامل خلاصه ای از به روز رسانی اخبار روزانه است روی وب سایت آنها این خلاصه حاوی پیوندهایی به انتشارات خبری، پیوندهایی به تصاویر مقاله، توضیحاتی در مورد اخبار و موارد دیگر است. از فیدهای RSS نیز استفاده میشود تا به افراد اجازه دهد بدون خراش دادن وبسایتها به عنوان یک توکن خوب توسط صاحبان وبسایت، دادهها را دریافت کنند.
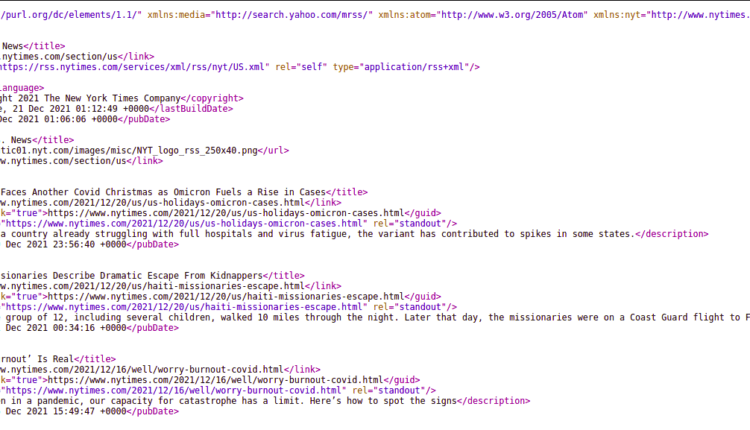
در اینجا یک عکس فوری از فید RSS از نیویورک تایمز است:

از این طریق می توانید به فیدهای RSS مختلف نیویورک تایمز در قاره ها، کشورها، مناطق، موضوعات و معیارهای مختلف دسترسی پیدا کنید. ارتباط دادن.
قبل از شروع تجزیه، دیدن و درک ساختار داده ها بسیار مهم است. داده هایی که می خواهیم از فید RSS در مورد هر مقاله خبری استخراج کنیم عبارتند از:
- شناسه منحصر به فرد جهانی (GUID)
- عنوان
- تاریخ انتشار
- شرح
حالا که با ساختار آشنا شدیم و اهداف مشخصی داریم، بیایید برنامه خود را شروع کنیم! ما نیاز داریم requests کتابخانه و pandas کتابخانه برای بازیابی داده ها و تبدیل آنها به یک فایل CSV.
اگر با آن کار نکرده اید
requestsقبل از این، راهنمای ماژول درخواست های پایتون را بخوانید!
با requests، می توانیم درخواست های HTTP را برای وب سایت ها ارسال کنیم و پاسخ ها را تجزیه کنیم. در این مورد، میتوانیم از آن برای بازیابی فیدهای RSS آنها (در XML) استفاده کنیم تا BeautifulSoup بتواند آن را تجزیه کند. با pandas، می توانیم داده های تجزیه شده را در یک جدول قالب بندی کنیم و در نهایت محتویات جدول را در یک فایل CSV ذخیره کنیم.
در همان دایرکتوری کار نصب کنید requests و pandas (محیط مجازی شما باید همچنان فعال باشد):
$ pip install requests pandas
در یک فایل جدید، nyt_rss_feed.py، بیایید import کتابخانه های ما:
import requests
from bs4 import BeautifulSoup
import pandas as pd
سپس، بیایید یک درخواست HTTP به سرور نیویورک تایمز برای دریافت فید RSS و بازیابی محتوای آن ارائه کنیم:
url = 'https://rss.nytimes.com/services/xml/rss/nyt/US.xml'
xml_data = requests.get(url).content
با کد بالا، ما توانستیم پاسخی از درخواست HTTP دریافت کنیم و محتوای آن را در آن ذخیره کنیم xml_data متغیر. را requests کتابخانه داده ها را به عنوان برمی گرداند bytes.
اکنون، با کمک BeautifulSoup، تابع زیر را برای تجزیه داده های XML به یک جدول در Pandas ایجاد کنید:
def parse_xml(xml_data):
soup = BeautifulSoup(xml_data, 'xml')
df = pd.DataFrame(columns=('guid', 'title', 'pubDate', 'description'))
all_items = soup.find_all('item')
items_length = len(all_items)
for index, item in enumerate(all_items):
guid = item.find('guid').text
title = item.find('title').text
pub_date = item.find('pubDate').text
description = item.find('description').text
row = {
'guid': guid,
'title': title,
'pubDate': pub_date,
'description': description
}
df = df.append(row, ignore_index=True)
print(f'Appending row %s of %s' % (index+1, items_length))
return df
تابع بالا داده های XML را از یک درخواست HTTP با BeautifulSoup تجزیه می کند و محتوای آن را در یک soup متغیر. Pandas DataFrame با سطرها و ستونهایی برای دادههایی که میخواهیم تجزیه کنیم از طریق df متغیر.
سپس در فایل XML تکرار میکنیم تا همه برچسبها را پیدا کنیم <item>. با تکرار از طریق <item> برچسب ما قادر به استخراج برچسب های فرزندان خود هستیم: <guid>، <title>، <pubDate>، و <description>. توجه داشته باشید که چگونه از آن استفاده می کنیم find() روش برای به دست آوردن فقط یک شی. مقادیر هر تگ فرزند را به جدول پانداها اضافه می کنیم.
حالا در انتهای فایل بعد از تابع، این دو خط کد را برای فراخوانی تابع اضافه کنید و یک فایل CSV ایجاد کنید:
df = parse_xml(xml_data)
df.to_csv('news.csv')
اجرا کن python nyt_rss_feed.py برای ایجاد یک فایل CSV جدید در فهرست کاری فعلی خود:
Appending row 1 of 24
Appending row 2 of 24
...
Appending row 24 of 24
محتویات فایل CSV به شکل زیر است:

توجه داشته باشید: بارگیری داده ها ممکن است کمی بسته به آن طول بکشد روی اتصال اینترنتی شما و خوراک RSS. تجزیه و تحلیل داده ها ممکن است کمی بسته شود روی CPU و منابع حافظه شما نیز. خوراک مورد استفاده ما نسبتاً کوچک است بنابراین باید process به سرعت. لطفاً اگر فوراً نتیجه را مشاهده نکردید صبور باشید.
تبریک، شما با موفقیت یک فید RSS از نیویورک تایمز نیوز را تجزیه و آن را به یک فایل CSV تبدیل کردید!
نتیجه
در این راهنما، یاد گرفتیم که چگونه میتوانیم BeautifulSoup و LXML را برای تجزیه فایلهای XML تنظیم کنیم. ما ابتدا با تجزیه یک فایل XML ساده با داده های معلم تمرین کردیم و سپس فید RSS نیویورک تایمز را تجزیه کردیم و داده های آنها را به یک فایل CSV تبدیل کردیم.
میتوانید از این تکنیکها برای تجزیه XML دیگری که ممکن است با آنها مواجه شوید، استفاده کنید و آنها را به فرمتهای مختلفی که نیاز دارید تبدیل کنید!
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-07 11:22:04
