از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



تشخیص اشیاء سه بعدی (جعبه های محدود کننده سه بعدی) در پایتون با MediaPipe Objectron
سرفصلهای مطلب
معرفی
تشخیص اشیا در حال افزایش است و چندین رویکرد برای حل آن بهبود یافته است. در چند سال گذشته، روشهای مبتنی بر YOLO با پیشرفتهای اخیر مانند YOLOv7 و YOLOv6 (که به طور مستقل پس از YOLOv7 منتشر شد) از نظر دقت و سرعت بهتر از سایرین عمل کردهاند.
با این حال – همه اینها نگران کننده هستند تشخیص اشیاء دو بعدی، که به خودی خود کار دشواری است. اخیراً توانستیم با موفقیت اجرا کنیم تشخیص اشیاء سه بعدیو در حالی که این آشکارسازها هنوز در مرحله ناپایدارتری نسبت به آشکارسازهای شی دو بعدی هستند، دقت آنها در حال افزایش است.
در این راهنما، ما تشخیص اشیاء سه بعدی را در پایتون با Objectron MediaPipe انجام خواهیم داد.
توجه داشته باشید: MediaPipe چارچوب متن باز گوگل برای ساخت خطوط لوله یادگیری ماشینی است process تصاویر، ویدئوها و جریان های صوتی، در درجه اول برای دستگاه های تلفن همراه. هم به صورت داخلی و هم خارجی استفاده می شود و مدل های از پیش آموزش دیده ای را برای کارهای مختلف از جمله تشخیص چهره، مش بندی صورت، تخمین دست و پوس، تقسیم بندی مو، تشخیص اشیا، ردیابی جعبه و غیره ارائه می دهد.
همه اینها میتوانند و برای کارهای پاییندستی مورد استفاده قرار میگیرند – مانند اعمال فیلترها روی چهرهها، فوکوس خودکار دوربین، تأیید بیومتریک، روباتیک کنترلشده با دست، و غیره. بیشتر پروژهها با API برای Android، iOS، C++، Python و JavaScript در دسترس هستند. برخی فقط برای زبان های خاصی در دسترس هستند.
در این راهنما، ما با آن کار خواهیم کرد Objectron MediaPipe، برای اندروید، سی پلاس پلاس، پایتون و جاوا اسکریپت موجود است.
این Objectron راه حل آموزش داده شد روی را مجموعه داده Objectron، که حاوی ویدئوهای شی محور کوتاه است. مجموعه داده فقط شامل 9 شیء است: دوچرخه، کتاب، بطری، دوربین، جعبه غلات، صندلی، فنجان، لپتاپ و کفش، بنابراین یک مجموعه داده خیلی کلی نیست، اما پردازش و تهیه این ویدیوها نسبتاً گران است (ژستهای دوربین، پراکنده نقطه-ابرها، خصوصیات سطوح مسطح، و غیره برای هر فریم از هر ویدیو)، باعث می شود مجموعه داده نزدیک به 2 ترابایت اندازه داشته باشد.
مدل Objectron آموزش دیده (معروف به a راه حل برای پروژه های MediaPipe) آموزش داده شده است روی چهار دسته – کفش، صندلی، لیوان و دوربین.
تشخیص اشیاء دوبعدی از اصطلاح “جعبه های محدود” استفاده می کند، در حالی که آنها در واقع مستطیل هستند. تشخیص اشیاء سه بعدی در واقع پیش بینی می کند جعبه ها در اطراف اجسام، که از آنها می توانید جهت، اندازه، حجم ناهموار و غیره آنها را استنباط کنید. انجام این کار نسبتاً دشواری است. روی، به ویژه با توجه به عدم وجود مجموعه داده های مناسب و هزینه ایجاد آنها. اگرچه مشکل است، اما این مشکل برای افراد مختلف نوید می دهد واقعیت افزوده (AR) برنامه های کاربردی!
راه حل Objectron می تواند در حالت یک مرحله ای یا دو مرحله ای اجرا شود – که در آن حالت یک مرحله ای در تشخیص چندین شی بهتر است، در حالی که حالت دو مرحله ای در تشخیص یک شی اصلی در صحنه بهتر است و به طور قابل توجهی اجرا می شود. سریعتر خط لوله تک مرحله ای از یک ستون فقرات MobileNetV2 استفاده می کند، در حالی که خط لوله دو مرحله ای از API تشخیص اشیاء TensorFlow استفاده می کند.
هنگامی که یک شی در یک ویدیو شناسایی می شود، پیش بینی های بیشتری برای آن انجام نمی شود روی هر فریم به دو دلیل:
- پیشبینیهای پیوسته، بیقراری بالا را ایجاد میکنند (به دلیل تصادفی بودن ذاتی در پیشبینیها)
- اجرای مدل های بزرگ گران است روی هر فریم
این تیم پیشبینیهای سنگین را برای اولین بار فقط برای برخورد بارگذاری میکند و سپس آن جعبه را تا زمانی که جسم مورد نظر هنوز در صحنه است، ردیابی میکند. هنگامی که خط دید شکسته شد و شی دوباره معرفی شد، یک پیش بینی دوباره انجام می شود. این امکان استفاده از مدل های بزرگتر را با دقت بالاتر و در عین حال پایین نگه داشتن نیازهای محاسباتی و کاهش سخت افزار مورد نیاز برای استنتاج بلادرنگ را ممکن می سازد!
بیایید پیش برویم و MediaPipe را نصب کنیم، import راه حل Objectron و آن را روی تصاویر ثابت و فید ویدیویی که مستقیماً از دوربین می آید اعمال کنید.
بیایید ابتدا MediaPipe را نصب کنیم و یک روش کمکی برای واکشی تصاویر از یک URL داده شده آماده کنیم:
$ ! pip install mediapipe
با نصب چارچوب، اجازه دهید import آن را در کنار کتابخانه های رایج:
import mediapipe as mp
import cv2
import numpy as np
import matplotlib.pyplot as plt
بیایید یک روش کمکی برای واکشی تصاویری که یک URL داده شده و یک آرایه RGB را نشان دهنده آن تصویر برمی گرداند، تعریف کنیم:
import PIL
import urllib
def url_to_array(url):
req = urllib.request.urlopen(url)
arr = np.array(bytearray(req.read()), dtype=np.int8)
arr = cv2.imdecode(arr, -1)
arr = cv2.cvtColor(arr, cv2.COLOR_BGR2RGB)
return arr
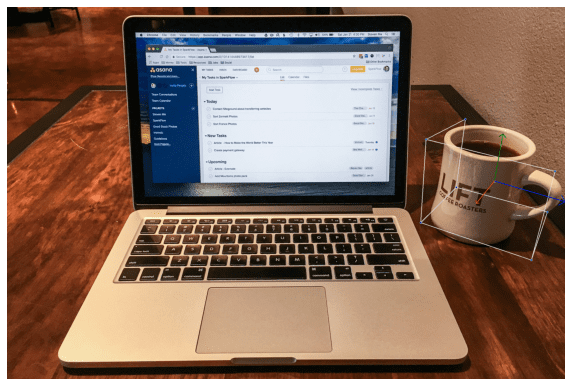
mug = 'https://goodstock.photos/wp-content/uploads/2018/01/Laptop-Coffee-Mug-روی-Table.jpg'
mug = url_to_array(mug)
در نهایت، ما می خواهیم import هم راه حل Objectron و هم ابزارهای طراحی برای تجسم پیش بینی ها:
mp_objectron = mp.solutions.objectron
mp_drawing = mp.solutions.drawing_utils
این Objectron کلاس اجازه می دهد تا چندین آرگومان از جمله:
static_image_mode: چه در یک تصویر یا جریانی از تصاویر تغذیه می کنید (ویدئو)max_num_objects: حداکثر تعداد قابل شناسایی اشیاءmin_detection_confidence: آستانه اطمینان تشخیص (چقدر شبکه باید مطمئن باشد تا یک شی برای کلاس داده شده طبقه بندی شود)model_name: کدام مدل را می خواهید در بین آن بارگذاری کنید'Cup'،'Shoe'،'Camera'و'Chair'.
با در نظر گرفتن آنها – بیایید یک نمونه Objectron و process() تصویر ورودی:
objectron = mp_objectron.Objectron(
static_image_mode=True,
max_num_objects=5,
min_detection_confidence=0.2,
model_name='Cup')
results = objectron.process(mug)
این results شامل نشانه های دوبعدی و سه بعدی شی(های) شناسایی شده و همچنین چرخش، ترجمه و مقیاس برای هر کدام است. ما میتوانیم process نتایج را به دست آورده و با استفاده از نقشه ارائه شده، جعبه های محدود کننده را به راحتی ترسیم کنید utils:
if not results.detected_objects:
print(f'No box landmarks detected.')
annotated_image = mug.copy()
for detected_object in results.detected_objects:
mp_drawing.draw_landmarks(annotated_image,
detected_object.landmarks_2d,
mp_objectron.BOX_CONNECTIONS)
mp_drawing.draw_axis(annotated_image,
detected_object.rotation,
detected_object.translation)
fig, ax = plt.subplots(figsize=(10, 10))
ax.imshow(annotated_image)
ax.axis('off')
plt.show()
این نتیجه در:
 در پایتون با MediaPipe Objectron 1")
یک برنامه هیجان انگیز تر است روی فیلم های! برای قرار دادن ویدیوها، چه از طریق وب کم یا یک فایل ویدیویی موجود، نیازی به تغییر کد زیادی ندارید. OpenCV یک تناسب طبیعی برای خواندن، دستکاری و تغذیه فریم های ویدئویی به مدل Objectron است:
cap = cv2.VideoCapture(0)
objectron = mp_objectron.Objectron(static_image_mode=False,
max_num_objects=5,
min_detection_confidence=0.4,
min_tracking_confidence=0.70,
model_name='Cup')
while cap.isOpened():
success, image = cap.read()
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = objectron.process(image)
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.detected_objects:
for detected_object in results.detected_objects:
mp_drawing.draw_landmarks(image,
detected_object.landmarks_2d,
mp_objectron.BOX_CONNECTIONS)
mp_drawing.draw_axis(image,
detected_object.rotation,
detected_object.translation)
cv2.imshow('MediaPipe Objectron', cv2.flip(image, 1))
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
غیرقابل نوشتن کردن تصویر با image.flags.writeable = False را می سازد process تا حدودی سریعتر اجرا شود و یک تغییر اختیاری است. آخرین cv2.flip() روی تصویر به دست آمده نیز اختیاری است – و به سادگی خروجی را آینه می کند تا کمی بصری تر شود.
هنگام اجرا روی یک دوربین و یک لیوان معمولی جهانی IKEA، نتایج به شرح زیر است:
 در پایتون با MediaPipe Objectron 2")
خروجی کمی لرزان است، اما ترجمه چرخشی را به خوبی انجام می دهد، حتی با دست لرزان دوربین با وضوح پایین. وقتی یک شی از کادر خارج می شود چه اتفاقی می افتد؟
 در پایتون با MediaPipe Objectron 3")
پیشبینیها برای شی در اولین تشخیص متوقف میشوند و ردیابی جعبه به وضوح متوجه میشود که جسم از کادر خارج شده است و به محض اینکه جسم دوباره وارد کادر شد، یک بار دیگر پیشبینی و ردیابی را انجام میدهد. به نظر می رسد که ردیابی زمانی که مدل بتواند آن را ببیند تا حدودی بهتر عمل می کند دسته لیوان، زیرا هنگامی که دسته قابل رویت نیست، خروجی ها لرزش بیشتری دارند (احتمالاً به این دلیل که تشخیص دقیق جهت گیری واقعی لیوان دشوارتر است).
علاوه بر این، به نظر می رسد برخی از زوایا در شرایط نوری چالش برانگیز خروجی های پایدارتری نسبت به سایرین تولید می کنند. مخصوصاً برای لیوانها، به جای دیدن برآمدگی متعامد جسم، به دیدن لبه لیوان کمک میکند.
علاوه بر این، هنگام آزمایش روی یک لیوان شفاف، مدل در تشخیص آن به عنوان یک لیوان مشکل داشت. این احتمالاً نمونه ای از یک است خارج از توزیع چون اکثر لیوان ها مات هستند و رنگ های متنوعی دارند.
نتیجه
تشخیص اشیاء سه بعدی هنوز تا حدودی جوان است و Objectron MediaPipe یک نمایش توانمند است! در حالی که حساس به شرایط نور، انواع شی (شفاف در مقابل لیوان های مات، و غیره) و کمی لرزان – Objectron یک نگاه اجمالی به آنچه که به زودی با دقت و دسترسی بالاتر از همیشه امکان پذیر خواهد بود.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-03 02:36:03
