از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
فایل CSV چیست؟
فایل CSV (مقادیر جدا شده با کاما) فایلی است که از قالب بندی خاصی برای ذخیره داده ها استفاده می کند. این فرمت فایل، اطلاعات را سازماندهی میکند که شامل یک رکورد در هر خط است و هر فیلد (ستون) توسط یک جداکننده از هم جدا شده است. جداکننده که بیشتر استفاده می شود معمولاً کاما است.
این فرمت آنقدر رایج است که در واقع استاندارد شده است RFC 4180. با این حال، این استاندارد همیشه رعایت نمی شود و عدم استفاده از استاندارد جهانی وجود دارد. فرمت دقیق مورد استفاده گاهی اوقات می تواند بستگی داشته باشد روی برنامه ای که برای آن استفاده می شود.
فایلهای CSV معمولاً استفاده میشوند، زیرا خواندن و مدیریت آنها آسان است، اندازه آنها کوچک و سریع هستند. process/انتقال. به دلیل این مزایا، آنها اغلب در برنامه های نرم افزاری استفاده می شوند، از فروشگاه های تجارت الکترونیک آنلاین گرفته تا برنامه های تلفن همراه و ابزارهای دسکتاپ. به عنوان مثال، Magento، یک پلتفرم تجارت الکترونیک، به دلیل آن شناخته شده است پشتیبانی از CSV.
علاوه بر این، می توان از بسیاری از برنامه ها مانند Microsoft Excel، Notepad و Google Docs استفاده کرد import یا export فایل های CSV
این csv ماژول پایتون
این ماژول csv کلاس هایی را برای کار با فایل های CSV پیاده سازی می کند. متمرکز است روی قالبی که مایکروسافت اکسل ترجیح می دهد. با این حال، عملکرد آن به اندازه کافی گسترده است تا با فایل های CSV که از جداکننده ها و کاراکترهای نقل قول مختلف استفاده می کنند، کار کند.
این ماژول توابع را ارائه می دهد reader و writer، که به صورت متوالی کار می کنند. آن را نیز دارد DictReader و DictWriter کلاس هایی برای مدیریت داده های CSV شما در قالب یک شی فرهنگ لغت پایتون.
csv.reader
این csv.reader(csvfile, dialect='excel', **fmtparams) روش را می توان برای استخراج داده ها از فایلی که حاوی داده های با فرمت CSV است استفاده کرد.
پارامترهای زیر را می گیرد:
csvfile: یک شی که از پروتکل iterator پشتیبانی می کند، که در این مورد معمولاً یک شی فایل برای فایل CSV است.dialect(اختیاری): نام لهجه مورد استفاده (که در بخش های بعدی توضیح داده خواهد شد)fmtparams(اختیاری): قالب بندی پارامترهایی که پارامترهای مشخص شده در گویش را بازنویسی می کند
این روش یک شی خواننده را برمی گرداند، که می تواند برای بازیابی خطوط CSV شما تکرار شود. داده ها به صورت لیستی از رشته ها خوانده می شوند. اگر قالب QUOTE_NONNUMERIC را مشخص کنیم، مقادیر غیر نقل قول به مقادیر شناور تبدیل می شوند.
یک مثال روی روش استفاده از این روش در قسمت داده شده است خواندن فایل های CSV بخش این مقاله
csv.writer
این csv.writer(csvfile, dialect='excel', **fmtparams) متد، که شبیه به روش خواننده ای است که در بالا توضیح دادیم، روشی است که به ما امکان می دهد داده ها را در یک فایل با فرمت CSV بنویسیم.
این روش پارامترهای زیر را می گیرد:
csvfile: هر شیء با الفwrite()متد، که در این مورد معمولاً یک شی فایل استdialect(اختیاری): نام گویش مورد استفادهfmtparams(اختیاری): قالب بندی پارامترهایی که پارامترهای مشخص شده در گویش را بازنویسی می کند
یک نکته احتیاط با این روش: اگر csvfile پارامتر مشخص شده یک شی فایل است که باید با آن باز شود newline=''. اگر این مشخص نشده باشد، خطوط جدید داخل فیلدهای نقلشده به درستی تفسیر نمیشوند و بسته به آن روی پلت فرم کار، کاراکترهای اضافی، مانند ‘\r’ ممکن است اضافه شود.
csv.DictReader و csv.DictWriter
این csv ماژول نیز به ما ارائه می دهد DictReader و DictWriter کلاس ها، که به ما امکان خواندن و نوشتن فایل ها با استفاده از اشیاء دیکشنری را می دهند.
کلاس DictReader() به روشی مشابه کار می کند csv.reader، اما در پایتون 2 داده ها را به یک فرهنگ لغت و در پایتون 3 داده ها را به یک دیکشنری نگاشت می کند. OrderedDict. کلیدها با پارامتر فیلد-names داده می شوند.
و درست مثل DictReader، کلاس DictWriter() بسیار شبیه به csv.writer روش، اگرچه فرهنگ لغت را به ردیف های خروجی نگاشت می کند. با این حال، توجه داشته باشید که از آنجایی که دیکشنریهای پایتون مرتب نیستند، نمیتوانیم ترتیب ردیفها را در فایل خروجی پیشبینی کنیم.
هر دوی این کلاس ها شامل یک پارامتر اختیاری برای استفاده از گویش ها هستند.
گویش ها
آ گویش، در زمینه خواندن و نوشتن CSV ها، ساختاری است که به شما امکان می دهد پارامترهای قالب بندی مختلف را برای داده های خود ایجاد، ذخیره و دوباره استفاده کنید.
پایتون دو روش مختلف برای تعیین پارامترهای قالب بندی ارائه می دهد. اولین مورد با اعلان یک زیر کلاس از این کلاس است که شامل ویژگی های خاص است. مورد دوم با مشخص کردن مستقیم پارامترهای قالب بندی، با استفاده از همان نام هایی است که در آن تعریف شده است Dialect کلاس
Dialect چندین ویژگی را پشتیبانی می کند. بیشترین استفاده از آنها عبارتند از:
Dialect.delimiter: به عنوان کاراکتر جداکننده بین فیلدها استفاده می شود. مقدار پیش فرض کاما (،) است.Dialect.quotechar: برای نقل قول فیلدهای حاوی کاراکترهای خاص استفاده می شود. پیش فرض دو نقل قول (“) است.Dialect.lineterminator: برای ایجاد خطوط جدید استفاده می شود. پیش فرض ‘\r\n’ است.
از این کلاس برای گفتن استفاده کنید csv ماژول روش تعامل با داده های CSV غیر استاندارد خود.
نسخه ها
اگر از Python 2.7 استفاده میکنید، یک نکته مهم باید به آن توجه کنید: پشتیبانی از ورودی یونیکد در این نسخه از پایتون به آسانی نیست، بنابراین ممکن است لازم باشد مطمئن شوید که تمام ورودیهای شما به صورت UTF-8 یا نویسههای ASCII قابل چاپ است.
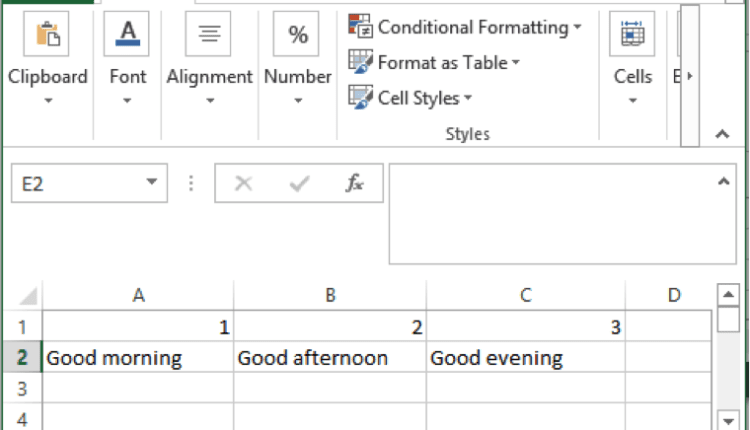
یک نمونه فایل CSV
ما می توانیم یک فایل CSV را به راحتی با یک ویرایشگر متن یا حتی اکسل ایجاد کنیم. در مثال زیر، فایل اکسل دارای ترکیبی از اعداد (1، 2 و 3) و کلمات (صبح بخیر، عصر بخیر، عصر بخیر) است که هر کدام در سلولی متفاوت هستند.

برای ذخیره این فایل به عنوان CSV، کلیک کنید File->Save As، سپس در ذخیره به عنوان پنجره، “مقادیر جدا شده با کاما” را انتخاب کنید (.csv)” زیر قالب کشویی آن را به عنوان ذخیره کنید csvexample.csv برای استفاده بعدی
ساختار فایل CSV را می توان با استفاده از یک ویرایشگر متن، مانند Notepad یا Sublime Text مشاهده کرد. در اینجا، میتوانیم همان مقادیر موجود در فایل اکسل را دریافت کنیم، اما با کاما از هم جدا شدهاند.
1,2,3
Good morning,Good afternoon,Good evening
در مثال های زیر از این فایل استفاده خواهیم کرد.
همچنین میتوانیم جداکننده را به چیزی غیر از کاما تغییر دهیم، مانند اسلش رو به جلو (‘/’). این تغییر را در فایل بالا انجام دهید، تمام کاماها را با اسلش های جلو جایگزین کنید و آن را به عنوان ذخیره کنید. csvexample2.csv برای استفاده بعدی به صورت زیر خواهد بود:
1/2/3
Good morning/Good afternoon/Good evening
این دادههای CSV نیز معتبر است، تا زمانی که از گویش و قالببندی صحیح برای خواندن/نوشتن دادهها استفاده کنیم، که در این مورد به یک جداکننده ‘/’ نیاز دارد.
خواندن فایلهای CSV
یک فایل CSV ساده
در این مثال می خواهیم نشان دهیم که چگونه می توانید آن را بخوانید csvexample.csv فایلی که در قسمت قبل ایجاد و توضیح دادیم. کد به شرح زیر است:
import csv
with open('csvexample.csv', newline='') as myFile:
reader = csv.reader(myFile)
for row in reader:
print(row)
در این کد فایل CSV خود را به صورت باز می کنیم myFile و سپس از csv.reader روش استخراج داده ها در reader شی، که سپس میتوانیم آن را تکرار کنیم تا هر خط از دادههایمان را بازیابی کنیم. برای این مثال، برای نشان دادن اینکه داده ها واقعا خوانده شده اند، فقط print آن را به console.
اگر کد را در فایلی به نام ذخیره کنیم reader.py و ما آن را اجرا می کنیم، نتیجه باید موارد زیر را نشان دهد:
$ python reader.py
('1', '2', '3')
('Good morning', 'Good afternoon', 'Good evening')
همانطور که از اجرای این کد می بینیم، محتویات کد را بدست می آوریم csvexample.csv فایلی که در console، با این تفاوت که اکنون به شکل ساختار یافته ای است که می توانیم راحت تر در کد خود با آن کار کنیم.
تغییر جداکننده
این csv ماژول به ما امکان میدهد فایلهای CSV را بخوانیم، حتی زمانی که برخی از ویژگیهای قالب فایل با قالببندی استاندارد متفاوت است. برای مثال، ما میتوانیم فایلی را با جداکنندههای مختلف بخوانیم، مانند برگهها، نقطهها یا حتی فاصلهها (واقعاً هر کاراکتری). در مثال دیگر ما، csvexample2.csv، برای نشان دادن این موضوع، کاما را با یک اسلش رو به جلو جایگزین کرده ایم.
برای انجام همان کار فوق با این قالب بندی جدید، باید کد را تغییر دهیم تا نشان دهنده جداکننده جدید در حال استفاده باشد. در این مثال ما کد را در فایلی به نام reader2 ذخیره کرده ایم.py. برنامه اصلاح شده به شرح زیر است:
import csv
with open('csvexample2.csv', newline='') as myFile:
reader = csv.reader(myFile, delimiter='/', quoting=csv.QUOTE_NONE)
for row in reader:
print(row)
همانطور که از کد بالا می بینیم، خط سوم کد را با اضافه کردن آن تغییر داده ایم delimiter پارامتر و تخصیص مقدار ‘/’ به آن. این به روش می گوید که همه کاراکترهای ‘/’ را به عنوان نقطه جدایی بین داده های ستون در نظر بگیرد.
ما همچنین پارامتر quoting را اضافه کرده ایم و مقدار آن را به آن اختصاص داده ایم csv.QUOTE_NONE، به این معنی که روش در هنگام تجزیه نباید از نقل قول خاصی استفاده کند. همانطور که انتظار می رود، نتیجه مشابه مثال قبلی است:
$ python reader2.py
('1', '2', '3')
('Good morning', 'Good afternoon', 'Good evening')
همانطور که می بینید، به لطف تغییرات کوچک در کد، ما همچنان همان نتیجه مورد انتظار را دریافت می کنیم.
ایجاد یک گویش
این csv ماژول به ما امکان می دهد یک گویش با ویژگی های خاص فایل CSV خود ایجاد کنیم. بنابراین، همان نتیجه بالا را می توان با کد زیر نیز به دست آورد:
import csv
csv.register_dialect('myDialect', delimiter='/', quoting=csv.QUOTE_NONE)
with open('csvexample2.csv', newline='') as myFile:
reader = csv.reader(myFile, dialect='myDialect')
for row in reader:
print(row)
در اینجا ما گویش نامگذاری شده خودمان را ایجاد و ثبت می کنیم که در این مورد از پارامترهای قالب بندی مشابه قبلی استفاده می کند (اسلش های جلو و بدون نقل قول). سپس مشخص می کنیم csv.reader که میخواهیم از لهجهای که ثبت کردهایم با گذاشتن نام آن به عنوان استفاده کنیم dialect پارامتر.
اگر این کد را در فایلی به نام reader3 ذخیره کنیم.py و آن را اجرا کنید، نتیجه به شرح زیر خواهد بود:
$ python reader3.py
('1', '2', '3')
('Good morning', 'Good afternoon', 'Good evening')
باز هم، این خروجی دقیقاً همان خروجی بالا است، به این معنی که دادههای غیر استاندارد CSV را به درستی تجزیه کردیم.
نوشتن در فایلهای CSV
درست مانند خواندن CSV ها، csv ماژول به طور مناسب قابلیت های زیادی را برای نوشتن داده ها در یک فایل CSV نیز فراهم می کند. این writer شی دو تابع دارد، یعنی writerow() و writerows(). تفاوت بین آنها، همانطور که احتمالاً از روی نام ها می توانید متوجه شوید، این است که تابع اول فقط یک ردیف می نویسد و تابع writerows() چندین ردیف را همزمان می نویسد.
کد در مثال زیر فهرستی از داده ها را ایجاد می کند که هر عنصر در لیست بیرونی نشان دهنده یک ردیف در فایل CSV است. سپس، کد ما یک فایل CSV به نام باز می کند csvexample3.csv، ایجاد می کند writer شی، و داده های ما را با استفاده از عبارت در فایل می نویسد writerows() روش.
import csv
myData = ((1, 2, 3), ('Good Morning', 'Good Evening', 'Good Afternoon'))
myFile = open('csvexample3.csv', 'w')
with myFile:
writer = csv.writer(myFile)
writer.writerows(myData)
فایل حاصل، csvexample3.csv، باید متن زیر را داشته باشد:
1,2,3
Good Morning,Good Evening,Good Afternoon
این writer شی همچنین به سایر فرمت های CSV نیز پاسخ می دهد. مثال زیر یک گویش با ‘/’ به عنوان جداکننده ایجاد می کند و استفاده می کند:
import csv
myData = ((1, 2, 3), ('Good Morning', 'Good Evening', 'Good Afternoon'))
csv.register_dialect('myDialect', delimiter='/', quoting=csv.QUOTE_NONE)
myFile = open('csvexample4.csv', 'w')
with myFile:
writer = csv.writer(myFile, dialect='myDialect')
writer.writerows(myData)
مشابه مثال “خواندن” ما، ما یک گویش را به همین روش ایجاد می کنیم (از طریق csv.register_dialect()) و با مشخص کردن نام از آن به همین ترتیب استفاده کنید.
و دوباره، اجرای کد بالا منجر به خروجی زیر برای جدید ما می شود csvexample4.csv فایل:
1/2/3
Good Morning/Good Evening/Good Afternoon
استفاده از دیکشنری ها
در بسیاری از موارد، داده های ما به صورت یک آرایه دوبعدی فرمت نمی شوند (همانطور که در مثال های قبلی دیدیم)، و اگر کنترل بهتری روی داده هایی که می خوانیم داشته باشیم، خوب خواهد بود. برای کمک به این مشکل، csv ماژول کلاسهای کمکی را ارائه میدهد که به ما امکان میدهد دادههای CSV خود را در/از اشیاء فرهنگ لغت بخوانیم/بنویسیم، که کار با دادهها را بسیار آسانتر میکند.
تعامل با داده های شما به این روش برای اکثر برنامه های پایتون بسیار طبیعی تر است و به لطف آشنایی با dict.
خواندن یک فایل CSV با DictReader
با استفاده از ویرایشگر متن مورد علاقه خود، یک فایل CSV به نام ایجاد کنید countries.csv با محتوای زیر:
country,capital
France,Paris
Italy,Rome
Spain,Madrid
Russia,Moscow
اکنون، قالب این داده ها ممکن است کمی متفاوت از نمونه های قبلی ما به نظر برسد. ردیف اول در این فایل شامل نام فیلد/ستون است که برای هر ستون داده یک برچسب ارائه می کند. سطرهای این فایل شامل جفت مقادیر (کشور، سرمایه) است که با کاما از هم جدا شده اند. این برچسبها اختیاری هستند، اما بسیار مفید هستند، مخصوصاً زمانی که باید خودتان به این دادهها نگاه کنید.
برای خواندن این فایل کد زیر را ایجاد می کنیم:
import csv
with open('countries.csv') as myFile:
reader = csv.DictReader(myFile)
for row in reader:
print(row('country'))
ما همچنان از طریق هر ردیف از دادهها حلقه میزنیم، اما متوجه میشویم که چگونه میتوانیم اکنون به ستونهای هر ردیف با برچسب آنها، که در این مورد کشور است، دسترسی داشته باشیم. اگر می خواستیم می توانستیم به پایتخت هم دسترسی داشته باشیم row('capital').
اجرای کد به صورت زیر می شود:
$ python readerDict.py
France
Italy
Spain
Russia
نوشتن روی یک فایل با DictWriter
ما همچنین می توانیم با استفاده از دیکشنری های خود یک فایل CSV ایجاد کنیم. در کد زیر یک دیکشنری با فیلدهای کشور و پایتخت ایجاد می کنیم. سپس یک را ایجاد می کنیم writer شی که داده ها را در ما می نویسد countries.csv فایل، که دارای مجموعه فیلدهایی است که قبلاً با لیست تعریف شده است myFields.
پس از آن، ابتدا ردیف سرصفحه را با the می نویسیم writeheader() روش، و سپس جفت مقادیر با استفاده از writerow() روش. موقعیت هر مقدار در ردیف با استفاده از برچسب ستون مشخص می شود. احتمالاً میتوانید تصور کنید که وقتی دهها یا حتی صدها ستون در دادههای CSV خود دارید، چقدر مفید است.
import csv
myFile = open('countries.csv', 'w')
with myFile:
myFields = ('country', 'capital')
writer = csv.DictWriter(myFile, fieldnames=myFields)
writer.writeheader()
writer.writerow({'country' : 'France', 'capital': 'Paris'})
writer.writerow({'country' : 'Italy', 'capital': 'Rome'})
writer.writerow({'country' : 'Spain', 'capital': 'Madrid'})
writer.writerow({'country' : 'Russia', 'capital': 'Moscow'})
و در نهایت، اجرای این کد خروجی CSV صحیح را با برچسب ها و همه موارد زیر به ما می دهد:
country,capital
France,Paris
Italy,Rome
Spain,Madrid
Russia,Moscow
نتیجه
فایلهای CSV یک فرمت ذخیرهسازی فایل مفید هستند که بسیاری از توسعهدهندگان در پروژههای خود از آن استفاده میکنند. آنها کوچک، آسان برای مدیریت، و به طور گسترده ای در طول توسعه نرم افزار استفاده می شود. خوشبختانه برای شما، پایتون یک ماژول اختصاصی برای آنها دارد که روش ها و کلاس های انعطاف پذیری را برای مدیریت فایل های CSV به شیوه ای ساده و کارآمد ارائه می دهد.
در این مقاله روش استفاده از آن را به شما نشان دادیم csv ماژول پایتون برای خواندن و نوشتن داده های CSV در یک فایل. علاوه بر این، ما همچنین روش ایجاد گویش ها و استفاده از کلاس های کمکی مانند را نشان دادیم DictReader و DictWriter برای خواندن و نوشتن CSV از/به dict اشیاء.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-30 01:02:07
