از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
وقتی چند سال پیش شروع به یادگیری تجزیه و تحلیل داده ها کردم، اولین چیزی که یاد گرفتم SQL و Pandas بود. به عنوان یک تحلیلگر داده، داشتن یک پایه قوی در کار با SQL و پانداها بسیار مهم است. هر دو ابزار قدرتمندی هستند که به تحلیلگران داده کمک میکنند تا دادههای ذخیرهشده در پایگاههای داده را بهطور کارآمد تحلیل و دستکاری کنند.
مروری بر SQL و پانداها
SQL (زبان پرس و جوی ساختاریافته) یک زبان برنامه نویسی است که برای مدیریت و دستکاری پایگاه داده های رابطه ای استفاده می شود. از سوی دیگر، پانداها یک کتابخانه پایتون است که برای دستکاری و تجزیه و تحلیل داده ها استفاده می شود.
تجزیه و تحلیل داده ها شامل کار با حجم زیادی از داده ها است و از پایگاه های داده اغلب برای ذخیره این داده ها استفاده می شود. SQL و Pandas ابزارهای قدرتمندی را برای کار با پایگاههای داده ارائه میکنند که به تحلیلگران داده اجازه میدهد تا به طور موثر دادهها را استخراج، دستکاری و تجزیه و تحلیل کنند. با استفاده از این ابزارها، تحلیلگران داده می توانند بینش های ارزشمندی از داده ها به دست آورند که در غیر این صورت به دست آوردن آنها دشوار خواهد بود.
در این مقاله، روش استفاده از SQL و Pandas برای خواندن و نوشتن در پایگاه داده را بررسی خواهیم کرد.
اتصال به DB
نصب کتابخانه ها
قبل از اینکه بتوانیم با پانداها به پایگاه داده SQL متصل شویم، ابتدا باید کتابخانه های لازم را نصب کنیم. دو کتابخانه اصلی مورد نیاز Pandas و SQLAlchemy هستند. Pandas یک کتابخانه دستکاری داده محبوب است که امکان ذخیره سازی ساختارهای داده بزرگ را فراهم می کند، همانطور که در مقدمه ذکر شد. در مقابل، SQLAlchemy یک API برای اتصال و تعامل با پایگاه داده SQL فراهم می کند.
ما می توانیم هر دو کتابخانه را با استفاده از مدیریت بسته Python نصب کنیم، pip، با اجرای دستورات زیر در خط فرمان.
$ pip install pandas
$ pip install sqlalchemy
ایجاد ارتباط
با نصب کتابخانه ها، اکنون می توانیم از پانداها برای اتصال به پایگاه داده SQL استفاده کنیم.
برای شروع، یک شی موتور SQLAlchemy را با آن ایجاد می کنیم create_engine(). این create_engine() تابع کد پایتون را به پایگاه داده متصل می کند. به عنوان آرگومان یک رشته اتصال می گیرد که نوع پایگاه داده و جزئیات اتصال را مشخص می کند. در این مثال، از نوع پایگاه داده SQLite و مسیر فایل پایگاه داده استفاده می کنیم.
با استفاده از مثال زیر یک شی موتور برای پایگاه داده SQLite ایجاد کنید:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
اگر فایل پایگاه داده SQLite، student.db در مورد ما، در همان دایرکتوری اسکریپت پایتون باشد، میتوانیم از نام فایل مستقیماً مانند شکل زیر استفاده کنیم.
engine = create_engine('sqlite:///student.db')
خواندن فایل های SQL با پانداها
اکنون که اتصال برقرار کرده ایم، داده ها را بخوانیم. در این بخش به بررسی read_sql، read_sql_table، و read_sql_query توابع و روش استفاده از آنها برای کار با پایگاه داده.
اجرای پرس و جوهای SQL با استفاده از Panda read_sql() تابع
این read_sql() یک تابع کتابخانه Pandas است که به ما امکان می دهد یک پرس و جوی SQL را اجرا کنیم و نتایج را در قالب داده Pandas بازیابی کنیم. این read_sql() تابع SQL و Python را به هم متصل می کند و به ما امکان می دهد از قدرت هر دو زبان استفاده کنیم. تابع بسته می شود read_sql_table() و read_sql_query(). این read_sql() تابع بر اساس مسیریابی داخلی است روی ورودی ارائه شده، به این معنی که اگر ورودی قرار باشد یک پرس و جوی SQL را اجرا کند، به مسیریابی می شود. read_sql_query()، و اگر یک جدول پایگاه داده باشد، به آن روت می شود read_sql_table().
این read_sql() نحو به شرح زیر است:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
پارامترهای SQL و con مورد نیاز است. بقیه اختیاری هستند با این حال، ما می توانیم نتیجه را با استفاده از این پارامترهای اختیاری دستکاری کنیم. بیایید نگاهی دقیق تر به هر پارامتر بیندازیم.
sql: پرس و جوی SQL یا نام جدول پایگاه دادهcon: شیء اتصال یا URL اتصالindex_col: این پارامتر به ما امکان می دهد از یک یا چند ستون از نتیجه پرس و جو SQL به عنوان شاخص قاب داده استفاده کنیم. می تواند یک ستون یا لیستی از ستون ها را بگیرد.coerce_float: این پارامتر مشخص می کند که آیا مقادیر غیر عددی باید به اعداد شناور تبدیل شوند یا به عنوان رشته باقی بمانند. به طور پیش فرض روی true تنظیم شده است. در صورت امکان، مقادیر غیر عددی را به انواع شناور تبدیل می کند.params: پارامترها یک روش امن برای ارسال مقادیر پویا به کوئری SQL ارائه می کنند. میتوانیم از پارامتر params برای ارسال یک فرهنگ لغت، تاپل یا فهرست استفاده کنیم. بسته به روی در پایگاه داده، نحو پارامترها متفاوت است.parse_dates: این به ما امکان می دهد مشخص کنیم کدام ستون در چارچوب داده به عنوان تاریخ تفسیر می شود. این یک ستون، فهرستی از ستونها یا فرهنگ لغت با کلید به عنوان نام ستون و مقدار به عنوان قالب ستون را میپذیرد.columns: این به ما امکان می دهد فقط ستون های انتخاب شده را از لیست واکشی کنیم.chunksize: هنگام کار با یک مجموعه داده بزرگ، اندازه کوچک مهم است. نتیجه پرس و جو را در تکه های کوچکتر بازیابی می کند و عملکرد را افزایش می دهد.
در اینجا مثالی از روش استفاده آورده شده است read_sql():
کد:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype)
engine.dispose()
خروجی:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson (email protected) 2000-02-23
2 Peter Griffen (email protected) 2001-04-15
3 Meg Aniston (email protected) 2001-09-20
Date type of dateOfBirth: datetime64(ns)
پس از اتصال به پایگاه داده، یک کوئری اجرا می کنیم که تمام رکوردها را از روی برمی گرداند Student جدول و آنها را در DataFrame ذخیره می کند df. ستون “Roll Number” با استفاده از این به یک نمایه تبدیل می شود index_col پارامتر، و نوع داده “dateOfBirth” “datetime64(ns)” است به دلیل parse_dates. ما میتوانیم استفاده کنیم read_sql() نه تنها برای بازیابی داده ها بلکه برای انجام عملیات های دیگر مانند درج، حذف و به روز رسانی. read_sql() یک تابع عمومی است.
بارگیری جداول یا نماهای خاص از DB
بارگیری یک جدول یا نمای خاص با پانداها read_sql_table() تکنیک دیگری برای خواندن داده ها از پایگاه داده در قالب داده پاندا است.
چیست read_sql_table?
کتابخانه پانداها را فراهم می کند read_sql_table تابع، که به طور خاص طراحی شده است تا کل جدول SQL را بدون اجرای هیچ کوئری بخواند و نتیجه را به عنوان یک دیتافریم Pandas برگرداند.
نحو از read_sql_table() به شرح زیر است:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
بجز table_name و طرحواره، پارامترها به همان روش توضیح داده شده اند read_sql().
table_name: پارامترtable_nameنام جدول SQL در پایگاه داده است.schema: این پارامتر اختیاری نام طرحواره حاوی نام جدول است.
پس از ایجاد یک اتصال به پایگاه داده، از آن استفاده خواهیم کرد read_sql_table تابع برای بارگذاری Student جدول به یک DataFrame پانداها.
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
df = pd.read_sql_table('Student', engine)
print(df.head())
engine.dispose()
خروجی:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson (email protected) 2000-02-23
1 2 Peter Griffen (email protected) 2001-04-15
2 3 Meg Aniston (email protected) 2001-09-20
ما فرض می کنیم میز بزرگی است که می تواند حافظه فشرده باشد. بیایید بررسی کنیم که چگونه می توانیم از آن استفاده کنیم chunksize پارامتر برای رفع این مشکل
کد:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
df_iterator = pd.read_sql_table('Student', engine, chunksize = 1)
for df in df_iterator:
print(df.head())
engine.dispose()
خروجی:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson (email protected) 2000-02-23
0 2 Peter Griffen (email protected) 2001-04-15
0 3 Meg Aniston (email protected) 2001-09-20
لطفا در نظر داشته باشید که chunksize من از اینجا 1 استفاده می کنم زیرا فقط 3 رکورد در جدول خود دارم.
پرس و جو مستقیماً از DB با سینتکس SQL پانداها
استخراج بینش از پایگاه داده بخش مهمی برای تحلیلگران و دانشمندان داده است. برای انجام این کار، ما از اهرم استفاده خواهیم کرد read_sql_query() تابع.
read_sql_query() چیست؟
استفاده از پانداها read_sql_query() تابع، ما می توانیم پرس و جوهای SQL را اجرا کنیم و نتایج را مستقیماً در یک DataFrame دریافت کنیم. این read_sql_query() تابع به طور خاص برای SELECT بیانیه. نمی توان از آن برای هیچ عملیات دیگری مانند DELETE یا UPDATE.
نحو:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
تمام توضیحات پارامترها مشابه هستند read_sql() تابع. در اینجا یک نمونه از read_sql_query():
کد:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df)
engine.dispose()
خروجی:
firstName lastName
0 Mark Simson
نوشتن فایل های SQL با پانداها
در حین تجزیه و تحلیل دادهها، فرض کنید متوجه شدیم که چند ورودی باید اصلاح شوند یا یک جدول یا نمای جدید با دادهها مورد نیاز است. برای به روز رسانی یا درج یک رکورد جدید، یک روش استفاده از آن است read_sql() و یک پرس و جو بنویسید با این حال، این روش می تواند طولانی باشد. پانداها یک روش عالی به نام ارائه می دهند to_sql() برای موقعیت هایی مانند این
در این قسمت ابتدا یک جدول جدید در پایگاه داده می سازیم و سپس یک جدول موجود را ویرایش می کنیم.
ایجاد یک جدول جدید در پایگاه داده SQL
قبل از ایجاد جدول جدید، اجازه دهید ابتدا بحث کنیم to_sql() به تفصیل
چیست to_sql()?
این to_sql() عملکرد کتابخانه Pandas به ما اجازه می دهد تا پایگاه داده را بنویسیم یا به روز کنیم. این to_sql() تابع می تواند داده های DataFrame را در پایگاه داده SQL ذخیره کند.
نحو برای to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
فقط name و con پارامترها برای اجرا اجباری هستند to_sql(); با این حال، پارامترهای دیگر انعطاف پذیری و گزینه های سفارشی سازی اضافی را فراهم می کنند. بیایید هر پارامتر را به طور مفصل مورد بحث قرار دهیم:
name: نام جدول SQL برای ایجاد یا تغییر.con: هدف اتصال پایگاه داده.schema: طرح واره جدول (اختیاری).if_exists: مقدار پیش فرض این پارامتر “fail” است. این پارامتر به ما این امکان را می دهد که در صورت وجود جدول در مورد اقدامی که باید انجام شود تصمیم گیری کنیم. گزینه ها عبارتند از: “شکست”، “جایگزینی” و “الحاق”.index: پارامتر index یک مقدار بولی را می پذیرد. به طور پیش فرض روی True تنظیم شده است، به این معنی که فهرست DataFrame در جدول SQL نوشته می شود.index_label: این پارامتر اختیاری به ما اجازه می دهد که یک برچسب ستون برای ستون های شاخص تعیین کنیم. بهطور پیشفرض، ایندکس روی جدول نوشته میشود، اما با استفاده از این پارامتر میتوان یک نام خاص داد.chunksize: تعداد ردیف هایی که باید در یک زمان در پایگاه داده SQL نوشته شوند.dtype: این پارامتر یک فرهنگ لغت با کلیدها را به عنوان نام ستون و مقادیر را به عنوان نوع داده آنها می پذیرد.method: پارامتر متد اجازه می دهد تا روش مورد استفاده برای درج داده ها در SQL را مشخص کنید. بهطور پیشفرض، روی None تنظیم شده است، به این معنی که پانداها کارآمدترین راه را بر اساس پیدا خواهند کرد روی پایگاه داده. دو گزینه اصلی برای پارامترهای روش وجود دارد:multi: اجازه درج چند ردیف در یک پرس و جو SQL را می دهد. با این حال، همه پایگاههای داده از درج چند ردیفی پشتیبانی نمیکنند.- تابع قابل فراخوانی: در اینجا می توانیم یک تابع سفارشی برای درج بنویسیم و با استفاده از پارامترهای متد آن را فراخوانی کنیم.
در اینجا یک مثال با استفاده از to_sql():
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
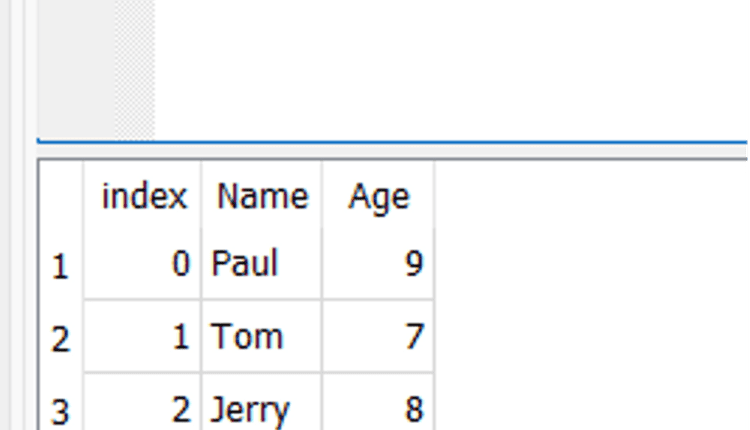
data = {'Name': ('Paul', 'Tom', 'Jerry'), 'Age': (9, 8, 7)}
df = pd.DataFrame(data)
df.to_sql('Customer', con=engine, if_exists='fail')
engine.dispose()
یک جدول جدید به نام مشتری در پایگاه داده ایجاد می شود که دارای دو فیلد به نام های “Name” و “Age” است.
عکس فوری پایگاه داده:

به روز رسانی جداول موجود با فریم های داده پاندا
به روز رسانی داده ها در یک پایگاه داده یک کار پیچیده است، به ویژه هنگامی که با داده های بزرگ سروکار داریم. با این حال، با استفاده از to_sql() عملکرد در پانداها می تواند این کار را بسیار آسان تر کند. برای به روز رسانی جدول موجود در پایگاه داده، to_sql() تابع را می توان با استفاده کرد if_exists پارامتر روی “جایگزینی” تنظیم شده است. با این کار جدول موجود با داده های جدید بازنویسی می شود.
در اینجا یک نمونه از to_sql() که قبلا ایجاد شده را به روز می کند Customer جدول. فرض کنید، در Customer جدول ما می خواهیم سن مشتری به نام Paul را از 9 به 10 به روز کنیم. برای این کار، ابتدا می توانیم ردیف مربوطه را در DataFrame تغییر دهیم و سپس از to_sql() عملکرد به روز رسانی پایگاه داده
کد:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('sqlite:///C/SQLite/student.db')
df = pd.read_sql_table('Customer', engine)
df.loc(df('Name') == 'Paul', 'Age') = 10
df.to_sql('Customer', con=engine, if_exists='replace')
engine.dispose()
در پایگاه داده، سن پل به روز می شود:

نتیجه
در پایان، پانداها و SQL هر دو ابزار قدرتمندی برای کارهای تجزیه و تحلیل داده ها مانند خواندن و نوشتن داده ها در پایگاه داده SQL هستند. Pandas یک راه آسان برای اتصال به پایگاه داده SQL، خواندن داده ها از پایگاه داده در قالب داده Pandas، و نوشتن داده های فریم داده به پایگاه داده ارائه می دهد.
کتابخانه Pandas دستکاری داده ها را در یک دیتافریم آسان می کند، در حالی که SQL یک زبان قدرتمند برای جستجوی داده ها در پایگاه داده ارائه می دهد. استفاده از هر دو پاندا و SQL برای خواندن و نوشتن داده ها می تواند باعث صرفه جویی در زمان و تلاش در کارهای تجزیه و تحلیل داده ها شود، به خصوص زمانی که داده ها بسیار بزرگ هستند. به طور کلی، استفاده از SQL و پانداها با هم می تواند به تحلیلگران داده و دانشمندان کمک کند تا گردش کار خود را ساده کنند.
(برچسبها به ترجمه)# python
منتشر شده در 1402-12-31 09:56:04
