از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



زمان لازم برای مطالعه: 2 دقیقه
خوشه بندی سلسله مراتبی تجمعی یک الگوریتم یادگیری بدون نظارت است که نقاط داده را بر اساس پیوند می دهد. روی فاصله را برای تشکیل یک خوشه، و سپس آن نقاط از قبل خوشهبندی شده را به یک خوشه دیگر پیوند میدهد و ساختاری از خوشهها را با خوشههای فرعی ایجاد میکند.
با استفاده از Scikit-Learn که قبلاً روشهای پیوند تک، متوسط، کامل و بخش را در دسترس دارد، به راحتی پیادهسازی میشود.
اگر میخواهید یک راهنمای عمیق برای خوشهبندی سلسله مراتبی بخوانید، خوشهبندی سلسله مراتبی ما را با Python و Scikit-Learn بخوانید”!
برای تجسم ساختار سلسله مراتبی خوشه ها، می توانید بارگذاری کنید پنگوئن های پالمر مجموعه دادهها، ستونهایی را انتخاب کنید که خوشهبندی میشوند و از SciPy برای رسم دندروگرام از زیر خوشهها استفاده کنید.
توجه داشته باشید: می توانید مجموعه داده را از اینجا دانلود کنید ارتباط دادن.
اجازه دهید import کتابخانه ها و بارگذاری مجموعه داده پنگوئن ها، برش آن به ستون های انتخاب شده و رها کردن ردیف هایی با داده های از دست رفته (فقط 2 مورد وجود دارد):
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster import hierarchy
df = pd.read_csv('penguins.csv')
print(df.shape)
df = df(('bill_length_mm', 'flipper_length_mm'))
df = df.dropna(axis=0)
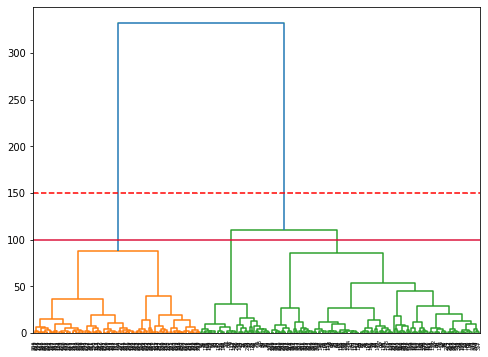
ما می توانیم از SciPy استفاده کنیم hierarchy.linkage() برای تشکیل خوشه ها و رسم آنها hierarchy.dendrogram():
clusters = hierarchy.linkage(df, method="ward")
plt.figure(figsize=(8, 6))
dendrogram = hierarchy.dendrogram(clusters)
plt.axhline(150, color='red', linestyle='--');
plt.axhline(100, color='crimson');

این مثال نشان می دهد که چگونه دندروگرام زمانی که برای انتخاب تعداد خوشه ها استفاده می شود تنها یک مرجع است. ما قبلاً می دانیم که ما 3 نوع پنگوئن در مجموعه داده داریم، اما اگر بخواهیم تعداد آنها را با دندروگرام تعیین کنیم، 2 گزینه اول و 3 گزینه دوم ما خواهد بود.
اکنون، بیایید با Scikit-Learn خوشهبندی تجمعی را انجام دهیم تا برچسبهای خوشهای را برای سه نوع پنگوئن پیدا کنیم:
clustering_model = AgglomerativeClustering(n_clusters=3, linkage="ward")
clustering_model.fit(df)
labels = clustering_model.labels_
و داده ها را قبل و بعد از خوشه بندی انباشته با 3 خوشه رسم کنید:
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15,5))
sns.scatterplot(ax=axes(0), data=df, x='bill_length_mm', y='flipper_length_mm').set_title('Without clustering')
sns.scatterplot(ax=axes(1), data=df, x='bill_length_mm', y='flipper_length_mm', hue=clustering_model.labels_).set_title('With clustering');

هنگام استفاده از خوشهبندی تجمعی، نیازی به تعیین تعداد خوشهها ندارید. همانطور که در دندروگرام دیدیم، اگر تعداد خوشه های مورد نظر خود را تعیین نکنیم، الگوریتم معمولا نقاط را به 2 خوشه تقسیم می کند.
بیایید خوشهبندی انبوهی را بدون مشخص کردن تعداد خوشهها امتحان کنیم و دادهها را بدون خوشهبندی تجمعی با 3 خوشه و بدون خوشههای از پیش تعریفشده رسم کنیم:
clustering_model_no_clusters = AgglomerativeClustering(linkage="ward")
clustering_model_no_clusters.fit(df)
labels_no_clusters = clustering_model_no_clusters.labels_
و در نهایت، بیایید داده ها را بدون خوشه بندی تجمعی، با 3 خوشه و بدون خوشه های از پیش تعریف شده رسم کنیم:
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15,5))
sns.scatterplot(ax=axes(0), data=df, x='bill_length_mm', y='flipper_length_mm').set_title('Without clustering')
sns.scatterplot(ax=axes(1), data=df, x='bill_length_mm', y='flipper_length_mm', hue=clustering.labels_).set_title('With 3 clusters')
sns.scatterplot(ax=axes(2), data=df, x='bill_length_mm', y='flipper_length_mm', hue=clustering_model_no_clusters.labels_).set_title('Without choosing number of clusters');

(برچسبها به ترجمه)# python
منتشر شده در 1403-01-05 10:26:03
