از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
درخت تصمیم یکی از متداولترین و پرکاربردترین الگوریتمهای یادگیری ماشینی تحت نظارت است که میتواند هم وظایف رگرسیون و هم طبقهبندی را انجام دهد. شهود پشت الگوریتم درخت تصمیم ساده و در عین حال بسیار قدرتمند است.
برای هر ویژگی در مجموعه داده، درخت تصمیم الگوریتم اشکال الف node، جایی که مهمترین ویژگی در قسمت قرار می گیرد root node. برای ارزیابی ما از این شروع می کنیم root node و با دنبال کردن موارد مربوطه، به سمت پایین درخت حرکت کنیم node که شرایط یا “تصمیم” ما را برآورده می کند. این process تا یک برگ ادامه دارد node رسیده است که حاوی پیش بینی یا نتیجه درخت تصمیم است.
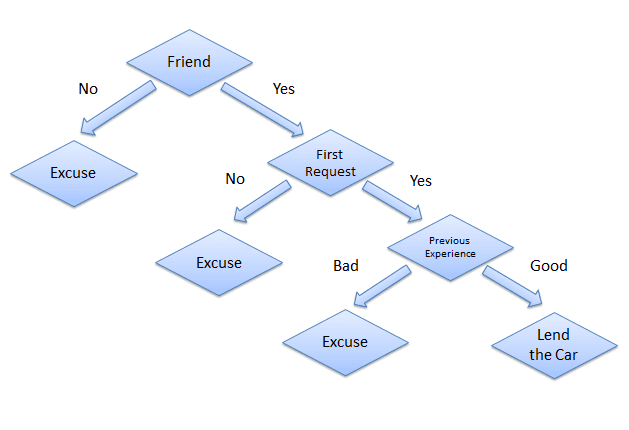
این ممکن است در ابتدا کمی پیچیده به نظر برسد، اما چیزی که احتمالاً متوجه نمیشوید این است که در تمام زندگی خود از درختهای تصمیمگیری برای تصمیمگیری استفاده کردهاید، حتی بدون اینکه بدانید. سناریویی را در نظر بگیرید که در آن شخصی از شما می خواهد ماشین خود را برای یک روز به آنها قرض دهید و شما باید تصمیم بگیرید که آیا خودرو را به آنها قرض دهید یا نه. عوامل متعددی وجود دارد که به تعیین تصمیم شما کمک می کند که برخی از آنها در زیر ذکر شده است:
- آیا این شخص دوست صمیمی است یا فقط یک آشنا؟ اگر آن شخص فقط یک آشنا است، درخواست را رد کنید. اگر آن شخص دوست است، به مرحله بعدی بروید.
- آیا شخصی برای اولین بار است که ماشین را می خواهد؟ اگر چنین است، ماشین را به آنها قرض دهید، در غیر این صورت به مرحله بعدی بروید.
- آخرین باری که ماشین را پس دادند ماشین آسیب دید؟ اگر بله، درخواست را رد کنید. اگر نه، ماشین را به آنها قرض دهید.
درخت تصمیم برای سناریوی فوق به صورت زیر است:

مزایای درختان تصمیم
چندین مزیت استفاده از درخت های تصمیم برای تحلیل پیش بینی وجود دارد:
- درختهای تصمیم را میتوان برای پیشبینی مقادیر پیوسته و گسسته استفاده کرد، یعنی هم برای وظایف رگرسیون و هم برای طبقهبندی به خوبی کار میکنند.
- آنها به تلاش نسبتاً کمتری برای آموزش الگوریتم نیاز دارند.
- آنها می توانند برای طبقه بندی داده های غیرخطی قابل تفکیک استفاده شوند.
- آنها در مقایسه با KNN و سایر الگوریتم های طبقه بندی بسیار سریع و کارآمد هستند.
پیاده سازی درخت تصمیم با پایتون Scikit-Learn
در این بخش الگوریتم درخت تصمیم را با استفاده از پایتون پیاده سازی می کنیم Scikit-Learn کتابخانه در مثالهای زیر، مسائل طبقهبندی و رگرسیون را با استفاده از درخت تصمیم حل خواهیم کرد.
توجه داشته باشید: هر دو وظیفه طبقه بندی و رگرسیون در الف اجرا شد Jupyter نوت بوک آی پایتون.
1. درخت تصمیم برای طبقه بندی
در این بخش، با توجه به چهار ویژگی مختلف تصویر اسکناس، اعتبار یا جعلی بودن اسکناس را پیشبینی میکنیم. ویژگی ها عبارتند از واریانس تصویر تبدیل موجک، کشیدگی تصویر، آنتروپی و چولگی تصویر.
مجموعه داده
مجموعه داده این کار را می توانید از این لینک دانلود کنید:
https://drive.google.com/open؟id=13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt
برای اطلاعات دقیق تر در مورد این مجموعه داده، بررسی کنید مخزن UCI ML برای این مجموعه داده
بقیه مراحل پیاده سازی این الگوریتم در Scikit-Learn ما با هر مشکل یادگیری ماشین معمولی یکسان هستند import کتابخانه ها و مجموعه داده ها، تجزیه و تحلیل داده ها را انجام می دهند، داده ها را به مجموعه های آموزشی و آزمایشی تقسیم می کنند، الگوریتم را آموزش می دهند، پیش بینی می کنند و در نهایت عملکرد الگوریتم را ارزیابی می کنیم. روی مجموعه داده ما
واردات کتابخانه ها
اسکریپت زیر کتابخانه های مورد نیاز را وارد می کند:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
وارد کردن مجموعه داده
از آنجایی که فایل ما با فرمت CSV است، از پاندا استفاده خواهیم کرد read_csv روش خواندن فایل داده CSV ما. برای این کار اسکریپت زیر را اجرا کنید:
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")
در این مورد فایل bill_authentication.csv در پوشه “Datasets” درایو “D” قرار دارد. شما باید این مسیر را با توجه به تنظیمات سیستم خود تغییر دهید.
تحلیل داده ها
دستور زیر را برای مشاهده تعداد سطرها و ستون های مجموعه داده ما اجرا کنید:
dataset.shape
خروجی “(1372,5)” را نشان می دهد، به این معنی که مجموعه داده ما دارای 1372 رکورد و 5 ویژگی است.
دستور زیر را برای بازرسی پنج رکورد اول مجموعه داده اجرا کنید:
dataset.head()
خروجی به شکل زیر خواهد بود:
| واریانس | چولگی | کورتوز | آنتروپی | کلاس | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.6661 | -2.8073 | -0.44699 | 0 |
| 1 | 4.54590 | 8.1674 | -2.4586 | -1.46210 | 0 |
| 2 | 3.86600 | -2.6383 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.5228 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.4552 | 4.5718 | -0.98880 | 0 |
آماده سازی داده ها
در این بخش دادههای خود را به ویژگیها و برچسبها تقسیم میکنیم و سپس دادههای حاصل را به مجموعههای آموزشی و آزمایشی تقسیم میکنیم. با این کار می توانیم الگوریتم خود را آموزش دهیم روی یک مجموعه داده و سپس آن را آزمایش کنید روی مجموعه ای کاملاً متفاوت از داده ها که الگوریتم هنوز ندیده است. این به شما دید دقیق تری از روش عملکرد الگوریتم آموزش دیده شما ارائه می دهد.
برای تقسیم داده ها به ویژگی ها و برچسب ها، کد زیر را اجرا کنید:
X = dataset.drop('Class', axis=1)
y = dataset('Class')
اینجا X متغیر شامل تمام ستون های مجموعه داده است، به جز ستون “Class” که همان برچسب است. این y متغیر حاوی مقادیر ستون “Class” است. این X متغیر مجموعه ویژگی ما و the است y متغیر حاوی برچسب های مربوطه است.
آخرین مرحله پیش پردازش، تقسیم داده های ما به مجموعه های آموزشی و آزمایشی است. این model_selection کتابخانه از Scikit-Learn شامل train_test_split روشی که از آن برای تقسیم تصادفی داده ها به مجموعه های آموزشی و آزمایشی استفاده می کنیم. برای این کار کد زیر را اجرا کنید:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
در کد بالا، test_size پارامتر نسبت مجموعه تست را مشخص می کند که از آن برای تقسیم 20% داده ها به مجموعه تست و 80% برای آموزش استفاده می کنیم.
آموزش و پیش بینی
هنگامی که داده ها به مجموعه های آموزشی و آزمایشی تقسیم شدند، مرحله نهایی آموزش الگوریتم درخت تصمیم است. روی این داده ها و پیش بینی. Scikit-Learn شامل tree کتابخانه، که شامل کلاسها/روشهای داخلی برای الگوریتمهای درخت تصمیمگیری مختلف است. از آنجایی که ما در اینجا قرار است یک کار طبقه بندی را انجام دهیم، از آن استفاده خواهیم کرد DecisionTreeClassifier کلاس برای این مثال این fit متد این کلاس برای آموزش الگوریتم فراخوانی می شود روی داده های آموزشی که به عنوان پارامتر به fit روش. برای آموزش الگوریتم اسکریپت زیر را اجرا کنید:
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
اکنون که طبقه بندی کننده ما آموزش دیده است، بیایید پیش بینی کنیم روی داده های تست برای پیش بینی، predict روش از DecisionTreeClassifier کلاس استفاده می شود. برای استفاده به کد زیر توجه کنید:
y_pred = classifier.predict(X_test)
ارزیابی الگوریتم
در این مرحله ما الگوریتم خود را آموزش داده ایم و برخی پیش بینی ها را انجام داده ایم. اکنون خواهیم دید که الگوریتم ما چقدر دقیق است. برای وظایف طبقه بندی، برخی از معیارهای رایج مورد استفاده قرار می گیرند ماتریس سردرگمی، دقت، یادآوری و امتیاز F1. برای ما خوش شانس Scikit=-Learn’s metrics کتابخانه شامل classification_report و confusion_matrix روش هایی که می توان برای محاسبه این معیارها برای ما استفاده کرد:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
این ارزیابی زیر را ایجاد می کند:
((142 2)
2 129))
precision recall f1-score support
0 0.99 0.99 0.99 144
1 0.98 0.98 0.98 131
avg / total 0.99 0.99 0.99 275
از ماتریس سردرگمی، می توانید ببینید که از 275 نمونه آزمایشی، الگوریتم ما تنها 4 مورد را اشتباه طبقه بندی کرده است. این دقت 98.5 درصد است. نه خیلی بد!
2. درخت تصمیم برای رگرسیون
این process حل مسائل رگرسیون با درخت تصمیم با استفاده از Scikit-Learn بسیار شبیه به طبقه بندی است. با این حال برای رگرسیون ما استفاده می کنیم DecisionTreeRegressor کلاس کتابخانه درختی همچنین معیارهای ارزیابی برای رگرسیون با معیارهای طبقه بندی متفاوت است. بقیه ی process تقریباً یکسان است
مجموعه داده
مجموعه داده ای که برای این بخش استفاده خواهیم کرد همان است که در مقاله رگرسیون خطی استفاده کردیم. ما از این مجموعه داده برای پیشبینی مصرف گاز (به میلیونها گالن) در 48 ایالت ایالات متحده بر اساس مالیات بر گاز (به سنت)، درآمد سرانه (دلار)، بزرگراههای آسفالت شده (بر حسب مایل) و نسبت جمعیت با گواهینامه رانندگی.
مجموعه داده در این لینک موجود است:
https://drive.google.com/open؟id=1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_
جزئیات مجموعه داده را می توان از قسمت پیدا کرد منبع اصلی.
دو ستون اول در مجموعه داده فوق هیچ اطلاعات مفیدی ارائه نمی دهند، بنابراین از فایل مجموعه داده حذف شده اند.
حالا بیایید الگوریتم درخت تصمیم خود را اعمال کنیم روی این داده ها را امتحان کنید و مصرف گاز را از این داده ها پیش بینی کنید.
واردات کتابخانه ها
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
وارد کردن مجموعه داده
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')
تحلیل داده ها
ما دوباره استفاده خواهیم کرد head عملکرد دیتافریم برای دیدن اینکه داده های ما واقعاً چه شکلی هستند:
dataset.head()
خروجی به شکل زیر است:
| بنزین_مالیات | درآمد متوسط | سنگفرش_بزرگراه | جمعیت_گواهی_راننده(%) | بنزین_مصرف | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 | 0.525 | 541 |
| 1 | 9.0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9.0 | 3865 | 1586 | 0.580 | 561 |
| 3 | 7.5 | 4870 | 2351 | 0.529 | 414 |
| 4 | 8.0 | 4399 | 431 | 0.544 | 410 |
برای مشاهده جزئیات آماری مجموعه داده، دستور زیر را اجرا کنید:
dataset.describe()
| بنزین_مالیات | درآمد متوسط | سنگفرش_بزرگراه | جمعیت_گواهی_راننده(%) | بنزین_مصرف | |
|---|---|---|---|---|---|
| شمردن | 48.000000 | 48.000000 | 48.000000 | 48.000000 | 48.000000 |
| منظور داشتن | 7.668333 | 4241.833333 | 5565.416667 | 0.570333 | 576.770833 |
| std | 0.950770 | 573.623768 | 3491.507166 | 0.055470 | 111.885816 |
| دقیقه | 5.000000 | 3063.000000 | 431.000000 | 0.451000 | 344.000000 |
| 25% | 7.000000 | 3739.000000 | 3110.250000 | 0.529750 | 509.500000 |
| 50% | 7.500000 | 4298.000000 | 4735.500000 | 0.564500 | 568.500000 |
| 75% | 8.125000 | 4578.750000 | 7156.000000 | 0.595250 | 632.750000 |
| حداکثر | 10.00000 | 5342.000000 | 17782.000000 | 0.724000 | 986.000000 |
آماده سازی داده ها
همانند کار طبقهبندی، در این بخش دادههای خود را به ویژگیها و برچسبها و در نتیجه به مجموعههای آموزشی و آزمایشی تقسیم میکنیم.
دستورات زیر را برای تقسیم داده ها به برچسب ها و ویژگی ها اجرا کنید:
X = dataset.drop('Petrol_Consumption', axis=1)
y = dataset('Petrol_Consumption')
اینجا X متغیر شامل تمام ستون های مجموعه داده است، به جز ستون “Petrol_Consumption” که همان برچسب است. این y متغیر حاوی مقادیری از ستون “Petrol_Consumption” است، به این معنی که X متغیر شامل مجموعه ویژگی و y متغیر حاوی برچسب های مربوطه است.
کد زیر را اجرا کنید تا داده های خود را به مجموعه های آموزشی و آزمایشی تقسیم کنید:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
آموزش و پیش بینی
همانطور که قبلا ذکر شد، برای یک کار رگرسیون از یک متفاوت استفاده می کنیم sklearn کلاس نسبت به کار طبقه بندی. کلاسی که ما در اینجا استفاده خواهیم کرد این است DecisionTreeRegressor کلاس، بر خلاف DecisionTreeClassifier از قبل.
برای آموزش درخت، ما آن را نمونهسازی میکنیم DecisionTreeRegressor کلاس و تماس بگیرید fit روش:
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor()
regressor.fit(X_train, y_train)
برای پیش بینی روی مجموعه تست، از predict روش:
y_pred = regressor.predict(X_test)
حال بیایید برخی از مقادیر پیش بینی شده خود را با مقادیر واقعی مقایسه کنیم و ببینیم چقدر دقیق بوده ایم:
df=pd.DataFrame({'Actual':y_test, 'Predicted':y_pred})
df
خروجی به شکل زیر است:
| واقعی | پیش بینی کرد | |
|---|---|---|
| 41 | 699 | 631.0 |
| 2 | 561 | 524.0 |
| 12 | 525 | 510.0 |
| 36 | 640 | 704.0 |
| 38 | 648 | 524.0 |
| 9 | 498 | 510.0 |
| 24 | 460 | 510.0 |
| 13 | 508 | 603.0 |
| 35 | 644 | 631.0 |
به یاد داشته باشید که در مورد شما رکوردها ممکن است متفاوت باشد، بسته به تقسیم بندی آموزش و آزمایش. از آنجا که train_test_split روش بهطور تصادفی دادههایی را تقسیم میکند که احتمالاً مجموعههای آموزشی و آزمایشی مشابهی نداریم.
ارزیابی الگوریتم
برای ارزیابی عملکرد الگوریتم رگرسیون، معیارهای رایج مورد استفاده قرار می گیرند به معنای خطای مطلق، خطای میانگین مربعات، و root خطای میانگین مربعات. این Scikit-Learn کتابخانه شامل توابعی است که می تواند به محاسبه این مقادیر برای ما کمک کند. برای انجام این کار، از این کد از metrics بسته:
from sklearn import metrics
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
خروجی باید چیزی شبیه به این باشد:
Mean Absolute Error: 54.7
Mean Squared Error: 4228.9
Root Mean Squared Error: 65.0299930801
میانگین خطای مطلق برای الگوریتم ما 54.7 است که کمتر از 10 درصد از میانگین همه مقادیر در Petrol_Consumption ستون این بدان معناست که الگوریتم ما کار پیش بینی خوبی را انجام داده است.
نتیجه
در این مقاله نشان دادیم که چگونه می توانید از محبوب پایتون استفاده کنید Scikit-Learn کتابخانه برای استفاده از درخت های تصمیم برای کارهای طبقه بندی و رگرسیون. در حالی که به خودی خود یک الگوریتم نسبتاً ساده است، پیاده سازی درختان تصمیم با Scikit-Learn حتی راحت تر است
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-28 06:34:03
