از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
در عصر کنونی که علم داده / هوش مصنوعی در حال رونق است، درک چگونگی استفاده از یادگیری ماشینی در صنعت برای حل مشکلات پیچیده تجاری مهم است. به منظور انتخاب مدل یادگیری ماشینی که باید در تولید استفاده شود، یک معیار انتخاب انتخاب میشود که بر اساس آن مدلهای مختلف یادگیری ماشین امتیازدهی میشوند.
یکی از پرکاربردترین معیارهای امروزه این است AUC-ROC منحنی (Area Under Curve – Receiver Operating Charteristics). وقتی درک خوبی از ماتریس سردرگمی و انواع مختلف خطاها وجود دارد، درک و ارزیابی منحنیهای ROC بسیار آسان است.
در این مقاله به توضیح موضوعات زیر می پردازم:
- مقدمه ای بر ماتریس سردرگمی و آمارهای مختلف محاسبه شده روی آی تی
- تعاریف TP، FN، TN، FP
- خطاهای نوع 1 و نوع 2
- آمار محاسبه شده از Recall، Precision، F-Score
- مقدمه ای بر منحنی AUC ROC
- سناریوهای مختلف با منحنی ROC و انتخاب مدل
- مثالی از منحنی ROC با پایتون
مقدمه ای بر ماتریس سردرگمی
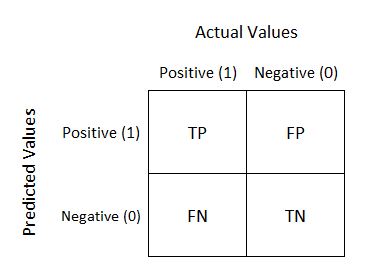
به منظور نمایش برچسبهای کلاس پیشبینیشده و واقعی از مدلهای یادگیری ماشین، ماتریس سردرگمی استفاده می شود. اجازه دهید مثالی از یک مشکل طبقه بندی کلاس دودویی بیاوریم.

کلاس با برچسب 1، کلاس مثبت در مثال ما است. کلاس با برچسب 0 کلاس منفی در اینجا است. همانطور که می بینیم، مقادیر واقعی مثبت و منفی به عنوان ستون نشان داده می شوند، در حالی که مقادیر پیش بینی شده به عنوان ردیف نشان داده می شوند.
تعاریف TP، FP، TN و FN
اجازه دهید اصطلاحاتی را که اغلب در درک منحنی های ROC استفاده می کنیم، درک کنیم:
- TP = مثبت واقعی – مدل کلاس مثبت را به درستی پیشبینی میکند تا یک کلاس مثبت باشد.
- FP = مثبت کاذب – مدل کلاس منفی را به اشتباه پیشبینی میکند که یک کلاس مثبت است.
- FN = منفی کاذب – مدل کلاس مثبت را به اشتباه پیشبینی کرد که کلاس منفی است.
- TN = منفی واقعی – مدل کلاس منفی را به درستی پیشبینی کرد که کلاس منفی باشد.
خطاهای نوع 1 و نوع 2
دو نوع خطا وجود دارد که در اینجا قابل شناسایی است:
-
خطای نوع 1: مدل نمونه را به عنوان یک کلاس مثبت پیش بینی کرد، اما نادرست است. این مثبت کاذب (FP) است.
-
خطای نوع 2: مدل نمونه را کلاس Negative پیش بینی کرد، اما آیا درست نیست؟ این منفی کاذب (FN) است.
آمار محاسبه شده از ماتریس سردرگمی
به منظور ارزیابی مدل، برخی حقایق/آمار اساسی از نمایش ماتریس سردرگمی محاسبه میشوند.

Source: https://commons.wikimedia.org/wiki/File:Precisionrecall.svg
به خاطر آوردن: از بین تمام طبقات مثبت، چند نمونه به درستی شناسایی شد.
Recall = TP / (TP + FN)
دقت، درستی: از بین تمام موارد مثبت پیش بینی شده، چند مورد به درستی پیش بینی شده است.
Precision = TP / (TP + FP)
امتیاز اف: از Precision and Recall، F-Measure محاسبه می شود و گاهی اوقات به عنوان معیار استفاده می شود. F – اندازه گیری چیزی نیست جز میانگین هارمونیک Precision و Recall.
F-Score = (2 * Recall * Precision) / (Recall + Precision)
مقدمه ای بر AUC – ROC Curve
منحنی AUC-ROC معیار انتخاب مدل برای مسائل طبقه بندی باینری/چند کلاس است. ROC یک منحنی احتمال برای کلاس های مختلف است. ROC به ما می گوید که چقدر این مدل برای تشخیص کلاس های داده شده از نظر احتمال پیش بینی شده خوب است.
یک منحنی ROC معمولی دارای نرخ مثبت کاذب (FPR) است. روی محور X و نرخ مثبت واقعی (TPR) روی محور Y

ناحیه تحت پوشش منحنی، ناحیه بین خط نارنجی (ROC) و محور است. این منطقه تحت پوشش AUC است. هرچه منطقه تحت پوشش بزرگتر باشد، مدل های یادگیری ماشینی در تشخیص کلاس های داده شده بهتر هستند. مقدار ایده آل برای AUC 1 است.
سناریوهای مختلف با منحنی ROC و انتخاب مدل
سناریوی شماره 1 (بهترین سناریوی موردی)
برای هر مدل طبقه بندی، بهترین سناریو زمانی است که تمایز واضحی بین این دو / همه کلاس ها وجود داشته باشد.

نمودار بالا احتمال کلاس پیش بینی شده را برای هر دو کلاس 0 و 1 نشان می دهد. آستانه 0.5 است که به این معنی است که اگر احتمال پیش بینی شده کلاس برای یک نمونه کمتر از 0.5 باشد، آن نمونه به عنوان نمونه ای از کلاس 0 پیش بینی می شود. احتمال کلاس برای یک نمونه برابر یا بیشتر از 0.5 است، نمونه به عنوان نمونه کلاس 1 طبقه بندی می شود.
منحنی AUC-ROC برای این مورد به صورت زیر است.

همانطور که در اینجا می بینیم، ما یک تمایز واضح بین دو کلاس داریم، در نتیجه ما AUC 1 را داریم. حداکثر مساحت بین منحنی ROC و خط پایه در اینجا به دست می آید.
سناریوی شماره 2 (حدس تصادفی)
در صورتی که هر دو توزیع کلاس به سادگی از یکدیگر تقلید کنند، AUC 0.5 است. به عبارت دیگر، مدل ما برای نمونه ها و طبقه بندی آنها 50 درصد دقیق است. مدل در این مورد اصلاً قابلیت تبعیض ندارد.

می بینیم که هیچ تبعیض آشکاری بین این دو طبقه وجود ندارد.

از نمودار منحنی ROC AUC مشهود است که مساحت بین ROC و محور 0.5 است. این هنوز بدترین مدل نیست، اما یک حدس تصادفی میدهد، درست مانند یک انسان.
سناریوی شماره 3 (بدترین سناریو)
اگر مدل کلاس ها را کاملاً اشتباه طبقه بندی کند، بدترین حالت است.

کاملا برعکس بهترین حالت (سناریوی شماره 1)، در این حالت، تمام نمونه های کلاس 1 به اشتباه به عنوان کلاس 0 و تمام نمونه های کلاس 0 به اشتباه به عنوان کلاس 1 طبقه بندی می شوند.

در نتیجه، AUC را 0 دریافت می کنیم که بدترین حالت ممکن است.
سناریوی شماره 4 (صنعت / سناریوی عادی)
در یک سناریوی صنعتی معمول، بهترین موارد هرگز مشاهده نمی شود. ما هرگز تمایز واضحی بین این دو طبقه نمییابیم.

در این مورد، همانطور که مشاهده شد، مقداری همپوشانی داریم که خطاهای نوع 1 و نوع 2 را به پیش بینی مدل معرفی می کند. در این مورد ما AUC را بین 0.5 و 1 دریافت می کنیم.
مثال با پایتون
اجازه دهید نمونهای از منحنیهای ROC را با مقداری داده و یک طبقهبندی کننده در عمل ببینیم!
مرحله 1: وارد کردن کتابخانه ها
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
مرحله 2: تعریف a python تابع رسم منحنی های ROC.
def plot_roc_curve(fpr, tpr):
plt.plot(fpr, tpr, color='orange', label='ROC')
plt.plot((0, 1), (0, 1), color='darkblue', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend()
plt.show()
مرحله 3: داده های نمونه تولید کنید.
data_X, class_label = make_classification(n_samples=1000, n_classes=2, weights=(1,1), random_state=1)
مرحله 4: داده ها را به زیر مجموعه های آموزش و آزمایش تقسیم کنید.
trainX, testX, trainy, testy = train_test_split(data_X, class_label, test_size=0.3, random_state=1)
مرحله 5: یک مدل را بچینید روی داده های قطار
model = RandomForestClassifier()
model.fit(trainX, trainy)
مرحله 6: پیش بینی احتمالات برای داده های آزمون.
probs = model.predict_proba(testX)
مرحله 7: احتمالات را فقط از کلاس مثبت نگه دارید.
probs = probs(:, 1)
مرحله 8: امتیاز AUC را محاسبه کنید.
auc = roc_auc_score(testy, probs)
print('AUC: %.2f' % auc)
خروجی:
AUC: 0.95
مرحله 9: منحنی ROC را دریافت کنید.
fpr, tpr, thresholds = roc_curve(testy, probs)
مرحله 10: منحنی ROC را با استفاده از تابع تعریف شده ترسیم کنید
plot_roc_curve(fpr, tpr)
خروجی:

نتیجه
منحنی AUC-ROC یکی از متداولترین معیارهای مورد استفاده برای ارزیابی عملکرد الگوریتمهای یادگیری ماشین بهویژه در مواردی است که مجموعه دادههای نامتعادل داریم. در این مقاله منحنی های ROC و مفاهیم مرتبط با آن را به تفصیل مشاهده می کنیم. در نهایت، نشان دادیم که چگونه منحنیهای ROC را میتوان با استفاده از پایتون ترسیم کرد.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-24 16:17:04
