از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



راهنمای باز کردن تنظیم دقیق Source مدل های LLM روی داده های سفارشی
سرفصلهای مطلب
معرفی
من مطمئن هستم که بیشتر شما نام ChatGPT را شنیده اید و آن را برای پاسخ به سوالات خود امتحان کرده اید! تا به حال فکر کرده اید که زیر کاپوت چه اتفاقی می افتد؟ این توسط یک مدل GPT-3 با زبان بزرگ طراحی شده توسط Open AI طراحی شده است. این مدلهای زبان بزرگ، که اغلب به عنوان LLM شناخته میشوند، امکانات زیادی را در پردازش زبان طبیعی باز کردهاند.
مدل های زبان بزرگ چیست؟
مدل های LLM آموزش دیده اند روی حجم عظیمی از داده های متنی، آنها را قادر می سازد تا زبان انسان را با معنا و زمینه درک کنند. پیش از این، بیشتر مدلها با استفاده از رویکرد نظارت شده آموزش داده میشدند، جایی که ویژگیهای ورودی و برچسبهای مربوطه را تغذیه میکردیم. بر خلاف این، LLM ها از طریق یادگیری بدون نظارت آموزش می بینند، جایی که حجم عظیمی از داده های متنی بدون هیچ برچسب و دستورالعملی به آنها داده می شود. از این رو، LLM ها معنا و روابط بین کلمات یک زبان را به طور موثر یاد می گیرند. آنها را می توان برای طیف گسترده ای از وظایف مانند تولید متن، پاسخ به سؤال، ترجمه از یک زبان به زبان دیگر و بسیاری موارد دیگر استفاده کرد.
به عنوان گیلاس روی بالا، این مدل های زبان بزرگ را می توان به خوبی تنظیم کرد روی مجموعه داده سفارشی شما برای کارهای خاص دامنه. در این مقاله، من در مورد نیاز به تنظیم دقیق، LLM های مختلف موجود، و همچنین یک مثال صحبت خواهم کرد.
آشنایی با LLM Fine-Tuning
فرض کنید شما یک انجمن حمایت از دیابت دارید و می خواهید یک خط راهنمای آنلاین برای پاسخ به سوالات راه اندازی کنید. یک LLM از قبل آموزش دیده به طور کلی تر آموزش دیده است و نمی تواند بهترین پاسخ ها را برای سؤالات خاص دامنه ارائه دهد و اصطلاحات پزشکی و کلمات اختصاری را درک کند. این را می توان با تنظیم دقیق حل کرد.
منظور ما از تنظیم دقیق چیست؟ به طور خلاصه بگویم، انتقال
یادگیری! مدل های زبان بزرگ آموزش دیده اند روی مجموعه داده های عظیم با استفاده از منابع سنگین و دارای میلیون ها پارامتر. بازنمایی ها و الگوهای زبانی که توسط LLM در طول آموزش پیش از آموزش آموخته شده است به وظیفه فعلی شما منتقل می شود. از نظر فنی، ما یک مدل را با وزنه های از قبل آموزش داده شده مقداردهی اولیه می کنیم و سپس آن را آموزش می دهیم روی دادههای ویژه کار ما برای رسیدن به وزنهای بهینهسازی کار بیشتر برای پارامترها. همچنین می توانید تغییراتی در معماری مدل ایجاد کنید و طبق نیاز خود لایه ها را تغییر دهید.
چرا باید مدل ها را دقیق تنظیم کنید؟
- صرفه جویی در زمان و منابع: تنظیم دقیق می تواند به شما کمک کند زمان و منابع مورد نیاز آموزش را نسبت به آموزش از ابتدا کاهش دهید.
- نیازهای داده کاهش یافته: اگر میخواهید یک مدل را از ابتدا آموزش دهید، به مقادیر زیادی داده برچسبدار نیاز دارید که اغلب برای افراد و مشاغل کوچک در دسترس نیست. تنظیم دقیق می تواند به شما کمک کند حتی با حجم کمتری از داده، عملکرد خوبی داشته باشید.
- بر اساس نیاز خود سفارشی کنید: LLM از پیش آموزش دیده ممکن است اصطلاحات و اختصارات خاص دامنه شما را پیدا نکند. به عنوان مثال، یک LLM معمولی تشخیص نمی دهد که “نوع 1” و “نوع 2” نشان دهنده انواع دیابت هستند، در حالی که یک LLM دقیق می تواند تشخیص دهد.
- فعال کردن یادگیری مستمر: فرض کنید مدل خود را به خوبی تنظیم کرده ایم روی داده های اطلاعات دیابت و به کارگیری آن. اگر برنامه غذایی یا درمانی جدیدی وجود داشته باشد که بخواهید آن را بگنجانید، چه؟ میتوانید از وزنهای مدل قبلی خود استفاده کنید و آن را طوری تنظیم کنید که دادههای جدیدتان را شامل شود. این می تواند به سازمان ها کمک کند تا مدل های خود را به شیوه ای کارآمد به روز نگه دارند.
انتخاب یک Open-Source مدل LLM
گام بعدی این است که یک مدل زبان بزرگ برای کار خود انتخاب کنید. گزینه های شما چیست؟ پیشرفته ترین مدل های زبان بزرگ موجود در حال حاضر شامل GPT-3، Bloom، BERT، T5 و XLNet هستند. در این میان، GPT-3 (ترانسفورماتورهای پیشآموزشی ژنراتور) بهترین عملکرد را از خود نشان داده است. روی 175 میلیارد پارامتر دارد و می تواند وظایف متنوع NLU را انجام دهد. اما تنظیم دقیق GPT-3 فقط از طریق اشتراک پولی قابل دسترسی است و نسبتاً گرانتر از گزینههای دیگر است.
از سوی دیگر، BERT یک مدل زبان بزرگ منبع باز است و می توان آن را به صورت رایگان تنظیم کرد. برت مخفف Bi-directional Encoder Decoder Transformers می باشد. BERT کار بسیار خوبی در درک بازنمایی کلمات متنی انجام می دهد.
چگونه انتخاب می کنید؟
اگر وظیفه شما بیشتر به سمت تولید متن است، مدلهای GPT-3 (پرداخت) یا GPT-2 (متن باز) انتخاب بهتری خواهند بود. اگر وظیفه شما در طبقه بندی متن، پاسخ به سؤال یا شناسایی نهاد قرار می گیرد، می توانید با BERT بروید. برای مورد من از پاسخ به سوال روی دیابت، من با مدل BERT ادامه خواهم داد.
آماده سازی و پیش پردازش مجموعه داده شما
این مهم ترین مرحله تنظیم دقیق است، زیرا قالب داده ها بر اساس متفاوت است روی مدل و وظیفه برای این مورد، من یک سند متنی نمونه با اطلاعات ایجاد کرده ام روی دیابت که من از موسسه ملی بهداشت تهیه کرده ام سایت اینترنتی. شما می توانید از داده های خود استفاده کنید.
برای تنظیم دقیق کار پرسش-پاسخ BERT، تبدیل داده های خود به فرمت SQuAD توصیه می شود. SQuAD مجموعه داده های پاسخگویی به پرسش استنفورد است و این فرمت به طور گسترده برای آموزش مدل های NLP برای وظایف پاسخگویی به سؤال مورد استفاده قرار می گیرد. داده ها باید در قالب JSON باشند، که در آن هر فیلد شامل موارد زیر است:
context: جمله یا پاراگراف با متن روی که مدل برای پاسخ سوال جستجو خواهد کردquestion: پرسشی که می خواهیم BERT به آن پاسخ دهد. شما باید این سوالات را بر اساس چارچوب بندی کنید روی چگونه کاربر نهایی با مدل QA تعامل خواهد داشت.answers: در این قسمت باید پاسخ مورد نظر را ارائه دهید. دو جزء فرعی زیر این وجود دارد،textوanswer_start. اینtextرشته پاسخ خواهد داشت. در حالیکه،answer_startنشان دهنده شاخص است، جایی که پاسخ در پاراگراف زمینه شروع می شود.
همانطور که می توانید تصور کنید، اگر به صورت دستی این کار را انجام دهید، ایجاد این داده ها برای سند شما زمان زیادی می برد. نگران نباشید، من به شما نشان خواهم داد که چگونه این کار را به راحتی با ابزار حاشیه نویسی Haystack انجام دهید.
چگونه با Haystack داده ها را در قالب SQuAD ایجاد کنیم؟
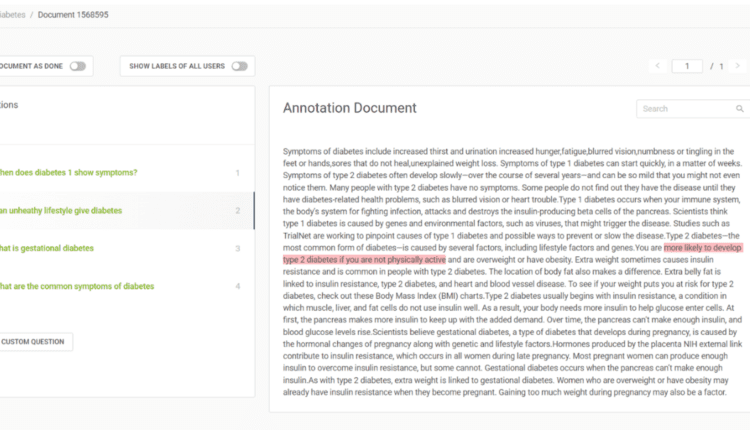
با استفاده از ابزار حاشیه نویسی Haystack، می توانید به سرعت یک مجموعه داده برچسب دار برای وظایف پاسخگویی به سوال ایجاد کنید. با ایجاد حساب کاربری می توانید به این ابزار دسترسی داشته باشید روی آنها سایت. یک پروژه جدید ایجاد کنید و سند خود را آپلود کنید. شما می توانید آن را در زیر برگه “اسناد” مشاهده کنید، به “اقدامات” بروید و می توانید گزینه ایجاد سوالات خود را مشاهده کنید. شما می توانید سوال خود را بنویسید و پاسخ را در سند برجسته کنید، Haystack به طور خودکار شاخص شروع آن را پیدا می کند. من نشان داده ام که چگونه این کار را انجام دادم روی سند من در تصویر زیر

شکل 1: ایجاد مجموعه داده های برچسب دار برای پرسش-پاسخ با Haystack
هنگامی که ایجاد جفت پرسش و پاسخ کافی برای تنظیم دقیق تمام شد، باید بتوانید خلاصه ای از آنها را همانطور که در زیر نشان داده شده است ببینید. در برگه «Export Labels»، میتوانید چندین گزینه برای قالب مورد نظر خود پیدا کنید export ما فرمت تیم را برای پرونده خود انتخاب می کنیم. اگر در استفاده از ابزار به کمک بیشتری نیاز دارید، می توانید آنها را بررسی کنید مستندات. ما اکنون فایل JSON خود را داریم که شامل جفتهای QA برای تنظیم دقیق است.

چگونه دقیق تنظیم کنیم؟
پایتون بسته های منبع باز بسیاری را ارائه می دهد که می توانید برای تنظیم دقیق از آنها استفاده کنید. من از بسته Pytorch and Transformers برای کیس خود استفاده کردم. با وارد کردن ماژول های بسته با استفاده از pip، مدیر بسته. این transformers کتابخانه ارائه می کند BERTTokenizerکه به طور خاص برای توکن کردن ورودی ها به مدل BERT است.
!pip install torch
!pip install transformers
import json
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
from torch.utils.data import DataLoader, Dataset
تعریف مجموعه داده سفارشی برای بارگیری و پیش پردازش
مرحله بعدی بارگذاری و پیشprocess داده. می توانید استفاده کنید Dataset کلاس از pytorch’s utils.data ماژول برای تعریف یک کلاس سفارشی برای مجموعه داده شما. من یک کلاس مجموعه داده سفارشی ایجاد کرده ام diabetes همانطور که در قطعه کد زیر می بینید. این init وظیفه مقداردهی اولیه متغیرها را بر عهده دارد. این file_path یک آرگومان است که مسیر فایل آموزشی JSON شما را وارد می کند و برای مقداردهی اولیه استفاده می شود data. را مقداردهی اولیه می کنیم BertTokenizer هم چنین این جا.
بعد، a را تعریف می کنیم load_data() تابع. این تابع فایل JSON را در یک شی داده JSON می خواند و متن، سوال، پاسخ ها و فهرست آنها را از آن استخراج می کند. فیلدهای استخراج شده را به لیست اضافه می کند و آن را برمی گرداند.
این getitem از توکنایزر BERT برای رمزگذاری سوال و زمینه در تانسورهای ورودی استفاده می کند input_ids و attention_mask. این encode_plus متن را نشانه گذاری می کند و نشانه های خاصی را اضافه می کند (مانند (CLS) و (SEP)). توجه داشته باشید که ما از squeeze() روشی برای حذف ابعاد تکی قبل از وارد کردن به BERT. در نهایت، تانسورهای ورودی پردازش شده را برمی گرداند.
class diabetes(Dataset):
def __init__(self, file_path):
self.data = self.load_data(file_path)
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
def load_data(self, file_path):
with open(file_path, 'r') as f:
data = json.load(f)
paragraphs = data('data')(0)('paragraphs')
extracted_data = ()
for paragraph in paragraphs:
context = paragraph('context')
for qa in paragraph('qas'):
question = qa('question')
answer = qa('answers')(0)('text')
start_pos = qa('answers')(0)('answer_start')
extracted_data.append({
'context': context,
'question': question,
'answer': answer,
'start_pos': start_pos,
})
return extracted_data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
example = self.data(index)
question = example('question')
context = example('context')
answer = example('answer')
inputs = self.tokenizer.encode_plus(question, context, add_special_tokens=True, padding='max_length', max_length=512, truncation=True, return_tensors='pt')
input_ids = inputs('input_ids').squeeze()
attention_mask = inputs('attention_mask').squeeze()
start_pos = torch.tensor(example('start_pos'))
return input_ids, attention_mask, start_pos, end_pos
هنگامی که آن را تعریف کردید، می توانید ادامه دهید و با عبور دادن یک نمونه از این کلاس ایجاد کنید file_path استدلال به آن
file_path = 'diabetes.json'
dataset = diabetes(file_path)
آموزش مدل
من با استفاده از BertForQuestionAnswering مدلی که برای وظایف QA مناسب است. شما می توانید وزنه های از قبل تمرین شده را مقداردهی اولیه کنید bert-base-uncased مدل با تماس با from_pretrained تابع روی مدل. همچنین باید تابع ضرر ارزیابی و بهینهسازی را که برای آموزش استفاده میکنید انتخاب کنید.
من از یک بهینه ساز Adam و تابع از دست دادن آنتروپی متقابل استفاده می کنم. می توانید از کلاس Pytorch استفاده کنید DataLoader برای بارگیری داده ها در دسته های مختلف و همچنین به هم زدن آنها برای جلوگیری از هرگونه سوگیری.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
loss_fn = torch.nn.CrossEntropyLoss()
batch_size = 8
num_epochs = 50
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
هنگامی که بارگذار داده تعریف شد، می توانید ادامه دهید و حلقه آموزشی نهایی را بنویسید. در طول هر تکرار، هر دسته به دست آمده از data_loader شامل batch_size تعداد نمونه، روی که انتشار به جلو و عقب انجام می شود. این کد تلاش میکند تا بهترین مجموعه وزنها را برای پارامترها پیدا کند، که در آن از دست دادن حداقل باشد.
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch in data_loader:
input_ids = batch(0).to(device)
attention_mask = batch(1).to(device)
start_positions = batch(2).to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, start_positions=start_positions)
loss = outputs.loss
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(data_loader)
print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")
این تنظیم دقیق شما را کامل می کند! می توانید مدل را با تنظیم آن تست کنید model.eval(). همچنین میتوانید از تنظیم دقیق نرخ یادگیری و پارامترهای no of epochs برای به دست آوردن بهترین نتایج استفاده کنید روی داده های شما
بهترین نکات و شیوه ها
در اینجا نکاتی وجود دارد که هنگام تنظیم دقیق هر مدل زبان بزرگ باید به آنها توجه کنید روی داده های سفارشی:
- مجموعه داده شما باید نشان دهنده دامنه یا وظیفه ای باشد که می خواهید مدل زبان در آن برتر باشد. تمیز و داده های به خوبی ساختار یافته ضروری است.
- مطمئن شوید که نمونه های آموزشی کافی در داده های خود دارید تا مدل الگوها را یاد بگیرد. در غیر این صورت، مدل ممکن است نمونه ها را به خاطر بسپارد و بیش از حد برازش کند، بدون اینکه ظرفیت آن را داشته باشد تعمیم دادن به نمونه های دیده نشده
- یک مدل از پیش آموزش دیده را انتخاب کنید روی مجموعه ای که به وظیفه شما مرتبط است. برای پاسخ به سؤال، ما یک مدل از پیش آموزش دیده را انتخاب می کنیم روی مجموعه داده پاسخ به پرسش استنفورد. مشابه این، مدلهای مختلفی برای کارهایی مانند تحلیل احساسات، تولید متن، خلاصهسازی، طبقهبندی متن و موارد دیگر در دسترس هستند.
- تلاش کردن تجمع گرادیان اگر حافظه گرافیکی محدودی دارید. در این روش، بهجای بهروزرسانی وزنهای مدل بعد از هر دسته، گرادیانها قبل از انجام بهروزرسانی روی چندین مینی دسته جمعآوری میشوند.
- اگر هنگام تنظیم دقیق با مشکل بیش از حد برازش مواجه شدید، استفاده کنید منظم سازی فنون برخی از روشهای رایج شامل افزودن لایههای حذفی به معماری مدل، پیادهسازی کاهش وزن و عادیسازی لایهها هستند.
نتیجه
مدل های زبان بزرگ می توانند به شما کمک کنند تا بسیاری از وظایف را به شیوه ای سریع و کارآمد خودکار کنید. تنظیم دقیق LLM به شما کمک می کند تا از قدرت انتقال یادگیری استفاده کنید و آن را در دامنه خاص خود سفارشی کنید. اگر مجموعه دادههای شما در حوزههایی مانند پزشکی، بخش فنی، مجموعه دادههای مالی و موارد دیگر باشد، تنظیم دقیق میتواند ضروری باشد.
در این مقاله از BERT استفاده کردیم زیرا منبع باز است و برای استفاده شخصی به خوبی کار می کند. اگر در حال کار هستید روی یک پروژه در مقیاس بزرگ، میتوانید LLMهای قدرتمندتر مانند GPT3 یا سایر جایگزینهای منبع باز را انتخاب کنید. به یاد داشته باشید، تنظیم دقیق مدل های زبان بزرگ می تواند از نظر محاسباتی گران و وقت گیر باشد. اطمینان حاصل کنید که منابع محاسباتی کافی، از جمله GPU یا TPU مبتنی بر در اختیار دارید روی مقیاس.
(برچسبها به ترجمه)# python
منتشر شده در 1402-12-30 17:19:05
