از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
Web scraping به صورت برنامه نویسی اطلاعات را از وب سایت های مختلف جمع آوری می کند. در حالی که کتابخانهها و چارچوبهای زیادی به زبانهای مختلف وجود دارد که میتوانند دادههای وب را استخراج کنند، پایتون به دلیل گزینههای فراوانی که برای اسکرپینگ وب دارد، مدتهاست که یک انتخاب محبوب بوده است.
این مقاله به شما یک دوره تصادف می دهد روی خراش دادن وب در پایتون با سوپ زیبا – یک کتابخانه محبوب پایتون برای تجزیه HTML و XML.
خراش دادن وب اخلاقی
اسکرپینگ وب همه جا حاضر است و داده هایی را به ما می دهد که با یک API دریافت می کنیم. با این حال، به عنوان شهروندان خوب اینترنت، این مسئولیت ماست که به صاحبان سایتی که از آنها می خریم احترام بگذاریم. در اینجا چند اصل وجود دارد که یک وب اسکراپر باید به آنها پایبند باشد:
- محتوای خراشیده شده را به عنوان محتوای ما ادعا نکنید. صاحبان وبسایتها گاهی اوقات زمان زیادی را صرف ایجاد مقاله، جمعآوری جزئیات درباره محصولات یا جمعآوری محتوای دیگر میکنند. ما باید به زحمت و اصالت آنها احترام بگذاریم.
- وب سایتی را که نمی خواهد خراشیده شود، خراش ندهید. وب سایت ها گاهی اوقات با یک
robots.txtفایل – که قسمت هایی از یک وب سایت را که می توان خراش داد را تعریف می کند. بسیاری از وب سایت ها همچنین شرایط استفاده دارند که ممکن است اجازه خراش دادن را ندهند. ما باید به وب سایت هایی که نمی خواهند خراشیده شوند احترام بگذاریم. - آیا API در حال حاضر موجود است؟ بسیار عالی، نیازی به نوشتن اسکراپر نیست. APIها برای فراهم کردن دسترسی به داده ها به روشی کنترل شده که توسط صاحبان داده ها تعریف شده است ایجاد می شوند. ما ترجیح می دهیم از API ها در صورت در دسترس بودن استفاده کنیم.
- درخواست برای یک وب سایت می تواند باعث عوارض شود روی عملکرد یک وب سایت یک اسکراپر وب که درخواست های زیادی می کند می تواند به اندازه یک حمله DDOS ضعیف کننده باشد. ما باید به طور مسئولانه خراش دهیم تا هیچ گونه اختلالی در عملکرد منظم وب سایت ایجاد نکنیم.
مروری بر سوپ زیبا
محتوای HTML صفحات وب را می توان با Beautiful Soup تجزیه و تحلیل کرد. در بخش بعدی، عملکردهایی را که برای خراش دادن صفحات وب مفید هستند، پوشش خواهیم داد.
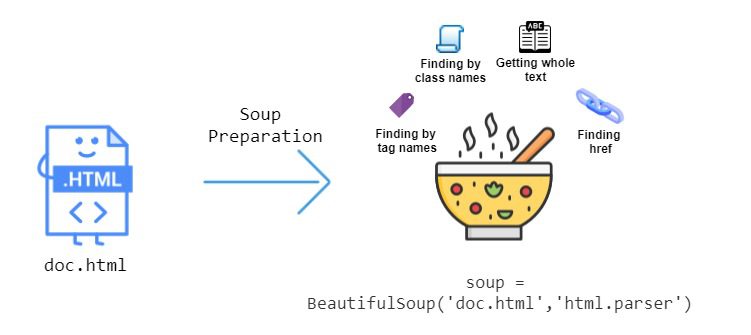
چیزی که Beautiful Soup را بسیار مفید می کند، توابع بی شماری است که برای استخراج داده ها از HTML ارائه می دهد. این تصویر زیر برخی از عملکردهایی را که می توانیم استفاده کنیم را نشان می دهد:

بیا دست بگیریم -روی و ببینید چگونه می توانیم HTML را با Beautiful Soup تجزیه کنیم. HTML زیر را در نظر بگیرید page در فایل به عنوان ذخیره شد doc.html:
<html>
<head>
<title>Head's title</title>
</head>
<body>
<p class="title"><b>Body's title</b></p>
<p class="story">Line begins
<a href="http://example.com/element1" class="element" id="link1">1</a>
<a href="http://example.com/element2" class="element" id="link2">2</a>
<a href="http://example.com/avatar1" class="avatar" id="link3">3</a>
<p> line ends</p>
</body>
</html>
قطعه کد زیر تست شده است روی Ubuntu 20.04.1 LTS. می توانید نصب کنید BeautifulSoup ماژول با تایپ دستور زیر در terminal:
$ pip3 install beautifulsoup4
فایل HTML doc.html باید آماده شود. این کار با ارسال فایل به BeautifulSoup سازنده، بیایید از پوسته تعاملی پایتون برای این کار استفاده کنیم تا بتوانیم فوراً print محتویات قسمت خاصی از a page:
from bs4 import BeautifulSoup
with open("doc.html") as fp:
soup = BeautifulSoup(fp, "html.parser")
اکنون می توانیم از Beautiful Soup برای پیمایش وب سایت خود و استخراج داده ها استفاده کنیم.
پیمایش به برچسب های خاص
از شیء سوپ ایجاد شده در قسمت قبل، تگ عنوان را دریافت می کنیم doc.html:
soup.head.title
در اینجا به تفکیک هر مؤلفه ای که برای بدست آوردن عنوان استفاده کردیم، آمده است:

Beautiful Soup قدرتمند است زیرا اشیاء پایتون ما با ساختار تودرتوی سند HTML که در حال خراشیدن هستیم مطابقت دارد.
برای دریافت متن اول <a> برچسب، این را وارد کنید:
soup.body.a.text
برای دریافت عنوان در تگ بدنه HTML (که با کلاس “title” مشخص می شود)، موارد زیر را در خود تایپ کنید. terminal:
soup.body.p.b
برای اسناد HTML عمیق تو در تو، ناوبری می تواند به سرعت خسته کننده شود. خوشبختانه، Beautiful Soup دارای یک تابع جستجو است، بنابراین ما مجبور نیستیم برای بازیابی عناصر HTML پیمایش کنیم.
جستجو در عناصر برچسب ها
را find_all() متد یک تگ HTML را به عنوان آرگومان رشته ای می گیرد و لیست عناصری را که با تگ ارائه شده مطابقت دارند برمی گرداند. مثلاً اگر همه را بخواهیم a برچسب ها در doc.html:
soup.find_all("a")
ما این لیست را خواهیم دید a برچسب ها به عنوان خروجی:
(<a class="element" href="http://example.com/element1" id="link1">1</a>, <a class="element" href="http://example.com/element2" id="link2">2</a>, <a class="element" href="http://example.com/element3" id="link3">3</a>)
در اینجا به تفکیک هر مؤلفه ای که برای جستجوی یک برچسب استفاده کردیم، آمده است:

همچنین میتوانیم برچسبهای یک کلاس خاص را با ارائه آن جستجو کنیم class_ بحث و جدل. موارد استفاده از سوپ زیبا class_ زیرا class یک کلمه کلیدی رزرو شده در پایتون است. بیایید همه را جستجو کنیم a برچسب هایی که دارای کلاس “element” هستند:
soup.find_all("a", class_="element")
از آنجایی که ما فقط دو پیوند با کلاس “element” داریم، این خروجی را خواهید دید:
(<a class="element" href="http://example.com/element1" id="link1">1</a>, <a class="element" href="http://example.com/element2" id="link2">2</a>)
چه می شود اگر بخواهیم پیوندهای تعبیه شده در داخل را واکشی کنیم a برچسب ها؟ بیایید یک پیوند را بازیابی کنیم href ویژگی با استفاده از find() گزینه. درست مثل کار می کند find_all() اما به جای لیست، اولین عنصر تطبیق را برمی گرداند. این را در پوسته خود تایپ کنید:
soup.find("a", href=True)("href")
را find() و find_all() توابع نیز به جای رشته، یک عبارت منظم را می پذیرند. در پشت صحنه، متن با استفاده از عبارت منظم کامپایل شده فیلتر می شود search() روش. مثلا:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag)
لیست پس از تکرار، برچسب هایی را که با کاراکتر شروع می شوند واکشی می کند b که شامل <body> و <b>:
<body>
<p class="title"><b>Body's title</b></p>
<p class="story">line begins
<a class="element" href="http://example.com/element1" id="link1">1</a>
<a class="element" href="http://example.com/element2" id="link2">2</a>
<a class="element" href="http://example.com/element3" id="link3">3</a>
<p> line ends</p>
</p></body>
<b>Body's title</b>
ما محبوب ترین روش های دریافت برچسب ها و ویژگی های آنها را پوشش داده ایم. گاهی اوقات، به خصوص برای صفحات وب کمتر پویا، فقط متن را از آن می خواهیم. بیایید ببینیم چگونه می توانیم آن را بدست آوریم!
دریافت کل متن
را get_text() تابع تمام متن را از سند HTML بازیابی می کند. بیایید تمام متن سند HTML را دریافت کنیم:
soup.get_text()
خروجی شما باید به این صورت باشد:
Head's title
Body's title
line begins
1
2
3
line ends
گاهی اوقات کاراکترهای خط جدید چاپ می شوند، بنابراین خروجی شما ممکن است به این شکل باشد:
"\n\nHead's title\n\n\nBody's title\nline begins\n 1\n2\n3\n line ends\n\n"
اکنون که احساس می کنیم چگونه از سوپ زیبا استفاده کنیم، بیایید یک وب سایت را خراش دهیم!
سوپ زیبا در عمل – تهیه فهرست کتاب
اکنون که بر اجزای سوپ زیبا تسلط داریم، وقت آن است که از یادگیری خود استفاده کنیم. بیایید یک اسکراپر برای استخراج داده ها بسازیم https://books.toscrape.com/ و آن را در یک فایل CSV ذخیره کنید. این سایت حاوی دادههای تصادفی درباره کتابها است و فضایی عالی برای آزمایش تکنیکهای خراش دادن وب شما است.
ابتدا یک فایل جدید به نام ایجاد کنید scraper.py. اجازه دهید import تمام کتابخانه هایی که برای این اسکریپت نیاز داریم:
import requests
import time
import csv
import re
from bs4 import BeautifulSoup
در ماژول های ذکر شده در بالا:
requests– درخواست URL را انجام می دهد و HTML وب سایت را واکشی می کندtime– تعداد دفعات خراشیدن را محدود می کند page فوراcsv– به ما کمک می کند export داده های خراشیده شده ما در یک فایل CSVre– به ما امکان می دهد عبارات منظمی را بنویسیم که برای انتخاب متن بر اساس مفید باشد روی الگوی آنbs4– واقعاً مال شما، ماژول خراش برای تجزیه HTML
شما باید داشته باشید bs4 قبلا نصب شده است، و time، csv، و re بسته های داخلی در پایتون هستند. شما باید نصب کنید requests ماژول به طور مستقیم مانند این:
$ pip3 install requests
قبل از شروع، باید بدانید ساختار HTML صفحه وب چگونه است. در مرورگر شما، بیایید به http://books.toscrape.com/catalogue/page-1.html. سپس راست کلیک کنید روی اجزای وب page خراشیده شود و کلیک کنید روی را بازرسی برای درک سلسله مراتب تگ ها همانطور که در زیر نشان داده شده است را فشار دهید.
این HTML زیربنایی را برای آنچه که در حال بررسی هستید به شما نشان می دهد. تصویر زیر این مراحل را نشان می دهد:

از بررسی HTML، روش دسترسی به URL کتاب، تصویر جلد، عنوان، رتبه بندی، قیمت و فیلدهای بیشتر از HTML را یاد می گیریم. بیایید تابعی بنویسیم که یک آیتم کتاب را خراش می دهد و داده های آن را استخراج می کند:
def scrape(source_url, soup):
books = soup.find_all("article", class_="product_pod")
for each_book in books:
info_url = source_url+"/"+each_book.h3.find("a")("href")
cover_url = source_url+"/catalogue" + \
each_book.a.img("src").replace("..", "")
title = each_book.h3.find("a")("title")
rating = each_book.find("p", class_="star-rating")("class")(1)
price = each_book.find("p", class_="price_color").text.strip().encode(
"ascii", "ignore").decode("ascii")
availability = each_book.find(
"p", class_="instock availability").text.strip()
write_to_csv((info_url, cover_url, title, rating, price, availability))
آخرین خط از قطعه بالا به تابعی اشاره می کند که لیست رشته های خراشیده شده را در یک فایل CSV بنویسد. اکنون آن تابع را اضافه می کنیم:
def write_to_csv(list_input):
try:
with open("allBooks.csv", "a") as fopen:
csv_writer = csv.writer(fopen)
csv_writer.writerow(list_input)
except:
return False
همانطور که ما تابعی داریم که می تواند a را خراش دهد page و export به CSV، ما تابع دیگری می خواهیم که در وب سایت صفحه بندی شده می خزد و داده های کتاب را جمع آوری می کند روی هر یک page.
برای انجام این کار، بیایید به آدرس اینترنتی که این اسکراپر را برای آن می نویسیم نگاه کنیم:
"http://books.toscrape.com/catalogue/page-1.html"
تنها عنصر متفاوت در URL است page عدد. ما می توانیم URL را به صورت پویا قالب بندی کنیم تا به a تبدیل شود نشانی وب اولیه:
"http://books.toscrape.com/catalogue/page-{}.html".format(str(page_number))
این رشته URL را با page شماره را می توان با استفاده از روش واکشی کرد requests.get(). سپس می توانیم یک جدید ایجاد کنیم BeautifulSoup هدف – شی. هر بار که ما شیء سوپ را دریافت می کنیم، وجود دکمه “بعدی” بررسی می شود تا بتوانیم در آخر توقف کنیم. page. ما پیگیری یک شمارنده برای page عددی که پس از خراش دادن موفقیت آمیز a به میزان 1 افزایش می یابد page.
def browse_and_scrape(seed_url, page_number=1):
url_pat = re.compile(r"(http://.*\.com)")
source_url = url_pat.search(seed_url).group(0)
formatted_url = seed_url.format(str(page_number))
try:
html_text = requests.get(formatted_url).text
soup = BeautifulSoup(html_text, "html.parser")
print(f"Now Scraping - {formatted_url}")
if soup.find("li", class_="next") != None:
scrape(source_url, soup)
time.sleep(3)
page_number += 1
browse_and_scrape(seed_url, page_number)
else:
scrape(source_url, soup)
return True
return True
except Exception as e:
return e
تابع بالا، browse_and_scrape()، به صورت بازگشتی تا تابع فراخوانی می شود soup.find("li",class_="next") برمی گرداند None. در این مرحله، کد قسمت باقی مانده از صفحه وب را خراش می دهد و از آن خارج می شود.
برای قطعه نهایی به پازل، جریان خراش را آغاز می کنیم. را تعریف می کنیم seed_url و تماس بگیرید browse_and_scrape() برای بدست آوردن داده ها این کار در زیر انجام می شود if __name__ == "__main__" مسدود کردن:
if __name__ == "__main__":
seed_url = "http://books.toscrape.com/catalogue/page-{}.html"
print("Web scraping has begun")
result = browse_and_scrape(seed_url)
if result == True:
print("Web scraping is now complete!")
else:
print(f"Oops, That doesn't seem right!!! - {result}")
اگر می خواهید در مورد آن بیشتر بدانید if __name__ == "__main__" مسدود کنید، راهنمای ما را بررسی کنید روی چگونه کار می کند
شما می توانید اسکریپت را مطابق تصویر زیر اجرا کنید terminal و خروجی را به صورت زیر دریافت کنید:
$ python scraper.py
Web scraping has begun
Now Scraping - http://books.toscrape.com/catalogue/page-1.html
Now Scraping - http://books.toscrape.com/catalogue/page-2.html
Now Scraping - http://books.toscrape.com/catalogue/page-3.html
.
.
.
Now Scraping - http://books.toscrape.com/catalogue/page-49.html
Now Scraping - http://books.toscrape.com/catalogue/page-50.html
Web scraping is now complete!
داده های خراشیده شده را می توان در فهرست کاری فعلی زیر نام فایل یافت allBooks.csv. نمونه ای از محتوای فایل در اینجا آمده است:
http://books.toscrape.com/a-light-in-the-attic_1000/index.html,http://books.toscrape.com/catalogue/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg,A Light in the Attic,Three,51.77,In stock
http://books.toscrape.com/tipping-the-velvet_999/index.html,http://books.toscrape.com/catalogue/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg,Tipping the Velvet,One,53.74,In stock
http://books.toscrape.com/soumission_998/index.html,http://books.toscrape.com/catalogue/media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg,Soumission,One,50.10,In stock
آفرین! اگر می خواهید به کل کد اسکراپر نگاهی بیندازید، می توانید آن را پیدا کنید روی GitHub.
نتیجه
در این آموزش، اخلاق نوشتن وب اسکراپرهای خوب را آموختیم. سپس از Beautiful Soup برای استخراج داده ها از یک فایل HTML با استفاده از ویژگی های شیء Beautiful Soup و روش های مختلف آن مانند find()، find_all() و get_text(). سپس یک اسکراپر ساختیم که فهرست کتاب را به صورت آنلاین بازیابی می کند و به CSV صادر می کند.
Web scraping یک مهارت مفید است که به فعالیتهای مختلفی مانند استخراج دادهها مانند API، انجام QA کمک میکند. روی یک وبسایت، آدرسهای خراب را بررسی میکند روی یک وب سایت و موارد دیگر. خراش بعدی که قرار است بسازید چیست؟
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-14 19:44:04
