از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
افراد به ندرت می توانند به یک داده خام نگاه کنند و فوراً یک مشاهده داده محور مانند:
مردم در فروشگاه ها تمایل به خرید دارند پوشک و آبجو در پیوند!
یا حتی اگر شما به عنوان یک دانشمند داده واقعاً می توانید داده های خام را مشاهده کنید، سرمایه گذار یا رئیس شما به احتمال زیاد نمی تواند.
برای اینکه بتوانیم داده های خود را به درستی تجزیه و تحلیل کنیم، باید آن ها را به شیوه ای ملموس و جامع بازنمایی کنیم. دقیقاً به همین دلیل است که ما از تجسم داده ها استفاده می کنیم!
را pandas کتابخانه مجموعه وسیعی از ابزارها را ارائه می دهد که به شما در انجام این کار کمک می کند. در این مقاله، ما قدم به قدم پیش می رویم و همه چیزهایی را که برای شروع به آن نیاز دارید، پوشش می دهیم pandas ابزار تجسم، از جمله نمودار میله، هیستوگرام ها، قطعات منطقه، نمودارهای تراکم، ماتریس های پراکنده، و توطئه های بوت استرپ.
وارد کردن داده ها
اول، ما به یک مجموعه داده کوچک برای کار و آزمایش چیزها نیاز داریم.
من از مجموعه داده غذاهای هندی استفاده خواهم کرد زیرا رک و پوست کنده، غذاهای هندی خوشمزه هستند. شما می توانید آن را به صورت رایگان از Kaggle.com. به import از آن استفاده خواهیم کرد read_csv() روشی که a را برمی گرداند DataFrame. در اینجا یک قطعه کد کوچک است که پنج ورودی اول و پنج ورودی آخر در مجموعه داده ما را چاپ می کند. بیایید آن را امتحان کنیم:
import pandas as pd
menu = pd.read_csv('indian_food.csv')
print(menu)
با اجرای این کد خروجی:
name state region ... course
0 Balu shahi West Bengal East ... dessert
1 Boondi Rajasthan West ... dessert
2 Gajar ka halwa Punjab North ... dessert
3 Ghevar Rajasthan West ... dessert
4 Gulab jamun West Bengal East ... dessert
.. ... ... ... ... ...
250 Til Pitha Assam North East ... dessert
251 Bebinca Goa West ... dessert
252 Shufta Jammu & Kashmir North ... dessert
253 Mawa Bati Madhya Pradesh Central ... dessert
254 Pinaca Goa West ... dessert
اگر می خواهید داده ها را از فرمت فایل دیگری بارگیری کنید، pandas روش های خواندن مشابهی را ارائه می دهد read_json(). نما به دلیل فرم بلند آن کمی کوتاه شده است ingredients متغیر.
برای استخراج تنها چند ستون انتخابی، میتوانیم مجموعه داده را از طریق براکتهای مربع زیر مجموعهبندی کنیم و نام ستونهایی را که میخواهیم تمرکز کنیم فهرست کنیم. روی:
import pandas as pd
menu = pd.read_csv('indian_food.csv')
recipes = menu(('name', 'ingredients'))
print(recipes)
این نتیجه می دهد:
name ingredients
0 Balu shahi Maida flour, yogurt, oil, sugar
1 Boondi Gram flour, ghee, sugar
2 Gajar ka halwa Carrots, milk, sugar, ghee, cashews, raisins
3 Ghevar Flour, ghee, kewra, milk, clarified butter, su...
4 Gulab jamun Milk powder, plain flour, baking powder, ghee,...
.. ... ...
250 Til Pitha Glutinous rice, black sesame seeds, gur
251 Bebinca Coconut milk, egg yolks, clarified butter, all...
252 Shufta Cottage cheese, dry dates, dried rose petals, ...
253 Mawa Bati Milk powder, dry fruits, arrowroot powder, all...
254 Pinaca Brown rice, fennel seeds, grated coconut, blac...
(255 rows x 2 columns)
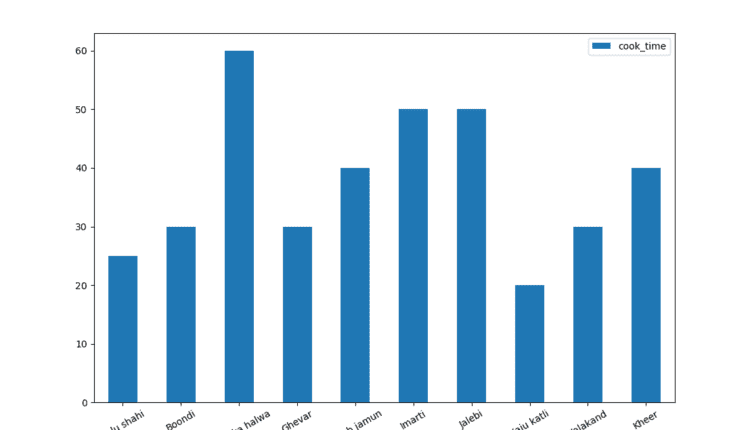
ترسیم نمودار میله ای با پانداها
کلاسیک نمودار میله ای خواندن آن آسان است و مکان خوبی برای شروع است – بیایید تجسم کنیم که پخت هر غذا چقدر طول می کشد.
پانداها متکی هستند روی را Matplotlib موتور برای نمایش نمودارهای تولید شده پس مجبوریم import ماژول PyPlot Matplotlib برای فراخوانی plt.show() پس از ایجاد نمودارها
اول، اجازه دهید import داده های ما تعداد زیادی ظرف در مجموعه داده ما وجود دارد – به طور دقیق 255. این در حالی که خوانا می ماند واقعاً در یک شکل قرار نمی گیرد.
ما استفاده خواهیم کرد head() روش استخراج 10 ظرف اول و استخراج متغیرهای مربوط به طرح ما. یعنی، ما می خواهیم آن را استخراج کنیم name و cook_time برای هر ظرف یک DataFrame جدید به نام name_and_timeو آن را به 10 ظرف اول کوتاه کنید:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
name_and_time = menu(('name', 'cook_time')).head(10)
حالا ما از bar() روش رسم داده های ما:
DataFrame.plot.bar(x=None, y=None, **kwargs)
- را
xوyپارامترها با محور X و Y مطابقت دارند kwargsمربوط به آرگومان های کلیدواژه اضافی است که در مستند شده اندDataFrame.plot().
بسیاری از پارامترهای اضافی را می توان برای سفارشی کردن بیشتر طرح ارسال کرد، مانند rot برای چرخش برچسب، legend برای افزودن یک افسانه، style، و غیره…
بسیاری از این آرگومانها دارای مقادیر پیشفرض هستند که اکثر آنها خاموش هستند. از آنجا که rot آرگومان پیش فرض به 90، برچسب های ما 90 درجه می چرخند. اجازه دهید در حین ساخت طرح، آن را به 30 تغییر دهیم:
name_and_time.plot.bar(x='name',y='cook_time', rot=30)
و در نهایت، ما با آن تماس می گیریم show() روشی از نمونه PyPlot برای نمایش گراف ما:
plt.show()
این خروجی نمودار میله ای مورد نظر ما را نشان می دهد:
ترسیم ستون های متعدد روی محور X-Plot در پانداها
اغلب، ممکن است بخواهیم دو متغیر را در یک نوار Plot مقایسه کنیم، مانند the cook_time و prep_time. اینها هر دو متغیر مربوط به هر ظرف هستند و مستقیماً قابل مقایسه هستند.
بیایید تغییر دهیم name_and_time DataFrame را نیز شامل شود prep_time:
name_and_time = menu(('name', 'prep_time', 'cook_time')).head(10)
name_and_time.plot.bar(x='name', rot=30)
پانداها به طور خودکار فرض کردند که دو مقدار عددی در کنار هم هستند name به آن گره خورده اند، بنابراین کافی است فقط محور X را تعریف کنید. وقتی با سایر DataFrame ها سروکار دارید، ممکن است اینطور نباشد.
اگر نیاز دارید که به صراحت تعریف کنید که کدام متغیرهای دیگر باید رسم شوند، می توانید به سادگی در یک لیست ارسال کنید:
name_and_time.plot.bar(x='name', y=('prep_time', 'cook_time'), rot=30)
اجرای هر یک از این دو کد به دست می آید:

جالبه. به نظر می رسد غذایی که سریعتر طبخ می شود زمان بیشتری را برای آماده سازی نیاز دارد و بالعکس. اگرچه، این از یک زیرمجموعه نسبتاً محدود از داده ها ناشی می شود و این فرض ممکن است برای زیر مجموعه های دیگر اشتباه باشد.
ترسیم نمودارهای نواری انباشته با پانداها
بیایید ببینیم پخت کدام غذا به طور کلی طولانیترین زمان را میگیرد. از آنجایی که می خواهیم هم زمان آماده سازی و هم زمان پخت را در نظر بگیریم، این کار را می کنیم پشته آنها روی روی هم
برای انجام این کار، ما را تنظیم می کنیم stacked پارامتر به True:
name_and_time.plot.bar(x='name', stacked=True)

اکنون، با در نظر گرفتن زمان آماده سازی و زمان پخت، به راحتی می توانیم ببینیم که کدام ظروف طولانی ترین زمان را برای آماده شدن دارند.
سفارشی کردن قطعه نوار در پانداها
اگر بخواهیم نمودارها کمی زیباتر به نظر برسند، میتوانیم برخی از آرگومانهای اضافی را به آن منتقل کنیم bar() روش، مانند:
color: که برای هر کدام یک رنگ تعریف می کندDataFrameصفات می تواند رشته ای باشد مانند'orange'،rgbیا مانند rgb-code#faa005.title: رشته یا لیستی که نشان دهنده عنوان طرح است.grid: یک مقدار بولی که نشان می دهد خطوط شبکه قابل مشاهده هستند یا خیر.figsize: یک تاپل که اندازه طرح را بر حسب اینچ نشان می دهد.legend: Boolean که نشان می دهد افسانه نشان داده شده است یا خیر.
اگر نمودار میلهای افقی میخواهیم، میتوانیم از آن استفاده کنیم barh() روشی که همان آرگومان ها را می گیرد.
برای مثال، بیایید یک نوار افقی نارنجی و سبز با عنوان ترسیم کنیم "Dishes"، با یک شبکه به اندازه 5 در 6 اینچ و یک افسانه:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
name_and_time = menu(('name', 'cook_time', 'prep_time')).head()
name_and_time.plot.barh(x='name',color =('orange', 'green'), title = "Dishes", grid = True, figsize=(5,6), legend = True)
plt.show()

ترسیم هیستوگرام با پانداها
هیستوگرام ها برای نمایش توزیع داده ها مفید هستند. با نگاهی به یک دستور غذا، نمیدانیم که زمان پخت نزدیک به میانگین زمان پخت است یا اینکه زمان بسیار زیادی طول میکشد. ابزارها می توانند تا حدی در این امر به ما کمک کنند، اما می توانند گمراه کننده باشند یا مستعد نوارهای خطای بزرگ باشند.
برای دریافت ایده ای از توزیع، که اطلاعات زیادی به ما می دهد روی در زمان پخت، می خواهیم یک هیستوگرام ترسیم کنیم.
با پانداها، میتوانیم آن را صدا کنیم hist() تابع روی یک DataFrame برای تولید هیستوگرام آن:
DataFrame.hist(column=None, by=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, ax=None, sharex=False, sharey=False, fcigsize=None, layout=None, bins=10, backend=None, legend=False,**kwargs)
را bins پارامتر تعداد سطل های مورد استفاده را نشان می دهد.
بخش بزرگی از کار با هر مجموعه داده، تمیز کردن و پیش پردازش داده است. در مورد ما، برخی از غذاها زمان پخت و آماده سازی مناسبی ندارند (و دارای یک -1 مقدار ذکر شده در عوض).
بیایید قبل از تجسم هیستوگرام، آنها را از منوی خود فیلتر کنیم. این ابتدایی ترین نوع پیش پردازش داده است. در برخی موارد، ممکن است بخواهید انواع داده ها را تغییر دهید (مثلاً رشته های فرمت شده ارز به شناور) یا حتی بر اساس نقاط داده جدید بسازید. روی یک متغیر دیگر
بیایید مقادیر نامعتبر را فیلتر کرده و یک هیستوگرام با 50 bin رسم کنیم روی محور X:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
menu = menu(menu.cook_time != -1)
cook_time = menu('cook_time')
cook_time.plot.hist(bins = 50)
plt.legend()
plt.show()
این منجر به:

در محور Y، ما می توانیم فرکانس از ظروف، در حالی که روی در محور X، میتوانیم ببینیم چقدر طول میکشد تا پخته شوند.
هرچه نوار بالاتر باشد فرکانس بالاتر است. با توجه به این هیستوگرام، اکثر ظروف بین 0..80 دقیقه برای پختن بیشترین تعداد آنها در نوار واقعاً بالا است، هرچند، ما واقعاً نمیتوانیم تشخیص دهیم که این دقیقاً کدام عدد است زیرا فرکانس تیکهای ما کم است (یک عدد در هر 100 دقیقه).
در حال حاضر، بیایید سعی کنیم تعداد سطل ها را تغییر دهیم تا ببینیم که چگونه بر هیستوگرام ما تأثیر می گذارد. پس از آن می توانیم فرکانس تیک ها را تغییر دهیم.
تاکید بر داده ها با Bin Sizes
بیایید سعی کنیم این هیستوگرام را با آن ترسیم کنیم 10 سطل زباله در عوض:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
menu = menu(menu.cook_time != -1)
cook_time = menu('cook_time')
cook_time.plot.hist(bins = 10)
plt.legend()
plt.show()

اکنون، 10 سطل در کل محور X داریم. توجه داشته باشید که فقط 3 سطل مقداری فرکانس داده دارند در حالی که بقیه خالی هستند.
حالا بیایید تعداد سطل ها را افزایش دهیم:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
menu = menu(menu.cook_time != -1)
cook_time = menu('cook_time')
cook_time.plot.hist(bins = 100)
plt.legend()
plt.show()

اکنون، سطل ها به طرز ناخوشایندی دور از هم قرار گرفته اند، و ما دوباره برخی از اطلاعات را به این دلیل از دست داده ایم. همیشه میخواهید اندازههای سطل را آزمایش کنید و آنها را تنظیم کنید تا دادههایی که میخواهید کاوش کنید به خوبی نشان داده شوند.
تنظیمات پیشفرض (عدد bin بهطور پیشفرض روی 10 است) در این مورد به عدد بن فرد منجر میشود.
فرکانس تیک را برای هیستوگرام پانداها تغییر دهید
از آنجایی که ما از Matplotlib به عنوان موتور برای نمایش این نمودارها استفاده می کنیم، می توانیم از هر تکنیک سفارشی سازی Matplotlib نیز استفاده کنیم.
از آنجایی که تیکهای محور X ما کمی نادر هستند، آرایهای از اعداد صحیح را با افزایش ۲۰ مرحلهای، بین 0 و cook_time.max()، که ورودی با بیشترین تعداد را برمی گرداند.
همچنین، از آنجایی که تیک های زیادی در طرح خود خواهیم داشت، آنها را 45 درجه می چرخانیم تا مطمئن شویم که به خوبی مطابقت دارند:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
menu = pd.read_csv('indian_food.csv')
menu = menu(menu.cook_time != -1)
cook_time = menu('cook_time')
cook_time.plot.hist(bins=50)
plt.xticks(np.arange(0, cook_time.max(), 20))
plt.xticks(rotation = 45)
plt.legend()
plt.show()
این منجر به:

ترسیم هیستوگرام های متعدد
حالا بیایید زمان آماده سازی را به مخلوط اضافه کنیم. برای اضافه کردن این هیستوگرام، آن را به عنوان یک تنظیم هیستوگرام جداگانه هر دو در کدورت 60% ترسیم می کنیم.
آنها هم محور Y و هم محور X را به اشتراک می گذارند، بنابراین همپوشانی خواهند داشت. بدون اینکه آنها را کمی شفاف تنظیم کنیم، ممکن است هیستوگرام را در زیر تصویر دومی که رسم می کنیم نبینیم:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
menu = pd.read_csv('indian_food.csv')
menu = menu((menu.cook_time!=-1) & (menu.prep_time!=-1))
cook_time = menu('cook_time')
prep_time = menu('prep_time')
prep_time.plot.hist(alpha = 0.6 , bins = 50)
cook_time.plot.hist(alpha = 0.6, bins = 50)
plt.xticks(np.arange(0, cook_time.max(), 20))
plt.xticks(rotation = 45)
plt.legend()
plt.show()
این منجر به:

میتوان نتیجه گرفت که بیشتر غذاها را میتوان در کمتر از یک ساعت یا در حدود یک ساعت درست کرد. با این حال، تعدادی وجود دارد که چند روز طول می کشد تا آماده شوند، با زمان آماده سازی 10 ساعت و زمان پخت طولانی.
سفارشی کردن نمودارهای هیستوگرام
برای سفارشیسازی هیستوگرامها، میتوانیم از همان آرگومانهای کلمه کلیدی استفاده کنیم که با نمودار نوار استفاده کردیم.
به عنوان مثال، بیایید یک هیستوگرام سبز و قرمز، با عنوان، یک شبکه، یک افسانه – به اندازه 7×7 اینچ ایجاد کنیم:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
menu = pd.read_csv('indian_food.csv')
menu = menu((menu.cook_time!=-1) & (menu.prep_time!=-1))
cook_time = menu('cook_time')
prep_time = menu('prep_time')
prep_time.plot.hist(alpha = 0.6 , color = 'green', title = 'Cooking time', grid = True, bins = 50)
cook_time.plot.hist(alpha = 0.6, color = 'red', figsize = (7,7), grid = True, bins = 50)
plt.xticks(np.arange(0, cook_time.max(), 20))
plt.xticks(rotation = 45)
plt.legend()
plt.show()
و این هم هیستوگرام رنگی کریسمس ما:

توطئه های منطقه ای با پانداها
هنگام نگاه کردن به همبستگی دو پارامتر، نمودارهای مساحتی مفید هستند. به عنوان مثال، از نمودارهای هیستوگرام، درست است که به این ایده متمایل شویم که غذاهایی که برای آماده شدن طولانیتر طول میکشد، زمان کمتری برای پختن نیاز دارند.
برای آزمایش این، این رابطه را با استفاده از area() تابع:
DataFrame.plot.area(x=None, y=None, **kwargs)
بیایید از میانگین زمان پخت، گروه بندی شده بر اساس زمان آماده سازی برای ساده کردن این نمودار استفاده کنیم:
time = menu.groupby('prep_time').mean()
این منجر به یک DataFrame جدید می شود:
prep_time
5 20.937500
10 40.918367
12 40.000000
15 36.909091
20 36.500000
...
495 40.000000
500 120.000000
اکنون، یک قطعه مساحتی را با نتیجه آن ترسیم می کنیم time DataFrame:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
menu = menu((menu.cook_time!=-1) & (menu.prep_time!=-1))
time = menu.groupby('prep_time').mean()
time.plot.area()
plt.legend()
plt.show()

در اینجا، تصور ما از همبستگی اصلی بین زمان آماده سازی و زمان پخت از بین رفته است. حتی اگر انواع نمودارهای دیگر ممکن است ما را به برخی نتیجه گیری ها هدایت کنند – نوعی همبستگی وجود دارد که نشان می دهد با زمان های آماده سازی بالاتر، زمان پخت بیشتری نیز خواهیم داشت. که برعکس آن چیزی است که ما فرض کردیم.
این یک دلیل عالی است که فقط به یک نوع گراف پایبند نباشید، بلکه مجموعه داده خود را با رویکردهای متعدد بررسی کنید.
ترسیم قطعه زمین های انباشته شده
نمودارهای ناحیه دارای مجموعه ای بسیار مشابه از آرگومان های کلیدواژه مانند نمودارهای نواری و هیستوگرام هستند. یکی از استثناهای قابل توجه این خواهد بود:
stacked: مقدار بولی که نشان می دهد آیا دو یا چند نمودار روی هم چیده می شوند یا خیر
بیایید زمان های پخت و پز و آماده سازی را طوری ترسیم کنیم که روی هم چیده شوند، صورتی و بنفش، با شبکه ای به اندازه 8×9 اینچ، با یک افسانه:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
menu = menu((menu.cook_time!=-1) & (menu.prep_time!=-1))
menu.plot.area()
plt.legend()
plt.show()

ترسیم نمودارهای پای با پانداها
نمودارهای دایره ای زمانی مفید هستند که تعداد کمی مقادیر طبقه بندی داشته باشیم که باید آنها را با هم مقایسه کنیم. آنها بسیار واضح و دقیق هستند، با این حال، مراقب باشید. خوانایی نمودارهای دایره ای با کوچکترین افزایش در تعداد مقادیر طبقه بندی بسیار پایین می آید.
برای ترسیم نمودارهای دایره ای، از pie() تابعی که دستور زیر را دارد:
DataFrame.plot.pie(**kwargs)
ترسیم نمایه های طعم:
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
flavors = menu(menu.flavor_profile != '-1')
flavors('flavor_profile').value_counts().plot.pie()
plt.legend()
plt.show()
این منجر به:

تا به حال، بیشتر غذاها تند و شیرین هستند.
سفارشی کردن نمودارهای پای
برای جذابتر کردن نمودار دایرهای خود، میتوانیم آن را با همان آرگومانهای کلیدواژهای که در همه نمودارهای جایگزین قبلی استفاده میکردیم، تغییر دهیم، با برخی از موارد جدید:
shadow: Boolean که نشان می دهد آیا برش های نمودار دایره ای سایه دارند یا خیرstartangle: زاویه شروع نمودار دایره ای
برای نشان دادن این که چگونه این کار می کند، بیایید مناطقی را که ظروف از آن سرچشمه می گیرند، ترسیم کنیم. استفاده خواهیم کرد head() فقط 10 مورد اول را بگیرید تا برش های زیادی نداشته باشید.
بیایید پای را با عنوان “ایالات” صورتی کنیم، به آن سایه و افسانه بدهیم و کاری کنیم که از زاویه شروع شود. 15 :
import pandas as pd
import matplotlib.pyplot as plt
menu = pd.read_csv('indian_food.csv')
states = (menu(menu.state != '-1'))('state').value_counts().head(10)
colors = ('lightpink', 'pink', 'fuchsia', 'mistyrose', 'hotpink', 'deeppink', 'magenta')
states.plot.pie(colors = colors, shadow = True, startangle = 15, title = "States")
plt.show()

ترسیم نقشه های تراکم با پانداها
اگر تجربه ای در مورد آمار دارید، احتمالاً طرح تراکم را دیده اید. نمودارهای چگالی یک نمایش بصری از چگالی احتمال در طیف وسیعی از مقادیر هستند.
یک هیستوگرام است یک نمودار چگالی، که نقاط داده را در دسته بندی ها با هم جمع می کند. دومین نمودار چگالی محبوب، نمودار KDE (تخمین تراکم هسته) است – به عبارت ساده، مانند یک هیستوگرام بسیار صاف با تعداد بی نهایت bin است.
برای ترسیم یک، از آن استفاده می کنیم kde() تابع:
DataFrame.plot.kde(bw_method=None, ind=None, **kwargs)
به عنوان مثال، ما زمان پخت را ترسیم می کنیم:
import pandas as pd
import matplotlib.pyplot as plt
import scipy
menu = pd.read_csv('indian_food.csv')
time = (menu(menu.cook_time != -1))('cook_time')
time.value_counts().plot.kde()
plt.show()
این توزیع به شکل زیر است:

در هیستوگرام در بخش، ما برای گرفتن تمام اطلاعات و دادههای مرتبط با استفاده از binها تلاش کردهایم، زیرا هر بار که دادهها را تعمیم میدهیم و با هم جمع میکنیم – مقداری دقت را از دست میدهیم.
با نمودارهای KDE، ما از مزایای استفاده از تعداد بی نهایت bin ها بهره مند شده ایم. هیچ داده ای از این طریق کوتاه نمی شود یا از بین نمی رود.
ترسیم یک ماتریس پراکندگی (نقشه جفت) در پانداها
روش کمی پیچیده تر برای تفسیر داده ها استفاده است ماتریس های پراکندگی. که راهی برای در نظر گرفتن رابطه هر جفت پارامتر است. اگر با کتابخانه های دیگری کار کرده اید، این نوع طرح ممکن است برای شما آشنا باشد طرح جفت.
برای ترسیم ماتریس پراکندگی، باید این کار را انجام دهیم import را scatter_matrix() تابع از pandas.plotting مدول.
نحو برای scatter_matrix() تابع است:
pandas.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, grid=False, diagonal='hist', marker='.', density_kwds=None, hist_kwds=None, range_padding=0.05, **kwargs)
از آنجایی که ما روابط زوجی را برای چندین کلاس ترسیم می کنیم، روی یک شبکه – تمام خطوط مورب در شبکه منسوخ خواهند شد زیرا ورودی را با خود مقایسه می کند. از آنجایی که این فضای مرده خواهد بود، مورب ها با نمودار توزیع تک متغیره برای آن کلاس جایگزین می شوند.
را diagonal پارامتر می تواند هر دو باشد 'kde' یا 'histبرای هر دو تخمین چگالی هسته یا نمودارهای هیستوگرام
بیایید یک طرح ماتریس پراکندگی بسازیم:
import pandas as pd
import matplotlib.pyplot as plt
import scipy
from pandas.plotting import scatter_matrix
menu = pd.read_csv('indian_food.csv')
scatter_matrix(menu,diagonal='kde')
plt.show()
طرح باید به شکل زیر باشد:
طراحی یک طرح بوت استرپ در پانداها
Pandas همچنین برای نیازهای نقشه کشی شما یک طرح بوت استرپ ارائه می دهد. نمودار بوت استرپ نموداری است که چند آمار مختلف را با اندازه های زیر نمونه متفاوت محاسبه می کند. سپس با داده های انباشته شده روی آمار، خود توزیع آمار را ایجاد می کند.
استفاده از آن به سادگی وارد کردن است bootstrap_plot() روش از pandas.plotting مدول. را bootstrap_plot() نحو عبارت است از:
pandas.plotting.bootstrap_plot(series, fig=None, size=50, samples=500, **kwds)
و در نهایت، بیایید یک طرح بوت استرپ را ترسیم کنیم:
import pandas as pd
import matplotlib.pyplot as plt
import scipy
from pandas.plotting import bootstrap_plot
menu = pd.read_csv('indian_food.csv')
bootstrap_plot(menu('cook_time'))
plt.show()
طرح بوت استرپ چیزی شبیه به این خواهد بود:
نتیجه
در این راهنما، ما به معرفی آن پرداختیم تجسم داده ها در پایتون با پانداها. ما نمودارهای اصلی مانند نمودارهای دایره ای، نمودارهای نواری، پیشرفت به نمودارهای چگالی مانند نمودارهای هیستوگرام و نمودارهای KDE را پوشش داده ایم.
در نهایت، ماتریس های Scatter و Bootstrap Plots را پوشش داده ایم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً کتاب ما را بررسی کنید روی تجسم داده ها در پایتون.
تجسم داده ها در پایتون، کتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را از طریق دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-13 01:58:06
