از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
آ نقشه حرارت یک تکنیک تجسم داده است که از رنگ برای نشان دادن چگونگی تغییر مقدار علاقه بسته به آن استفاده می کند روی مقادیر دو متغیر دیگر
به عنوان مثال، می توانید از یک نقشه حرارتی برای درک اینکه چگونه آلودگی هوا بر اساس زمان روز در مجموعه ای از شهرها متفاوت است استفاده کنید.
مورد دیگر، شاید نادرتر استفاده از نقشه های حرارتی، مشاهده رفتار انسان است – می توانید تجسمی از روش استفاده مردم از رسانه های اجتماعی، روش پاسخ های آنها ایجاد کنید. روی نظرسنجیها در طول زمان تغییر کردند و غیره. این تکنیکها میتوانند برای بررسی الگوهای رفتار، بهویژه برای مؤسسات روانشناختی که معمولاً نظرسنجیهای خودارزیابی را برای بیماران ارسال میکنند، بسیار قدرتمند باشد.
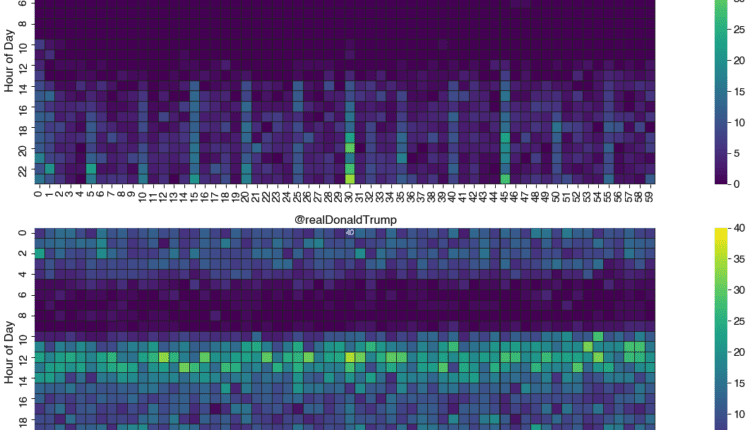
در اینجا دو نقشه حرارتی وجود دارد که تفاوتها را در روش استفاده دو کاربر از توییتر نشان میدهد:

این نمودارها شامل تمام اجزای اصلی یک نقشه حرارتی است. اساساً شبکه ای از مربع های رنگی است که هر مربع یا صندوقچه، تقاطع مقادیر دو متغیر را نشان می دهد که در امتداد محورهای افقی و عمودی امتداد دارند.
در این مثال، این متغیرها عبارتند از:
- ساعت روز
- دقیقه از ساعت
مربع ها بر اساس تعداد توییت هایی که در هر سطل ساعت/دقیقه قرار می گیرند رنگ می شوند. در کنار شبکه افسانه ای وجود دارد که به ما نشان می دهد رنگ چگونه با مقادیر شمارش ارتباط دارد. در این مورد، رنگهای روشنتر (یا گرمتر) به معنای تعداد توییتهای بیشتر و تیرهتر (یا سردتر) به معنای کمتر است. از این رو نام نقشه حرارت!
نقشه های حرارتی برای شناسایی الگوها در مقادیر زیاد داده در یک نگاه بسیار مفید هستند. به عنوان مثال، نوار تیرهتر و سردتر در صبح نشان میدهد که هر دو نامزد قبل از ظهر توییتهای زیادی انجام نمیدهند. همچنین، کاربر دوم خیلی بیشتر از کاربر اول توییت میکند، با خط قطع واضحتر در ساعت 10 صبح، در حالی که کاربر اول چنین خط واضحی ندارد. این را می توان به برنامه ریزی شخصی در طول روز نسبت داد، جایی که کاربر دوم معمولاً برخی از کارهای محول شده را تا ساعت 10 صبح به پایان می رساند و به دنبال آن بررسی می کند. روی شبکه های اجتماعی و استفاده از آن
نقشه های حرارتی اغلب نقطه شروع خوبی برای تحلیل های پیچیده تر است. اما همچنین یک تکنیک تجسم چشم نواز است که آن را به ابزاری مفید برای ارتباط تبدیل می کند.
در این آموزش به شما نشان خواهیم داد که چگونه با استفاده از کتابخانه Seaborn در پایتون، یک نقشه حرارتی مانند تصویر بالا ایجاد کنید.
Seaborn یک کتابخانه تجسم داده ساخته شده است روی بالای Matplotlib. آنها با هم رهبران واقعی در مورد کتابخانه های تجسم در پایتون هستند.
Seaborn یک API سطح بالاتری نسبت به Matplotlib دارد که به ما این امکان را میدهد تا بسیاری از سفارشیسازیها و کارهای کوچکی را که معمولاً باید انجام دهیم تا طرحهای Matplotlib را برای چشم انسان مناسبتر کنیم، خودکار کنیم. همچنین با ساختارهای داده پانداها ادغام می شود، که پیش پردازش و تجسم داده ها را آسان تر می کند. همچنین دارد زیاد نقشه های داخلی، با پیش فرض های مفید و یک ظاهر طراحی جذاب.
در این راهنما، ما سه بخش اصلی را پوشش خواهیم داد:
- آماده سازی داده ها
- ترسیم نقشه حرارتی
- بهترین روش ها و سفارشی سازی نقشه حرارتی
بیا شروع کنیم!
آماده سازی مجموعه داده برای ایجاد یک نقشه حرارتی با Seaborn
بارگیری یک مجموعه داده نمونه با پانداها
لطفا توجه داشته باشید: این راهنما با استفاده از Python 3.8، Seaborn 0.11.0 و Pandas 1.1.2 نوشته شده است.
برای این راهنما، ما از مجموعه داده ای استفاده خواهیم کرد که حاوی مهرهای زمانی توییت های ارسال شده توسط دو تن از نامزدهای ریاست جمهوری 2020 ایالات متحده در آن زمان، جو بایدن و دونالد ترامپ – بین ژانویه 2017 تا سپتامبر 2020 است. شرح مجموعه داده ها و چگونگی آن. ایجاد شده را می توان در یافت اینجا.
یک تمرین سرگرم کننده در خانه می تواند ایجاد مجموعه داده های خود از توییت های خود یا دوستان و مقایسه عادات استفاده از رسانه های اجتماعی شما باشد!
اولین وظیفه ما بارگذاری آن داده ها و تبدیل آنها به شکلی است که Seaborn انتظار دارد و کار کردن با آن برای ما آسان است.
ما از کتابخانه Pandas برای بارگذاری و دستکاری داده ها استفاده خواهیم کرد:
import pandas as pd
ما می توانیم از پانداها استفاده کنیم read_csv() تابعی برای بارگذاری مجموعه داده تعداد توییت. میتوانید URL را که به مجموعه داده اشاره میکند ارسال کنید، یا آن را دانلود کنید و به صورت دستی به فایل ارجاع دهید:
data_url = "https://bit.ly/3cngqgL"
df = pd.read_csv(data_url,
parse_dates=('date_utc'),
dtype={'hour_utc':int,'minute_utc':int,'id':str}
)
همیشه ارزش استفاده از آن را دارد head روش بررسی چند ردیف اول DataFrameبرای آشنایی با شکل آن:
df.head()
| شناسه | نام کاربری | date_utc | ساعت_utc | minute_utc | بازتوییت می کند | |
|---|---|---|---|---|---|---|
| 0 | 815422340540547073 | واقعی دونالد ترامپ | 2017-01-01 05:00:10+00:00 | 5 | 0 | 27134 |
| 1 | 815930688889352192 | واقعی دونالد ترامپ | 2017-01-02 14:40:10+00:00 | 14 | 40 | 23930 |
| 2 | 815973752785793024 | واقعی دونالد ترامپ | 2017-01-02 17:31:17+00:00 | 17 | 31 | 14119 |
| 3 | 815989154555297792 | واقعی دونالد ترامپ | 2017-01-02 18:32:29+00:00 | 18 | 32 | 3193 |
| 4 | 815990335318982656 | واقعی دونالد ترامپ | 2017-01-02 18:37:10+00:00 | 18 | 37 | 7337 |
در اینجا، ما 5 عنصر اول را در صفحه چاپ کرده ایم DataFrame. ابتدا ایندکس هر سطر و به دنبال آن عدد را داریم id از توییت، username کاربری که آن توییت را توییت کرده است و همچنین اطلاعات مربوط به زمان مانند date_utc، hour_utc و minute_utc.
در نهایت، ما به تعداد retweets در پایان، که می تواند برای بررسی روابط جالب بین محتوای توییت ها و “توجه” آن استفاده شود.
تبدیل داده ها به یک فرم گسترده DataFrame
یافتن داده های گزارشی مانند این سازماندهی شده در a معمول است طولانی (یا مرتب) فرم. این بدان معنی است که برای هر متغیر یک ستون وجود دارد و هر ردیف از داده ها یک مشاهده (مقدار خاص) از آن متغیرها است. در اینجا، هر توییت هر متغیر است. هر ردیف مربوط به یک توییت است و حاوی داده هایی در مورد آن است.
اما از نظر مفهومی یک نقشه حرارتی مستلزم آن است که داده ها در یک سازماندهی شوند کوتاه (یا وسیع) فرم. و در واقع کتابخانه Seaborn از ما میخواهد که دادههایی را در این فرم داشته باشیم تا تصویرسازیهای نقشه گرمایی مانند آنچه قبلا دیدهایم تولید کنیم.
فرم عریض داده ها دارای مقادیر متغیرهای مستقل به عنوان سرفصل سطر و ستون هستند در حالی که مقادیر متغیر وابسته در سلول ها موجود است.
این اساساً به این معنی است که ما از تمام ویژگی هایی که مشاهده نمی کنیم به عنوان دسته استفاده می کنیم. به خاطر داشته باشید که برخی از دسته ها بیش از یک بار رخ می دهند. به عنوان مثال، در جدول اصلی، چیزی شبیه به:
| نام کاربری | ساعت_utc | minute_utc |
| واقعی دونالد ترامپ | 12 | 4 |
| واقعی دونالد ترامپ | 13 | 0 |
| واقعی دونالد ترامپ | 12 | 4 |
با استفاده از اصل دسته، میتوانیم وقوع ویژگیهای خاصی را جمع آوری کنیم:
| دسته بندی | ظهور |
| realDonaldTrump | 12 ساعت | 4 دقیقه | 2 |
| realDonaldTrump | 13 ساعت | 0 دقیقه | 1 |
که در نهایت می توانیم آن را به چیزی سازگارتر با نقشه حرارتی تبدیل کنیم:
| ساعت\دقیقه | 0 | 1 | 2 | 3 | 4 |
| 12 | 0 | 0 | 0 | 0 | 2 |
| 13 | 1 | 0 | 0 | 0 | 0 |
در اینجا، ساعتها را بهعنوان ردیف، مقادیر منحصربهفرد، و همچنین دقیقهها بهعنوان ستون داریم. هر مقدار در سلول ها تعداد دفعات توییت در آن زمان است. به عنوان مثال، در اینجا، ما می توانیم 2 توییت در ساعت 12:04 و یک توییت در ساعت 13:01 مشاهده کنیم. با این رویکرد، ما فقط 24 سطر (24 ساعت) و 60 ستون داریم. اگر تصور کنید که این گسترش بصری است، اساساً این گسترش است است هر چند یک نقشه حرارتی با اعداد.
در مثال ما میخواهم بفهمم آیا الگوهایی برای روش توییت کردن نامزدها در زمانهای مختلف روز وجود دارد یا خیر. یکی از راه های انجام این کار، شمارش توییت های ایجاد شده در هر ساعت از روز و هر دقیقه از یک ساعت است.
از نظر فنی، ما 2880 دسته داریم. هر ترکیبی از hour_utc، minute_utc و username یک دسته جداگانه است و ما برای هر یک از آنها تعداد توییت ها را می شماریم.
این تجمیع با استفاده از پانداها مستقیم است. ساعت و دقیقه ایجاد در ستون ها موجود است hour_utc و minute_utc. ما می توانیم از پانداها استفاده کنیم groupby() عملکرد جمع آوری تمام توییت ها برای هر ترکیبی از username، hour_utc، و minute_utc:
g = df.groupby(('hour_utc','minute_utc','username'))
این بدان معنی است که فقط ردیف هایی که دارای ارزش یکسانی هستند
hour_utc،minute_utc،usernameرا می توان اتفاقی از همین دسته در نظر گرفت.
اکنون میتوانیم تعداد توییتهای هر گروه را با استفاده از آن بشماریم nunique() تابع برای شمارش تعداد منحصر به فرد idس این روش از شمارش مضاعف هر گونه توییت تکراری که ممکن است در داده ها پنهان شود، در صورتی که از قبل به درستی پاک نشده باشد، جلوگیری می کند:
tweet_cnt = g.id.nunique()
این یک سری پانداها را با تعداد مورد نیاز برای ترسیم نقشه حرارتی به ما می دهد:
tweet_cnt.head()
hour_utc minute_utc username
0 0 JoeBiden 26
realDonaldTrump 6
1 JoeBiden 16
realDonaldTrump 11
2 JoeBiden 6
Name: id, dtype: int64
برای تبدیل این به شکل گسترده DataFrame مورد نیاز Seaborn ما می توانیم از پانداها استفاده کنیم pivot() تابع.
برای این مثال، گرفتن یک کاربر در یک زمان و ترسیم یک نقشه حرارتی برای هر یک از آنها به طور جداگانه آسانتر خواهد بود. ما می توانیم این را قرار دهیم روی یک شکل واحد یا مجزا.
از پانداها استفاده کنید loc() accessor برای انتخاب تعداد توییت های یک کاربر و سپس اعمال آن pivot() تابع. از مقادیر منحصر به فرد از شاخص/ستون های مشخص شده برای تشکیل محورهای حاصل استفاده می کند DataFrame. ساعتها و دقیقهها را بهگونهای تنظیم میکنیم که نتیجه حاصل شود DataFrame شکل گسترده ای دارد:
jb_tweet_cnt = tweet_cnt.loc(:,:,'JoeBiden').reset_index().pivot(index='hour_utc', columns='minute_utc', values='id')
سپس به بخشی از حاصل نگاه کنید DataFrame:
jb_tweet_cnt.iloc(:10,:9)
| minute_utc | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| ساعت_utc | |||||||||
| 0 | 26.0 | 16.0 | 6.0 | 7.0 | 4.0 | 24.0 | 2.0 | 2.0 | 9.0 |
| 1 | 24.0 | 7.0 | 5.0 | 6.0 | 4.0 | 19.0 | 1.0 | 2.0 | 6.0 |
| 2 | 3.0 | 3.0 | 3.0 | NaN | 5.0 | 1.0 | 4.0 | 8.0 | NaN |
| 3 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 | 1.0 | 3.0 | 5.0 | 4.0 |
| 4 | 1.0 | 1.0 | 1.0 | 2.0 | NaN | NaN | 1.0 | 1.0 | 1.0 |
| 5 | 1.0 | 2.0 | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN |
| 6 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 10 | 7.0 | 2.0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 11 | 2.0 | 5.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 12 | 4.0 | NaN | 1.0 | 1.0 | 1.0 | NaN | 1.0 | NaN | NaN |
مقابله با ارزش های گمشده
در بالا می بینیم که داده های تبدیل شده ما حاوی مقادیر گم شده است. هر جا که توییتی برای یک معین وجود نداشت دقیقه/ساعت ترکیب pivot() تابع یک عدد Not-a-Number را وارد می کند (NaN) ارزش به DataFrame.
علاوه بر این pivot() وقتی برای یک ساعت (یا دقیقه) اصلا توییتی وجود نداشت، سطر (یا ستون) ایجاد نمی کند.
ساعت های بالا را ببینید
7،8و9گم شده اند.
این یک اتفاق معمول در هنگام پیش پردازش داده خواهد بود. داده ها ممکن است گم شده باشند، ممکن است از انواع یا ورودی های عجیب و غریب باشند (بدون تایید) و غیره.
Seaborn میتواند این دادههای از دست رفته را به خوبی مدیریت کند، بدون آنها رسم میکند و از ساعتهای 7، 8 و 9 صرفنظر میکند. با این حال، اگر مقادیر از دست رفته را پر کنیم، نقشههای حرارتی ما سازگارتر و قابل تفسیرتر خواهند بود. در این مورد می دانیم که مقادیر از دست رفته واقعاً یک شمارش صفر هستند.
برای پر کردن NaNمواردی که قبلاً درج شده اند، استفاده کنید fillna() مانند:
jb_tweet_cnt.fillna(0, inplace=True)
برای درج ردیفهای از دست رفته – مطمئن شوید که تمام ترکیبهای ساعت و دقیقه در نقشه حرارتی ظاهر میشوند – ما reindex() را DataFrame برای درج شاخص های گمشده و مقادیر آنها:
jb_tweet_cnt = jb_tweet_cnt.reindex(range(0,24), axis=0, fill_value=0)
jb_tweet_cnt = jb_tweet_cnt.reindex(range(0,60), axis=1, fill_value=0).astype(int)
عالی. اکنون میتوانیم آمادهسازی دادههای خود را با تکرار مراحل مشابه برای سایر توییتهای نامزدها تکمیل کنیم:
dt_tweet_cnt = tweet_cnt.loc(:,:,'realDonaldTrump').reset_index().pivot(index='hour_utc', columns='minute_utc', values='id')
dt_tweet_cnt.fillna(0, inplace=True)
dt_tweet_cnt = dt_tweet_cnt.reindex(range(0,24), axis=0, fill_value=0)
dt_tweet_cnt = dt_tweet_cnt.reindex(range(0,60), axis=1, fill_value=0).astype(int)
ایجاد یک نقشه حرارتی اولیه با استفاده از متولد دریا
اکنون که داده ها را آماده کرده ایم، ترسیم نقشه حرارتی با استفاده از Seaborn آسان است. ابتدا مطمئن شوید که کتابخانه Seaborn را وارد کرده اید:
import seaborn as sns
import matplotlib.pyplot as plt
ما نیز خواهیم کرد import ماژول PyPlot Matplotlib، زیرا Seaborn متکی است روی آن را به عنوان موتور اساسی. پس از ترسیم نمودارهایی با توابع Seaborn کافی، ما همیشه تماس خواهیم گرفت plt.show() تا در واقع این طرح ها را نشان دهد.
اکنون، طبق معمول Seaborn، رسم داده ها به سادگی ارسال یک آماده است DataFrame به تابعی که می خواهیم استفاده کنیم. به طور خاص، ما از heatmap() تابع.
بیایید یک نقشه حرارتی ساده از فعالیت ترامپ ترسیم کنیم روی توییتر:
sns.heatmap(dt_tweet_cnt)
plt.show()

و سپس فعالیت بایدن:
sns.heatmap(jb_tweet_cnt)
plt.show()

نقشه های حرارتی تولید شده با استفاده از تنظیمات پیش فرض Seaborn بلافاصله قابل استفاده هستند. آنها همان الگوهایی را نشان میدهند که در نمودارهای ابتدای راهنما دیده میشوند، اما کمی متلاطمتر، کوچکتر هستند و برچسبهای محورها با فرکانس فرد ظاهر میشوند.
به کنار، ما می توانیم این الگوها را ببینیم زیرا Seaborn کارهای زیادی را برای ما انجام می دهد، به طور خودکار، فقط با تماس با heatmap() تابع:
- انتخاب های مناسبی از پالت رنگ و مقیاس انجام داد
- افسانه ای برای ارتباط رنگ ها با مقادیر زیربنایی ایجاد کرد
- بر محورها برچسب زد
این پیشفرضها ممکن است برای اهداف و بررسی اولیه شما، بهعنوان یک علاقهمند یا دانشمند داده، کافی باشند. اما اغلب اوقات، تولید یک نقشه حرارتی واقعا مؤثر مستلزم آن است که ارائه را سفارشی کنیم تا نیازهای مخاطبان را برآورده کنیم.
بیایید نگاهی بیندازیم که چگونه میتوانیم نقشه حرارتی Seaborn را برای تولید نقشههای حرارتی که در ابتدای راهنما مشاهده میکنید، سفارشی کنیم.
روش سفارشی سازی a متولد دریا نقشه حرارت
استفاده موثر از رنگ
مشخصه تعیین کننده یک نقشه حرارتی استفاده از رنگ برای نشان دادن مقدار یک کمیت زیربنایی است.
به راحتی می توان رنگ هایی را که Seaborn برای ترسیم نقشه حرارتی استفاده می کند، با تعیین رنگ اختیاری تغییر داد cmap پارامتر (colormap). به عنوان مثال، در اینجا روش تغییر به 'mako' پالت رنگ:
sns.heatmap(dt_tweet_cnt, cmap="mako")
plt.show()

Seaborn پالتهای داخلی زیادی را ارائه میکند که میتوانید از بین آنها انتخاب کنید، اما باید مراقب باشید که یک پالت خوب برای دادهها و هدف خود انتخاب کنید.
برای نقشه های حرارتی که داده های عددی را نشان می دهد – مانند ما – متوالی پالت هایی مانند پیش فرض 'rocket' یا 'mako' انتخاب های خوبی هستند دلیل آن این است که رنگ های موجود در این پالت ها به گونه ای انتخاب شده اند از نظر ادراکی یکنواخت. این بدان معناست که تفاوتی که ما بین دو رنگ با چشم خود درک می کنیم با تفاوت بین مقادیر زیرین متناسب است.
نتیجه این است که با نگاهی اجمالی به نقشه میتوانیم احساسی فوری برای توزیع مقادیر در دادهها داشته باشیم.
یک مثال متقابل مزایای یک پالت یکنواخت ادراکی و مشکلات انتخاب ضعیف پالت را نشان می دهد. در اینجا همان نقشه حرارتی است که با استفاده از آن ترسیم شده است tab10 جعبه رنگ نقاشی:
sns.heatmap(dt_tweet_cnt, cmap="tab10")
plt.show()

این پالت برای مثال ما انتخاب ضعیفی است زیرا اکنون باید برای درک رابطه بین رنگ های مختلف واقعاً سخت کار کنیم. تا حد زیادی الگوهایی را که قبلا آشکار بودند پنهان کرده است!
این به این دلیل است که tab10 پالت از تغییرات در رنگ استفاده می کند تا تشخیص بین دسته ها را آسان کند. اگر مقادیر نقشه حرارتی شما طبقه بندی شده باشد، ممکن است انتخاب خوبی باشد.
اگر به مقادیر کم و زیاد در داده های خود علاقه مند هستید، می توانید از a استفاده کنید واگرا پالت مانند coolwarm یا icefire که یک طرح یکنواخت است که هر دو حد را برجسته می کند.
برای اطلاعات بیشتر روی با انتخاب پالتهای رنگی، اسناد Seaborn دارای مقداری هستند راهنمایی مفید.
کنترل اثر اعوجاج پرت
نقاط پرت در داده ها می توانند هنگام ترسیم نقشه های حرارتی مشکل ایجاد کنند. بهطور پیشفرض Seaborn مرزهای مقیاس رنگ را روی حداقل و حداکثر مقدار در دادهها تنظیم میکند.
این بدان معنی است که مقادیر بسیار بزرگ (یا کوچک) در داده ها می تواند باعث مبهم شدن جزئیات شود. هر چه نقاط پرت شدیدتر باشد، از مرحله رنگ آمیزی یکنواخت دورتر هستیم. ما دیدیم که این چه تاثیری می تواند با نقشه های رنگی مختلف داشته باشد.
به عنوان مثال، اگر یک مقدار پرت شدید اضافه کنیم، مانند 400 تکرار توییت در یک دقیقه – آن نقطه پرت، گسترش رنگ را تغییر داده و آن را به طور قابل توجهی مخدوش می کند:

یکی از راههای مدیریت مقادیر شدید بدون نیاز به حذف آنها از مجموعه داده، استفاده از اختیاری است robust پارامتر. تنظیمات robust به True باعث می شود Seaborn به جای حداکثر و حداقل، مرزهای مقیاس رنگ را در مقادیر صدک 2 و 98 داده ها تنظیم کند. این در اکثر موارد، رنگ پخش شده را به حالت بسیار قابل استفاده تری عادی می کند.
توجه داشته باشید که در مثال ما، این محدوده وقوع/رنگ گسترش از 0..16، به عنوان مخالف 0..40 از قبل. این نیست ایده آل، اما یک راه حل سریع و آسان برای مقادیر شدید است.
که می تواند جزئیات را به عنوان مثال بازگرداند روی درست نشان می دهد توجه داشته باشید که نقطه بسیار با ارزش همچنان در نمودار وجود دارد. مقادیر بالاتر یا پایینتر از مرزهای مقیاس رنگ به رنگهای انتهای مقیاس بریده میشوند.
همچنین می توان با تنظیم مقادیر پارامترها، مرزهای مقیاس رنگ را به صورت دستی تنظیم کرد. vmin و vmax. اگر برنامه ریزی داشته باشید می تواند بسیار مفید باشد روی داشتن دو نقشه حرارتی در کنار هم و می خواهید از مقیاس رنگی یکسان برای هر کدام اطمینان حاصل کنید:
sns.heatmap(tmp, vmin=0, vmax=40)
plt.show()
ترکیب: مرتب سازی محورها به روابط سطحی
در مثال ما، مقادیری که محورهای نقشه حرارتی ما را تشکیل میدهند، ساعتها و دقیقهها، دارای نظم طبیعی هستند. توجه به این نکته مهم است که این مقادیر گسسته و پیوسته نیستند و می توان آنها را برای کمک به الگوهای سطحی در داده ها بازآرایی کرد.
بهعنوان مثال، بهجای اینکه دقیقهها را به ترتیب صعودی معمولی داشته باشیم، میتوانیم آنها را بر اساس مرتب کنیم روی کدام دقیقه بیشترین تعداد توییت را دارد:

این ارائه جدید و جایگزین داده های تعداد توییت ها را ارائه می دهد. از اولین نقشه حرارتی، می بینیم که بایدن ترجیح می دهد توییت کند روی علامت یک چهارم (30، 45، 0 و 15 از ساعت گذشته)، مشابه این که چگونه افراد خاصی صدای تلویزیون خود را با افزایش 5 تنظیم می کنند، یا اینکه چه تعداد از افراد تمایل دارند برای شروع یک کار “برای زمان مناسب منتظر بمانند” – معمولا روی یک عدد گرد یا یک چهارم
از سوی دیگر، به نظر نمی رسد دقیقه مطلوبی در هیت مپ دوم وجود داشته باشد. در تمام دقایق ساعت پخش کاملاً ثابتی وجود دارد و الگوهای زیادی وجود ندارد که بتوان آنها را مشاهده کرد.
در زمینههای دیگر، ترتیب دقیق و/یا گروهبندی متغیرهای طبقهبندی که محورهای نقشه حرارتی را تشکیل میدهند میتواند در برجسته کردن الگوها در دادهها و افزایش چگالی اطلاعات نمودار مفید باشد.
اضافه کردن حاشیه نویسی ارزش
یکی از نقاط ضعف نقشه های حرارتی این است که مقایسه مستقیم بین مقادیر دشوار است. نمودار میله ای یا خطی راه بسیار ساده تری برای انجام این کار است.
با این حال، می توان با اضافه کردن حاشیه نویسی به Heatmap برای نشان دادن مقادیر زیر، این مشکل را کاهش داد. این کار به راحتی در Seaborn با تنظیم کردن انجام می شود annot پارامتر به True، مثل این:
sns.heatmap(jb_tweet_cnt.iloc(14:23,25:35), annot=True)
plt.show()

ما دادهها را در مجموعهای کوچکتر برش دادهایم تا مشاهده و مقایسه برخی از این سطلها آسانتر شود. در اینجا، اکنون هر bin با مقادیر اساسی حاشیه نویسی شده است، که مقایسه آنها را بسیار ساده تر می کند. اگرچه به اندازه نمودار خطی یا نمودار میله ای طبیعی و شهودی نیست، اما هنوز مفید است.
ترسیم این مقادیر روی کل نقشه حرارتی ما غیرعملی خواهد بود، زیرا اعداد برای خواندن بسیار کوچک هستند.
یک مصالحه مفید ممکن است اضافه کردن حاشیه نویسی فقط برای برخی از مقادیر جالب باشد. در مثال زیر، اجازه دهید یک حاشیه نویسی فقط برای حداکثر مقدار اضافه کنیم.
این کار با ایجاد مجموعه ای از برچسب های حاشیه نویسی که می توانند به Seaborn منتقل شوند، انجام می شود heatmap() عملکرد از طریق annot پارامتر. را annot_kws پارامتر همچنین می تواند برای کنترل جنبه هایی از برچسب مانند اندازه فونت استفاده شده استفاده شود:
M = jb_tweet_cnt.iloc(14:23,25:35).values.max()
labels = jb_tweet_cnt.iloc(14:23,25:35).applymap(lambda v: str(v) if v == M else '')
sns.heatmap(jb_tweet_cnt.iloc(14:23,25:35), annot=labels, annot_kws={'fontsize':16}, fmt='')
plt.show()

می توانید در تعریف مجموعه برچسب های سفارشی خلاق باشید. تنها محدودیت این است که دادههایی که برای برچسبها ارسال میکنید باید به اندازه دادههایی باشد که رسم میکنید. همچنین، اگر برچسبهای شما رشتهای هستند، باید از آن عبور کنید fmt='' پارامتری برای جلوگیری از Seaborn از تفسیر برچسب های شما به عنوان اعداد.
خطوط شبکه و مربع
گاهی اوقات این کمک می کند که به مخاطب خود یادآوری کنید که یک نقشه حرارتی مبتنی است روی سطل هایی با مقادیر گسسته با برخی از مجموعههای داده، رنگ بین دو سطل میتواند بسیار شبیه باشد، و بافتی شیبمانند ایجاد میکند که تشخیص بین مقادیر خاص را سختتر میکند. پارامترها linewidth و linecolor می توان از آن برای افزودن خطوط شبکه به نقشه حرارتی استفاده کرد.
در رگ مشابه پارامتر square می توان برای وادار کردن نسبت ابعاد مربع ها به درستی استفاده کرد. به خاطر داشته باشید که نیازی به استفاده از مربع برای سطل نیست.
بیایید یک خط سفید نازک بین هر سطل اضافه کنیم تا تأکید کنیم که آنها ورودی های جداگانه هستند:
sns.heatmap(jb_tweet_cnt.iloc(14:23,25:35), linewidth=1, linecolor='w', square=True)
plt.show()

در هر یک از این موارد، این به قضاوت شما بستگی دارد که آیا این تغییرات زیبایی شناختی به اهداف تجسم شما کمک می کند یا خیر.
نقشه های حرارتی طبقه بندی شده در Seaborn
مواقعی وجود دارد که ساده کردن یک نقشه حرارتی با قرار دادن دادههای عددی در دستهها مفید است. برای مثال میتوانیم دادههای تعداد توییتها را فقط در سه دسته قرار دهیم 'high'، 'medium'، و 'low'، به جای یک محدوده عددی مانند 0..40.
متأسفانه در زمان نگارش، Seaborn توانایی داخلی برای تولید نقشه های حرارتی برای داده های طبقه بندی شده مانند این را ندارد زیرا انتظار ورودی عددی را دارد. در اینجا یک قطعه کد وجود دارد که نشان می دهد امکان “جعل” آن با هک کردن کمی پالت و نوار رنگ وجود دارد.
اگرچه این یکی از شرایطی است که ممکن است بخواهید شایستگی سایر بستههای تجسمی را که دارای چنین ویژگیهایی هستند در نظر بگیرید.
ما از یک دست یاری از Matplotlib استفاده خواهیم کرد، موتور زیربنایی در زیر Seaborn زیرا گزینه های سفارشی سازی سطح پایین زیادی دارد و ما به آن دسترسی کامل داریم. در اینجا، ما می توانیم افسانه را “هک” کنیم روی حق نمایش مقادیری که می خواهیم:
import matplotlib.pyplot as plt
fig,ax = plt.subplots(1,1,figsize=(18,8))
my_colors=((0.2,0.3,0.3),(0.4,0.5,0.4),(0.1,0.7,0),(0.1,0.7,0))
sns.heatmap(dt_tweet_cnt, cmap=my_colors, square=True, linewidth=0.1, linecolor=(0.1,0.2,0.2), ax=ax)
colorbar = ax.collections(0).colorbar
M=dt_tweet_cnt.max().max()
colorbar.set_ticks((1/8*M,3/8*M,6/8*M))
colorbar.set_ticklabels(('low','med','high'))
plt.show()

آماده سازی نقشه های حرارتی برای ارائه
چند مرحله آخر برای انجام کارهای نهایی روی نقشه حرارتی شما
استفاده از Seaborn Context برای کنترل ظاهر
را set_context() تابع راه مفیدی برای کنترل برخی از عناصر طرح بدون تغییر سبک کلی آن فراهم می کند. به عنوان مثال می تواند یک راه راحت برای سفارشی کردن اندازه فونت و خانواده باشد.
چند وجود دارد زمینه های از پیش تعیین شده در دسترس است:
sns.set_context("notebook", font_scale=1.75, rc={"lines.linewidth": 2.5, 'font.family':'Helvetica'})
استفاده از طرحهای فرعی برای کنترل طرحبندی نقشههای حرارتی
مرحله آخر در ایجاد نقشه حرارتی تعداد توییت ها، قرار دادن دو نمودار در کنار یکدیگر در یک شکل است تا مقایسه بین آنها آسان باشد.
ما می توانیم استفاده کنیم subplot() ویژگی matplotlib.pyplot برای کنترل طرح نقشه های حرارتی در Seaborn. این به شما حداکثر کنترل را بر روی گرافیک نهایی می دهد و به شما امکان می دهد تا کار را آسان کنید export از تصویر
ایجاد نمودارهای فرعی با استفاده از Matplotlib به آسانی تعریف شکل آنهاست (در مورد ما 2 قطعه فرعی در 1 ستون):
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12,12))
sns.heatmap(jb_tweet_cnt, ax=ax1)
sns.heatmap(dt_tweet_cnt, ax=ax2)
plt.show()

این اساساً همین است، اگرچه فاقد برخی از استایلهایی است که در ابتدا دیدهایم. بیایید بسیاری از سفارشیسازیهایی را که در راهنما دیدهایم گرد هم بیاوریم تا طرح نهایی خود را تولید کنیم export آن را به عنوان یک .png برای اشتراک گذاری:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2, 1, figsize=(24,12))
for i,d in enumerate((jb_tweet_cnt,dt_tweet_cnt)):
labels = d.applymap(lambda v: str(v) if v == d.values.max() else '')
sns.heatmap(d,
cmap="viridis",
annot=jb_labels,
annot_kws={'fontsize':11},
fmt='',
square=True,
vmax=40,
vmin=0,
linewidth=0.01,
linecolor="#222",
ax=ax(i),
)
ax(0).set_title('@JoeBiden')
ax(1).set_title('@realDonaldTrump')
ax(0).set_ylabel('Hour of Day')
ax(1).set_ylabel('Hour of Day')
ax(0).set_xlabel('')
ax(1).set_xlabel('Minute of Hour')
plt.tight_layout()
plt.savefig('final.png', dpi=120)
نتیجه
در این راهنما به نقشه های حرارتی و روش ایجاد آنها با پایتون و کتابخانه تجسم Seaborn نگاه کردیم.
نقطه قوت نقشه های حرارتی در روش استفاده از رنگ برای انتقال اطلاعات است، به عبارت دیگر، دیدن الگوهای گسترده را برای هر کسی آسان می کند.
ما دیدیم که چگونه برای انجام این کار باید پالت رنگ و مقیاس را با دقت انتخاب کنیم. همچنین دیدهایم که تعدادی گزینه برای سفارشیسازی نقشه حرارتی با استفاده از Seaborn وجود دارد تا بر جنبههای خاصی از نمودار تأکید شود. اینها عبارتند از حاشیه نویسی، گروه بندی و ترتیب محورهای طبقه بندی، و طرح.
مثل همیشه، قضاوت تحریریه روی بخشی از Data Visualizer برای انتخاب مناسب ترین سفارشی سازی ها برای زمینه تجسم مورد نیاز است.
انواع مختلفی از نقشه حرارتی وجود دارد که ممکن است به مطالعه آنها علاقه مند باشید، از جمله نقشه های حرارتی شعاعی، نمودارهای موزاییکی یا نمودارهای ماتریسی.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-13 11:52:04
