از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
«tab» به عنوان جداکننده در فایل جداشده با برگه استفاده میشود. این نوع فایل متنی برای ذخیره انواع مختلف داده های متنی در قالب ساختار یافته ایجاد می شود. انواع مختلفی از دستورات در لینوکس برای تجزیه این نوع فایل ها وجود دارد. دستور «awk» یکی از راههای تجزیه فایل جداشده با تب به روشهای مختلف است. موارد استفاده از دستور awk برای خواندن فایل جدا شده با برگه در این آموزش نشان داده شده است.
یک فایل جدا شده با برگه ایجاد کنید:
یک فایل متنی با نام ایجاد کنید users.txt با مطالب زیر برای تست دستورات این آموزش. این فایل شامل نام، ایمیل، نام کاربری و رمز عبور کاربر است.
users.txt
نام ایمیل نام کاربری رمز عبور
دکتر رابین robin@gmail.com robin89 563425
نیلا حسن nila@gmail.com nila78 245667
میرزا عباس mirza@gmail.com mirza23 534788
Aornob Hasan aornob@gmail.com arnob45 778473
Nuhas Ahsan nuhas@gmail.com nuhas34 563452
مثال-1: ستون دوم یک فایل جدا شده با برگه را با استفاده از گزینه -F چاپ کنید
دستور sed زیر خواهد بود print ستون دوم یک فایل متنی جدا شده با برگه. اینجا ‘-F’ از گزینه برای تعریف جداکننده فیلد فایل استفاده می شود.
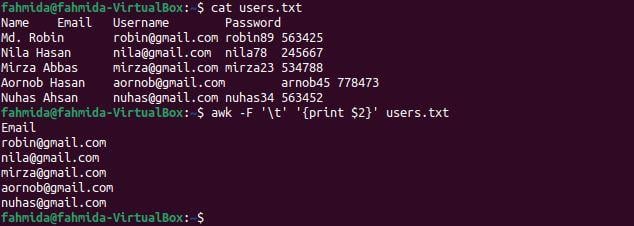
$ گربه users.txt
$ بیخیال -اف ‘\t’ ‘{print $2} users.txt
پس از اجرای دستورات خروجی زیر ظاهر می شود. ستون دوم فایل شامل آدرس های ایمیل کاربر است که به عنوان خروجی نمایش داده می شود.

مثال-2: با استفاده از متغیر FS، اولین ستون یک فایل جدا شده با تب را چاپ کنید
دستور sed زیر خواهد بود print اولین ستون یک فایل متنی جدا شده با برگه. اینجا، FS متغیر (Field Separator) برای تعریف جداکننده فیلد فایل استفاده می شود.
$ گربه users.txt
$ بیخیال ‘{ print $1 }’ FS=‘\t’ users.txt
پس از اجرای دستورات خروجی زیر ظاهر می شود. ستون اول فایل شامل نام کاربر است که به عنوان خروجی نمایش داده می شود.

مثال-3: ستون سوم یک فایل جدا شده با برگه را با قالب بندی چاپ کنید
دستور sed زیر خواهد بود print ستون سوم فایل متنی جدا شده با برگه با قالب بندی با استفاده از FS متغیر و printf. اینجا FS متغیر برای تعریف جداکننده فیلد فایل استفاده می شود.
$ گربه users.txt
$ بیخیال ‘BEGIN{FS=”\t”} {printf “%10s\n”, $3}” users.txt
پس از اجرای دستورات خروجی زیر ظاهر می شود. ستون سوم فایل شامل نام کاربری است که در اینجا چاپ شده است.

مثال-4: با استفاده از OFS ستون های سوم و چهارم فایل جدا شده با برگه را چاپ کنید.
OFS (Output Field Separator) برای اضافه کردن یک جداکننده میدان در خروجی استفاده می شود. دستور awk زیر محتوای فایل را بر اساس تقسیم می کند روی جداکننده tab(\t) و print ستون های 3 و 4 با استفاده از tab(\t) به عنوان جداکننده.
$ گربه users.txt
$ بیخیال -اف “\ t“ ‘OFS=”\t” {print $3, $4 > (“output.txt”)}” users.txt
$ گربه output.txt
پس از اجرای دستورات بالا خروجی زیر ظاهر می شود. ستون های 3 و 4 حاوی نام کاربری و رمز عبور هستند که در اینجا چاپ شده اند.

مثال-5: محتوای خاص فایل جدا شده با برگه را جایگزین کنید
تابع sub() در `awk برای دستور تعویض استفاده می شود. دستور awk زیر عدد 45 را جستجو می کند و در صورت وجود شماره جستجو در فایل، عدد 90 را جایگزین می کند. پس از تعویض، محتوای فایل در فایل output.txt ذخیره می شود.
$ گربه users.txt
$ بیخیال -اف “\ t“‘{sub(/45/,90);print}’ users.txt > output.txt
$ گربه output.txt
پس از اجرای دستورات بالا خروجی زیر ظاهر می شود. فایل output.txt محتوای اصلاح شده را پس از اعمال جایگزینی نشان می دهد. در اینجا محتوای خط 5 تغییر کرده است و ‘arnob45’ به ‘arnob90’ تغییر یافته است.

مثال-6: در ابتدای هر خط از یک فایل جدا شده با زبانه، رشته اضافه کنید
در ادامه، دستور awk، از گزینه ی «-F» برای تقسیم محتوای فایل بر اساس استفاده می شود. روی زبانه (\t). OFS برای اضافه کردن کاما(،) به عنوان جداکننده فیلد در خروجی استفاده کرده است. تابع sub() برای اضافه کردن رشته ‘—→’ در ابتدای هر خط خروجی استفاده می شود.
$ گربه users.txt
$ بیخیال -اف “\ t“ ‘{{OFS=”,”};sub(/^/، “—->”);print $1, $2, $3}’ users.txt
پس از اجرای دستورات بالا خروجی زیر ظاهر می شود. هر مقدار فیلد با کاما(،) جدا می شود و در ابتدای هر خط یک رشته اضافه می شود.

مثال-7: با استفاده از تابع gsub، مقدار یک فایل جدا شده با تب را جایگزین کنید.
تابع gsub() در دستور awk برای جایگزینی سراسری استفاده می شود. تمام مقادیر رشته فایل در جایی که الگوی جستجو مطابقت دارد جایگزین می شود. تفاوت اصلی بین توابع sub() و gsub() در این است که تابع ()sub پس از یافتن اولین تطابق، کار جایگزینی را متوقف می کند و تابع ()gsub الگوی انتهای فایل را برای جایگزینی جستجو می کند. دستور «awk» زیر کلمه «nila» و «Mira» را به صورت سراسری در فایل جستجو میکند و همه موارد را با متن «نام نامعتبر» جایگزین میکند، جایی که کلمه جستجوگر مطابقت دارد.
$ گربه users.txt
$ بیخیال -F ‘\t’ ‘{gsub(/nila|Mira/، “نام نامعتبر”); print}’ users.txt
پس از اجرای دستورات بالا خروجی زیر ظاهر می شود. کلمه “nila” دو بار در خط 3 فایل وجود دارد که در خروجی با کلمه “Invalid Name” جایگزین شده است.

مثال-8: محتوای قالب بندی شده را از یک فایل جدا شده با برگه چاپ کنید
دستور awk زیر خواهد بود print ستون اول و دوم فایل با قالب بندی با استفاده از printf. خروجی با قرار دادن آدرس ایمیل در داخل پرانتز، نام کاربر را نشان می دهد.
$ گربه users.txt
$ بیخیال -اف ‘\t’ ‘{printf “%s(%s)\n”, $1,$2}” users.txt
پس از اجرای دستورات بالا خروجی زیر ظاهر می شود.

نتیجه
با استفاده از دستور awk می توان هر فایل جدا شده با تب را به راحتی تجزیه و با جداکننده دیگری چاپ کرد. روش های تجزیه فایل های جدا شده با تب و چاپ در فرمت های مختلف در این آموزش با استفاده از مثال های متعدد نشان داده شده است. استفاده از توابع sub() و gsub() در دستور awk برای جایگزینی محتوای فایل جدا شده با تب نیز در این آموزش توضیح داده شده است. امیدوارم این آموزش به خوانندگان کمک کند تا پس از تمرین صحیح نمونه های این آموزش، فایل جدا شده از برگه را به راحتی تجزیه و تحلیل کنند.
برای نگارش بخشهایی از این متن ممکن است از ترجمه ماشینی یا هوش مصنوعی GPT استفاده شده باشد
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
لطفا در صورت وجود مشکل در متن یا مفهوم نبودن توضیحات، از طریق دکمه گزارش نوشتار یا درج نظر روی این مطلب ما را از جزییات مشکل مشاهده شده مطلع کنید تا به آن رسیدگی کنیم
زمان انتشار: 1402-12-31 07:39:04
