از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
K-Means یکی از محبوب ترین الگوریتم های خوشه بندی است. با داشتن نقاط مرکزی در یک خوشه، نقاط دیگر را بر اساس گروه بندی می کند روی فاصله آنها تا آن نقطه مرکزی
یک نقطه ضعف K-Means این است که باید تعداد خوشه ها را انتخاب کنید. ک، قبل از اجرای الگوریتمی که نقاط را گروه بندی می کند.
اگر مایلید راهنمای عمیقی برای K-Means Clustering بخوانید، نگاهی به “K-Means Clustering with Scikit Learn” بیندازید.
روش آرنج و تحلیل سیلوئت
متداول ترین تکنیک های مورد استفاده برای انتخاب تعداد K ها هستند روش آرنج و تحلیل سیلوئت.
برای تسهیل انتخاب Ks، آجر زرد کتابخانه کد را با حلقه های for و نموداری که معمولاً در 4 خط کد می نویسیم جمع می کند.
برای نصب Yellowbrick به طور مستقیم از a Jupyter notebook، اجرا کن:
! pip install yellowbrick
بیایید ببینیم که چگونه برای یک مجموعه داده آشنا که قبلاً بخشی از Scikit Learn است، کار می کند عنبیه مجموعه داده
اولین قدم این است که import مجموعه داده، KMeans و yellowbrick کتابخانه ها و بارگذاری داده ها:
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer, SilhouetteVisualizer
iris = load_iris()
به اینجا توجه کنید، ما import را KElbowVisualizer و SilhouetteVisualizer از جانب yellowbrick.cluster، اینها ماژول هایی هستند که برای تجسم نتایج Elbow و Silhouette استفاده خواهیم کرد!
پس از بارگذاری مجموعه داده، در data کلید دسته (نوع داده ای که پسوند یک فرهنگ لغت است) مقادیر نقاطی هستند که می خواهیم خوشه بندی کنیم. اگر می خواهید بدانید اعداد نشان دهنده چیست، نگاهی به آن بیندازید iris('feature_names').
مشخص است که مجموعه داده عنبیه شامل سه نوع عنبیه است: ‘versicolor’، ‘virginica’ و ‘setosa’. همچنین می توانید کلاس های داخل را بررسی کنید iris('target_names') به منظور بررسی.
بنابراین، ما 4 ویژگی برای خوشه بندی داریم و باید آنها را با توجه به آنچه قبلاً می دانیم به 3 خوشه مختلف تقسیم کنیم. بیایید ببینیم که آیا نتایج ما با روش آرنج و تجزیه و تحلیل Silhouette آن را تأیید می کند یا خیر.
ابتدا مقادیر ویژگی را انتخاب می کنیم:
print(iris('feature_names'))
print(iris('target_names'))
X = iris('data')
سپس، می توانیم a ایجاد کنیم KMeans مدل، الف KElbowVisualizer() نمونه ای که آن مدل را به همراه تعداد ks که یک متریک برای آن محاسبه می شود، دریافت می کند، در این مورد از 2 تا 11 Ks.
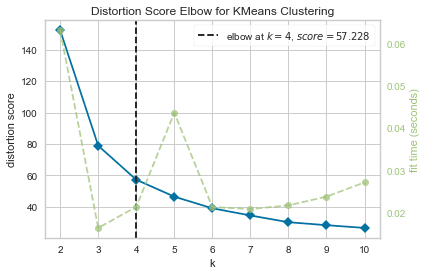
پس از آن، ما ویژوالایزر را با داده های استفاده شده مطابقت می دهیم fit() و نمایش طرح با show(). اگر معیاری مشخص نشده باشد، ویژوالایزر از آن استفاده می کند اعوجاج متریک، که مجموع مسافت های مجذور هر نقطه تا مرکز اختصاص داده شده را محاسبه می کند:
model = KMeans(random_state=42)
elb_visualizer = KElbowVisualizer(model, k=(2,11))
elb_visualizer.fit(X)
elb_visualizer.show()

در حال حاضر، ما در حال حاضر یک زانو نمره اعوجاج برای KMeans Clustering نمودار با علامت گذاری خط عمودی که بهترین تعداد ks خواهد بود، در این مورد، 4.
به نظر میرسد اگر تعداد واقعی خوشهها را نمیدانستیم، روش زانو با معیار اعوجاج بهترین انتخاب نبود. آیا Silhouette همچنین نشان می دهد که 4 خوشه وجود دارد؟ برای پاسخ به آن، فقط باید آخرین کد را با یک مدل با 4 خوشه و یک شی ویژوالایزر متفاوت تکرار کنیم:
model_4clust = KMeans(n_clusters = 4, random_state=42)
sil_visualizer = SilhouetteVisualizer(model_4clust)
sil_visualizer.fit(X)
sil_visualizer.show()

کد a را نمایش می دهد طرح سیلوئت خوشه بندی KMeans برای 150 نمونه در 4 مرکز. برای تجزیه و تحلیل این خوشه ها، باید به مقدار ضریب (یا امتیاز) silhouette نگاه کنیم، بهترین مقدار آن نزدیک به 1 است. مقدار متوسطی که داریم 0.5، با خط عمودی مشخص شده است و چندان خوب نیست.
ما همچنین باید به توزیع بین خوشه ها نگاه کنیم – یک طرح خوب دارای اندازه های مشابه مناطق خوشه ای یا نقاط به خوبی توزیع شده است. در این نمودار، 3 خوشه کوچکتر (شماره 3، 2، 1) و یک خوشه بزرگتر (شماره 0) وجود دارد که نتیجه مورد انتظار ما نیست.
بیایید همان طرح را برای 3 خوشه تکرار کنیم تا ببینیم چه اتفاقی می افتد:
model_3clust = KMeans(n_clusters = 3, random_state=42)
sil_visualizer = SilhouetteVisualizer(model_3clust)
sil_visualizer.fit(X)
sil_visualizer.show()

با تغییر تعداد خوشه ها، امتیاز silhouette بدست آمد 0.05 بالاتر و خوشه ها متعادل تر هستند. اگر تعداد واقعی خوشه ها را نمی دانستیم، با آزمایش و ترکیب هر دو تکنیک، انتخاب می کردیم. 3 بجای 2 به عنوان تعداد Ks.
این مثالی است از اینکه چگونه ترکیب و مقایسه معیارهای مختلف، تجسم دادهها و آزمایش با مقادیر مختلف خوشهها برای هدایت نتیجه در جهت درست مهم است. و همچنین، چگونه داشتن کتابخانه ای که آن تحلیل را تسهیل می کند، می تواند در این امر کمک کند process!
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-05 02:48:03
