از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
رگرسیون خطی یکی از رایج ترین الگوریتم های مورد استفاده در یادگیری ماشین است. شما می خواهید با رگرسیون خطی آشنا شوید زیرا اگر می خواهید رابطه بین دو یا چند مقدار پیوسته را اندازه گیری کنید، باید از آن استفاده کنید.
یک فرو رفتن عمیق در تئوری و اجرای رگرسیون خطی به شما کمک می کند تا این الگوریتم یادگیری ماشینی ارزشمند را درک کنید.
تعریف اصطلاحات
قبل از اینکه به رگرسیون خطی بپردازیم، بیایید یک لحظه وقت بگذاریم تا مطمئن شویم که واضح هستیم روی رگرسیون چیست
در یادگیری ماشینی وجود دارد دو نوع مختلف روش های یادگیری تحت نظارت: طبقه بندی و پسرفت.
به طور کلی رگرسیون یک روش آماری است که روابط بین متغیرها را تخمین می زند. طبقه بندی همچنین سعی می کند روابط بین متغیرها را بیابد که تفاوت اصلی بین طبقه بندی و رگرسیون خروجی مدل است.
در یک کار رگرسیونی، متغیر خروجی ماهیت عددی یا پیوسته دارد، در حالی که برای کارهای طبقه بندی، متغیر خروجی ماهیت مقوله ای یا گسسته دارد. اگر یک متغیر مقولهای باشد به این معنی است که تعداد محدود/گسسته گروهها یا دستههایی وجود دارد که متغیر میتواند در آن قرار بگیرد.
طبقهبندیکنندهای را در نظر بگیرید که سعی میکند پیشبینی کند که یک حیوان از چه نوع پستانداری است روی ویژگی های مختلف اگرچه پستانداران زیادی وجود دارد، پستانداران بی نهایت وجود ندارند، تنها دسته های ممکن زیادی وجود دارد که می توان خروجی را در آنها طبقه بندی کرد.
در مقابل، متغیرهای پیوسته بین هر دو متغیر دارای بی نهایت مقدار خواهند بود. تفاوت بین دو عدد داده شده را می توان به صورت بی نهایت راه نشان داد که اعشار طولانی تر را می نویسد. این بدان معنی است که اگر اندازهگیریها در دستههای مجزا قرار نگیرند، حتی مواردی مانند اندازهگیریهای تاریخ و زمان نیز میتوانند متغیرهای پیوسته در نظر گرفته شوند.
در حالی که وظایف رگرسیون مربوط به تخمین رابطه بین برخی از متغیرهای ورودی با یک متغیر خروجی پیوسته است، انواع مختلف رگرسیون الگوریتم ها:
- رگرسیون خطی
- رگرسیون چند جمله ای
- رگرسیون گام به گام
- رگرسیون ریج
- رگرسیون کمند
- رگرسیون ElasticNet
این انواع مختلف رگرسیون برای کارهای مختلف مناسب هستند. رگرسیون ریج هنگامی که درجات بالایی از همخطی یا روابط تقریباً خطی در مجموعه ویژگی ها وجود دارد، بهترین استفاده است. در همین حال، رگرسیون چند جمله ای هنگامی که یک رابطه غیر خطی بین ویژگی ها وجود دارد بهترین استفاده است، زیرا قادر به ترسیم خطوط پیش بینی منحنی است.
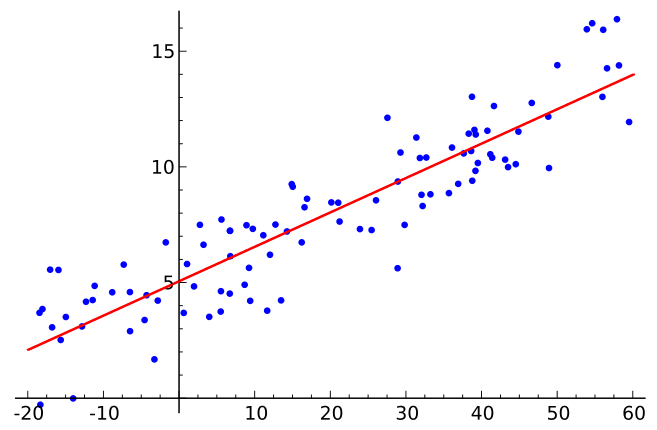
رگرسیون خطی یکی از رایج ترین انواع رگرسیون است که برای رسم یک خط مستقیم در طول یک نمودار که رابطه خطی بین متغیرها را نشان می دهد مناسب است.
نظریه پشت رگرسیون خطی چندگانه
یک رگرسیون خطی به سادگی رابطه را نشان می دهد بین متغیر وابسته و متغیر مستقل.
اگر رگرسیون خطی فقط رسم رابطه بین یک متغیر مستقل (X) و یک متغیر وابسته (Y) باشد، ممکن است بتوانید حدس بزنید که چند متغیره/رگرسیون خطی چندگانه فقط یک رگرسیون خطی انجام شده است روی بیش از یک متغیر مستقل
بیایید نگاهی به معادله رگرسیون خطی بیندازیم، زیرا درک روش عملکرد آن به شما کمک میکند تا بدانید چه زمانی آن را اعمال کنید.

اعتبار: commons.wikimedia.org
معادله رگرسیون خطی: Y = a+b*X. در یک کار رگرسیون خطی، پارامترهای (a و b) توسط مدل ما تخمین زده شود. سپس ثابت یا رهگیری را می گیریم aو شیب خط را اضافه کنید b برابر متغیر مستقل X (ویژگی ورودی ما)، برای تعیین مقدار متغیر وابسته (Y).
تصویر بالا نمونه ای از رابطه خطی بین این است X و Y متغیرها شبیه به
معادله ای که برای محاسبه مقادیر استفاده می شود a و b برای بهترین خط مناسب است روش حداقل مربعات، که با به حداقل رساندن فاصله مربع از هر نقطه داده تا خط ترسیم شده عمل می کند. برای پیاده سازی رگرسیون خطی نیازی به دانستن روش عملکرد معادله نیست، اما اگر کنجکاو هستید می توانید در لینک بالا در مورد آن بیشتر بخوانید.
اگر Y = a+b*X معادله رگرسیون خطی منفرد است، پس نتیجه می شود که برای رگرسیون خطی چندگانه، تعداد متغیرهای مستقل و شیب ها به معادله متصل می شوند.
به عنوان مثال، در اینجا معادله رگرسیون خطی چندگانه با دو متغیر مستقل است:
این برای هر تعداد معینی از متغیرها صادق است.
رگرسیون خطی چند متغیره را می توان به عنوان چندگانه مدلهای رگرسیون خطی منظم، زیرا شما فقط همبستگیهای بین ویژگیها را برای تعداد مشخصی از ویژگیها مقایسه میکنید.
برای معادلات ذکر شده در بالا، فرض بر این است که یک رابطه خطی بین متغیر وابسته و متغیر یا متغیرهای مستقل وجود دارد. این همچنین فرض میکند که متغیرها/ویژگیها همه مقادیر پیوسته هستند نه مقادیر گسسته.
پیاده سازی MLR
تبدیل متغیرهای طبقه بندی شده

اعتبار: commons.wikimedia.org
هنگام اجرای رگرسیون خطی در سیستم یادگیری ماشین، متغیرها باید باشند مداوم در طبیعت، نه طبقه بندی شده. با این حال، اغلب دادههایی خواهید داشت که حاوی متغیرهای طبقهبندی هستند و متغیرهای پیوسته نیستند.
به عنوان مثال، یک مجموعه داده می تواند شامل وقوع برخی رویدادها در کشورهای خاص باشد. کشورها متغیرهای طبقه بندی هستند. برای استفاده صحیح از رگرسیون خطی، این متغیرهای طبقه بندی شده باید به متغیرهای پیوسته تبدیل شوند.
وجود دارد چندین راه مختلف که این می توان به دست آورد، بسته به روی نوع متغیر مورد نظر متغیرها می توانند دوگانه، اسمی یا ترتیبی باشند.
متغیرهای دوگانه
متغیرهای دوگانه آنهایی هستند که فقط در یکی از دو دسته وجود دارند. یک متغیر دوگانه یا “بله” یا “نه”، سفید یا سیاه است. متغیرهای دوگانه به راحتی به متغیرهای پیوسته تبدیل می شوند، آنها به سادگی باید برچسب گذاری شوند 0 یا 1.
متغیرهای اسمی / ترتیبی
متغیرهای اسمی و ترتیبی انواعی از متغیرهای طبقهبندی هستند و میتوانند هر تعداد دستهای وجود داشته باشند که مقادیر به آن تعلق داشته باشند. از نظر متغیرهای ترتیبی، فرض بر این است که ترتیب متغیرها وجود دارد، یا اینکه متغیرها باید وزن متفاوتی داشته باشند. بنابراین، متغیرهای طبقهبندی را میتوان با تخصیص اعدادی که از صفر شروع میشوند و تا طول دستهها اجرا میشوند، به مقادیر پیوسته تبدیل کرد.
تبدیل متغیرهای اسمی به متغیرهای پیوسته چالش برانگیزترین کار در بین هر سه نوع تبدیل است. این به این دلیل است که متغیرهای اسمی نباید وزن یا ترتیب متفاوتی به آنها داشته باشند، فرض بر این است که همه متغیرهای طبقهای دارای “مقدار” معادل هستند. این بدان معنی است که شما نمی توانید آنها را به سادگی از صفر به تعداد دسته ها مرتب کنید زیرا این بدان معناست که دسته های قبلی “ارزش” کمتری نسبت به دسته های بعدی دارند.
به همین دلیل، تاکتیک پیش فرض برای تبدیل متغیرهای اسمی به متغیرهای پیوسته چیزی به نام است رمزگذاری تک داغ، گاهی اوقات به عنوان “ایجاد متغیرهای ساختگی” نامیده می شود. اساساً، شما ویژگیها یا متغیرهای بیشتری ایجاد میکنید که برای دستههای واقعی در دادههای شما قرار میگیرند. این process رمزگذاری یک داغ به معنای ایجاد یک آرایه به اندازه تعداد دسته های شما و پر کردن آنها با یک “یک” در موقعیت مربوط به دسته مربوطه و صفر در هر جای دیگر است.
به عنوان مثال، در اینجا جدولی با داده های طبقه بندی شده است:
بعد از اینکه ما این جدول را از طریق یک Hot-encoding قرار دادیم process، در نهایت به این شکل می شود:
| قرمز | سبز | آبی |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
هنگامی که برچسبهای پیوسته برای متغیرهای طبقهبندی خود ایجاد میکنید، مطمئن شوید که مقادیر واقعاً با اهمیت دسته مورد نظر مطابقت دارند. اگر متغیرهای ترتیبی و دامنه مقادیری را دارید که به شما داده شده است، رتبه را در نظر نگیرید، روابط بین دسته ها از بین می رود و طبقه بندی کننده شما تأثیر منفی خواهد گذاشت.
خط لوله یادگیری ماشین
قبل از اینکه به مثالی از اجرای رگرسیون خطی چندگانه نگاه کنیم روی یک مجموعه داده واقعی، اجازه دهید لحظه ای را برای درک یادگیری ماشین صرف کنیم گردش کار یا خط لوله.
هر پیاده سازی الگوریتم های یادگیری ماشین دارای اجزای اساسی یکسانی است. شما باید:
- داده ها را آماده کنید
- مدل را ایجاد کنید
- مدل را آموزش دهید
- مدل را ارزیابی کنید
آمادهسازی دادهها اغلب یکی از چالشبرانگیزترین بخشهای یادگیری ماشینی است، زیرا نه تنها شامل جمعآوری دادهها، بلکه تبدیل آن دادهها به قالبی است که میتواند توسط الگوریتم انتخابی شما استفاده شود. این شامل بسیاری از وظایف مانند مقابله با مقادیر از دست رفته یا داده های خراب/بد است. به همین دلیل، ما از یک مجموعه داده از پیش ساخته شده استفاده خواهیم کرد که نیاز به پیش پردازش کمی دارد.
ایجاد مدل یادگیری ماشینی در هنگام استفاده از کتابخانه ای بسیار ساده است Scikit-Learn. معمولاً فقط چند خط کد برای نمونهسازی الگوریتم یادگیری ماشینی لازم وجود دارد. با این حال، آرگومانها و پارامترهای مختلفی وجود دارد که این الگوریتمها میگیرند که بر دقت مدل شما تأثیر میگذارند. هنر انتخاب مقادیر صحیح پارامترها برای مدل به مرور زمان به سراغ شما می آید، اما همیشه می توانید به مستندات الگوریتم در کتابخانه انتخابی خود مراجعه کنید تا ببینید کدام پارامترها را می توانید آزمایش کنید.
آموزش مدل در هنگام استفاده از کتابخانه ای مانند Scikit-Learn نیز نسبتاً ساده است، زیرا یک بار دیگر معمولاً فقط چند خط کد برای آموزش الگوریتم مورد نیاز است. روی مجموعه داده های انتخابی شما
با این حال، باید مطمئن باشید که داده های خود را به دو دسته تقسیم کرده اید آموزش و آزمایش کردن مجموعه ها شما نمی توانید عملکرد طبقه بندی کننده خود را ارزیابی کنید روی همان مجموعه داده ای که شما آن را آموزش داده اید روی، زیرا مدل شما قبلاً پارامترهای این مجموعه داده را یاد گرفته است. ارزیابی داده ها روی مجموعه آموزشی به شما هیچ بینشی در مورد عملکرد مدل شما نمی دهد روی مجموعه داده دیگری
نمونه پیاده سازی MLR
بدون تاخیر بیشتر، بیایید روش انجام رگرسیون خطی چندگانه را با استفاده از ماژول Scikit-Learn برای پایتون بررسی کنیم.

اعتبار: commons.wikimedia.org
ابتدا باید مجموعه داده خود را بارگذاری کنیم. ما از کتابخانه Scikit-Learn استفاده میکنیم، و این مجموعه با مجموعههای داده نمونه از پیش بستهبندی شده است. مجموعه داده ای که ما استفاده خواهیم کرد عبارت است از مجموعه داده مسکن بوستون. مجموعه داده دارای ویژگیهای مختلفی در مورد خانههای منطقه بوستون است، مانند اندازه خانه، میزان جرم و جنایت، سن ساختمان و غیره. هدف پیشبینی قیمت خانه است. روی این ویژگی ها
تمام وارداتی که نیاز داریم در اینجا آمده است:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error, r2_Score
اکنون باید یک نمونه از مجموعه داده را با فراخوانی ایجاد کنیم load_boston() تابع:
bh_data = load_boston()
اجازه دهید print مقدار متغیر داده را حذف کنید تا ببینید چه نوع داده هایی دارد:
print(bh_data.keys())
در اینجا چیزی است که ما دریافت می کنیم:
dict_keys(('data', 'target', 'feature_names', 'DESCR'))
این data تمام اطلاعات واقعی در مورد خانه ها است، در حالی که target قیمت خانه است، feature names نام دسته هایی هستند که داده ها در آنها قرار می گیرند و DESCR دستوری برای توصیف ویژگی های مجموعه داده است.
ما سعی میکنیم دادهها و نام ویژگیها را در قالب دادهای که مدلمان میتواند استفاده کند، وارد کنیم، بنابراین بیایید با استفاده از Pandas، یک شی قاب داده از دادهها ایجاد کنیم.
ما همچنین نام ویژگی ها را به عنوان سربرگ ستون ها ارسال می کنیم:
boston = pd.Dataframe(bh_data.data, columns=bh_data.feature_names)
اگر بخواهیم ایده ای از انواع ویژگی های مجموعه داده به دست آوریم، می توانیم print برخی از ردیفها را همراه با توضیحاتی در مورد ویژگیهای آن بیان کنید:
print(data.DESCR)
در اینجا چند مورد از توضیحاتی که برگردانده شده است:
CRIM: Per capita crime rate by town
ZN: Proportion of residential land zoned for lots over 25,000 sq. ft
INDUS: Proportion of non-retail business acres per town
...
LSTAT: Percentage of lower status of the population
MEDV: Median value of owner-occupied homes in $1000s
ما می خواهیم ارزش متوسط یک خانه را پیش بینی کنیم، اما مجموعه داده فعلی ما آن اطلاعات را برای آموزش/آزمایش ندارد روی، بنابراین بیایید یک ستون جدید در چارچوب داده ایجاد کنیم و مقادیر هدف را از مجموعه داده بارگذاری کنیم.
این کار فقط با مشخص کردن قاب داده و نام ستونی که میخواهیم در متغیر ایجاد کنیم و سپس انتخاب target ارزش های:
boston('MEDV') = bh_data.target
به طور معمول، شما باید برخی از تجزیه و تحلیل داده ها را انجام دهید تا بفهمید مهم ترین ویژگی ها چیست و از آن متغیرها برای رگرسیون استفاده کنید. با این حال، این می تواند به تنهایی یک مقاله باشد، بنابراین در این مورد، من فقط به شما می گویم که ویژگی هایی با قوی ترین همبستگی ها، نسبت “وضعیت پایین تر” در جمعیت (‘LSTAT’) و تعداد اتاق ها است. در خانه (‘RM’).
بنابراین بیایید از «RM» و «LSTAT» به عنوان متغیرهای خود برای رگرسیون خطی استفاده کنیم. این مقادیر قبلاً در مجموعه داده ما پیوسته هستند، بنابراین ما اصلاً نیازی به رمزگذاری آنها نداریم.
با این حال، اجازه دهید دو ستون متغیر را به یک ستون با کتابخانه NumPy متصل کنیم. np.c_ فرمان ما همچنین یک متغیر جدید برای ذخیره مقادیر هدف با تعیین مقدار ایجاد می کنیم boston dataframe و ستون مورد نظر ما:
X = pd.DataFrame(np.c_(boston('LSTAT'), boston('RM')), columns=('LSTAT','RM')
Y = boston('MEDV')
حال بیایید دیتافریم را به مجموعه های آموزشی و آزمایشی تقسیم کنیم:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=9)
اکنون باید یک نمونه از مدل ایجاد کنیم که به سادگی آن را فراخوانی می کنیم LinearRegression تابع از Scikit-Learn:
lin_reg_mod = LinearRegression()
اکنون مدل را متناسب می کنیم روی داده های آموزشی:
lin_reg_mod.fit(X_train, y_train)
اکنون که مدل مناسب است، میتوانیم با فراخوانی پیشبینی کنیم predict فرمان ما داریم پیش بینی می کنیم روی مجموعه تست:
pred = lin_reg_mod.predict(X_test)
اکنون با استفاده از معیارهای RMSE و R-2، دو معیاری که معمولاً برای ارزیابی وظایف رگرسیون استفاده میشوند، پیشبینیها را در برابر مقادیر واقعی بررسی میکنیم:
test_set_rmse = (np.sqrt(mean_squared_error(y_test, pred)))
test_set_r2 = r2_score(y_test, pred)
عالی متغیرهای ما وجود دارند که ارزیابی مدل را ذخیره می کنند و ما یک پیاده سازی کامل از رگرسیون خطی چندگانه داریم. روی یک مجموعه داده نمونه
اجازه دهید print معیارهای دقت را بررسی کنید و ببینید چه نتایجی به دست می آوریم:
print(test_set_rmse)
print(test_set_r2)
در اینجا نتایج ما آمده است:
6.035041736063677
0.6400551238836978
می توانید از ویژگی های بیشتری برای بهبود دقت مدل استفاده کنید.
نتیجه
رگرسیون خطی چند متغیره / چند متغیره یک الگوریتم بسیار مفید برای ردیابی روابط متغیرهای پیوسته است. همچنین یکی از متداولترین الگوریتمهای مورد استفاده در یادگیری ماشینی است، بنابراین آشنایی با آن مفید است.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-22 05:31:05
