از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
متولد دریا یکی از پرکاربردترین کتابخانه های تجسم داده در پایتون، به عنوان پسوندی است Matplotlib. این یک API ساده، بصری و در عین حال بسیار قابل تنظیم برای تجسم داده ها ارائه می دهد.
در این آموزش، روش انجام این کار را بررسی خواهیم کرد طرح یک طرح خطی در Seaborn – یکی از اساسی ترین انواع قطعه.
Line Plots مقادیر عددی را نمایش می دهد روی یک محور و مقادیر مقوله ای روی دیگری.
آنها معمولاً می توانند به همان روشی که می توان از نوار پلات استفاده کرد، استفاده می شود، اگرچه، آنها معمولاً برای پیگیری تغییرات در طول زمان استفاده می شوند.
با Seaborn یک پلات خطی ترسیم کنید
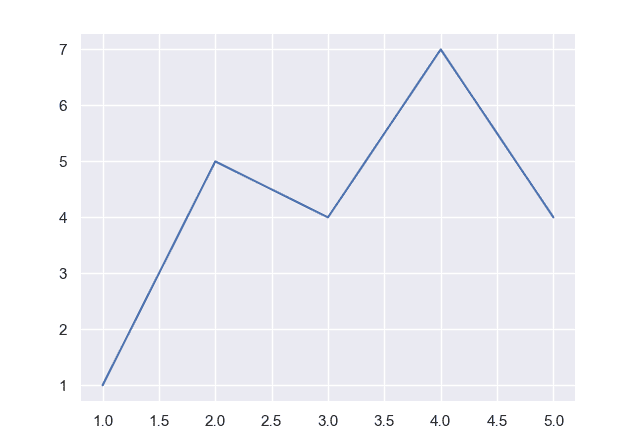
بیایید با ابتداییترین شکل جمعآوری دادهها برای یک Line Plot، با ارائه چند لیست برای محور X و Y-محور شروع کنیم. lineplot() تابع:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="darkgrid")
x = (1, 2, 3, 4, 5)
y = (1, 5, 4, 7, 4)
sns.lineplot(x, y)
plt.show()
در اینجا، ما دو لیست از مقادیر داریم، x و y. این x لیست به عنوان لیست متغیر دسته بندی ما عمل می کند، در حالی که y لیست به عنوان لیست متغیر عددی عمل می کند.
این کد نتیجه می دهد:

برای این منظور، میتوانیم از انواع دادههای دیگر، مانند رشتهها برای محور دستهبندی استفاده کنیم:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="darkgrid")
x = ('day 1', 'day 2', 'day 3')
y = (1, 5, 4)
sns.lineplot(x, y)
plt.show()
و این منجر به:

توجه داشته باشید: اگر از اعداد صحیح به عنوان فهرست دسته بندی خود استفاده می کنید، مانند (1, 2, 3, 4, 5)، اما سپس برای رفتن به 100، همه مقادیر بین 5..100 پوچ خواهد بود:
import seaborn as sns
sns.set_theme(style="darkgrid")
x = (1, 2, 3, 4, 5, 10, 100)
y = (1, 5, 4, 7, 4, 5, 6)
sns.lineplot(x, y)
plt.show()

این به این دلیل است که یک مجموعه داده ممکن است به سادگی باشد گم شده مقادیر عددی روی محور X در آن صورت، Seaborn به سادگی به ما اجازه میدهد فرض کنیم که آن مقادیر گم شدهاند و نمودارها را از بین میبرد. با این حال، هنگامی که شما با رشته ها کار می کنید، این مورد نخواهد بود:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="darkgrid")
x = ('day 1', 'day 2', 'day 3', 'day 100')
y = (1, 5, 4, 5)
sns.lineplot(x, y)
plt.show()

با این حال، به طور معمول، ما با لیست های ساده و دست ساز مانند این کار نمی کنیم. ما با داده های وارد شده از مجموعه داده های بزرگتر یا استخراج مستقیم از پایگاه داده کار می کنیم. اجازه دهید import یک مجموعه داده و به جای آن با آن کار کنید.
وارد کردن داده ها
بیایید استفاده کنیم رزرو هتل مجموعه داده و استفاده از داده ها از آنجا:
import pandas as pd
df = pd.read_csv('hotel_bookings.csv')
print(df.head())
بیایید به ستون های این مجموعه داده نگاهی بیندازیم:
hotel is_canceled reservation_status ... arrival_date_month stays_in_week_nights
0 Resort Hotel 0 Check-Out ... July 0
1 Resort Hotel 0 Check-Out ... July 0
2 Resort Hotel 0 Check-Out ... July 1
3 Resort Hotel 0 Check-Out ... July 1
4 Resort Hotel 0 Check-Out ... July 2
این یک نمای کوتاه است، زیرا تعداد زیادی ستون در این مجموعه داده وجود دارد. به عنوان مثال، بیایید این مجموعه داده را با استفاده از کاوش کنیم arrival_date_month به عنوان محور X طبقه بندی ما، در حالی که ما از آن استفاده می کنیم stays_in_week_nights به عنوان محور Y عددی ما:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set_theme(style="darkgrid")
df = pd.read_csv('hotel_bookings.csv')
sns.lineplot(x = "arrival_date_month", y = "stays_in_week_nights", data = df)
plt.show()
ما از پانداها برای خواندن دادههای CSV و بستهبندی آن در یک استفاده کردهایم DataFrame. سپس، ما می توانیم اختصاص دهیم x و y استدلال های lineplot() به عنوان نام ستون ها در آن دیتا فریم عمل می کند. البته، ما باید مشخص کنیم که با کدام مجموعه داده کار می کنیم با تخصیص چارچوب داده به data بحث و جدل.
حال، این نتیجه می شود:

ما به وضوح میتوانیم ببینیم که اقامتهای هفتهای در طول ماههای ژوئن، جولای و آگوست (تعطیلات تابستانی) طولانیتر است، در حالی که در ژانویه و فوریه، درست پس از زنجیره تعطیلات منتهی به سال نو، کمترین میزان را دارند.
علاوه بر این، شما می توانید ببینید فاصله اطمینان به عنوان منطقه اطراف خود خط که همان است برآورد تمایل مرکزی از داده های ما از آنجایی که ما چندگانه داریم y مقادیر برای هر کدام x ارزش (بسیاری از افراد در هر ماه ماندند)، Seaborn گرایش مرکزی این رکوردها را محاسبه می کند و آن خط را ترسیم می کند، همچنین یک فاصله اطمینان برای آن گرایش را ترسیم می کند.
به طور کلی، مردم 2.8 روز می مانند روی شبهای هفته، در ماه ژوئیه، اما فاصله اطمینان از آن شروع میشود 2.78-2.84.
ترسیم داده های گسترده
حال، بیایید نگاهی به این بیندازیم که چگونه میتوانیم دادههای با فرم گسترده را ترسیم کنیم، بهجای شکل مرتب، همانطور که تاکنون انجام دادهایم. ما می خواهیم به تجسم stays_in_week_nights در طول ماه ها متغیر است، اما ما می خواهیم سال ورود را نیز در نظر بگیریم. این منجر به یک خط خطی برای هر ساله، در طول ماه ها، روی یک رقم واحد
از آنجایی که مجموعه داده به طور پیشفرض برای این کار مناسب نیست، باید پیشپردازش دادهها را انجام دهیم. روی آی تی.
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv('hotel_bookings.csv')
df = df(('arrival_date_year', 'arrival_date_month', 'stays_in_week_nights'))
order = df('arrival_date_month')
df_wide = df.pivot_table(index='arrival_date_month', columns='arrival_date_year', values='stays_in_week_nights')
df_wide = df_wide.reindex(order, axis=0)
print(df_wide)
در اینجا، ابتدا مجموعه داده را به چند ستون مرتبط کوتاه کرده ایم. سپس، ترتیب ماههای تاریخ ورود را ذخیره کردهایم تا بتوانیم آن را برای بعد حفظ کنیم. هر چند می توانید در اینجا هر ترتیبی را تنظیم کنید.
سپس، برای تبدیل دادههای با فرم باریک به شکل گسترده، جدول را حول آن چرخاندهایم arrival_date_month ویژگی، چرخش arrival_date_year به ستون ها، و stays_in_week_nights به ارزش ها در نهایت، ما استفاده کرده ایم reindex() برای اجرای همان دستور ماه های ورود که قبلاً داشتیم.
بیایید نگاهی بیندازیم که مجموعه داده ما اکنون چگونه به نظر می رسد:
arrival_date_year 2015 2016 2017
arrival_date_month
July 2.789625 2.836177 2.787502
July 2.789625 2.836177 2.787502
July 2.789625 2.836177 2.787502
July 2.789625 2.836177 2.787502
July 2.789625 2.836177 2.787502
... ... ... ...
August 2.654153 2.859964 2.956142
August 2.654153 2.859964 2.956142
August 2.654153 2.859964 2.956142
August 2.654153 2.859964 2.956142
August 2.654153 2.859964 2.956142
عالی! مجموعه داده ما اکنون به درستی برای تجسم فرم گسترده، با گرایش مرکزی به فرمت شده است stays_in_week_nights محاسبه شد. اکنون که ما با یک مجموعه داده گسترده کار می کنیم، تنها کاری که باید انجام دهیم این است:
sns.lineplot(data=df_wide)
plt.show()
این lineplot() تابع می تواند به طور بومی مجموعه داده های گسترده را تشخیص دهد و آنها را بر اساس آن رسم کند. این منجر به:

سفارشی کردن خطوط خط با Seaborn
اکنون که روش رسم دادههای درج شده به صورت دستی، روش ترسیم ویژگیهای مجموعه داده ساده، و همچنین دستکاری مجموعه دادهها برای انطباق با نوع دیگری از تجسم را بررسی کردهایم – بیایید نگاهی بیندازیم که چگونه میتوانیم نمودارهای خط خود را برای ارائه بیشتر سفارشی کنیم. اطلاعات آسان برای هضم
طرح خط طرح با رنگ ها
رنگ ها می توان از آن برای تفکیک یک مجموعه داده به چند نمودار خط جداگانه استفاده کرد روی یک ویژگی که مایلید آنها را بر اساس گروه بندی (رنگ آمیزی) قرار دهید. به عنوان مثال، ما می توانیم گرایش مرکزی را تجسم کنیم stays_in_week_nights ویژگی، در طول ماه ها، اما آن را بگیرید arrival_date_year همچنین در نظر گرفته شده و بر اساس نمودارهای خط فردی گروه بندی کنید روی آن ویژگی
این دقیقاً همان کاری است که ما در مثال قبلی انجام دادیم – به صورت دستی. ما مجموعه داده را به یک دیتافریم با فرم گسترده تبدیل کرده و آن را رسم کرده ایم. با این حال، میتوانستیم سالها را به دو دسته تقسیم کنیم رنگ ها همچنین، که دقیقاً همان نتیجه را برای ما به ارمغان می آورد:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv('hotel_bookings.csv')
sns.lineplot(x = "arrival_date_month", y = "stays_in_week_nights", hue='arrival_date_year', data = df)
plt.show()
با تنظیم arrival_date_year ویژگی به عنوان hue استدلال، ما به Seaborn گفتهایم که هر نگاشت XY را بر اساس آن جدا کند arrival_date_year ویژگی، بنابراین ما با سه نمودار خطی مختلف به پایان خواهیم رسید:

این بار، ما همچنین فواصل اطمینان را در اطراف تمایلات مرکزی خود مشخص کرده ایم.
بازه اطمینان خط خط را با Seaborn سفارشی کنید
شما می توانید با استفاده از چند آرگومان به راحتی در اطراف کمانچه، فعال/غیرفعال و نوع فواصل اطمینان را تغییر دهید. این ci آرگومان را می توان برای تعیین اندازه فاصله استفاده کرد و می توان آن را به یک عدد صحیح تنظیم کرد، 'sd' (انحراف معیار) یا None اگر می خواهید آن را خاموش کنید
این err_style را می توان برای مشخص کردن استفاده کرد سبک از فواصل اطمینان – band یا bars. ما تا کنون دیدهایم که گروهها چگونه کار میکنند، بنابراین بیایید یک فاصله اطمینان را امتحان کنیم bars بجای:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv('hotel_bookings.csv')
sns.lineplot(x = "arrival_date_month", y = "stays_in_week_nights", err_style='bars', data = df)
plt.show()
این منجر به:

و بیایید فاصله اطمینان را که به طور پیش فرض روی تنظیم شده است تغییر دهیم 95، برای نمایش انحراف استاندارد به جای آن:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv('hotel_bookings.csv')
sns.lineplot(x = "arrival_date_month", y = "stays_in_week_nights", err_style='bars', ci='sd', data = df)
plt.show()

نتیجه
در این آموزش، ما چندین روش را برای ترسیم یک خط خط در Seaborn بررسی کرده ایم. ما نگاهی به روش ترسیم نمودارهای ساده، با محورهای X عددی و طبقهای انداختهایم، پس از آن یک مجموعه داده را وارد کرده و آن را تجسم کردهایم.
ما روش دستکاری مجموعه داده ها و تغییر شکل آنها برای تجسم چندین ویژگی و همچنین روش سفارشی کردن خطوط خطی را بررسی کرده ایم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً ما را بررسی کنید بسته کتاب روی تجسم داده ها در پایتون:
تجسم داده ها در پایتون با Matplotlib و Pandas کتابی است که طراحی شده است تا مبتدیان مطلق را با دانش پایه پایتون به Pandas و Matplotlib ببرد و به آنها اجازه دهد پایه ای قوی برای کار پیشرفته با این کتابخانه ها بسازند – از طرح های ساده گرفته تا طرح های سه بعدی متحرک با دکمه های تعاملی.
این به عنوان یک راهنمای عمیق عمل می کند که همه چیزهایی را که باید در مورد پانداها و Matplotlib بدانید، از جمله روش ساخت انواع طرح هایی که در خود کتابخانه تعبیه نشده اند را به شما آموزش می دهد.
تجسم داده ها در پایتون، کتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را در دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید. به طور خاص، در طول ۱۱ فصل، این کتاب ۹ کتابخانه پایتون را پوشش میدهد: Pandas، Matplotlib، Seaborn، Bokeh، Altair، Plotly، GGPlot، GeoPandas و VisPy.
این به عنوان یک راهنمای عملی و منحصر به فرد برای تجسم داده ها، در مجموعه ای از ابزارهایی که ممکن است در حرفه خود استفاده کنید، عمل می کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-12 03:56:04
