از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
کتابخانه های تجسم داده های زیادی در پایتون وجود دارد، با این حال Matplotlib محبوب ترین کتابخانه در بین همه آنهاست. محبوبیت Matplotlib به دلیل قابلیت اطمینان و کاربردی بودن آن است – قادر است هر دو طرح ساده و پیچیده را با کد کمی ایجاد کند. شما همچنین می توانید طرح ها را به روش های مختلف سفارشی کنید.
در این آموزش به آن خواهیم پرداخت روش ترسیم نقشه های ویولن در Matplotlib.
نمودارهای ویولن برای تجسم توزیع داده ها، نمایش محدوده، میانه و توزیع داده ها استفاده می شود.
نمودارهای ویولن همان آمار خلاصه را نشان می دهد که نمودارهای جعبه ای است، اما آنها نیز شامل می شوند تخمین تراکم هسته که شکل/توزیع داده ها را نشان می دهد.
وارد کردن داده ها
قبل از اینکه بتوانیم یک طرح ویولن ایجاد کنیم، برای ترسیم به اطلاعاتی نیاز داریم. ما از مجموعه داده Gapminder.
ما با وارد کردن کتابخانه های مورد نیاز خود، که شامل Pandas و Matplotlib است، شروع می کنیم:
import pandas as pd
import matplotlib.pyplot as plt
ما بررسی می کنیم تا مطمئن شویم که هیچ ورودی داده گم نشده ای وجود ندارد و print سر مجموعه داده را بیرون بیاورید تا اطمینان حاصل شود که داده ها به درستی بارگذاری شده اند. حتما نوع رمزگذاری را روی آن تنظیم کنید ISO-8859-1:
dataframe = pd.read_csv("gapminder_full.csv", error_bad_lines=False, encoding="ISO-8859-1")
print(dataframe.head())
print(dataframe.isnull().values.any())
country year population continent life_exp gdp_cap
0 Afghanistan 1952 8425333 Asia 28.801 779.445314
1 Afghanistan 1957 9240934 Asia 30.332 820.853030
2 Afghanistan 1962 10267083 Asia 31.997 853.100710
3 Afghanistan 1967 11537966 Asia 34.020 836.197138
4 Afghanistan 1972 13079460 Asia 36.088 739.981106
طرح یک نقشه ویولن در Matplotlib
برای ایجاد پلات ویولن در Matplotlib، ما آن را فراخوانی می کنیم violinplot() تابع روی یا Axes نمونه یا خود نمونه PyPlot:
import pandas as pd
import matplotlib.pyplot as plt
dataframe = pd.read_csv("gapminder_full.csv", error_bad_lines=False, encoding="ISO-8859-1")
population = dataframe.population
life_exp = dataframe.life_exp
gdp_cap = dataframe.gdp_cap
fig, ax = plt.subplots()
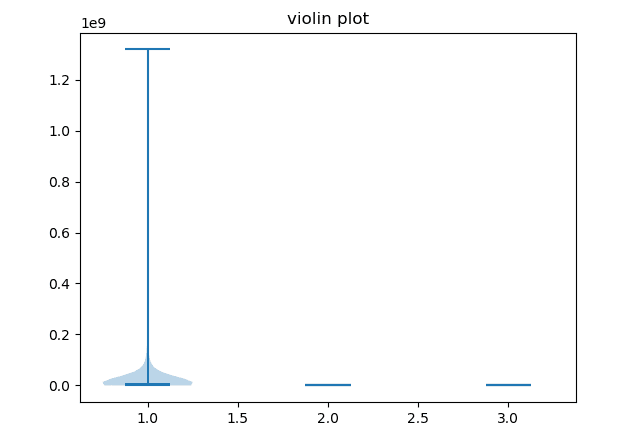
ax.violinplot((population, life_exp, gdp_cap))
ax.set_title('Violin Plot')
plt.show()

وقتی اولین نمودار را ایجاد می کنیم، می توانیم توزیع داده های خود را ببینیم، اما متوجه برخی مشکلات نیز خواهیم شد. از آنجایی که مقیاس ویژگی ها بسیار متفاوت است، توزیع آنها عملا غیرممکن است امید به زندگی و تولید ناخالص ملی ستون ها.
به همین دلیل می خواهیم هر ستون را رسم کنیم روی طرح فرعی خودش
برای آسانتر کردن مقایسه ستونهای مجموعه داده، کمی مرتبسازی و برش قاب داده انجام میدهیم. ما دیتافریم را بر اساس گروه بندی می کنیم “کشور”و فقط جدیدترین/آخرین ورودی ها را برای هر یک از کشورها انتخاب کنید.
سپس بر اساس جمعیت مرتبسازی میکنیم و ورودیهای دارای بیشترین جمعیت (فروت جمعیت بزرگ) را حذف میکنیم تا بقیه چارچوب داده در محدوده مشابهتری قرار بگیرند و مقایسهها آسانتر باشد:
dataframe = dataframe.groupby("country").last()
dataframe = dataframe.sort_values(by=("population"), ascending=False)
dataframe = dataframe.iloc(10:)
print(dataframe)
اکنون، دیتافریم چیزی شبیه به این است:
year population continent life_exp gdp_cap
country
Philippines 2007 91077287 Asia 71.688 3190.481016
Vietnam 2007 85262356 Asia 74.249 2441.576404
Germany 2007 82400996 Europe 79.406 32170.374420
Egypt 2007 80264543 Africa 71.338 5581.180998
Ethiopia 2007 76511887 Africa 52.947 690.805576
... ... ... ... ... ...
Montenegro 2007 684736 Europe 74.543 9253.896111
Equatorial Guinea 2007 551201 Africa 51.579 12154.089750
Djibouti 2007 496374 Africa 54.791 2082.481567
Iceland 2007 301931 Europe 81.757 36180.789190
Sao Tome and Principe 2007 199579 Africa 65.528 1598.435089
عالی! حالا میتوانیم یک شکل و اشیاء سه محور را با آن ایجاد کنیم subplots() تابع. هر کدام از این محورها یک طرح ویولن خواهند داشت. از آنجایی که ما کار می کنیم روی اکنون یک مقیاس بسیار قابل کنترل تر، اجازه دهید به آن نیز بپردازیم روی را showmedians آرگومان با تنظیم آن در True.
این یک خط افقی در میانه طرح های ویولن ما ایجاد می کند:
fig, (ax1, ax2, ax3) = plt.subplots(nrows=1, ncols=3)
ax1.violinplot(dataframe.population, showmedians=True)
ax1.set_title('Population')
ax2.violinplot(life_exp, showmedians=True)
ax2.set_title('Life Expectancy')
ax3.violinplot(gdp_cap, showmedians=True)
ax3.set_title('GDP Per Cap')
plt.show()
اکنون اجرای این کد به ما نشان می دهد:

اکنون می توانیم ایده خوبی از توزیع داده های خود داشته باشیم. خط افقی مرکزی در ویولن ها جایی است که میانه داده های ما قرار دارد و مقادیر حداقل و حداکثر با موقعیت های خط نشان داده می شوند. روی محور Y
سفارشی کردن نقشه های ویولن در Matplotlib
اکنون، بیایید نگاهی به روش سفارشی سازی ویولن پلات بیندازیم.
اضافه کردن تیک X و Y
همانطور که می بینید، در حالی که نمودارها با موفقیت تولید شده اند، بدون برچسب تیک روی در محور X و Y ممکن است تفسیر نمودار دشوار باشد. انسان ها مقادیر مقوله ای را بسیار راحت تر از مقادیر عددی تفسیر می کنند.
ما میتوانیم طرح را سفارشی کنیم و با استفاده از آن، برچسبهایی را به محور X اضافه کنیم set_xticks() تابع:
fig, ax = plt.subplots()
ax.violinplot(gdp_cap, showmedians=True)
ax.set_title('violin plot')
ax.set_xticks((1))
ax.set_xticklabels(("Country GDP",))
plt.show()
این منجر به:

در اینجا، ما تیکهای X را از یک محدوده به یک تک، در وسط تنظیم کردهایم و برچسبی را اضافه کردهایم که تفسیر آن آسان است.
توطئه ویولن افقی در Matplotlib
اگر بخواهیم میتوانیم جهت طرح را با تغییر دادن تغییر دهیم vert پارامتر. vert کنترل می کند که آیا طرح به صورت عمودی رندر شود یا نه و آن را تنظیم می کند True به صورت پیش فرض:
fig, ax = plt.subplots()
ax.violinplot(gdp_cap, showmedians=True, vert=False)
ax.set_title('violin plot')
ax.set_yticks((1))
ax.set_yticklabels(("Country GDP",))
ax.tick_params(axis='y', labelrotation = 90)
plt.show()

در اینجا، ما برچسب های تیک محور Y و فرکانس آنها را به جای محور X تنظیم کرده ایم. ما همچنین برچسب ها را 90 درجه چرخانده ایم
نمایش معنی مجموعه داده ها در طرح های ویولن
ما برخی از پارامترهای سفارشی سازی دیگر را نیز در دسترس داریم. میتوانیم علاوه بر میانهها، با استفاده از نشاندهنده نشان دهیم showmean پارامتر.
بیایید سعی کنیم ابزارها را علاوه بر میانه ها تجسم کنیم:
fig, (ax1, ax2, ax3) = plt.subplots(nrows=1, ncols=3)
ax1.violinplot(population, showmedians=True, showmeans=True, vert=False)
ax1.set_title('Population')
ax2.violinplot(life_exp, showmedians=True, showmeans=True, vert=False)
ax2.set_title('Life Expectancy')
ax3.violinplot(gdp_cap, showmedians=True, showmeans=True, vert=False)
ax3.set_title('GDP Per Cap')
plt.show()

اگرچه، لطفاً توجه داشته باشید که از آنجایی که میانهها و معنیها اساساً یکسان به نظر میرسند، ممکن است مشخص نباشد که کدام خط عمودی در اینجا به یک میانه و کدام به یک میانگین اشاره دارد.
سفارشی کردن تخمین چگالی هسته برای پلات ویولن
همچنین میتوانیم تعداد نقاط دادهای را که مدل در هنگام ایجاد تخمینهای چگالی هسته گاوسی در نظر میگیرد، با تغییر دادن تغییر دهیم. points پارامتر.
تعداد امتیاز در نظر گرفته شده به طور پیش فرض 100 است. با ارائه تابع با نقاط داده کمتری برای تخمین زدن، ممکن است توزیع داده کمتر نمایندهای داشته باشیم.
بیایید این عدد را به مثلاً 10 تغییر دهیم:
fig, ax = plt.subplots()
ax.violinplot(gdp_cap, showmedians=True, points=10)
ax.set_title('violin plot')
ax.set_xticks((1))
ax.set_xticklabels(("Country GDP",))
plt.show()

توجه داشته باشید که شکل ویولن کمتر صاف است زیرا نقاط کمتری نمونه برداری شده است.
به طور معمول، شما می خواهید تعداد نقاط استفاده شده را افزایش دهید تا درک بهتری از توزیع داشته باشید. ممکن است همیشه اینطور نباشد، اگر 100 به سادگی کافی باشد. بیایید یک طرح ویولن 10، 100 و 500 نقطه ای را ترسیم کنیم:
fig, (ax1, ax2, ax3) = plt.subplots(nrows=1, ncols=3)
ax1.violinplot(gdp_cap, showmedians=True, points=10)
ax1.set_title('GDP Per Cap, 10p')
ax2.violinplot(gdp_cap, showmedians=True, points=100)
ax2.set_title('GDP Per Cap, 100p')
ax3.violinplot(gdp_cap, showmedians=True, points=500)
ax3.set_title('GDP Per Cap, 500p')
plt.show()
این منجر به:

هیچ تفاوت آشکاری بین طرح دوم و سوم وجود ندارد، هر چند، یک تفاوت قابل توجه بین اول و دوم وجود دارد.
نتیجه
در این آموزش، ما چندین روش را برای ترسیم طرح ویولن با استفاده از Matplotlib و Python بررسی کردهایم. ما همچنین روش سفارشی کردن آنها را با افزودن تیک های X و Y، ترسیم افقی، نشان دادن ابزارهای داده و همچنین تغییر نمونه برداری از نقطه KDE پوشش داده ایم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً ما را بررسی کنید بسته کتاب روی تجسم داده ها در پایتون:
تجسم داده ها در پایتون با Matplotlib و Pandas کتابی است که طراحی شده است تا مبتدیان مطلق را با دانش پایه پایتون به Pandas و Matplotlib ببرد و به آنها اجازه دهد پایه ای قوی برای کار پیشرفته با این کتابخانه ها بسازند – از طرح های ساده گرفته تا طرح های سه بعدی متحرک با دکمه های تعاملی.
این به عنوان یک راهنمای عمیق عمل می کند که همه چیزهایی را که باید در مورد پانداها و Matplotlib بدانید، از جمله روش ساخت انواع طرح هایی که در خود کتابخانه تعبیه نشده اند را به شما آموزش می دهد.
تجسم داده ها در پایتون، کتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را در دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید. به طور خاص، در طول ۱۱ فصل، این کتاب ۹ کتابخانه پایتون را پوشش میدهد: Pandas، Matplotlib، Seaborn، Bokeh، Altair، Plotly، GGPlot، GeoPandas و VisPy.
این به عنوان یک راهنمای عملی و منحصر به فرد برای تجسم داده ها، در مجموعه ای از ابزارهایی که ممکن است در حرفه خود استفاده کنید، عمل می کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-13 18:41:04
