از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
این فرمت سند قابل حمل (PDF) یک نیست WYSIWYG (آنچه می بینید همان چیزی است که به دست می آورید) قالب این برای پلتفرم-آگنوستیک، مستقل از سیستم عامل اصلی و موتورهای رندر توسعه داده شد.
برای دستیابی به این هدف، PDF ساخته شد تا از طریق چیزی بیشتر شبیه به یک زبان برنامه نویسی و متکی با آن تعامل داشته باشد. روی مجموعه ای از دستورالعمل ها و عملیات برای رسیدن به نتیجه. در واقع PDF است مستقر روی یک زبان برنامه نویسی – پست اسکریپتکه اولین دستگاه مستقل بود زبان توضیحات صفحه.
در این راهنما، ما استفاده خواهیم کرد بورب – یک کتابخانه پایتون که به خواندن، دستکاری و تولید اسناد PDF اختصاص یافته است. هم یک مدل سطح پایین (که به شما امکان میدهد به مختصات و طرحبندی دقیق در صورت استفاده از آنها دسترسی داشته باشید) و هم یک مدل سطح بالا (که در آن میتوانید محاسبات دقیق حاشیهها، موقعیتها و غیره را به یک مدیر طرحبندی واگذار کنید) ارائه میدهد. .
در این راهنما، نگاهی به چگونه process یک فاکتور PDF در پایتون با استفاده از borb، با استخراج متن، از آنجایی که PDF یک قابل استخراج قالب – که آن را مستعد پردازش خودکار می کند.
پردازش خودکار یکی از اهداف اساسی ماشینها است و اگر کسی سند قابل تجزیه را ارائه ندهد، مانند json در کنار یک فاکتور انسان محور – شما باید خودتان محتوای PDF را تجزیه کنید.
نصب borb
بورب را می توان از منبع دانلود کرد روی GitHub، یا نصب شده از طریق pip:
$ pip install borb
ایجاد فاکتور PDF در پایتون با borb
در راهنمای قبلی، یک فاکتور PDF با استفاده از borb ایجاد کردهایم که اکنون در حال پردازش آن هستیم.
اگر میخواهید درباره روش ایجاد فاکتور در پایتون با borb بیشتر بخوانید، ما شما را تحت پوشش قرار دادهایم!
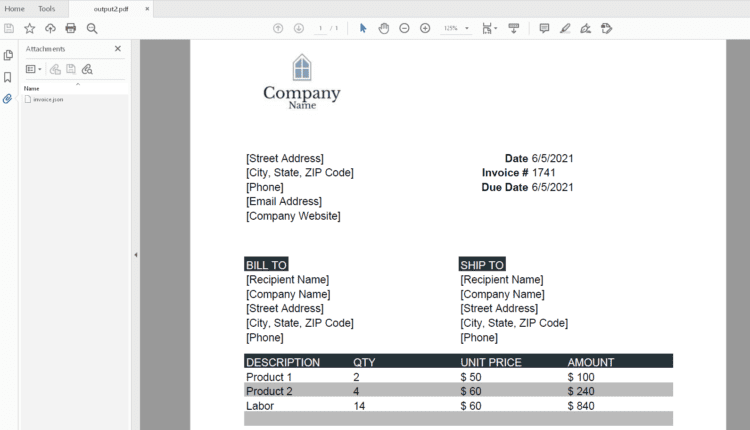
سند PDF تولید شده به طور خاص به شکل زیر است:

پردازش فاکتور PDF با borb
بیایید با باز کردن فایل PDF و بارگذاری آن در a شروع کنیم Document – نمایش شیء فایل:
import typing
from borb.pdf.document import Document
from borb.pdf.pdf import PDF
def main():
d: typing.Optional(Document) = None
with open("output.pdf", "rb") as pdf_in_handle:
d = PDF.loads(pdf_in_handle)
assert d is not None
if __name__ == "__main__":
main()
کد از همان الگوی پیروی می کند که ممکن است در آن ببینید json کتابخانه؛ یک روش استاتیک، loads()، که یک دسته فایل را می پذیرد و یک ساختار داده را خروجی می دهد.
در مرحله بعد، ما می خواهیم بتوانیم تمام محتوای متنی فایل را استخراج کنیم. borb با امکان ثبت نام به شما این امکان را می دهد EventListener کلاس ها به تجزیه Document.
به عنوان مثال، هر زمان borb با نوعی دستورالعمل رندر متن مواجه می شود و به همه افراد ثبت نام شده اطلاع می دهد EventListener اشیاء، که پس از آن می تواند process منتشر شده Event.
borb همراه با چند پیاده سازی از EventListener:
SimpleTextExtraction: متن را از PDF استخراج می کندSimpleImageExtraction: تمام تصاویر را از یک PDF استخراج می کندRegularExpressionTextExtraction: یک عبارت منظم را مطابقت می دهد و مطابقت ها را در هر برمی گرداند page- و غیره.
ما با استخراج تمام متن شروع می کنیم:
import typing
from borb.pdf.document import Document
from borb.pdf.pdf import PDF
from borb.toolkit.text.simple_text_extraction import SimpleTextExtraction
def main():
d: typing.Optional(Document) = None
l: SimpleTextExtraction = SimpleTextExtraction()
with open("output.pdf", "rb") as pdf_in_handle:
d = PDF.loads(pdf_in_handle, (l))
assert d is not None
print(l.get_text_for_page(0))
if __name__ == "__main__":
main()
این قطعه کد باید print تمام متن فاکتور به ترتیب خواندن (بالا به پایین، چپ به راست):
(Street Address) Date 6/5/2021
(City, State, ZIP Code) Invoice # 1741
(Phone) Due Date 6/5/2021
(Email Address)
(Company Website)
BILL TO SHIP TO
(Recipient Name) (Recipient Name)
(Company Name) (Company Name)
(Street Address) (Street Address)
(City, State, ZIP Code) (City, State, ZIP Code)
(Phone) (Phone)
DESCRIPTION QTY UNIT PRICE AMOUNT
Product 1 2 $ 50 $ 100
Product 2 4 $ 60 $ 240
Labor 14 $ 60 $ 840
Subtotal $ 1,180.00
Discounts $ 177.00
Taxes $ 100.30
Total $ 1163.30
البته این برای ما خیلی مفید نیست، زیرا قبل از اینکه بتوانیم کارهای زیادی با آن انجام دهیم، به پردازش بیشتری نیاز دارد، اگرچه این یک شروع عالی است، به خصوص در مقایسه با اسناد PDF اسکن شده با OCR!
بیایید این کد را اصلاح کنیم و بگوییم
borbکهRectangleما علاقه مند هستیم
به عنوان مثال، اجازه دهید اطلاعات حمل و نقل را استخراج کنیم (اما شما می توانید کد را برای بازیابی هر منطقه مورد علاقه تغییر دهید).
به منظور اجازه دادن borb فیلتر کردن a Rectangle ما از LocationFilter کلاس این کلاس پیاده سازی می کند EventListener. از همه مطلع می شود Events هنگام رندر کردن Page و آنهایی را (به فرزندان خود) که در محدوده های از پیش تعریف شده رخ می دهند، منتقل می کند:
import typing
from decimal import Decimal
from borb.pdf.document import Document
from borb.pdf.pdf import PDF
from borb.toolkit.text.simple_text_extraction import SimpleTextExtraction
from borb.toolkit.location.location_filter import LocationFilter
from borb.pdf.canvas.geometry.rectangle import Rectangle
def main():
d: typing.Optional(Document) = None
r: Rectangle = Rectangle(Decimal(280),
Decimal(510),
Decimal(200),
Decimal(130))
l0: LocationFilter = LocationFilter(r)
l1: SimpleTextExtraction = SimpleTextExtraction()
l0.add_listener(l1)
with open("output.pdf", "rb") as pdf_in_handle:
d = PDF.loads(pdf_in_handle, (l0))
assert d is not None
print(l1.get_text_for_page(0))
if __name__ == "__main__":
main()
با اجرای این کد، با فرض انتخاب مستطیل سمت راست، چاپ می شود:
SHIP TO
(Recipient Name)
(Company Name)
(Street Address)
(City, State, ZIP Code)
(Phone)
این کد دقیقاً منعطف ترین یا مقاوم ترین کد نیست. برای پیدا کردن حق، کمی تکان دادن نیاز است Rectangle، و هیچ تضمینی وجود ندارد که اگر طرح فاکتور حتی اندکی تغییر کند، کار خواهد کرد.
ما باید چیزی قوی تر بسازیم تا کاربرد عملی واقعی داشته باشیم.
می توانیم با حذف کدهای سخت شروع کنیم Rectangle. RegularExpressionTextExtraction می تواند یک عبارت منظم را مطابقت دهد و (در میان چیزهای دیگر) مختصات آن را برگرداند روی را Page! با استفاده از تطبیق الگو، میتوانیم بهجای حدس زدن محل رسم مستطیل، عناصر یک سند را بهطور خودکار جستجو کرده و آنها را بازیابی کنیم.
بیایید از این کلاس برای پیدا کردن کلمات “SHIP TO” استفاده کنیم و a را بسازیم Rectangle مستقر روی آن مختصات:
import typing
from borb.pdf.document import Document
from borb.pdf.pdf import PDF
from borb.pdf.canvas.geometry.rectangle import Rectangle
from borb.toolkit.text.regular_expression_text_extraction import RegularExpressionTextExtraction, PDFMatch
def main():
d: typing.Optional(Document) = None
l: RegularExpressionTextExtraction = RegularExpressionTextExtraction("SHIP TO")
with open("output.pdf", "rb") as pdf_in_handle:
d = PDF.loads(pdf_in_handle, (l))
assert d is not None
matches: typing.List(PDFMatch) = l.get_matches_for_page(0)
assert len(matches) == 1
r: Rectangle = matches(0).get_bounding_boxes()(0)
print("%f %f %f %f" % (r.get_x(), r.get_y(), r.get_width(), r.get_height()))
if __name__ == "__main__":
main()
در اینجا، ما ساخته ایم Rectangle در اطراف بخش و چاپ مختصات آن:
299.500000 621.000000 48.012000 8.616000
متوجه خواهید شد که get_bounding_boxes() برمی گرداند typing.List(Rectangle). این مورد زمانی است که یک عبارت منظم در چندین خط متن در PDF مطابقت داده شود.
همچنین، به خاطر داشته باشید که منشا یک PDF (
(0, 0)نقطه) در گوشه پایین سمت چپ قرار دارد. بنابراین بالایPageدارای بالاترین مختصات Y است.
حالا که می دانیم کجا پیدا کنیم “ارسال به”، می توانیم کد قبلی خود را برای قرار دادن آن به روز کنیم Rectangle جالب زیر آن کلمات:
import typing
from decimal import Decimal
from borb.pdf.document import Document
from borb.pdf.pdf import PDF
from borb.pdf.canvas.geometry.rectangle import Rectangle
from borb.toolkit.location.location_filter import LocationFilter
from borb.toolkit.text.regular_expression_text_extraction import RegularExpressionTextExtraction, PDFMatch
from borb.toolkit.text.simple_text_extraction import SimpleTextExtraction
def find_ship_to() -> Rectangle:
d: typing.Optional(Document) = None
l: RegularExpressionTextExtraction = RegularExpressionTextExtraction("SHIP TO")
with open("output.pdf", "rb") as pdf_in_handle:
d = PDF.loads(pdf_in_handle, (l))
assert d is not None
matches: typing.List(PDFMatch) = l.get_matches_for_page(0)
assert len(matches) == 1
return matches(0).get_bounding_boxes()(0)
def main():
d: typing.Optional(Document) = None
ship_to_rectangle: Rectangle = find_ship_to()
r: Rectangle = Rectangle(ship_to_rectangle.get_x() - Decimal(50),
ship_to_rectangle.get_y() - Decimal(100),
Decimal(200),
Decimal(130))
l0: LocationFilter = LocationFilter(r)
l1: SimpleTextExtraction = SimpleTextExtraction()
l0.add_listener(l1)
with open("output.pdf", "rb") as pdf_in_handle:
d = PDF.loads(pdf_in_handle, (l0))
assert d is not None
print(l1.get_text_for_page(0))
if __name__ == "__main__":
main()
و این کد چاپ می کند:
SHIP TO
(Recipient Name)
(Company Name)
(Street Address)
(City, State, ZIP Code)
(Phone)
این هنوز نیاز دارد مقداری دانش سند، اما تقریباً به سختی روش قبلی نیست – و تا زمانی که می دانید متنی را که می خواهید استخراج کنید – می توانید مختصات را دریافت کنید و محتویات را در یک مستطیل رها کنید. روی را page.
نتیجه
در این راهنما نگاهی به روش انجام آن انداخته ایم process یک فاکتور در پایتون با استفاده از borb. ما با استخراج تمام متن شروع کردهایم و خود را اصلاح کردهایم process برای استخراج تنها یک منطقه مورد علاقه. در نهایت، یک عبارت معمولی را با یک PDF مطابقت دادیم تا آن را بسازیم process حتی قوی تر و مقاوم تر در آینده.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-09 05:34:03
