از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
بررسی همبستگی و کمی کردن همبستگی یکی از مراحل کلیدی در طول تجزیه و تحلیل داده های اکتشافی و تشکیل فرضیه است.
Pandas یکی از پرکاربردترین کتابخانههای دستکاری داده است و محاسبه ضرایب همبستگی بین همه متغیرهای عددی را بسیار ساده میکند – با یک فراخوانی روش.
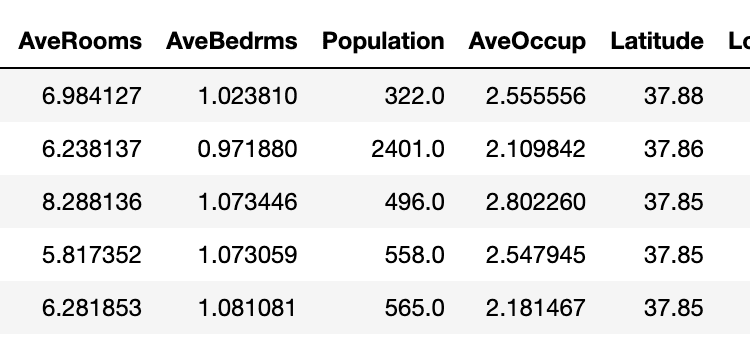
بیایید یک مجموعه داده را از Scikit-Learn بارگذاری کنیم و آن را در یک بسته بندی کنیم DataFrame:
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
ch = fetch_california_housing(as_frame=True)
df = pd.DataFrame(data=ch.data, columns=ch.feature_names)
df('MedHouseVal') = ch.target
df.head()
به درستی بارگذاری شده است!

همه ضرایب همبستگی را دریافت کنید
اکنون، برای بدست آوردن همبستگی بین تمام ویژگی های عددی، به سادگی فراخوانی می کنیم df.corr() (که پیش فرض همبستگی پیرسون است):
df.corr()
فراخوانی متد a را برمی گرداند DataFrame با همبستگی ها و همان ستون ها:

اگرچه، از آنجایی که یک قالب جدولی واقعاً بصری یا قابل خواندن نیست – اجازه دهید این را به عنوان یک نقشه حرارتی ترسیم کنیم:
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 6))
sns.heatmap(df.corr(), ax=ax, annot=True)

دریافت همبستگی با متغیر هدف
فرض کنید ما به یک متغیر هدف علاقه مند هستیم و می خواهیم ببینیم کدام ویژگی با آن ارتباط دارد. ما همبستگی ها را با df.corr() و سپس حاصل را زیر مجموعه قرار دهید DataFrame فقط شامل ستون هدف باشد:
corr = df.corr()(('MedHouseVal'))
sns.heatmap(corr, annot=True)

مرتب سازی ضرایب همبستگی
اغلب اوقات – شما می خواهید مقادیر را نیز مرتب کنید:
corr = df.corr()(('MedHouseVal')).sort_values(by='MedHouseVal', ascending=False)
sns.heatmap(corr, annot=True)

ضرایب رتبه پیرسون، اسپیرمن و کندال با پانداها
را corr() روش سه روش ضریب را می پذیرد – 'pearson'، 'spearman' و 'kendall':
fig, ax = plt.subplots(1,3, figsize=(18, 8))
corr1 = df.corr('pearson')(('MedHouseVal')).sort_values(by='MedHouseVal', ascending=False)
corr2 = df.corr('spearman')(('MedHouseVal')).sort_values(by='MedHouseVal', ascending=False)
corr3 = df.corr('kendall')(('MedHouseVal')).sort_values(by='MedHouseVal', ascending=False)
sns.heatmap(corr1, ax=ax(0), annot=True)
sns.heatmap(corr2, ax=ax(1), annot=True)
sns.heatmap(corr3, ax=ax(2), annot=True)

(برچسبها به ترجمه)# python
منتشر شده در 1403-01-05 01:37:11
