از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
یکی از عوامل کلیدی محرک رشد فناوری داده ها است. با پیشرفت تکنولوژی، داده ها در ابزارهایی که ساخته می شوند مهم تر و حیاتی تر شده اند. این به عامل محرک رشد فناوری، روش جمع آوری، ذخیره، ایمن سازی و توزیع داده ها تبدیل شده است.
این رشد داده ها منجر به افزایش استفاده از معماری ابری برای ذخیره و مدیریت داده ها شده است و در عین حال زحمت لازم برای حفظ ثبات و دقت را به حداقل می رساند. به عنوان مصرف کنندگان فناوری، ما در حال تولید و مصرف داده هستیم و این امر نیاز به سیستم های پیچیده ای را برای کمک به مدیریت داده ها ضروری کرده است.
معماری ابری به ما این امکان را می دهد که تا زمانی که به اینترنت متصل هستیم، فایل ها را از چندین دستگاه آپلود و دانلود کنیم. و این بخشی از چیزی است که AWS به ما کمک می کند از طریق سطل های S3 به دست آوریم.
S3 چیست؟
سرویس ذخیره سازی ساده آمازون (S3) یک پیشنهاد توسط خدمات وب آمازون (AWS) که به کاربران اجازه می دهد داده ها را در قالب اشیا ذخیره کنند. این برای پاسخگویی به انواع کاربران، از شرکت ها گرفته تا سازمان های کوچک یا پروژه های شخصی طراحی شده است.
S3 می تواند برای ذخیره داده های مختلف از تصاویر، ویدئو و صدا تا پشتیبان گیری یا داده های ثابت وب سایت و سایر موارد استفاده شود.
سطل S3 یک منبع ذخیره نامی است که برای ذخیره داده ها استفاده می شود روی AWS. این شبیه به پوشه ای است که برای ذخیره داده ها استفاده می شود روی AWS. سطل ها دارای نام ها و بر اساس منحصر به فرد هستند روی در ردیف و قیمت، کاربران سطوح مختلف افزونگی و دسترسی را با قیمتهای متفاوت دریافت میکنند.
امتیازات دسترسی به سطل های S3 را می توان از طریق کنسول AWS، ابزار AWS CLI یا از طریق API ها و کتابخانه های ارائه شده نیز مشخص کرد.
Boto3 چیست؟
Boto3 یک کیت توسعه نرم افزار (SDK) است که توسط AWS برای تسهیل تعامل با S3 API و سایر خدمات مانند ابر محاسباتی الاستیک (EC2). با استفاده از Boto3، میتوانیم تمام سطلهای S3 را فهرست کنیم، نمونههای EC2 ایجاد کنیم یا هر تعداد منبع AWS را کنترل کنیم.
چرا از S3 استفاده کنیم؟
ما همیشه میتوانیم سرورهای خود را برای ذخیره دادهها و دسترسی به آنها از طیف وسیعی از دستگاهها از طریق اینترنت فراهم کنیم، پس چرا باید از S3 AWS استفاده کنیم؟ چندین سناریو وجود دارد که در آن به کار می آید.
اول، AWS S3 تمام کارها و هزینه های مربوط به ساخت و نگهداری سرورهایی را که داده های ما را ذخیره می کنند حذف می کند. ما لازم نیست نگران به دست آوردن سخت افزار به host داده های ما یا پرسنل مورد نیاز برای نگهداری زیرساخت. در عوض، ما می توانیم تنها تمرکز کنیم روی کد ما و اطمینان از اینکه خدمات ما در بهترین شرایط هستند.
با استفاده از S3، میتوانیم از عملکرد چشمگیر، در دسترس بودن و قابلیتهای مقیاسپذیری AWS بهره ببریم. کد ما می تواند به طور موثر مقیاس شود و تحت بارهای سنگین کار کند و در دسترس کاربران نهایی ما باشد. ما بدون نیاز به ایجاد یا مدیریت زیرساخت های پشت آن به این مهم دست یابیم.
AWS ابزارهایی را برای کمک به ما در زمینه تجزیه و تحلیل و ممیزی و همچنین مدیریت و گزارش ارائه می دهد روی داده های ما ما میتوانیم روش دسترسی به دادههای موجود در سطلهایمان را مشاهده و تجزیه و تحلیل کنیم یا حتی دادهها را در مناطق دیگر تکرار کنیم تا دسترسی کاربران نهایی به دادهها را افزایش دهیم. دادههای ما نیز رمزگذاری شده و بهطور ایمن ذخیره میشوند تا همیشه امن باشند.
از طریق AWS Lambda ما همچنین میتوانیم به دادههایی که از سطلهای S3 خود آپلود یا دانلود میشوند پاسخ دهیم و از طریق هشدارها یا گزارشهای پیکربندیشده برای تجربه شخصیتر و فوریتر همانطور که از فناوری انتظار میرود به کاربران پاسخ دهیم.
راه اندازی AWS
برای شروع کار با S3، باید یک حساب کاربری ایجاد کنیم روی AWS یا وارد یکی موجود شوید.
همچنین باید ابزار AWS CLI را راهاندازی کنیم تا بتوانیم از طریق خط فرمان با منابع خود تعامل داشته باشیم که برای مک، لینوکس و ویندوز در دسترس است.
ما می توانیم آن را با اجرای:
$ pip install awscli
هنگامی که ابزار CLI راه اندازی شد، می توانیم اعتبارنامه های خود را در زیر نمایه خود ایجاد کنیم و از آنها برای پیکربندی ابزار CLI خود به صورت زیر استفاده کنیم:
$ aws configure
این دستور به ما دستوراتی می دهد تا ما را ارائه کنیم Access Key ID، Secret Access Key، مناطق پیش فرض و فرمت های خروجی. جزئیات بیشتر در مورد پیکربندی ابزار AWS CLI را می توان یافت اینجا.
برنامه ما – FlaskDrive
برپایی
بیایید یک برنامه Flask بسازیم که به کاربران اجازه میدهد فایلها را در سطل S3 ما آپلود و دانلود کنند. روی AWS.
ما از Boto3 SDK برای تسهیل این عملیات استفاده میکنیم و یک front-end ساده ایجاد میکنیم تا به کاربران اجازه آپلود و مشاهده فایلها را به صورت آنلاین میزبانی کنیم.
استفاده از محیط مجازی هنگام کار توصیه می شود روی پروژه های پایتون، و برای این یکی از آن استفاده خواهیم کرد پیپنف ابزاری برای ایجاد و مدیریت محیط ما پس از راه اندازی، محیط خود را با Python3 به صورت زیر ایجاد و فعال می کنیم:
$ pipenv install --three
$ pipenv shell
اکنون باید نصب کنیم Boto3 و Flask که برای ساخت برنامه FlaskDrive ما به شرح زیر مورد نیاز است:
$ pipenv install flask
$ pipenv install boto3
پیاده سازی
پس از راهاندازی، باید سطلهایی برای ذخیره دادههای خود ایجاد کنیم و میتوانیم با رفتن به AWS به آن دست پیدا کنیم. console و انتخاب S3 در خدمات منو.
پس از ایجاد یک سطل، می توانیم از ابزار CLI برای مشاهده سطل های موجود استفاده کنیم:
$ aws s3api list-buckets
{
"Owner": {
"DisplayName": "robley",
"ID": "##########################################"
},
"Buckets": (
{
"CreationDate": "2019-09-25T10:33:40.000Z",
"Name": "flaskdrive"
}
)
}
اکنون توابعی برای آپلود، دانلود و فهرست کردن فایل ها ایجاد می کنیم روی سطل های S3 ما با استفاده از Boto3 SDK، با شروع upload_file تابع:
def upload_file(file_name, bucket):
"""
Function to upload a file to an S3 bucket
"""
object_name = file_name
s3_client = boto3.client('s3')
response = s3_client.upload_file(file_name, bucket, object_name)
return response
این upload_file تابع یک فایل و نام سطل را می گیرد و فایل داده شده را در سطل S3 ما آپلود می کند روی AWS.
def download_file(file_name, bucket):
"""
Function to download a given file from an S3 bucket
"""
s3 = boto3.resource('s3')
output = f"downloads/{file_name}"
s3.Bucket(bucket).download_file(file_name, output)
return output
این download_file تابع یک نام فایل و یک سطل را می گیرد و آن را در پوشه ای که ما مشخص کرده ایم دانلود می کند.
def list_files(bucket):
"""
Function to list files in a given S3 bucket
"""
s3 = boto3.client('s3')
contents = ()
for item in s3.list_objects(Bucket=bucket)('Contents'):
contents.append(item)
return contents
کارکرد list_files برای بازیابی فایل های موجود در سطل S3 ما و فهرست کردن نام آنها استفاده می شود. ما از این نام ها برای دانلود فایل ها از سطل S3 خود استفاده خواهیم کرد.
با در اختیار داشتن فایل تعاملی S3، میتوانیم برنامه Flask خود را بسازیم تا رابط مبتنی بر وب را برای تعامل ارائه کنیم. این برنامه یک برنامه Flask تک فایلی ساده برای اهداف نمایشی با ساختار زیر خواهد بود:
.
├── Pipfile # stores our application requirements
├── __init__.py
├── app.py # our main Flask application
├── downloads # folder to store our downloaded files
├── s3_demo.py # S3 interaction code
├── templates
│ └── storage.html
└── uploads # folder to store the uploaded files
عملکرد اصلی برنامه Flask ما در app.py فایل:
import os
from flask import Flask, render_template, request, redirect, send_file
from s3_demo import list_files, download_file, upload_file
app = Flask(__name__)
UPLOAD_FOLDER = "uploads"
BUCKET = "flaskdrive"
@app.route('/')
def entry_point():
return 'Hello World!'
@app.route("/storage")
def storage():
contents = list_files("flaskdrive")
return render_template('storage.html', contents=contents)
@app.route("/upload", methods=('POST'))
def upload():
if request.method == "POST":
f = request.files('file')
f.save(os.path.join(UPLOAD_FOLDER, f.filename))
upload_file(f"uploads/{f.filename}", BUCKET)
return redirect("/storage")
@app.route("/download/<filename>", methods=('GET'))
def download(filename):
if request.method == 'GET':
output = download_file(filename, BUCKET)
return send_file(output, as_attachment=True)
if __name__ == '__main__':
app.run(debug=True)
این یک برنامه ساده Flask با 4 نقطه پایانی است:
- این
/storageنقطه پایان فرود خواهد بود page جایی که ما فایلهای فعلی را در سطل S3 خود برای دانلود نمایش میدهیم، و همچنین ورودی برای کاربران برای آپلود فایل در سطل S3 ما، - این
/uploadنقطه پایانی برای دریافت فایل و سپس فراخوانی استفاده خواهد شدupload_file()روشی که یک فایل را در سطل S3 آپلود می کند - این
/downloadنقطه پایانی یک نام فایل دریافت می کند و از آن استفاده می کندdownload_file()روش دانلود فایل در دستگاه کاربر
و در نهایت، قالب HTML ما به همین سادگی خواهد بود:
<!DOCTYPE html>
<html>
<head>
<title>FlaskDrive</title>
</head>
<body>
<div class="content">
<h3>Flask Drive: S3 Flask Demo</h3>
<p>Welcome to this AWS S3 Demo</p>
<div>
<h3>Upload your file here:</h3>
<form method="POST" action="/upload" enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
</div>
<div>
<h3>These are your uploaded files:</h3>
<p>Click روی the filename to download it.</p>
<ul>
{% for item in contents %}
<li>
<a href="/download/{{ item.Key }}"> {{ item.Key }} </a>
</li>
{% endfor %}
</ul>
</div>
</div>
</body>
</html>
با تنظیم کد و پوشه های ما، برنامه خود را با موارد زیر شروع می کنیم:
$ python app.py
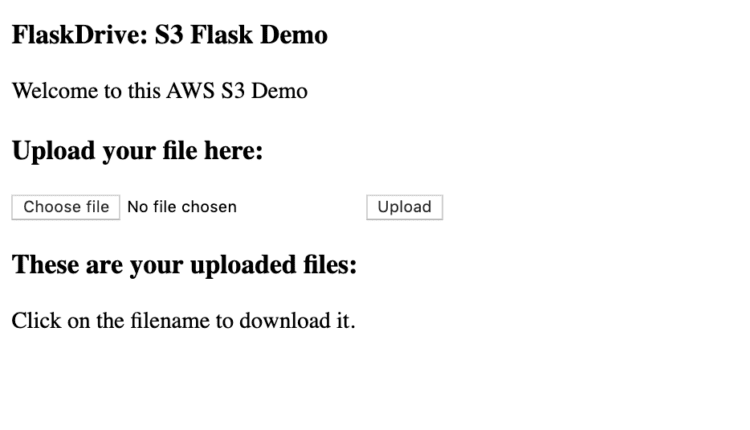
هنگامی که ما به http://localhost:5000/storage فرود زیر از ما استقبال می کند page:

اجازه دهید اکنون یک فایل را با استفاده از فیلد ورودی آپلود کنیم و این خروجی است:

میتوانیم با بررسی داشبورد S3، آپلود را تأیید کنیم و میتوانیم تصویر خود را در آنجا پیدا کنیم:

فایل ما با موفقیت از دستگاه ما در S3 Storage AWS آپلود شد.
بر روی … ما FlaskDrive فرود آمدن page، می توانیم فایل را به سادگی با کلیک کردن دانلود کنیم روی نام فایل را دریافت می کنیم و سپس دستور ذخیره فایل را دریافت می کنیم روی ماشین های ما
نتیجه
در این پست یک اپلیکیشن Flask ایجاد کرده ایم که فایل ها را ذخیره می کند روی S3 AWS و به ما امکان می دهد فایل های مشابه را از برنامه خود دانلود کنیم. ما از کتابخانه Boto3 در کنار ابزار AWS CLI برای مدیریت تعامل بین برنامه خود و AWS استفاده کردیم.
ما نیاز به داشتن سرورهای خود را برای مدیریت ذخیرهسازی فایلهایمان از بین بردهایم و از زیرساختهای آمازون استفاده کردهایم تا از طریق سرویس ذخیرهسازی ساده AWS آن را برای ما مدیریت کنیم. توسعه، استقرار و در دسترس قرار دادن برنامه خود برای کاربران نهایی زمان کوتاهی را از ما گرفته است و اکنون میتوانیم آن را برای افزودن مجوزها در میان ویژگیهای دیگر ارتقا دهیم.
کد منبع این پروژه موجود است اینجا روی GitHub.
(برچسبها برای ترجمه)# aws
منتشر شده در 1403-01-20 06:33:02
