از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
به عنوان یک تحلیلگر داده، مسئولیت ما تضمین یکپارچگی داده ها برای به دست آوردن بینش دقیق و قابل اعتماد است. پاکسازی داده ها نقشی حیاتی در این امر ایفا می کند process، و مقادیر تکراری از رایج ترین مسائلی هستند که تحلیلگران داده با آن مواجه می شوند. مقادیر تکراری به طور بالقوه می توانند اطلاعات بینش را نادرست نشان دهند. بنابراین، وجود روشهای کارآمد برای مقابله با مقادیر تکراری بسیار مهم است. در این مقاله، روش شناسایی و مدیریت مقادیر تکراری و همچنین بهترین روشها برای مدیریت موارد تکراری را خواهیم آموخت.
شناسایی مقادیر تکراری
اولین قدم در مدیریت مقادیر تکراری، شناسایی آنهاست. شناسایی مقادیر تکراری گام مهمی در پاکسازی داده ها است. Pandas روش های متعددی را برای شناسایی مقادیر تکراری در یک دیتا فریم ارائه می دهد. در این بخش به بحث خواهیم پرداخت duplicated() عملکرد و value_counts() تابعی برای شناسایی مقادیر تکراری
یوسین تکراری ()
را duplicated() تابع یک تابع کتابخانه پاندا است که ردیف های تکراری را در یک DataFrame بررسی می کند. خروجی از duplicated() تابع یک سری بولی با طولی برابر با DataFrame ورودی است، که در آن هر عنصر نشان می دهد که آیا سطر مربوطه تکراری است یا خیر.
بیایید یک مثال ساده از آن را در نظر بگیریم duplicated() تابع:
import pandas as pd
data = {
'StudentName': ('Mark', 'Ali', 'Bob', 'John', 'Johny', 'Mark'),
'Score': (45, 65, 76, 44, 39, 45)
}
df = pd.DataFrame(data)
df_duplicates = df.duplicated()
print(df_duplicates)
خروجی:
0 False
1 False
2 False
3 False
4 False
5 True
dtype: bool
در مثال بالا، ما یک DataFrame حاوی نام دانشآموزان و مجموع امتیازات آنها ایجاد کردیم. استناد کردیم duplicated() روی DataFrame که یک سری بولی با False نشان دهنده ارزش های منحصر به فرد و True نشان دهنده مقادیر تکراری
در این مثال، اولین وقوع مقدار یکتا در نظر گرفته می شود. با این حال، اگر بخواهیم آخرین مقدار منحصربهفرد در نظر گرفته شود، و نخواهیم تمام ستونها را هنگام شناسایی مقادیر تکراری در نظر بگیریم، چه؟ در اینجا، ما می توانیم تغییر دهید duplicated() با تغییر مقادیر پارامتر عمل کنید.
پارامترها: زیر مجموعه و Keep
را duplicated() تابع از طریق پارامترهای اختیاری خود گزینه های سفارشی سازی را ارائه می دهد. دارای دو پارامتر است که در زیر توضیح داده شده است:
-
subset: این پارامتر ما را قادر می سازد تا زیرمجموعه ستون ها را در هنگام تشخیص تکراری در نظر بگیریم. زیر مجموعه تنظیم شده استNoneبه طور پیش فرض، به این معنی که هر ستون در DataFrame در نظر گرفته می شود. برای تعیین نام ستونها، میتوانیم فهرستی از نام ستونها را به زیر مجموعه ارائه کنیم.در اینجا مثالی از استفاده از پارامتر زیر مجموعه آورده شده است:
df_duplicates = df.duplicated(subset=('StudentName'))خروجی:
0 False 1 False 2 False 3 False 4 False 5 True dtype: bool -
keep: این گزینه به ما اجازه می دهد تا انتخاب کنیم کدام نمونه از ردیف تکراری باید به عنوان تکراری علامت گذاری شود. مقادیر ممکن برای نگه داشتن عبارتند از:"first": این مقدار پیش فرض برای استkeepگزینه. همه موارد تکراری به جز اولین رخداد را شناسایی می کند و مقدار اول را منحصر به فرد می داند."last": این گزینه آخرین رخداد را به عنوان یک مقدار منحصر به فرد شناسایی می کند. همه موارد دیگر تکراری تلقی خواهند شد.False: این گزینه هر نمونه را به عنوان یک مقدار تکراری برچسب گذاری می کند.
در اینجا یک مثال از استفاده از keep پارامتر:
df_duplicates = df.duplicated(keep='last')
print(df_duplicates)
خروجی:
0 True
1 False
2 False
3 False
4 False
5 False
dtype: bool
تجسم مقادیر تکراری
را value_counts() تابع دومین رویکرد برای شناسایی موارد تکراری است. را value_counts() تابع تعداد دفعاتی که هر مقدار منحصر به فرد در یک ستون ظاهر می شود را می شمارد. با استفاده از value_counts() تابع به یک ستون خاص، فرکانس هر مقدار را می توان تجسم کرد.
در اینجا یک مثال از استفاده از value_counts() تابع:
import matplotlib.pyplot as plt
import pandas as pd
data = {
'StudentName': ('Mark', 'Ali', 'Bob', 'John', 'Johny', 'Mark'),
'Score': (45, 65, 76, 44, 39, 45)
}
df = pd.DataFrame(data)
name_counts = df('StudentName').value_counts()
print(name_counts)
خروجی:
Mark 2
Ali 1
Bob 1
John 1
Johny 1
Name: StudentName, dtype: int64
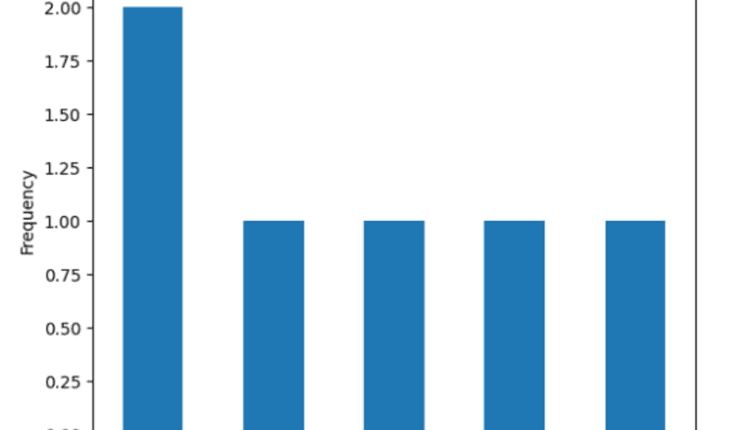
حالا بیایید مقادیر تکراری را با یک نمودار میله ای تجسم کنیم. ما می توانیم به طور موثر فراوانی مقادیر تکراری را با استفاده از نمودار میله ای تجسم کنیم.
name_counts.plot(kind='bar')
plt.xlabel('Student Name')
plt.ylabel('Frequency')
plt.title('Duplicate Name Frequencies')
plt.show()

مدیریت مقادیر تکراری
پس از شناسایی مقادیر تکراری، نوبت به پرداختن به آنها می رسد. در این بخش، استراتژیهای مختلف برای حذف و بهروزرسانی مقادیر تکراری با استفاده از پانداها را بررسی خواهیم کرد. drop_duplicates() و replace() کارکرد. علاوه بر این، در مورد جمع آوری داده ها با مقادیر تکراری با استفاده از groupby() تابع.
حذف مقادیر تکراری
رایج ترین روش برای رسیدگی به موارد تکراری، حذف آنها از DataFrame است. برای حذف رکوردهای تکراری از DataFrame، از drop_duplicates() تابع. به طور پیش فرض، این تابع اولین نمونه از هر ردیف تکراری را نگه می دارد و رخدادهای بعدی را حذف می کند. این مقادیر تکراری را بر اساس شناسایی می کند روی تمام مقادیر ستون؛ با این حال، میتوانیم ستون مورد نظر را با استفاده از پارامترهای زیرمجموعه مشخص کنیم.
نحو از drop_duplicates() با مقادیر پیش فرض در پارامترها به صورت زیر است:
dataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
را subset و keep پارامترها توضیح مشابهی دارند که در duplicates(). اگر پارامتر سوم را تنظیم کنیم inplace به True، تمام تغییرات به طور مستقیم انجام خواهد شد روی DataFrame اصلی، که منجر به بازگشت متد می شود None و DataFrame اصلی در حال تغییر است. به صورت پیش فرض، inplace است False.
در اینجا یک نمونه از drop_duplicates() تابع:
df.drop_duplicates(keep='last', inplace=True)
print(df)
خروجی:
StudentName Score
1 Ali 65
2 Bob 76
3 John 44
4 Johny 39
5 Mark 45
در مثال بالا، اولین ورودی حذف شد زیرا تکراری بود.
مقادیر تکراری را جایگزین یا به روز کنید
روش دوم برای رسیدگی به موارد تکراری شامل جایگزینی مقدار با استفاده از پانداها است replace() تابع. را replace() تابع به ما اجازه می دهد مقادیر یا الگوهای خاصی را در یک DataFrame با مقادیر جدید جایگزین کنیم. به طور پیش فرض، همه نمونه های مقدار را جایگزین می کند. با این حال، با استفاده از پارامتر limit، میتوانیم تعداد تعویضها را محدود کنیم.
در اینجا یک مثال از استفاده از replace() تابع:
df('StudentName').replace('Mark', 'Max', limit=1, inplace=True)
print(df)
خروجی:
StudentName Score
0 Max 45
1 Ali 65
2 Bob 76
3 John 44
4 Johny 39
5 Mark 45
در اینجا، از حد برای جایگزینی مقدار اول استفاده شد. اگر بخواهیم آخرین اتفاق را جایگزین کنیم چه؟ در این مورد، ما را با هم ترکیب می کنیم duplicated() و replace() کارکرد. استفاده کردن duplicated()، آخرین نمونه از هر مقدار تکراری را نشان می دهیم، شماره ردیف را با استفاده از نشان می دهیم loc تابع، و سپس با استفاده از replace() تابع. در اینجا یک مثال از استفاده است duplicated() و replace() با هم کار می کند.
last_occurrences = df.duplicated(subset='StudentName', keep='first')
last_occurrences_rows = df(last_occurrences)
df.loc(last_occurrences, 'StudentName') = df.loc(last_occurrences, 'StudentName').replace('Mark', 'Max')
print(df)
خروجی:
StudentName Score
0 Mark 45
1 Ali 65
2 Bob 76
3 John 44
4 Johny 39
5 Max 45
توابع سفارشی برای جایگزینی های پیچیده
در برخی موارد، مدیریت مقادیر تکراری نیاز به جایگزینی پیچیده تری نسبت به حذف یا به روز رسانی آنها دارد. توابع سفارشی ما را قادر می سازد تا قوانین جایگزینی خاص را متناسب با نیازهای خود ایجاد کنیم. با استفاده از پانداها apply() تابع، ما می توانیم تابع سفارشی را به داده های خود اعمال کنیم.
به عنوان مثال، فرض کنید ستون “StudentName” حاوی نام های تکراری است. هدف ما جایگزین کردن موارد تکراری با استفاده از یک تابع سفارشی است که یک عدد را در انتهای مقادیر تکراری اضافه می کند و آنها را منحصر به فرد می کند.
def add_number(name, counts):
if name in counts:
counts(name) += 1
return f'{name}_{counts(name)}'
else:
counts(name) = 0
return name
name_counts = {}
df('is_duplicate') = df.duplicated('StudentName', keep=False)
df('StudentName') = df.apply(lambda x: add_number(x('StudentName'), name_counts) if x('is_duplicate') else x('StudentName'), axis=1)
df.drop('is_duplicate', axis=1, inplace=True)
print(df)
خروجی:
StudentName Score
0 Mark 45
1 Ali 65
2 Bob 76
3 John 44
4 Johny 39
5 Mark_1 45
جمع آوری داده ها با مقادیر تکراری
داده های حاوی مقادیر تکراری را می توان برای خلاصه کردن و به دست آوردن بینش از داده ها جمع آوری کرد. پانداها groupby() تابع به شما امکان می دهد داده ها را با مقادیر تکراری جمع آوری کنید. با استفاده از groupby() تابع، می توانید یک یا چند ستون را گروه بندی کنید و میانگین، میانه یا مجموع ستون دیگری را برای هر گروه محاسبه کنید.
در اینجا یک مثال از استفاده از groupby() روش:
grouped = df.groupby(('StudentName'))
df_aggregated = grouped.sum()
print(df_aggregated)
خروجی:
Score
StudentName
Ali 65
Bob 76
John 44
Johny 39
Mark 90
تکنیک های پیشرفته
برای رسیدگی به سناریوهای پیچیده تر و اطمینان از تجزیه و تحلیل دقیق، چند تکنیک پیشرفته وجود دارد که می توانیم از آنها استفاده کنیم. این بخش در مورد برخورد با تکرارهای فازی، تکرار در داده های سری زمانی و مقادیر شاخص تکراری بحث خواهد کرد.
کپی های فازی
تکرارهای فازی رکوردهایی هستند که دقیقا مطابقت ندارند اما مشابه هستند و ممکن است به دلایل مختلفی از جمله اشتباهات ورودی داده ها، غلط املایی و تغییرات در قالب بندی رخ دهند. ما استفاده خواهیم کرد fuzzywuzzy کتابخانه پایتون برای شناسایی موارد تکراری با استفاده از تطبیق شباهت رشته ها.
در اینجا مثالی از مدیریت مقادیر فازی آورده شده است:
import pandas as pd
from fuzzywuzzy import fuzz
def find_fuzzy_duplicates(dataframe, column, threshold):
duplicates = ()
for i in range(len(dataframe)):
for j in range(i+1, len(dataframe)):
similarity = fuzz.ratio(dataframe(column)(i), dataframe(column)(j))
if similarity >= threshold:
duplicates.append(dataframe.iloc((i, j)))
if duplicates:
duplicates_df = pd.concat(duplicates)
return duplicates_df
else:
return pd.DataFrame()
data = {
'StudentName': ('Mark', 'Ali', 'Bob', 'John', 'Johny', 'Mark'),
'Score': (45, 65, 76, 44, 39, 45)
}
df = pd.DataFrame(data)
threshold = 70
fuzzy_duplicates = find_fuzzy_duplicates(df, 'StudentName', threshold)
print("Fuzzy duplicates:")
print(fuzzy_duplicates.to_string(index=False))
در این مثال، ما یک تابع سفارشی ایجاد می کنیم find_fuzzy_duplicates که یک DataFrame، نام ستون و آستانه تشابه را به عنوان ورودی می گیرد. تابع در هر ردیف در DataFrame تکرار می شود و با استفاده از سطرهای بعدی آن را مقایسه می کند. fuzz.ratio روش از fuzzywuzzy کتابخانه اگر امتیاز شباهت بیشتر یا مساوی با آستانه باشد، ردیف های تکراری به یک لیست اضافه می شوند. در نهایت، تابع یک DataFrame حاوی موارد تکراری فازی را برمیگرداند.
خروجی:
Fuzzy duplicates:
StudentName Score
Mark 45
Mark 45
John 44
Johny 39
در مثال بالا، تکرارهای فازی در ستون “StudentName” شناسایی می شوند. تابع ‘find_fuzzy_duplicates’ هر جفت رشته را با استفاده از عبارت مقایسه می کند fuzzywuzzy کتابخانه fuzz.ratio تابع، که امتیاز شباهت را بر اساس محاسبه می کند روی فاصله لونشتاین ما آستانه را روی 70 قرار دادهایم، به این معنی که هر نامی با نسبت مطابقت بیشتر از 70 یک مقدار فازی در نظر گرفته میشود. پس از شناسایی مقادیر فازی، میتوانیم آنها را با استفاده از روشی که در بخش با عنوان «بررسی موارد تکراری» توضیح داده شده است، مدیریت کنیم.
رسیدگی به داده های تکراری سری زمانی
هنگامی که چندین مشاهدات همزمان ثبت می شوند، می توانند تکرار شوند. این مقادیر در صورتی که به درستی مورد استفاده قرار نگیرند می توانند منجر به نتایج مغرضانه شوند. در اینجا چند روش برای مدیریت مقادیر تکراری در داده های سری زمانی وجود دارد.
- حذف دقیق موارد تکراری: در این روش ردیف های یکسان را با استفاده از عبارت حذف می کنیم
drop_duplicatesعملکرد در پانداها - مُهرهای زمانی تکراری با مقادیر مختلف: اگر مُهر زمانی یکسانی داشته باشیم اما مقادیر متفاوتی داشته باشیم، میتوانیم دادهها را جمع آوری کنیم و با استفاده از آن بینش بیشتری به دست آوریم.
groupby()، یا می توانیم جدیدترین مقدار را انتخاب کرده و با استفاده از مقادیر دیگر حذف کنیمdrop_duplicates()باkeepپارامتر روی “آخرین” تنظیم شده است.
مدیریت مقادیر تکراری شاخص
قبل از پرداختن به مقادیر شاخص تکراری، اجازه دهید ابتدا تعریف کنیم که یک شاخص در پانداها چیست. ایندکس یک شناسه منحصر به فرد است که به هر ردیف از DataFrame اختصاص داده می شود. Pandas به طور پیش فرض یک شاخص عددی را که از صفر شروع می شود اختصاص می دهد. با این حال، یک شاخص را می توان به هر ستون یا ترکیب ستونی اختصاص داد. برای شناسایی موارد تکراری در ستون Index، می توانیم از duplicated() و drop_duplicates() توابع، به ترتیب. در این بخش، روش رسیدگی به موارد تکراری در ستون Index را با استفاده از آن بررسی خواهیم کرد reset_index().
همانطور که از نام آن پیداست، reset_index() تابع در Pandas برای تنظیم مجدد شاخص DataFrame استفاده می شود. هنگام اعمال reset_index() عملکرد، شاخص فعلی به طور خودکار حذف می شود، به این معنی که مقادیر شاخص اولیه از بین می روند. با مشخص کردن drop پارامتر به عنوان False در reset_index() تابع، ما می توانیم مقدار شاخص اصلی را در حین تنظیم مجدد شاخص حفظ کنیم.
در اینجا یک مثال از استفاده است reset_index():
import pandas as pd
data = {
'Score': (45, 65, 76, 44, 39, 45)
}
df = pd.DataFrame(data, index=('Mark', 'Ali', 'Bob', 'John', 'Johny', 'Mark'))
df.reset_index(inplace=True)
print(df)
خروجی:
index Score
0 Mark 45
1 Ali 65
2 Bob 76
3 John 44
4 Johny 39
5 Mark 45
بهترین شیوه ها
-
ماهیت داده های تکراری را درک کنید: قبل از هر اقدامی، درک اینکه چرا مقادیر تکراری وجود دارند و چه چیزی را نشان می دهند بسیار مهم است. علت اصلی را شناسایی کنید و سپس اقدامات مناسب برای مقابله با آنها را تعیین کنید.
-
یک روش مناسب برای رسیدگی به موارد تکراری انتخاب کنید: همانطور که در بخش های قبلی بحث شد، راه های متعددی برای رسیدگی به موارد تکراری وجود دارد. روشی که انتخاب می کنید بستگی دارد روی ماهیت داده ها و تحلیلی که قصد انجام آن را دارید.
-
رویکرد را مستند کنید: مستند کردن این موضوع بسیار مهم است process برای تشخیص مقادیر تکراری و پرداختن به آنها، به دیگران اجازه می دهد تا افکار را درک کنند process.
-
احتیاط کنید: هر زمان که داده ها را حذف یا اصلاح می کنیم، باید اطمینان حاصل کنیم که حذف موارد تکراری باعث ایجاد خطا یا سوگیری در تجزیه و تحلیل نمی شود. آزمایش های سلامت عقل را انجام دهید و نتایج هر عمل را تأیید کنید.
-
داده های اصلی را حفظ کنید: قبل از انجام هر عملیاتی روی داده، ایجاد یک backup کپی از داده های اصلی
-
جلوگیری از تکرارهای آینده: اجرای اقدامات برای جلوگیری از تکرار در آینده. این می تواند شامل اعتبار سنجی داده ها در هنگام ورود داده ها، روال های پاکسازی داده ها، یا محدودیت های پایگاه داده برای اعمال منحصر به فرد بودن باشد.
افکار نهایی
در تجزیه و تحلیل داده ها، پرداختن به مقادیر تکراری یک گام بسیار مهم است. مقادیر تکراری می تواند منجر به نتایج نادرست شود. با شناسایی و مدیریت موثر مقادیر تکراری، تحلیلگران داده می توانند اطلاعات دقیق و قابل توجهی را استخراج کنند. اجرای تکنیک های ذکر شده و پیروی از بهترین شیوه ها، تحلیلگران را قادر می سازد تا یکپارچگی داده های خود را حفظ کرده و بینش های ارزشمندی را از آن استخراج کنند.
(برچسبها به ترجمه)# python
منتشر شده در 1402-12-31 01:05:03
