از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



زمان لازم برای مطالعه: 3 دقیقه
مدلهای مبتنی بر درخت نه تنها به دلیل نتایجشان، و نیاز به تغییرات کمتر در هنگام کار با دادهها (به دلیل استحکام در ورودی و تغییرناپذیری مقیاس)، به انتخاب محبوبی برای یادگیری ماشین تبدیل شدهاند، بلکه به این دلیل که راهی برای گرفتن آن وجود دارد. نگاهی به داخل آنها بیندازید تا ببینید چه خبر است روی با داده ها
ما فرض می کنیم که شما به تازگی یک طبقه بندی کننده مبتنی بر درخت را با استفاده از a آموزش داده اید درخت تصمیم مدل، و می خواهید نگاهی به روش مدیریت داده ها توسط درخت بیندازید. می خواهید ببینید هنگام طبقه بندی یک نقطه به عنوان متعلق به یک کلاس چه تصمیماتی گرفته شده است!
این بدان معنی است که شما می خواهید به آن نگاه کنید مرزهای تصمیم گیری از درخت خوشبختانه، Scikit-Learn در حال حاضر یک DecisionBoundaryDisplay در sklearn.inspection مدول.
ابتدا یک مجموعه داده شراب اسباب بازی را بارگذاری می کنیم و آن را به مجموعه های قطار و آزمایش تقسیم می کنیم:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
SEED = 42
data = load_wine()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
random_state=SEED)
پس از تقسیم داده ها، می توانیم دو ستون داده را برای ترسیم مرز تصمیم انتخاب کنید، متناسب با طبقه بندی درخت روی آنها را، و طرح را ایجاد کنید:
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.tree import DecisionTreeClassifier
X_train_cols = X_train(:, :2)
classifier = DecisionTreeClassifier(max_depth=4,
random_state=SEED).fit(X_train_cols, y_train)
disp = DecisionBoundaryDisplay.from_estimator(classifier,
X_train_cols,
response_method="predict",
xlabel=data.feature_names(0), ylabel=data.feature_names(1),
alpha=0.5,
cmap=plt.cm.coolwarm)
disp.ax_.scatter(X_train(:, 0), X_train(:, 1),
c=y_train, edgecolor="k",
cmap=plt.cm.coolwarm)
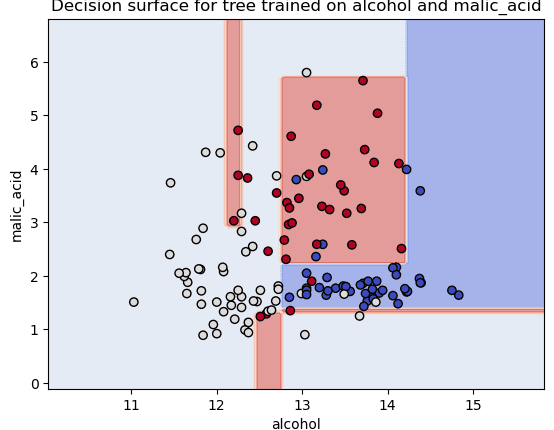
plt.title(f"Decision surface for tree trained روی {data.feature_names(0)} and {data.feature_names(1)}
")
plt.show()
نمودار حاصل به صورت زیر است:

مجموعه داده اصلی شراب دارای 13 ستون است، توجه داشته باشید که ما فقط 2 ستون را انتخاب کرده ایم – alcohol و malic_acid، بنابراین داده ها می توانند باشند با استفاده از دو بعد رسم شده است به جای 13 و تمام – شما فقط با استفاده از Python و Scikit-Learn مرزهای تصمیم را ترسیم کرده اید! اما، اگر علاقه دارید به چند نمونه دیگر نگاهی بیندازید – به خواندن ادامه دهید!
توجه داشته باشید: همچنین می توانید با روشی مانند PCA ابعاد داده ها را به 2 کاهش دهید و سپس مرز تصمیم مدل را رسم کنید. انجام این کار منجر به ایجاد همان کد قبلی می شود و فقط جایگزین می شود X_train_cols برای اجزای اصلی به دست آمده
ترسیم مرزهای تصمیم – مثال اضافی
اگر نگاهی به ترکیبهای ویژگیهای بیشتر جالب است، در زیر راهی برای ترسیم ترکیبها برای 5 ستون اول مجموعه داده شراب آورده شده است.
گام اولیه تولید تمام ترکیبات منحصر به فرد از ویژگی ها است:
from itertools import combinations
import numpy as np
comb = combinations(np.arange(0, 6), 2)
unique_combinations = set(comb)
این unique_combinations ستون هایی خواهند بود که مرزهای تصمیم برای آنها ترسیم می شود:
n_classes = 3
color_palette = plt.cm.coolwarm
plot_colors = "bwr"
plot_step = 0.02
plt.figure(figsize=(25, 12))
for pair_idx, pair in enumerate(sorted(unique_combinations)):
X_train_cols = X_train(:, pair)
classifier = DecisionTreeClassifier(max_depth=4,
random_state=SEED).fit(X_train_cols, y_train)
ax = plt.subplot(3, 5, pair_idx + 1)
DecisionBoundaryDisplay.from_estimator(classifier,
X_train_cols,
cmap=color_palette,
response_method="predict",
ax=ax,
xlabel=data.feature_names(pair(0)),
ylabel=data.feature_names(pair(1)),
alpha = 0.5)
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y_train == i)
plt.scatter(X_train_cols(idx, 0),
X_train_cols(idx, 1),
c=color,
label=data.target_names(i),
cmap=color_palette,
edgecolor="black",
s=15)
plt.suptitle("Decision surface of decision trees trained روی pairs of features", fontsize=14)
plt.legend(loc="lower right");
این کد نمودار زیر را نمایش می دهد:

هر دو طرح تصمیمگیری سفارشیسازیهای زیادی دارند، مانند پالتهای رنگ، تیرگی، فضای بین طرح و برچسبها و غیره. سعی کنید با تغییر برخی از مقادیر بازی کنید تا هر قسمت از کد را بهتر درک کنید!
توجه داشته باشید: این DecisionBoundaryDisplay به مدلهای مبتنی بر درخت محدود نمیشود، میتوانید از آن با برآوردگرهای دیگر در Scikit-learn استفاده کنید، مستندات برای دانستن بیشتر در مورد کاربردهای دیگر
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-02 10:03:03
