از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
متولد دریا یکی از پرکاربردترین کتابخانه های تجسم داده در پایتون، به عنوان پسوندی است Matplotlib. این یک API ساده، بصری و در عین حال بسیار قابل تنظیم برای تجسم داده ها ارائه می دهد.
در این آموزش، روش انجام این کار را بررسی خواهیم کرد طرح توزیع در Seaborn. ما روش ترسیم نمودار توزیع با Seaborn، روش تغییر اندازههای سطل پلات توزیع، و همچنین نمودارهای تخمین تراکم هسته را پوشش خواهیم داد. روی بالای آنها و نمایش داده های توزیع به جای داده های شمارش.
وارد کردن داده ها
ما از نمایش های نتفلیکس مجموعه داده و تجسم توزیع ها از آنجا.
اجازه دهید import پانداها و بارگذاری در مجموعه داده:
import pandas as pd
df = pd.read_csv('netflix_titles.csv')
چگونه با Seaborn یک پلات توزیع را ترسیم کنیم؟
Seaborn متفاوت است انواع از توطئه های توزیع که ممکن است بخواهید استفاده کنید.
این انواع نمودار عبارتند از: KDE Plots (kdeplot()و نمودارهای هیستوگرام (histplot()). هر دوی اینها را می توان از طریق عمومی به دست آورد displot() تابع، یا از طریق توابع مربوطه.
توجه داشته باشید: از آنجایی که Seaborn 0.11، distplot() تبدیل شده است displot(). اگر از نسخه قدیمیتری استفاده میکنید، باید از عملکرد قدیمیتر نیز استفاده کنید.
بیایید نقشه کشیدن را شروع کنیم.
پلات هیستوگرام/نقشه توزیع (displot) با Seaborn
بریم جلو و import ماژول های مورد نیاز و تولید الف هیستوگرام/نقشه توزیع.
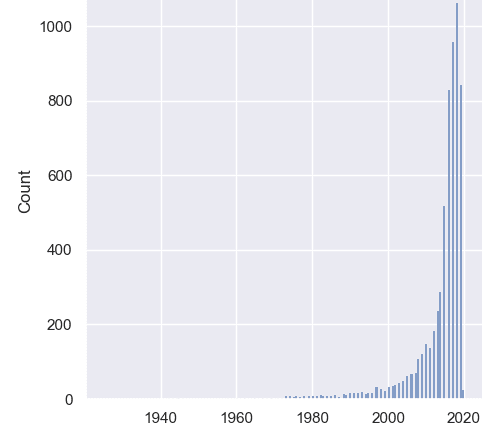
ما توزیع را تجسم خواهیم کرد release_year ویژگی، برای اینکه ببینید چه زمانی نتفلیکس با افزودن های جدید فعال ترین بوده است:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
df = pd.read_csv('netflix_titles.csv')
data = df('release_year')
sns.displot(data)
plt.show()
حال، اگر کد را اجرا کنیم، با نمودار هیستوگرام مواجه می شویم که تعداد وقوع این موارد را نشان می دهد. release_year ارزش های:

پلات توزیع پلات با اطلاعات چگالی با Seaborn
اکنون، مانند Matplotlib، رویکرد هیستوگرام پیشفرض شمارش تعداد رخدادها است. در عوض، میتوانید توزیع هر یک از این موارد را تجسم کنید انتشار_سال در درصد
بیایید اصلاح کنیم displot() برای تغییر آن تماس بگیرید:
data = df('release_year')
sns.displot(data, stat = 'density')
plt.show()
تنها چیزی که باید تغییر دهیم این است که آن را فراهم کنیم stat استدلال کنید، و به آن اطلاع دهید که مایلیم به جای اینکه چگالی را ببینیم 'count'.
اکنون، به جای شمارشی که قبلاً دیدهایم، تراکم ورودیها به ما نشان داده میشود:

تغییر اندازه سطل توزیع با Seaborn
گاهی اوقات، اندازه های سطل خودکار برای ما خیلی خوب کار نمی کنند. آنها خیلی بزرگ یا خیلی کوچک هستند. به طور پیش فرض، اندازه بر اساس انتخاب می شود روی واریانس مشاهدهشده در دادهها، اما این گاهی اوقات نمیتواند با آنچه ما میخواهیم به نمایش بگذاریم متفاوت باشد.
در طرح ما، آنها کمی بیش از حد کوچک هستند و به طرز ناخوشایندی با شکاف هایی بین آنها قرار می گیرند. می توانیم اندازه bin را با تنظیم کردن تغییر دهیم binwidth برای هر بن یا با تنظیم تعداد bins:
data = df('release_year')
sns.displot(data, binwidth = 3)
plt.show()
این باعث می شود که هر سطل داده ها را در بازه های 3 ساله در بر بگیرد:

یا، ما می توانیم تعداد ثابتی از bins:
data = df('release_year')
sns.displot(data, bins = 30)
plt.show()
اکنون، داده ها در 30 سطل بسته بندی می شوند و بسته به آن روی محدوده مجموعه داده شما، این یا تعداد زیادی bin یا مقدار بسیار کمی خواهد بود:

یکی دیگر از راه های عالی برای خلاص شدن از شکاف های ناخوشایند، تنظیم است discrete استدلال به True:
data = df('release_year')
sns.displot(data, discrete=True)
plt.show()
این نتیجه در:

Plot Distribution Plot با KDE
یک نمودار رایج برای رسم در کنار هیستوگرام، نمودار تخمین چگالی هسته است. آنها صاف هستند و با ربودن محدوده ای از مقادیر در سطل ها هیچ ارزشی را از دست نمی دهید. می توانید یک مقدار bin بزرگتر تنظیم کنید، یک نمودار KDE را روی هیستوگرام قرار دهید و تمام اطلاعات مربوطه را داشته باشید روی صفحه نمایش
خوشبختانه، از آنجایی که این یک کار واقعاً معمولی بود، Seaborn به ما اجازه میدهد یک نمودار KDE را به سادگی با تنظیم kde استدلال به True:
data = df('release_year')
sns.displot(data, discrete = True, kde = True)
plt.show()
این در حال حاضر منجر به:

پلات توزیع مشترک با Seaborn
گاهی اوقات، ممکن است بخواهید چندین ویژگی را در برابر یکدیگر و توزیع آنها تجسم کنید. به عنوان مثال، ممکن است بخواهیم توزیع رتبه بندی نمایش ها و همچنین سال اضافه شدن آنها را تجسم کنیم. اگر به دنبال این بودیم که ببینیم آیا نتفلیکس در طول سالها شروع به اضافه کردن محتوای مناسبتر برای کودکان کرده است، این یک جفت عالی برای طرح مشترک.
بیایید یک jointplot():
df = pd.read_csv('netflix_titles.csv')
df.dropna(inplace=True)
sns.jointplot(x = "rating", y = "release_year", data = df)
plt.show()
از آنجایی که Seaborn در تبدیل آنها به مقادیر قابل استفاده با مشکل مواجه خواهد شد، ما مقادیر null را در اینجا حذف کرده ایم.
در اینجا، ما یک نمودار هیستوگرام برای آن ساخته ایم رتبه بندی ویژگی، و همچنین یک نمودار هیستوگرام برای انتشار_سال ویژگی:

می بینیم که بیشتر ورودی های اضافه شده هستند TV-MAبا این حال، موارد زیادی نیز وجود دارد TV-14 ورودیها، بنابراین مجموعه خوبی از نمایشها برای کل خانواده وجود دارد.
نتیجه
در این آموزش، ما چندین روش را برای ترسیم نمودار توزیع با استفاده از Seaborn و Python بررسی کردهایم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً ما را بررسی کنید بسته کتاب روی تجسم داده ها در پایتون:
تجسم داده ها در پایتون با Matplotlib و Pandas کتابی است که طراحی شده است تا مبتدیان مطلق را با دانش پایه پایتون به Pandas و Matplotlib ببرد و به آنها اجازه دهد پایه ای قوی برای کار پیشرفته با این کتابخانه ها بسازند – از طرح های ساده گرفته تا طرح های سه بعدی متحرک با دکمه های تعاملی.
این به عنوان یک راهنمای عمیق عمل می کند که همه چیزهایی را که باید در مورد پانداها و Matplotlib بدانید، از جمله روش ساخت انواع طرح هایی که در خود کتابخانه تعبیه نشده اند را به شما آموزش می دهد.
تجسم داده ها در پایتون، کتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را در دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید. به طور خاص، در طول ۱۱ فصل، این کتاب ۹ کتابخانه پایتون را پوشش میدهد: Pandas، Matplotlib، Seaborn، Bokeh، Altair، Plotly، GGPlot، GeoPandas و VisPy.
این به عنوان یک راهنمای عملی و منحصر به فرد برای تجسم داده ها، در مجموعه ای از ابزارهایی که ممکن است در حرفه خود استفاده کنید، عمل می کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-14 08:52:03
