از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این چهاردهمین مقاله از سری مقالات من است روی پایتون برای NLP. در مقاله قبلی ام توضیح دادم که چگونه جملات را با استفاده از بردار عددی تبدیل کنیم کیسه کلمات رویکرد. برای درک بهتر رویکرد کیسه کلمات، این تکنیک را در پایتون پیاده سازی کردیم.
در این مقاله، مفهومی را که در مقاله آخر یاد گرفتهایم استوار میکنیم و آن را پیادهسازی میکنیم TF-IDF طرحی از ابتدا در پایتون اصطلاح TF مخفف “فرکانس مدت” است در حالی که اصطلاح IDF مخفف “فرکانس سند معکوس” است.
مشکل در مدل کیسه کلمات
قبل از اینکه واقعاً مدل TF-IDF را ببینیم، اجازه دهید ابتدا چند مشکل مرتبط با مدل کیسه کلمات را مورد بحث قرار دهیم.
در آخرین مقاله، سه جمله مثال زیر را داشتیم:
- “من دوست دارم فوتبال بازی کنم”
- “برای بازی تنیس بیرون رفتی”
- “من و جان تنیس بازی می کنیم”
مدل کیسه کلمات حاصل به این شکل بود:
| بازی | تنیس | به | من | فوتبال | انجام داد | شما | برو | |
|---|---|---|---|---|---|---|---|---|
| جمله 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
| جمله 2 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| جمله 3 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
یکی از مشکلات اصلی مربوط به مدل کیسه کلمات این است که صرف نظر از اهمیت آنها، ارزش یکسانی را برای کلمات قائل است. به عنوان مثال، کلمه “بازی” در هر سه جمله ظاهر می شود، بنابراین این کلمه بسیار رایج است. روی از سوی دیگر، کلمه “فوتبال” فقط در یک جمله آمده است. کلماتی که کمیاب هستند در مقایسه با کلمات رایج قدرت طبقه بندی بیشتری دارند.
ایده پشت رویکرد TF-IDF این است که به کلماتی که در یک جمله رایج تر و در جملات دیگر کمتر رایج هستند، وزن بالایی داده شود.
نظریه پشت TF-IDF
قبل از اجرای طرح TF-IDF در پایتون، اجازه دهید ابتدا نظریه را مطالعه کنیم. ما از همان سه جمله ای که در مدل کیسه کلمات استفاده کردیم به عنوان مثال استفاده خواهیم کرد.
- “من دوست دارم فوتبال بازی کنم”
- “برای بازی تنیس بیرون رفتی”
- “من و جان تنیس بازی می کنیم”
مرحله 1: توکن سازی
مانند کیسه کلمات، اولین گام برای پیاده سازی مدل TF-IDF، نشانه گذاری است.
| جمله 1 | جمله 2 | جمله 3 |
|---|---|---|
| من | انجام داد | جان |
| پسندیدن | شما | و |
| به | برو | من |
| بازی | خارج از | بازی |
| فوتبال | به | تنیس |
| بازی | ||
| تنیس |
مرحله 2: مقادیر TF-IDF را پیدا کنید
هنگامی که جملات را نشانه گذاری کردید، گام بعدی یافتن مقدار TF-IDF برای هر کلمه در جمله است.
همانطور که قبلاً بحث شد، مقدار TF به فرکانس مدت اشاره دارد و می تواند به صورت زیر محاسبه شود:
TF = (Frequency of the word in the sentence) / (Total number of words in the sentence)
به عنوان مثال، به کلمه “بازی” در جمله اول نگاه کنید. فراوانی عبارت آن 0.20 خواهد بود زیرا کلمه “بازی” فقط یک بار در جمله وجود دارد و تعداد کل کلمات در جمله 5 است، بنابراین 1/5 = 0.20 است.
IDF به فرکانس اسناد معکوس اشاره دارد و می تواند به صورت زیر محاسبه شود:
IDF: (Total number of sentences (documents))/(Number of sentences (documents) containing the word)
ذکر این نکته ضروری است که مقدار IDF برای یک کلمه در تمام اسناد یکسان می ماند زیرا به تعداد کل اسناد بستگی دارد. از طرف دیگر، مقادیر TF یک کلمه از سندی به سند دیگر متفاوت است.
بیایید فرکانس IDF کلمه “play” را پیدا کنیم. از آنجایی که ما سه سند داریم و کلمه “play” در هر سه آنها وجود دارد، بنابراین مقدار IDF کلمه “play” 3/3 = 1 است.
در نهایت، مقادیر TF-IDF با ضرب مقادیر TF با مقادیر IDF متناظر آنها محاسبه می شود.
برای یافتن مقدار TF-IDF، ابتدا باید یک فرهنگ لغت از بسامدهای کلمات را مطابق شکل زیر ایجاد کنیم:
| کلمه | فرکانس |
|---|---|
| من | 2 |
| پسندیدن | 1 |
| به | 2 |
| بازی | 3 |
| فوتبال | 1 |
| انجام داد | 1 |
| شما | 1 |
| برو | 1 |
| خارج از | 1 |
| تنیس | 2 |
| جان | 1 |
| و | 1 |
در مرحله بعد، بیایید فرهنگ لغت را به ترتیب نزولی فرکانس مرتب کنیم که در جدول زیر نشان داده شده است.
| کلمه | فرکانس |
|---|---|
| بازی | 3 |
| تنیس | 2 |
| به | 2 |
| من | 2 |
| فوتبال | 1 |
| انجام داد | 1 |
| شما | 1 |
| برو | 1 |
| خارج از | 1 |
| پسندیدن | 1 |
| جان | 1 |
| و | 1 |
در نهایت، 8 کلمه پرتکرار را فیلتر می کنیم.
همانطور که قبلاً گفتم، از آنجایی که مقادیر IDF با استفاده از کل مجموعه محاسبه می شود، اکنون می توانیم مقدار IDF را برای هر کلمه محاسبه کنیم. جدول زیر حاوی مقادیر IDF برای هر جدول است.
| کلمه | فرکانس | ارتش اسرائیل |
|---|---|---|
| بازی | 3 | 3/3 = 1 |
| تنیس | 2 | 3/2 = 1.5 |
| به | 2 | 3/2 = 1.5 |
| من | 2 | 3/2 = 1.5 |
| فوتبال | 1 | 3/1 = 3 |
| انجام داد | 1 | 3/1 = 3 |
| شما | 1 | 3/1 = 3 |
| برو | 1 | 3/1 = 3 |
شما به وضوح می بینید که کلماتی که نادر هستند در مقایسه با کلماتی که رایج تر هستند ارزش IDF بالاتری دارند.
حالا بیایید مقادیر TF-IDF را برای همه کلمات هر جمله پیدا کنیم.
| کلمه | جمله 1 | جمله 2 | جمله 3 |
|---|---|---|---|
| بازی | 0.20 x 1 = 0.20 | 0.14 x 1 = 0.14 | 0.20 x 1 = 0.20 |
| تنیس | 0 x 1.5 = 0 | 0.14 x 1.5 = 0.21 | 0.20 x 1.5 = 0.30 |
| به | 0.20 x 1.5 = 0.30 | 0.14 x 1.5 = 0.21 | 0 x 1.5 = 0 |
| من | 0.20 x 1.5 = 0.30 | 0 x 1.5 = 0 | 0.20 x 1.5 = 0.30 |
| فوتبال | 0.20 x 3 = 0.6 | 0 x 3 = 0 | 0 x 3 = 0 |
| انجام داد | 0 x 3 = 0 | 0.14 x 3 = 0.42 | 0 x 3 = 0 |
| شما | 0 x3 = 0 | 0.14 x 3 = 0.42 | 0 x 3 = 0 |
| برو | 0x3 = 0 | 0.14 x 3 = 0.42 | 0 x 3 = 0 |
مقادیر در ستون های جمله 1، 2 و 3 بردارهای TF-IDF متناظر برای هر کلمه در جملات مربوطه هستند.
توجه داشته باشید استفاده از تابع log با TF-IDF.
ذکر این نکته ضروری است که برای کاهش تأثیر کلمات بسیار نادر و بسیار رایج روی لاگ مقدار IDF را می توان قبل از ضرب آن در مقدار TF-IDF محاسبه کرد. در چنین حالتی فرمول IDF به صورت زیر در می آید:
IDF: log((Total number of sentences (documents))/(Number of sentences (documents) containing the word))
با این حال، از آنجایی که ما فقط سه جمله در مجموعه خود داشتیم، برای سادگی از log استفاده نکردیم. در قسمت پیاده سازی از تابع log برای محاسبه مقدار نهایی TF-IDF استفاده می کنیم.
مدل TF-IDF از ابتدا در پایتون
همانطور که در بخش تئوری توضیح داده شد، مراحل ایجاد یک فرهنگ لغت مرتب شده از بسامد کلمات بین کیسه کلمات و مدل TF-IDF مشابه است. برای درک چگونگی ایجاد فرهنگ لغت مرتب شده از بسامدهای کلمات، لطفاً به آخرین مقاله من مراجعه کنید. در اینجا، من فقط کد را می نویسم. مدل TF-IDF بر اساس این کد ساخته خواهد شد.
"""
Created روی Sat Jul 6 14:21:00 2019
@author: usman
"""
import nltk
import numpy as np
import random
import string
import bs4 as bs
import urllib.request
import re
raw_html = urllib.request.urlopen('https://en.wikipedia.org/wiki/Natural_language_processing')
raw_html = raw_html.read()
article_html = bs.BeautifulSoup(raw_html, 'lxml')
article_paragraphs = article_html.find_all('p')
article_text = ''
for para in article_paragraphs:
article_text += para.text
corpus = nltk.sent_tokenize(article_text)
for i in range(len(corpus )):
corpus (i) = corpus (i).lower()
corpus (i) = re.sub(r'\W',' ',corpus (i))
corpus (i) = re.sub(r'\s+',' ',corpus (i))
wordfreq = {}
for sentence in corpus:
tokens = nltk.word_tokenize(sentence)
for token in tokens:
if token not in wordfreq.keys():
wordfreq(token) = 1
else:
wordfreq(token) += 1
import heapq
most_freq = heapq.nlargest(200, wordfreq, key=wordfreq.get)
در اسکریپت بالا، ابتدا مقاله ویکی پدیا را خراش می دهیم روی پردازش زبان طبیعی. سپس آن را از قبل پردازش می کنیم تا همه کاراکترهای خاص و چندین فضای خالی حذف شوند. در نهایت، ما یک فرهنگ لغت از بسامدهای کلمات ایجاد می کنیم و سپس 200 کلمه پرتکرار را فیلتر می کنیم.
گام بعدی یافتن مقادیر IDF برای کلمات متداول در مجموعه است. اسکریپت زیر این کار را انجام می دهد:
word_idf_values = {}
for token in most_freq:
doc_containing_word = 0
for document in corpus:
if token in nltk.word_tokenize(document):
doc_containing_word += 1
word_idf_values(token) = np.log(len(corpus)/(1 + doc_containing_word))
در اسکریپت بالا یک دیکشنری خالی ایجاد می کنیم word_idf_values. این فرهنگ لغت اغلب کلماتی را که بهعنوان کلید و مقادیر IDF متناظر آنها را بهعنوان مقادیر فرهنگ لغت ذخیره میکند، ذخیره میکند. در مرحله بعد، ما لیستی از کلماتی که اغلب وجود دارند را تکرار می کنیم. در طول هر تکرار، یک متغیر ایجاد می کنیم doc_containing_word. این متغیر تعداد اسنادی را که کلمه در آنها ظاهر می شود ذخیره می کند. در مرحله بعد، تمام جملات موجود در مجموعه خود را تکرار می کنیم. جمله نشانه گذاری می شود و سپس بررسی می کنیم که آیا کلمه در جمله وجود دارد یا خیر، اگر کلمه وجود دارد، مقدار را افزایش می دهیم. doc_containing_word متغیر. در نهایت، برای محاسبه مقدار IDF، تعداد کل جملات را بر تعداد کل اسناد حاوی کلمه تقسیم می کنیم.
مرحله بعدی ایجاد فرهنگ لغت TF برای هر کلمه است. در فرهنگ لغت TF، کلید رایج ترین کلماتی است که استفاده می شود، در حالی که مقادیر 49 بردار بعدی خواهند بود زیرا سند ما دارای 49 جمله است. هر مقدار در بردار به مقدار TF کلمه برای جمله مربوطه تعلق دارد. به اسکریپت زیر نگاه کنید:
word_tf_values = {}
for token in most_freq:
sent_tf_vector = ()
for document in corpus:
doc_freq = 0
for word in nltk.word_tokenize(document):
if token == word:
doc_freq += 1
word_tf = doc_freq/len(nltk.word_tokenize(document))
sent_tf_vector.append(word_tf)
word_tf_values(token) = sent_tf_vector
در اسکریپت بالا، ما یک فرهنگ لغت ایجاد می کنیم که حاوی کلمه به عنوان کلید و لیستی از 49 مورد به عنوان مقدار است زیرا ما 49 جمله در مجموعه خود داریم. هر مورد در لیست مقدار TF کلمه را برای جمله مربوطه ذخیره می کند. در اسکریپت بالا word_tf_values فرهنگ لغت ماست برای هر کلمه، یک لیست ایجاد می کنیم sent_tf_vector.
سپس هر جمله را در پیکره تکرار می کنیم و جمله را نشانه گذاری می کنیم. کلمه از حلقه بیرونی با هر کلمه در جمله مطابقت دارد. اگر مطابقت پیدا شد doc_freq متغیر با 1 افزایش می یابد. هنگامی که همه کلمات در جمله تکرار می شوند، the doc_freq برای یافتن مقدار TF کلمه برای آن جمله بر طول کل جمله تقسیم می شود. این process برای همه کلمات موجود در لیست کلماتی که اغلب وجود دارند تکرار می شود. آخرین word_tf_values فرهنگ لغت شامل 200 کلمه به عنوان کلید خواهد بود. برای هر کلمه، لیستی از 49 مورد به عنوان مقدار وجود خواهد داشت.
اگر به word_tf_values دیکشنری، به نظر می رسد این است:

می توانید ببینید که word کلید است در حالی که لیستی از 49 مورد مقدار هر کلید است.
اکنون مقادیر IDF همه کلمات را به همراه مقادیر TF هر کلمه در جملات داریم. گام بعدی این است که به سادگی مقادیر IDF را با مقادیر TF ضرب کنید.
tfidf_values = ()
for token in word_tf_values.keys():
tfidf_sentences = ()
for tf_sentence in word_tf_values(token):
tf_idf_score = tf_sentence * word_idf_values(token)
tfidf_sentences.append(tf_idf_score)
tfidf_values.append(tfidf_sentences)
در اسکریپت بالا لیستی به نام ایجاد می کنیم tfidf_values. سپس تمام کلیدهای موجود در آن را تکرار کردیم word_tf_values فرهنگ لغت. این کلیدها اساساً رایج ترین کلمات هستند. با استفاده از این کلمات، لیست 49 بعدی را که حاوی مقادیر TF برای کلمه مربوط به هر جمله است، بازیابی می کنیم. در مرحله بعد، مقدار TF در مقدار IDF کلمه ضرب می شود و در آن ذخیره می شود tf_idf_score متغیر. سپس متغیر به ضمیمه می شود tf_idf_sentences فهرست در نهایت، tf_idf_sentences لیست به ضمیمه شده است tfidf_values فهرست
اکنون در این مقطع زمانی، tfidf_values لیستی از لیست ها است. جایی که هر مورد یک لیست 49 بعدی است که حاوی مقادیر TF IDF یک کلمه خاص برای همه جملات است. ما باید لیست دو بعدی را به یک آرایه numpy تبدیل کنیم. به اسکریپت زیر نگاه کنید:
tf_idf_model = np.asarray(tfidf_values)
اکنون، آرایه numpy ما به شکل زیر است:

با این حال، هنوز یک مشکل در این مدل TF-IDF وجود دارد. ابعاد آرایه 200 x 49 است، به این معنی که هر ستون نشان دهنده بردار TF-IDF برای جمله مربوطه است. ما سطرهایی را می خواهیم که بردارهای TF-IDF را نشان دهند. ما می توانیم این کار را به سادگی با جابجایی آرایه numpy به صورت زیر انجام دهیم:
tf_idf_model = np.transpose(tf_idf_model)
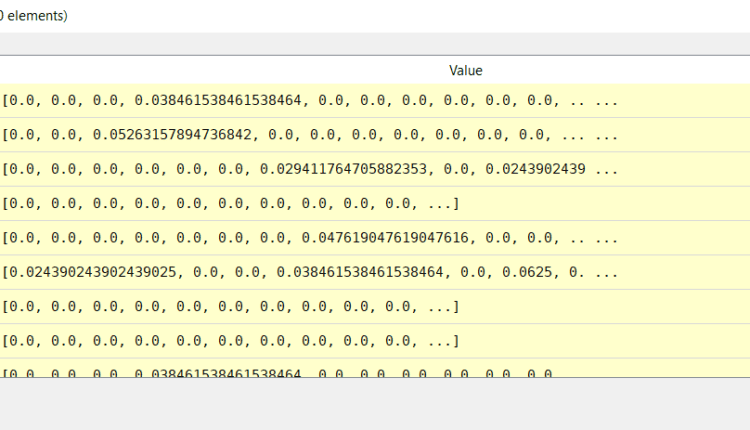
اکنون آرایهای 49×200 بعدی داریم که در آن ردیفها با بردارهای TF-IDF مطابقت دارند، همانطور که در زیر نشان داده شده است:

نتیجه
مدل TF-IDF یکی از پرکاربردترین مدل ها برای تبدیل متن به عدد است. در این مقاله، به طور خلاصه به بررسی تئوری مدل TF-IDF پرداختیم. در نهایت یک مدل TF-IDF را از ابتدا در پایتون پیاده سازی کردیم. در مقاله بعدی روش پیاده سازی مدل N-Gram را از ابتدا در پایتون خواهیم دید.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-21 17:41:05
