از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
این نوزدهمین مقاله از سری مقالات من است روی پایتون برای NLP. از چند مقاله اخیر، ما مفاهیم نسبتاً پیشرفته NLP را بررسی کرده ایم روی تکنیک های یادگیری عمیق در آخرین مقاله، روش ایجاد یک مدل طبقه بندی متن آموزش دیده با استفاده از ورودی های متعدد از انواع داده های مختلف را دیدیم. ما یک پیشبینیکننده احساسات متنی را با استفاده از ورودیهای متنی به اضافه اطلاعات متا ایجاد کردیم.
در این مقاله روش ایجاد یک مدل طبقه بندی متن با خروجی های متعدد را خواهیم دید. ما در حال توسعه یک مدل طبقه بندی متن خواهیم بود که یک نظر متنی را تجزیه و تحلیل می کند و چندین برچسب مرتبط با نظر را پیش بینی می کند. مسئله طبقه بندی چند برچسبی در واقع زیرمجموعه ای از مدل های خروجی چندگانه است. در پایان این مقاله شما قادر خواهید بود دسته بندی متن چند برچسبی را انجام دهید روی داده های شما
رویکرد توضیح داده شده در این مقاله را می توان برای انجام طبقه بندی کلی چند برچسبی گسترش داد. به عنوان مثال می توانید یک مشکل طبقه بندی را حل کنید که در آن یک تصویر به عنوان ورودی دارید و می خواهید دسته بندی تصویر و توضیحات تصویر را پیش بینی کنید.
در این مرحله، توضیح تفاوت بین یک مسئله طبقه بندی چند طبقه و یک طبقه بندی چند برچسب مهم است. در مسائل طبقهبندی چند کلاسه، یک نمونه یا یک رکورد میتواند به یک و تنها یکی از کلاسهای خروجی متعدد تعلق داشته باشد. به عنوان مثال، در مسئله تجزیه و تحلیل احساسات که در مقاله گذشته مطالعه کردیم، یک مرور متن می تواند “خوب”، “بد” یا “متوسط” باشد. نمی تواند در آن واحد هم «خوب» و هم «متوسط» باشد. از طرف دیگر در مسائل طبقه بندی چند برچسبی، یک نمونه می تواند همزمان چندین خروجی داشته باشد. به عنوان مثال، در مسئله طبقه بندی متن که در این مقاله می خواهیم حل کنیم، یک نظر می تواند چندین برچسب داشته باشد. این برچسب ها همزمان شامل «سمی»، «فحش»، «توهین آمیز» و … می باشد.
مجموعه داده
مجموعه داده شامل نظراتی از بحث ویکی پدیا page ویرایش ها شش برچسب خروجی برای هر نظر وجود دارد: سمی، شدید_سمی، ناپسند، تهدید، توهین و هویت_نفرت. یک نظر میتواند به همه این دستهها یا زیرمجموعهای از این دستهها تعلق داشته باشد که آن را به یک مشکل طبقهبندی چند برچسبی تبدیل میکند.
مجموعه داده های این مقاله را می توانید از اینجا دانلود کنید لینک کاگل. ما فقط استفاده خواهیم کرد train.csv فایلی که شامل 160000 رکورد می باشد.
فایل CSV را در فهرست محلی خود دانلود کنید. من فایل را به “toxic_comments.csv” تغییر نام داده ام. شما می توانید هر نامی به آن بدهید، اما فقط مطمئن شوید که از آن نام در کد خود استفاده کنید.
حالا بیایید import کتابخانه های مورد نیاز و بارگذاری مجموعه داده در برنامه ما. اسکریپت زیر کتابخانه های مورد نیاز را وارد می کند:
from numpy import array
from keras.preprocessing.text import one_hot
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers.core import Activation, Dropout, Dense
from keras.layers import Flatten, LSTM
from keras.layers import GlobalMaxPooling1D
from keras.models import Model
from keras.layers.embeddings import Embedding
from sklearn.model_selection import train_test_split
from keras.preprocessing.text import Tokenizer
from keras.layers import Input
from keras.layers.merge import Concatenate
import pandas as pd
import numpy as np
import re
import matplotlib.pyplot as plt
بیایید اکنون مجموعه داده را در حافظه بارگذاری کنیم:
toxic_comments = pd.read_csv("/content/drive/My Drive/Colab Datasets/toxic_comments.csv")
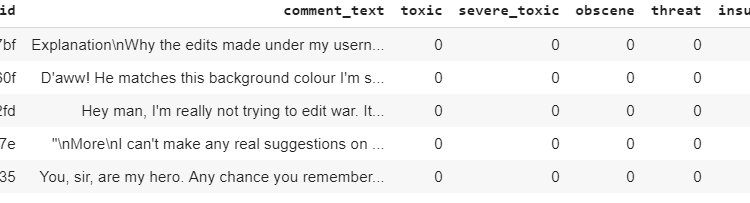
اسکریپت زیر شکل مجموعه داده را نمایش می دهد و همچنین هدر مجموعه داده را چاپ می کند:
print(toxic_comments.shape)
toxic_comments.head()
خروجی:
(159571,8)
مجموعه داده شامل 159571 رکورد و 8 ستون است. هدر مجموعه داده به شکل زیر است:

بیایید تمام رکوردهایی را که هر ردیف حاوی مقدار تهی یا رشته خالی است حذف کنیم.
filter = toxic_comments("comment_text") != ""
toxic_comments = toxic_comments(filter)
toxic_comments = toxic_comments.dropna()
این comment_text ستون حاوی نظرات متنی است. اجازه دهید print یک نظر تصادفی و سپس برچسب های نظرات را ببینید.
print(toxic_comments("comment_text")(168))
خروجی:
You should be fired, you're a moronic wimp who is too lazy to do research. It makes me sick that people like you exist in this world.
این به وضوح یک اظهار نظر سمی است. بیایید برچسب های مرتبط با این نظر را ببینیم:
print("Toxic:" + str(toxic_comments("toxic")(168)))
print("Severe_toxic:" + str(toxic_comments("severe_toxic")(168)))
print("Obscene:" + str(toxic_comments("obscene")(168)))
print("Threat:" + str(toxic_comments("threat")(168)))
print("Insult:" + str(toxic_comments("insult")(168)))
print("Identity_hate:" + str(toxic_comments("identity_hate")(168)))
خروجی:
Toxic:1
Severe_toxic:0
Obscene:0
Threat:0
Insult:1
Identity_hate:0
حالا بیایید تعداد نظرات را برای هر برچسب ترسیم کنیم. برای انجام این کار، ابتدا تمام برچسب ها یا ستون های خروجی را فیلتر می کنیم.
toxic_comments_labels = toxic_comments(("toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"))
toxic_comments_labels.head()
خروجی:

با استفاده از toxic_comments_labels چارچوب داده، نمودارهای نواری را رسم می کنیم که تعداد کل نظرات را برای برچسب های مختلف نشان می دهد.
fig_size = plt.rcParams("figure.figsize")
fig_size(0) = 10
fig_size(1) = 8
plt.rcParams("figure.figsize") = fig_size
toxic_comments_labels.sum(axis=0).plot.bar()
خروجی:

می بینید که کامنت «سمی» بیشترین فراوانی را دارد و به ترتیب «فحش» و «توهین» قرار دارند.
ما مجموعه داده های خود را با موفقیت تجزیه و تحلیل کرده ایم، در بخش بعدی مدل های طبقه بندی چند برچسبی را با استفاده از این مجموعه داده ایجاد خواهیم کرد.
ایجاد مدل های دسته بندی متن چند برچسبی
دو راه برای ایجاد مدلهای طبقهبندی چند برچسبی وجود دارد: استفاده از یک لایه خروجی متراکم و استفاده از چندین لایه خروجی متراکم.
در رویکرد اول، میتوانیم از یک لایه متراکم منفرد با شش خروجی با توابع فعالسازی سیگموئید و توابع از دست دادن آنتروپی متقاطع باینری استفاده کنیم. هر نورون در لایه متراکم خروجی یکی از شش برچسب خروجی را نشان خواهد داد. تابع فعال سازی سیگموئید مقداری بین 0 و 1 برای هر نورون برمی گرداند. اگر مقدار خروجی هر نورون بزرگتر از 0.5 باشد، فرض می شود که نظر متعلق به کلاسی است که توسط آن نورون خاص نشان داده شده است.
در رویکرد دوم ما یک لایه خروجی متراکم برای هر برچسب ایجاد می کنیم. مجموعاً 6 لایه متراکم در خروجی خواهیم داشت. هر لایه تابع سیگموئید خود را خواهد داشت.
مدل طبقهبندی متن چند برچسبی با لایه خروجی واحد
در این بخش یک مدل طبقه بندی متن چند برچسبی با یک لایه خروجی ایجاد می کنیم. مثل همیشه، اولین قدم در مدل طبقه بندی متن، ایجاد تابعی است که وظیفه پاکسازی متن را بر عهده دارد.
def preprocess_text(sen):
sentence = re.sub('(^a-zA-Z)', ' ', sen)
sentence = re.sub(r"\s+(a-zA-Z)\s+", ' ', sentence)
sentence = re.sub(r'\s+', ' ', sentence)
return sentence
در مرحله بعد مجموعه ورودی و خروجی خود را ایجاد می کنیم. ورودی نظر از comment_text ستون ما همه نظرات را پاک می کنیم و در آن ذخیره می کنیم X متغیر. برچسبها یا خروجیها قبلاً در آن ذخیره شدهاند toxic_comments_labels چارچوب داده ما از آن مقادیر dataframe برای ذخیره خروجی در y متغیر. به اسکریپت زیر نگاه کنید:
X = ()
sentences = list(toxic_comments("comment_text"))
for sen in sentences:
X.append(preprocess_text(sen))
y = toxic_comments_labels.values
در اینجا ما نیازی به انجام هیچ کدگذاری تک داغ نداریم زیرا برچسب های خروجی ما قبلاً به شکل بردارهای کدگذاری شده یک گرم هستند.
در مرحله بعد، داده های خود را به مجموعه های آموزشی و آزمایشی تقسیم می کنیم:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
باید ورودی های متن را به بردارهای جاسازی شده تبدیل کنیم. برای درک دقیق جاسازی کلمات، لطفاً به مقاله من مراجعه کنید روی جاسازی کلمات
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)
vocab_size = len(tokenizer.word_index) + 1
maxlen = 200
X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
ما از جاسازیهای کلمه GloVe برای تبدیل ورودیهای متن به همتایان عددی خود استفاده خواهیم کرد.
from numpy import array
from numpy import asarray
from numpy import zeros
embeddings_dictionary = dict()
glove_file = open('/content/drive/My Drive/Colab Datasets/glove.6B.100d.txt', encoding="utf8")
for line in glove_file:
records = line.split()
word = records(0)
vector_dimensions = asarray(records(1:), dtype='float32')
embeddings_dictionary(word) = vector_dimensions
glove_file.close()
embedding_matrix = zeros((vocab_size, 100))
for word, index in tokenizer.word_index.items():
embedding_vector = embeddings_dictionary.get(word)
if embedding_vector is not None:
embedding_matrix(index) = embedding_vector
اسکریپت زیر مدل را ایجاد می کند. مدل ما دارای یک لایه ورودی، یک لایه جاسازی، یک لایه LSTM با 128 نورون و یک لایه خروجی با 6 نورون خواهد بود زیرا ما 6 برچسب در خروجی داریم.
deep_inputs = Input(shape=(maxlen,))
embedding_layer = Embedding(vocab_size, 100, weights=(embedding_matrix), trainable=False)(deep_inputs)
LSTM_Layer_1 = LSTM(128)(embedding_layer)
dense_layer_1 = Dense(6, activation='sigmoid')(LSTM_Layer_1)
model = Model(inputs=deep_inputs, outputs=dense_layer_1)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=('acc'))
اجازه دهید print خلاصه مدل:
print(model.summary())
خروجی:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 200) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 200, 100) 14824300
_________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248
_________________________________________________________________
dense_1 (Dense) (None, 6) 774
=================================================================
Total params: 14,942,322
Trainable params: 118,022
Non-trainable params: 14,824,300
اسکریپت زیر معماری شبکه عصبی ما را چاپ می کند:
from keras.utils import plot_model
plot_model(model, to_file='model_plot4a.png', show_shapes=True, show_layer_names=True)
خروجی:

از شکل بالا می بینید که لایه خروجی فقط شامل 1 لایه متراکم با 6 نورون است. حال بیایید مدل خود را آموزش دهیم:
history = model.fit(X_train, y_train, batch_size=128, epochs=5, verbose=1, validation_split=0.2)
ما مدل خود را برای 5 دوره آموزش خواهیم داد. می توانید مدل را با دوره های بیشتری آموزش دهید و ببینید آیا نتایج بهتر یا بدتری دریافت می کنید.
نتیجه هر 5 دوره به شرح زیر است:
rain روی 102124 samples, validate روی 25532 samples
Epoch 1/5
102124/102124 (==============================) - 245s 2ms/step - loss: 0.1437 - acc: 0.9634 - val_loss: 0.1361 - val_acc: 0.9631
Epoch 2/5
102124/102124 (==============================) - 245s 2ms/step - loss: 0.0763 - acc: 0.9753 - val_loss: 0.0621 - val_acc: 0.9788
Epoch 3/5
102124/102124 (==============================) - 243s 2ms/step - loss: 0.0588 - acc: 0.9800 - val_loss: 0.0578 - val_acc: 0.9802
Epoch 4/5
102124/102124 (==============================) - 246s 2ms/step - loss: 0.0559 - acc: 0.9807 - val_loss: 0.0571 - val_acc: 0.9801
Epoch 5/5
102124/102124 (==============================) - 245s 2ms/step - loss: 0.0528 - acc: 0.9813 - val_loss: 0.0554 - val_acc: 0.9807
حال بیایید مدل خود را ارزیابی کنیم روی مجموعه تست:
score = model.evaluate(X_test, y_test, verbose=1)
print("Test Score:", score(0))
print("Test Accuracy:", score(1))
خروجی:
31915/31915 (==============================) - 108s 3ms/step
Test Score: 0.054090796736467786
Test Accuracy: 0.9810642735274182
مدل ما به دقت حدود 98 درصد دست می یابد که بسیار چشمگیر است.
در نهایت، مقادیر تلفات و دقت را برای مجموعه های آموزشی و آزمایشی ترسیم می کنیم تا ببینیم آیا مدل ما بیش از حد برازش دارد یا خیر.
import matplotlib.pyplot as plt
plt.plot(history.history('acc'))
plt.plot(history.history('val_acc'))
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(('train','test'), loc='upper left')
plt.show()
plt.plot(history.history('loss'))
plt.plot(history.history('val_loss'))
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(('train','test'), loc='upper left')
plt.show()
خروجی:

می بینید که مدل بیش از حد مناسب نیست روی مجموعه اعتبار سنجی
مدل طبقهبندی متن چند برچسبی با لایههای خروجی چندگانه
در این بخش یک مدل طبقه بندی متن چند برچسبی ایجاد می کنیم که در آن هر برچسب خروجی دارای یک لایه متراکم خروجی اختصاصی خواهد بود. اجازه دهید ابتدا عملکرد پیش پردازش خود را تعریف کنیم:
def preprocess_text(sen):
sentence = re.sub('(^a-zA-Z)', ' ', sen)
sentence = re.sub(r"\s+(a-zA-Z)\s+", ' ', sentence)
sentence = re.sub(r'\s+', ' ', sentence)
return sentence
مرحله دوم ایجاد ورودی و خروجی برای مدل است. ورودی مدل کامنت های متنی خواهد بود، در حالی که خروجی شش برچسب خواهد بود. اسکریپت زیر لایه ورودی و لایه خروجی ترکیبی را ایجاد می کند:
X = ()
sentences = list(toxic_comments("comment_text"))
for sen in sentences:
X.append(preprocess_text(sen))
y = toxic_comments(("toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"))
بیایید داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنیم:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
این y متغیر شامل خروجی ترکیبی از 6 برچسب است. با این حال، ما می خواهیم برای هر برچسب یک لایه خروجی جداگانه ایجاد کنیم. ما 6 متغیر ایجاد می کنیم که برچسب های فردی را از داده های آموزشی ذخیره می کند و 6 متغیر که مقادیر برچسب فردی را برای داده های تست ذخیره می کند.
به اسکریپت زیر نگاه کنید:
y1_train = y_train(("toxic")).values
y1_test = y_test(("toxic")).values
y2_train = y_train(("severe_toxic")).values
y2_test = y_test(("severe_toxic")).values
y3_train = y_train(("obscene")).values
y3_test = y_test(("obscene")).values
y4_train = y_train(("threat")).values
y4_test = y_test(("threat")).values
y5_train = y_train(("insult")).values
y5_test = y_test(("insult")).values
y6_train = y_train(("identity_hate")).values
y6_test = y_test(("identity_hate")).values
مرحله بعدی تبدیل ورودی های متنی به بردارهای جاسازی شده است. اسکریپت زیر این کار را انجام می دهد:
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)
vocab_size = len(tokenizer.word_index) + 1
maxlen = 200
X_train = pad_sequences(X_train, padding='post', maxlen=maxlen)
X_test = pad_sequences(X_test, padding='post', maxlen=maxlen)
در اینجا دوباره از تعبیههای کلمه GloVe استفاده خواهیم کرد:
glove_file = open('/content/drive/My Drive/Colab Datasets/glove.6B.100d.txt', encoding="utf8")
for line in glove_file:
records = line.split()
word = records(0)
vector_dimensions = asarray(records(1:), dtype='float32')
embeddings_dictionary(word) = vector_dimensions
glove_file.close()
embedding_matrix = zeros((vocab_size, 100))
for word, index in tokenizer.word_index.items():
embedding_vector = embeddings_dictionary.get(word)
if embedding_vector is not None:
embedding_matrix(index) = embedding_vector
اکنون زمان ایجاد مدل ما است. مدل ما یک لایه ورودی، یک لایه جاسازی و به دنبال آن یک لایه LSTM با 128 نورون خواهد داشت. خروجی لایه LSTM به عنوان ورودی 6 لایه خروجی متراکم استفاده خواهد شد. هر لایه خروجی دارای 1 نورون با عملکرد فعال سازی سیگموئید خواهد بود. هر خروجی مقدار صحیح بین 1 و 0 را برای برچسب مربوطه پیش بینی می کند.
اسکریپت زیر مدل ما را ایجاد می کند:
input_1 = Input(shape=(maxlen,))
embedding_layer = Embedding(vocab_size, 100, weights=(embedding_matrix), trainable=False)(input_1)
LSTM_Layer1 = LSTM(128)(embedding_layer)
output1 = Dense(1, activation='sigmoid')(LSTM_Layer1)
output2 = Dense(1, activation='sigmoid')(LSTM_Layer1)
output3 = Dense(1, activation='sigmoid')(LSTM_Layer1)
output4 = Dense(1, activation='sigmoid')(LSTM_Layer1)
output5 = Dense(1, activation='sigmoid')(LSTM_Layer1)
output6 = Dense(1, activation='sigmoid')(LSTM_Layer1)
model = Model(inputs=input_1, outputs=(output1, output2, output3, output4, output5, output6))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=('acc'))
اسکریپت زیر خلاصه ای از مدل را چاپ می کند:
print(model.summary())
خروجی:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 200) 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 200, 100) 14824300 input_1(0)(0)
__________________________________________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248 embedding_1(0)(0)
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 129 lstm_1(0)(0)
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 129 lstm_1(0)(0)
__________________________________________________________________________________________________
dense_3 (Dense) (None, 1) 129 lstm_1(0)(0)
__________________________________________________________________________________________________
dense_4 (Dense) (None, 1) 129 lstm_1(0)(0)
__________________________________________________________________________________________________
dense_5 (Dense) (None, 1) 129 lstm_1(0)(0)
__________________________________________________________________________________________________
dense_6 (Dense) (None, 1) 129 lstm_1(0)(0)
==================================================================================================
Total params: 14,942,322
Trainable params: 118,022
Non-trainable params: 14,824,300
و اسکریپت زیر معماری مدل ما را چاپ می کند:
from keras.utils import plot_model
plot_model(model, to_file='model_plot4b.png', show_shapes=True, show_layer_names=True)
خروجی:

می بینید که ما 6 لایه خروجی مختلف داریم. شکل بالا به وضوح تفاوت بین مدل با یک لایه ورودی که در قسمت آخر ایجاد کردیم و مدل با چندین لایه خروجی را توضیح می دهد.
حال بیایید مدل خود را آموزش دهیم:
history = model.fit(x=X_train, y=(y1_train, y2_train, y3_train, y4_train, y5_train, y6_train), batch_size=8192, epochs=5, verbose=1, validation_split=0.2)
من سعی کردم این مدل را برای پنج دوره اجرا کنم اما به طرز وحشتناکی بیش از حد مناسب بود روی مجموعه اعتبار سنجی من اندازه دسته را افزایش دادم اما هنوز دقت تست چندان خوب نبود. یکی از دلایل احتمالی بیش از حد برازش این است که در اینجا در این مورد ما یک لایه خروجی جداگانه برای هر برچسب داریم که پیچیدگی مدل ما را افزایش می دهد. افزایش پیچیدگی مدل اغلب منجر به بیش از حد برازش می شود.
نتیجه هر دوره در زیر نشان داده شده است:
خروجی:
Train روی 102124 samples, validate روی 25532 samples
Epoch 1/5
102124/102124 (==============================) - 24s 239us/step - loss: 3.5116 - dense_1_loss: 0.6017 - dense_2_loss: 0.5806 - dense_3_loss: 0.6150 - dense_4_loss: 0.5585 - dense_5_loss: 0.5828 - dense_6_loss: 0.5730 - dense_1_acc: 0.9029 - dense_2_acc: 0.9842 - dense_3_acc: 0.9444 - dense_4_acc: 0.9934 - dense_5_acc: 0.9508 - dense_6_acc: 0.9870 - val_loss: 1.0369 - val_dense_1_loss: 0.3290 - val_dense_2_loss: 0.0983 - val_dense_3_loss: 0.2571 - val_dense_4_loss: 0.0595 - val_dense_5_loss: 0.1972 - val_dense_6_loss: 0.0959 - val_dense_1_acc: 0.9037 - val_dense_2_acc: 0.9901 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9966 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9901
Epoch 2/5
102124/102124 (==============================) - 20s 197us/step - loss: 0.9084 - dense_1_loss: 0.3324 - dense_2_loss: 0.0679 - dense_3_loss: 0.2172 - dense_4_loss: 0.0338 - dense_5_loss: 0.1983 - dense_6_loss: 0.0589 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8616 - val_dense_1_loss: 0.3164 - val_dense_2_loss: 0.0555 - val_dense_3_loss: 0.2127 - val_dense_4_loss: 0.0235 - val_dense_5_loss: 0.1981 - val_dense_6_loss: 0.0554 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
Epoch 3/5
102124/102124 (==============================) - 20s 199us/step - loss: 0.8513 - dense_1_loss: 0.3179 - dense_2_loss: 0.0566 - dense_3_loss: 0.2103 - dense_4_loss: 0.0216 - dense_5_loss: 0.1960 - dense_6_loss: 0.0490 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8552 - val_dense_1_loss: 0.3158 - val_dense_2_loss: 0.0566 - val_dense_3_loss: 0.2074 - val_dense_4_loss: 0.0225 - val_dense_5_loss: 0.1960 - val_dense_6_loss: 0.0568 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
Epoch 4/5
102124/102124 (==============================) - 20s 198us/step - loss: 0.8442 - dense_1_loss: 0.3153 - dense_2_loss: 0.0570 - dense_3_loss: 0.2061 - dense_4_loss: 0.0213 - dense_5_loss: 0.1952 - dense_6_loss: 0.0493 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8527 - val_dense_1_loss: 0.3156 - val_dense_2_loss: 0.0558 - val_dense_3_loss: 0.2074 - val_dense_4_loss: 0.0226 - val_dense_5_loss: 0.1951 - val_dense_6_loss: 0.0561 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
Epoch 5/5
102124/102124 (==============================) - 20s 197us/step - loss: 0.8410 - dense_1_loss: 0.3146 - dense_2_loss: 0.0561 - dense_3_loss: 0.2055 - dense_4_loss: 0.0213 - dense_5_loss: 0.1948 - dense_6_loss: 0.0486 - dense_1_acc: 0.9043 - dense_2_acc: 0.9899 - dense_3_acc: 0.9474 - dense_4_acc: 0.9968 - dense_5_acc: 0.9510 - dense_6_acc: 0.9915 - val_loss: 0.8501 - val_dense_1_loss: 0.3153 - val_dense_2_loss: 0.0553 - val_dense_3_loss: 0.2069 - val_dense_4_loss: 0.0226 - val_dense_5_loss: 0.1948 - val_dense_6_loss: 0.0553 - val_dense_1_acc: 0.9038 - val_dense_2_acc: 0.9900 - val_dense_3_acc: 0.9469 - val_dense_4_acc: 0.9965 - val_dense_5_acc: 0.9509 - val_dense_6_acc: 0.9900
می بینید که برای هر دوره، ما مقادیری برای از دست دادن، از دست دادن ارزش، دقت و دقت ارزش برای تمام 6 لایه متراکم در خروجی داریم.
حال بیایید عملکرد مدل خود را ارزیابی کنیم روی مجموعه تست:
score = model.evaluate(x=X_test, y=(y1_test, y2_test, y3_test, y4_test, y5_test, y6_test), verbose=1)
print("Test Score:", score(0))
print("Test Accuracy:", score(1))
خروجی:
31915/31915 (==============================) - 111s 3ms/step
Test Score: 0.8471985269747015
Test Accuracy: 0.31425264998511726
دقت تنها 31 درصد به دست آمده است روی مجموعه تست از طریق چندین لایه خروجی.
اسکریپت زیر مقادیر از دست دادن و دقت را برای مجموعه های آموزشی و اعتبار سنجی برای اولین لایه متراکم ترسیم می کند.
import matplotlib.pyplot as plt
plt.plot(history.history('dense_1_acc'))
plt.plot(history.history('val_dense_1_acc'))
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(('train','test'), loc='upper left')
plt.show()
plt.plot(history.history('dense_1_loss'))
plt.plot(history.history('val_dense_1_loss'))
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(('train','test'), loc='upper left')
plt.show()
خروجی:

از خروجی می توانید ببینید که دقت مجموعه تست (اعتبارسنجی) بعد از اولین دوره ها همگرا نمی شود. همچنین، تفاوت بین دقت آموزش و اعتبارسنجی بسیار ناچیز است. بنابراین، مدل پس از دوره های اول شروع به اضافه کردن می کند و از این رو عملکرد ضعیفی داریم روی مجموعه تست های دیده نشده
نتیجه
طبقه بندی متن چند برچسبی یکی از رایج ترین مشکلات طبقه بندی متن است. در این مقاله، ما دو رویکرد یادگیری عمیق را برای طبقهبندی متن چند برچسبی مطالعه کردیم. در رویکرد اول ما از یک لایه خروجی متراکم با چندین نورون استفاده کردیم که در آن هر نورون یک برچسب را نشان میداد.
در رویکرد دوم، لایههای متراکم جداگانه برای هر برچسب با یک نورون ایجاد کردیم. نتایج نشان میدهد که در مورد ما، یک لایه خروجی منفرد با چند نورون بهتر از چندین لایه خروجی کار میکند.
به عنوان گام بعدی، من به شما توصیه می کنم که عملکرد فعال سازی و تقسیم تست قطار را تغییر دهید تا ببینید آیا می توانید نتایج بهتری نسبت به آنچه در این مقاله ارائه شده است بگیرید.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-20 18:47:03
