از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
این هفتمین مقاله از سری مقالات من است روی پایتون برای NLP. در مقاله قبلی ام روش انجام مدل سازی موضوع را با استفاده از آن توضیح دادم تخصیص دیریکله نهفته و فاکتورسازی ماتریس غیر منفی. ما از کتابخانه Scikit-Learn برای انجام مدلسازی موضوع استفاده کردیم.
در این مقاله به بررسی خواهیم پرداخت TextBlobکه یکی دیگر از کتابخانه های بسیار قدرتمند NLP برای پایتون است. TextBlob بر اساس NLTK ساخته شده است و یک رابط کاربری آسان برای کتابخانه NLTK فراهم می کند. خواهیم دید که چگونه میتوان از TextBlob برای انجام انواع وظایف NLP از برچسبگذاری بخشهای گفتار گرفته تا تجزیه و تحلیل احساسات و ترجمه زبان تا طبقهبندی متن استفاده کرد.
دستورالعمل های دانلود دقیق برای کتابخانه را می توانید در اینجا پیدا کنید لینک رسمی. من پیشنهاد می کنم که کتابخانه TextBlob و همچنین مجموعه نمونه را نصب کنید.
در اینجا خلاصه دستورالعمل های پیوند داده شده در بالا آمده است، اما برای دستورالعمل های بیشتر حتماً اسناد رسمی را بررسی کنید روی نصب در صورت نیاز:
$ pip install -U textblob
و برای نصب corpora:
$ python -m textblob.download_corpora
بیایید اکنون عملکردهای مختلف کتابخانه TextBlob را ببینیم.
توکن سازی
Tokenization به تقسیم یک پاراگراف بزرگ به جملات یا کلمات اشاره دارد. به طور معمول، یک نشانه به یک کلمه در یک سند متنی اشاره دارد. Tokenization با TextBlob بسیار ساده است. تنها کاری که باید انجام دهید این است import را TextBlob شی از textblob کتابخانه، سندی را که میخواهید توکنیزه کنید به آن منتقل کنید و سپس از آن استفاده کنید sentences و words ویژگی ها برای به دست آوردن جملات و ویژگی های نشانه گذاری شده. بیایید این را در عمل ببینیم:
اولین قدم این است که import را TextBlob هدف – شی:
from textblob import TextBlob
در مرحله بعد، باید رشته ای را تعریف کنید که حاوی متن سند باشد. رشته ای ایجاد می کنیم که شامل اولین پاراگراف مقاله ویکی پدیا است روی هوش مصنوعی
document = ("In computer science, artificial intelligence (AI), \
sometimes called machine intelligence, is intelligence \
demonstrated by machines, in contrast to the natural intelligence \
displayed by humans and animals. Computer science defines AI \
research as the study of \"intelligent agents\": any device that \
perceives its environment and takes actions that maximize its\
chance of successfully achieving its goals.(1) Colloquially,\
the term \"artificial intelligence\" is used to describe machines\
that mimic \"cognitive\" functions that humans associate with other\
human minds, such as \"learning\" and \"problem solving\".(2)")
مرحله بعدی این است که این سند را به عنوان یک پارامتر به TextBlob کلاس سپس شیء برگشتی می تواند برای تبدیل سند به کلمات و جملات استفاده شود.
text_blob_object = TextBlob(document)
حال برای بدست آوردن جملات نشانه گذاری شده، می توانیم از آن استفاده کنیم sentences صفت:
document_sentence = text_blob_object.sentences
print(document_sentence)
print(len(document_sentence))
در خروجی جملات توکن شده به همراه تعداد جملات را مشاهده خواهید کرد.
(Sentence("In computer science, artificial intelligence (AI), sometimes called machine intelligence, is intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans and animals."), Sentence("Computer science defines AI research as the study of "intelligent agents": any device that perceives its environment and takes actions that maximize its chance of successfully achieving its goals."), Sentence("(1) Colloquially, the term "artificial intelligence" is used to describe machines that mimic "cognitive" functions that humans associate with other human minds, such as "learning" and "problem solving"."), Sentence("(2)"))
4
به طور مشابه، words ویژگی کلمات نشانه گذاری شده در سند را برمی گرداند.
document_words = text_blob_object.words
print(document_words)
print(len(document_words))
خروجی به شکل زیر است:
('In', 'computer', 'science', 'artificial', 'intelligence', 'AI', 'sometimes', 'called', 'machine', 'intelligence', 'is', 'intelligence', 'demonstrated', 'by', 'machines', 'in', 'contrast', 'to', 'the', 'natural', 'intelligence', 'displayed', 'by', 'humans', 'and', 'animals', 'Computer', 'science', 'defines', 'AI', 'research', 'as', 'the', 'study', 'of', 'intelligent', 'agents', 'any', 'device', 'that', 'perceives', 'its', 'environment', 'and', 'takes', 'actions', 'that', 'maximize', 'its', 'chance', 'of', 'successfully', 'achieving', 'its', 'goals', '1', 'Colloquially', 'the', 'term', 'artificial', 'intelligence', 'is', 'used', 'to', 'describe', 'machines', 'that', 'mimic', 'cognitive', 'functions', 'that', 'humans', 'associate', 'with', 'other', 'human', 'minds', 'such', 'as', 'learning', 'and', 'problem', 'solving', '2')
84
Lemmatization
لماتیزه کردن به تقلیل کلمه به آن اشاره دارد root شکلی که در فرهنگ لغت یافت می شود.
برای انجام واژه سازی از طریق TextBlob، باید از آن استفاده کنید Word شی از textblob کتابخانه، کلمهای را که میخواهید کلمهسازی کنید به آن منتقل کنید و سپس آن را فراخوانی کنید lemmatize روش.
from textblob import Word
word1 = Word("apples")
print("apples:", word1.lemmatize())
word2 = Word("media")
print("media:", word2.lemmatize())
word3 = Word("greater")
print("greater:", word3.lemmatize("a"))
در اسکریپت بالا، ما لمت سازی را انجام می دهیم روی کلمات «سیب»، «رسانه» و «بزرگتر». در خروجی، کلمات “apple”، (که برای سیب مفرد است)، “متوسط” (که مفرد برای متوسط است) و “گروه” (که درجه مثبت کلمه greater است) را مشاهده خواهید کرد. توجه کنید که برای کلمه greater، “a” را به عنوان پارامتر به the پاس می کنیم lemmatize روش. این به طور خاص به روش می گوید که کلمه باید به عنوان یک صفت در نظر گرفته شود. به طور پیشفرض، کلمات به عنوان اسم در نظر گرفته میشوند lemmatize() روش. لیست کامل اجزای گفتار به شرح زیر است:
ADJ, ADJ_SAT, ADV, NOUN, VERB = 'a', 's', 'r', 'n', 'v'
برچسبگذاری بخشهای گفتار (POS).
مانند کتابخانههای spaCy و NLTK، کتابخانه TextBlob نیز دارای قابلیتهایی برای برچسبگذاری POS است.
برای یافتن تگ های POS برای کلمات یک سند، تنها کاری که باید انجام دهید این است که از آن استفاده کنید tags ویژگی مطابق شکل زیر:
for word, pos in text_blob_object.tags:
print(word + " => " + pos)
در اسکریپت بالا، print برچسب ها برای همه کلمات در پاراگراف اول مقاله ویکی پدیا روی هوش مصنوعی. خروجی اسکریپت بالا به شکل زیر است:
“` در => IN کامپیوتر => علم NN => NN مصنوعی => هوش JJ => NN AI => NNP گاهی اوقات => RB نامیده می شود => ماشین VBD => هوش NN => NN => هوش VBZ => NN نشان داد => VBN توسط => ماشین های IN => NNS در => در کنتراست => NN به => به => DT طبیعی => هوش JJ => NN نمایش داده شده => VBN توسط => در انسان => NNS و => حیوانات CC => کامپیوتر NNS => علم NNP => NN تعریف می کند => NNS AI => تحقیق NNP => NN به عنوان => IN the => DT مطالعه => NN of => IN intelligent => عوامل JJ => NNS هر => دستگاه DT => NN که => WDT درک می کند => VBZ آن => محیط PRP$ => NN و => CC => اقدامات VBZ => NNS که => IN حداکثر می کند => VB آن => PRP شانس $ => NN از => IN با موفقیت => RB دستیابی => VBG آن => PRP$ اهداف => NNS ( => RB 1 => CD ) => NNP در محاوره => NNP => اصطلاح DT => NN مصنوعی => هوش JJ => NN => VBZ استفاده می شود => VBN به => برای توصیف => ماشین های VB => NNS که => IN تقلید => JJ شناختی => توابع JJ => NNS که => انسان WDT = > ارتباط NNS => VBP با => IN دیگر => JJ انسان => JJ ذهن => NNS مانند => JJ به عنوان => IN یادگیری => VBG و => مشکل CC => حل NN => NN ( => RB 2 => CD ) => NNS “`
تگ های POS به صورت مخفف چاپ شده اند. برای مشاهده فرم کامل هر اختصار لطفاً مراجعه کنید این لینک.
تبدیل متن به مفرد و جمع
TextBlob همچنین به شما این امکان را می دهد که با استفاده از عبارت، متن را به صورت جمع یا مفرد تبدیل کنید pluralize و singularize روش ها، به ترتیب. به مثال زیر نگاه کنید:
text = ("Football is a good game. It has many health benefit")
text_blob_object = TextBlob(text)
print(text_blob_object.words.pluralize())
در خروجی، جمع همه کلمات را مشاهده خواهید کرد:
('Footballs', 'iss', 'some', 'goods', 'games', 'Its', 'hass', 'manies', 'healths', 'benefits')
به طور مشابه، برای منحصر به فرد کردن کلمات می توانید استفاده کنید singularize روش به شرح زیر است:
text = ("Footballs is a goods games. Its has many healths benefits")
text_blob_object = TextBlob(text)
print(text_blob_object.words.singularize())
خروجی اسکریپت بالا به شکل زیر است:
('Football', 'is', 'a', 'good', 'game', 'It', 'ha', 'many', 'health', 'benefit')
استخراج عبارت اسمی همانطور که از نام آن پیداست به استخراج عباراتی اطلاق می شود که حاوی اسم هستند. بیایید تمام عبارات اسمی را در پاراگراف اول مقاله ویکی پدیا پیدا کنیم روی هوش مصنوعی که قبلا استفاده کردیم.
برای یافتن عبارات اسمی، فقط باید از آن استفاده کنید noun_phrase ویژگی های روی را TextBlob هدف – شی. به مثال زیر نگاه کنید:
text_blob_object = TextBlob(document)
for noun_phrase in text_blob_object.noun_phrases:
print(noun_phrase)
خروجی به شکل زیر است:
computer science
artificial intelligence
ai
machine intelligence
natural intelligence
computer
science defines
ai
intelligent agents
colloquially
artificial intelligence
describe machines
human minds
شما می توانید تمام عبارات اسمی را در سند ما ببینید.
دریافت تعداد کلمات و عبارات
در بخش قبلی از برنامه داخلی پایتون استفاده کردیم len روشی برای شمارش تعداد جملات، کلمات و عبارات اسمی برگردانده شده توسط TextBlob هدف – شی. برای همین منظور می توانیم از متدهای داخلی TextBlob استفاده کنیم.
برای یافتن فراوانی وقوع یک کلمه خاص، باید نام کلمه را به عنوان شاخص به word_counts لیستی از TextBlob هدف – شی.
در مثال زیر، تعداد موارد کلمه “هوش” را در پاراگراف اول مقاله ویکی پدیا می شماریم. روی هوش مصنوعی.
text_blob_object = TextBlob(document)
text_blob_object.word_counts('intelligence')
راه دیگر این است که به سادگی تماس بگیرید count روش روی را words ویژگی، و نام کلمه ای را که فراوانی وقوع آن به شکل زیر یافت می شود، بفرستید:
text_blob_object.words.count('intelligence')
ذکر این نکته ضروری است که به طور پیش فرض جستجو به حروف کوچک و بزرگ حساس نیست. اگر میخواهید جستجوی شما به حروف بزرگ و کوچک حساس باشد، باید قبول کنید True به عنوان ارزش برای case_sensitive پارامتر، مطابق شکل زیر:
text_blob_object.words.count('intelligence', case_sensitive=True)
مانند شمارش کلمات، عبارات اسمی نیز می توانند به همین ترتیب شمارش شوند. مثال زیر عبارت “هوش مصنوعی” را در پاراگراف پیدا می کند.
text_blob_object = TextBlob(document)
text_blob_object.noun_phrases.count('artificial intelligence')
در خروجی 2 را مشاهده خواهید کرد.
تبدیل به حروف بزرگ و کوچک
اشیاء TextBlob بسیار شبیه به رشته ها هستند. می توانید آنها را به حروف بزرگ یا کوچک تبدیل کنید، مقادیر آنها را تغییر دهید و همچنین آنها را به هم متصل کنید. در اسکریپت زیر، متن را از شی TextBlob به حروف بزرگ تبدیل می کنیم:
text = "I love to watch football, but I have never played it"
text_blob_object = TextBlob(text)
print(text_blob_object.upper())
در خروجی، رشته را با حروف بزرگ نشان می دهید:
I LOVE TO WATCH FOOTBALL, BUT I HAVE NEVER PLAYED IT
به طور مشابه برای تبدیل متن به حروف کوچک، می توانیم از lower() روشی که در زیر نشان داده شده است:
text = "I LOVE TO WATCH FOOTBALL, BUT I HAVE NEVER PLAYED IT"
text_blob_object = TextBlob(text)
print(text_blob_object.lower())
یافتن N-Gram
N-Gram به n ترکیب کلمات در یک جمله اشاره دارد. به عنوان مثال، برای یک جمله “من عاشق تماشای فوتبال هستم”، مقدار 2 گرم می تواند (I love)، (عاشق تماشای) و (تماشای فوتبال) باشد. N-Gram ها می توانند نقش مهمی در طبقه بندی متن ایفا کنند.
در TextBlob، N-gram ها را می توان با ارسال تعداد N-Gram به آن پیدا کرد ngrams روش از TextBlob هدف – شی. به مثال زیر نگاه کنید:
text = "I love to watch football, but I have never played it"
text_blob_object = TextBlob(text)
for ngram in text_blob_object.ngrams(2):
print(ngram)
خروجی اسکریپت به شکل زیر است:
('I', 'love')
('love', 'to')
('to', 'watch')
('watch', 'football')
('football', 'but')
('but', 'I')
('I', 'have')
('have', 'never')
('never', 'played')
('played', 'it')
این به ویژه هنگام آموزش مدل های زبان یا انجام هر نوع پیش بینی متن مفید است.
اصلاحات املایی
تصحیح املا یکی از قابلیت های منحصر به فرد کتابخانه TextBlob است. با correct روش از TextBlob شی، می توانید تمام اشتباهات املایی متن خود را اصلاح کنید. به مثال زیر نگاه کنید:
text = "I love to watchf footbal, but I have neter played it"
text_blob_object = TextBlob(text)
print(text_blob_object.correct())
در فیلمنامه بالا سه اشتباه املایی داشتیم: “watchf” به جای “watch”، “footbal” به جای “football”، “neter” به جای “هرگز”. در خروجی مشاهده خواهید کرد که این اشتباهات توسط TextBlob تصحیح شده است، مانند شکل زیر:
I love to watch football, but I have never played it
ترجمه زبان
یکی از قدرتمندترین قابلیت های کتابخانه TextBlob ترجمه از یک زبان به زبان دیگر است. در باطن، مترجم زبان TextBlob از Google Translate API
برای ترجمه از یک زبان به زبان دیگر، فقط باید متن را به زبان دیگر منتقل کنید TextBlob شی و سپس با translate روش روی شی کد زبان برای زبانی که می خواهید متن شما به آن ترجمه شود به عنوان پارامتر به متد ارسال می شود. بیایید به یک مثال نگاه کنیم:
text_blob_object_french = TextBlob(u'Salut comment allez-vous?')
print(text_blob_object_french.translate(to='en'))
در اسکریپت بالا، ما یک جمله به زبان فرانسوی به the منتقل می کنیم TextBlob هدف – شی. بعد، ما را صدا می کنیم translate روش روی شی و کد زبان پاس en به to پارامتر. کد زبان en با زبان انگلیسی مطابقت دارد. در خروجی، ترجمه جمله فرانسوی را مطابق شکل زیر خواهید دید:
Hi, how are you?
بیایید مثال دیگری بزنیم که در آن از عربی به انگلیسی ترجمه می کنیم:
text_blob_object_arabic = TextBlob(u'مرحبا کیف حالک؟')
print(text_blob_object_arabic.translate(to='en'))
خروجی:
Hi, how are you?
در نهایت با استفاده از detect_language روش، شما همچنین می توانید زبان جمله را تشخیص دهید. به اسکریپت زیر نگاه کنید:
text_blob_object = TextBlob(u'Hola como estas?')
print(text_blob_object.detect_language())
در خروجی، خواهید دید esکه مخفف زبان اسپانیایی است.
کد زبان همه زبانها را میتوانید در اینجا پیدا کنید این لینک.
طبقه بندی متن
TextBlob همچنین قابلیت های پایه طبقه بندی متن را فراهم می کند. اگرچه، من TextBlob را به دلیل قابلیتهای محدود آن برای طبقهبندی متن توصیه نمیکنم، اما اگر دادههای واقعاً محدودی دارید و میخواهید به سرعت یک مدل طبقهبندی متن بسیار ابتدایی ایجاد کنید، میتوانید از TextBlob استفاده کنید. برای مدلهای پیشرفته، کتابخانههای یادگیری ماشینی مانند Scikit-Learn یا Tensorflow را توصیه میکنم.
بیایید ببینیم چگونه می توانیم طبقه بندی متن را با TextBlob انجام دهیم. اولین چیزی که ما نیاز داریم یک مجموعه داده آموزشی و داده های آزمایشی است. مدل طبقه بندی آموزش داده خواهد شد روی مجموعه داده آموزشی و ارزیابی خواهد شد روی مجموعه داده آزمایشی
فرض کنید داده های آموزشی و آزمایشی زیر را داریم:
train_data = (
('This is an excellent movie', 'pos'),
('The move was fantastic I like it', 'pos'),
('You should watch it, it is brilliant', 'pos'),
('Exceptionally good', 'pos'),
("Wonderfully directed and executed. I like it", 'pos'),
('It was very boring', 'neg'),
('I did not like the movie', 'neg'),
("The movie was horrible", 'neg'),
('I will not recommend', 'neg'),
('The acting is pathetic', 'neg')
)
test_data = (
('Its a fantastic series', 'pos'),
('Never watched such a brillent movie', 'pos'),
("horrible acting", 'neg'),
("It is a Wonderful movie", 'pos'),
('waste of money', 'neg'),
("pathetic picture", 'neg')
)
مجموعه داده حاوی برخی بررسی های ساختگی درباره فیلم ها است. می توانید ببینید مجموعه داده های آموزشی و آزمایشی ما شامل لیست هایی از تاپل ها است که در آن اولین عنصر تاپل متن یا یک جمله است در حالی که عضو دوم تاپل مرور یا احساس متن مربوطه است.
ما مجموعه داده خود را آموزش خواهیم داد روی را train_data و آن را ارزیابی خواهد کرد روی را test_data. برای انجام این کار، ما از NaiveBayesClassifier کلاس از textblob.classifiers کتابخانه اسکریپت زیر کتابخانه را وارد می کند:
from textblob.classifiers import NaiveBayesClassifier
برای آموزش مدل، به سادگی باید داده های آموزشی را به سازنده آن ارسال کنیم NaiveBayesClassifier کلاس کلاس یک شی آموزش دیده را برمی گرداند روی مجموعه داده و قادر به پیش بینی است روی مجموعه تست
classifier = NaiveBayesClassifier(train_data)
بیایید ابتدا یک پیش بینی کنیم روی یک جمله برای انجام این کار، باید با شماره تماس بگیرید classify روش و آن جمله را تصویب کنید. به مثال زیر نگاه کنید:
print(classifier.classify("It is very boring"))
به نظر یک بررسی منفی است. زمانی که اسکریپت بالا را اجرا کنید، خواهید دید neg در خروجی
به طور مشابه، اسکریپت زیر باز خواهد گشت pos از آنجایی که بررسی مثبت است
print(classifier.classify("It's a fantastic series"))
شما همچنین می توانید با عبور از ما یک پیش بینی انجام دهید classifier به classifier پارامتر از TextBlob هدف – شی. سپس شما باید با آن تماس بگیرید classify روش روی را TextBlob برای مشاهده پیش بینی شیء کنید.
sentence = TextBlob("It's a fantastic series.", classifier=classifier)
print(sentence.classify())
در نهایت، برای یافتن دقت الگوریتم خود روی مجموعه تست، تماس بگیرید accuracy روش روی طبقه بندی کننده شما و آن را پاس کنید test_data که ما به تازگی ایجاد کرده ایم. به اسکریپت زیر نگاه کنید:
classifier.accuracy(test_data)
در خروجی 0.66 را مشاهده می کنید که دقت الگوریتم است.
برای یافتن مهمترین ویژگی های طبقه بندی، show_informative_features روش می تواند استفاده شود. تعداد مهمترین ویژگیها برای دیدن بهعنوان پارامتر ارسال میشود.
classifier.show_informative_features(3)
خروجی به شکل زیر است:
Most Informative Features
contains(it) = False neg : pos = 2.2 : 1.0
contains(is) = True pos : neg = 1.7 : 1.0
contains(was) = True neg : pos = 1.7 : 1.0
در این بخش سعی شد با استفاده از طبقه بندی متن، احساس نقد فیلم را پیدا کنیم. در واقع، برای پیدا کردن احساس یک جمله در TextBlob، لازم نیست طبقه بندی متن را انجام دهید. کتابخانه TextBlob دارای یک تحلیلگر احساسات داخلی است که در بخش بعدی خواهیم دید.
تحلیل احساسات
در این بخش، احساسات نظرات عمومی را برای غذاهای مختلف خریداری شده از طریق آمازون تحلیل خواهیم کرد. برای این کار از تحلیلگر احساسات TextBlob استفاده خواهیم کرد.
مجموعه داده را می توان از دانلود کرد این لینک کاگل.
به عنوان اولین قدم، ما نیاز داریم import مجموعه داده ما فقط import 20000 رکورد اول به دلیل محدودیت حافظه. تو می توانی import رکوردهای بیشتر اگر بخواهید اسکریپت زیر مجموعه داده را وارد می کند:
import pandas as pd
import numpy as np
reviews_datasets = pd.read_csv(r'E:\Datasets\Reviews.csv')
reviews_datasets = reviews_datasets.head(20000)
reviews_datasets.dropna()
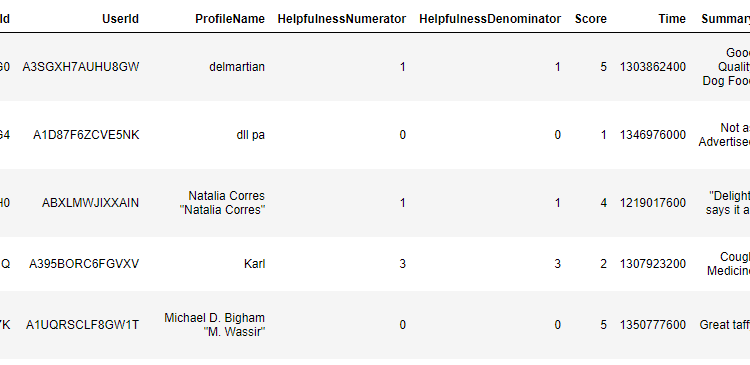
برای اینکه ببینیم مجموعه داده ما چگونه به نظر می رسد، از آن استفاده می کنیم head روش قاب داده پانداها:
reviews_datasets.head()
خروجی به شکل زیر است:

از خروجی مشاهده می کنید که بررسی متن در مورد غذا توسط ستون Text موجود است. ستون امتیاز شامل رتبه بندی های کاربر برای محصول خاص است که 1 کمترین و 5 بالاترین رتبه است.
بیایید توزیع امتیاز را ببینیم:
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.distplot(reviews_datasets('Score'))

می بینید که اکثر رتبه بندی ها بسیار مثبت هستند، یعنی 5. بیایید نمودار میله ای را برای رتبه بندی ها ترسیم کنیم تا به تعداد رکوردهای هر رتبه بندی بهتر نگاه کنیم.
sns.countplot(x='Score', data=reviews_datasets)

خروجی نشان می دهد که بیش از نیمی از نظرات دارای رتبه بندی 5 ستاره هستند.
بیایید به طور تصادفی یک بررسی را انتخاب کنیم و قطبیت آن را با استفاده از TextBlob پیدا کنیم. بیایید نگاهی به بررسی شماره 350 بیندازیم.
reviews_datasets('Text')(350)
خروجی:
'These chocolate covered espresso beans are wonderful! The chocolate is very dark and rich and the "bean" inside is a very delightful blend of flavors with just enough caffine to really give it a zing.'
به نظر می رسد که بررسی مثبت است. بیایید این را با استفاده از کتابخانه TextBlob تأیید کنیم. برای یافتن احساس، باید از آن استفاده کنیم sentiment ویژگی از TextBlog هدف – شی. این sentiment شی یک تاپلی را برمی گرداند که حاوی قطبیت و ذهنیت بررسی است.
مقدار قطبیت می تواند بین -1 و 1 باشد که در آن نظرات با قطبیت منفی احساسات منفی دارند در حالی که نظرات با قطبیت مثبت احساسات مثبت دارند.
مقدار ذهنیت می تواند بین 0 تا 1 باشد. ذهنیت میزان نظرات شخصی و اطلاعات واقعی موجود در متن را کمیت می کند. ذهنیت بالاتر به این معنی است که متن به جای اطلاعات واقعی، حاوی نظرات شخصی است.
بیایید احساس سیصد و پنجاهمین بررسی را پیدا کنیم.
text_blob_object = TextBlob(reviews_datasets('Text')(350))
print(text_blob_object.sentiment)
خروجی به شکل زیر است:
Sentiment(polarity=0.39666666666666667,subjectivity=0.6616666666666667)
خروجی نشان می دهد که بررسی مثبت با ذهنیت بالا است.
بیایید اکنون یک ستون برای قطبیت احساسات در مجموعه داده خود اضافه کنیم. اسکریپت زیر را اجرا کنید:
def find_pol(review):
return TextBlob(review).sentiment.polarity
reviews_datasets('Sentiment_Polarity') = reviews_datasets('Text').apply(find_pol)
reviews_datasets.head()
حالا بیایید توزیع قطبیت را در مجموعه داده خود ببینیم. اسکریپت زیر را اجرا کنید:
sns.distplot(reviews_datasets('Sentiment_Polarity'))
خروجی اسکریپت بالا به شکل زیر است:

از شکل بالا مشخص است که اکثر بررسی ها مثبت هستند و دارای قطبیت بین 0 تا 0.5 هستند. این طبیعی است زیرا اکثر نظرات در مجموعه داده دارای رتبه بندی 5 ستاره هستند.
بیایید اکنون قطبیت متوسط را برای هر امتیاز امتیاز ترسیم کنیم.
sns.barplot(x='Score', y='Sentiment_Polarity', data=reviews_datasets)
خروجی:

خروجی به وضوح نشان میدهد که بررسیهایی که امتیازهای رتبهبندی بالایی دارند، قطبهای مثبت بالایی دارند.
بیایید اکنون برخی از منفی ترین نقدها را ببینیم، یعنی بررسی هایی با مقدار قطبیت -1.
most_negative = reviews_datasets(reviews_datasets.Sentiment_Polarity == -1).Text.head()
print(most_negative)
خروجی به شکل زیر است:
545 These chips are nasty. I thought someone had ...
1083 All my fault. I thought this would be a carton...
1832 Pop Chips are basically a horribly over-priced...
2087 I do not consider Gingerbread, Spicy Eggnog, C...
2763 This popcorn has alot of hulls I order 4 bags ...
Name: Text, dtype: object
اجازه دهید print ارزش بررسی شماره 545.
reviews_datasets('Text')(545)
در خروجی، بررسی زیر را مشاهده خواهید کرد:
'These chips are nasty. I thought someone had spilled a drink in the bag, no the chips were just soaked with grease. Nasty!!'
خروجی به وضوح نشان می دهد که بررسی بسیار منفی است.
بیایید اکنون برخی از مثبت ترین نظرات را ببینیم. اسکریپت زیر را اجرا کنید:
most_positive = reviews_datasets(reviews_datasets.Sentiment_Polarity == 1).Text.head()
print(most_positive)
خروجی به شکل زیر است:
106 not what I was expecting in terms of the compa...
223 This is an excellent tea. One of the best I h...
338 I like a lot of sesame oil and use it in salad...
796 My mother and father were the recipient of the...
1031 The Kelloggs Muselix are delicious and the del...
Name: Text, dtype: object
بیایید بررسی 106 را با جزئیات ببینیم:
reviews_datasets('Text')(106)
خروجی:
"not what I was expecting in terms of the company's reputation for excellent home delivery products"
می بینید که اگرچه بررسی خیلی مثبت نبود، اما به دلیل وجود کلماتی مانند قطبیت 1 به آن اختصاص داده شده است. excellent و reputation. مهم است بدانید که تحلیلگر احساسات 100% ضد خطا نیست و ممکن است در موارد معدودی احساس اشتباه را پیشبینی کند، مانند چیزی که اخیراً دیدیم.
بیایید اکنون بررسی شماره 223 را ببینیم که همچنین به عنوان مثبت علامت گذاری شده است.
reviews_datasets('Text')(223)
خروجی به شکل زیر است:
"This is an excellent tea. One of the best I have ever had. It is especially great when you prepare it with a samovar."
خروجی به وضوح نشان می دهد که بررسی بسیار مثبت است.
نتیجه
کتابخانه TextBlob پایتون یکی از معروف ترین و پرکاربردترین کتابخانه های پردازش زبان طبیعی است. این مقاله چندین کارکرد کتابخانه TextBlob مانند نشانهسازی، ریشهیابی، تحلیل احساسات، طبقهبندی متن و ترجمه زبان را به تفصیل توضیح میدهد.
در مقاله بعدی به کتابخانه Pattern می پردازم که توابع بسیار مفیدی را برای تعیین ویژگی های جملات و همچنین ابزارهایی برای بازیابی داده ها از شبکه های اجتماعی، ویکی پدیا و موتورهای جستجو ارائه می دهد.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-23 15:58:05
