از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این بیستمین مقاله از سری مقالات من است روی پایتون برای NLP. در چند مقاله اخیر، تکنیک های یادگیری عمیق را برای انجام انواع وظایف یادگیری ماشین بررسی کرده ایم و همچنین باید با مفهوم جاسازی کلمات آشنا باشید. جاسازی کلمه راهی برای تبدیل اطلاعات متنی به شکل عددی است که به نوبه خود می تواند به عنوان ورودی به الگوریتم های آماری استفاده شود. در مقاله من روی جاسازی کلمه، من توضیح دادم که چگونه می توانیم جاسازی های کلمه خود را ایجاد کنیم و چگونه می توانیم از جاسازی های کلمه داخلی مانند دستکش.
در این مقاله قصد داریم به مطالعه بپردازیم FastText که یکی دیگر از ماژول های بسیار مفید برای جاسازی کلمات و طبقه بندی متن است. FastText توسط فیس بوک توسعه داده شده است و نتایج بسیار خوبی از خود نشان داده است روی بسیاری از مشکلات NLP، مانند تشخیص شباهت معنایی و طبقه بندی متن.
در این مقاله به طور خلاصه به بررسی کتابخانه FastText می پردازیم. این مقاله به دو بخش تقسیم شده است. در بخش اول، خواهیم دید که چگونه کتابخانه FastText نمایش های برداری ایجاد می کند که می تواند برای یافتن شباهت های معنایی بین کلمات استفاده شود. در بخش دوم کاربرد کتابخانه FastText برای طبقه بندی متون را مشاهده خواهیم کرد.
FastText برای تشابه معنایی
FastText از هر دو پشتیبانی می کند کیسه کلمات پیوسته و مدل های Skip-Gram. در این مقاله مدل skip-gram را برای یادگیری نمایش برداری کلمات از مقالات ویکی پدیا پیاده سازی می کنیم. روی هوش مصنوعی، فراگیری ماشین، یادگیری عمیق، و شبکه های عصبی. از آنجایی که این موضوعات کاملا مشابه هستند، ما این موضوعات را برای داشتن حجم قابل توجهی از داده ها برای ایجاد یک مجموعه انتخاب کردیم. در صورت تمایل می توانید موضوعات بیشتری با ماهیت مشابه اضافه کنید.
به عنوان اولین قدم، ما نیاز داریم import کتابخانه های مورد نیاز ما از کتابخانه ویکیپدیا برای پایتون استفاده خواهیم کرد که از طریق دستور زیر قابل دانلود است:
$ pip install wikipedia
واردات کتابخانه ها
اسکریپت زیر کتابخانه های مورد نیاز را به برنامه ما وارد می کند:
from keras.preprocessing.text import Tokenizer
from gensim.models.fasttext import FastText
import numpy as np
import matplotlib.pyplot as plt
import nltk
from string import punctuation
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
import wikipedia
import nltk
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('stopwords')
en_stop = set(nltk.corpus.stopwords.words('english'))
%matplotlib inline
می بینید که ما از آن استفاده می کنیم FastText ماژول از gensim.models.fasttext کتابخانه برای بازنمایی کلمه و شباهت معنایی، میتوان از مدل Gensim برای FastText استفاده کرد. این مدل می تواند اجرا شود روی ویندوز، با این حال، برای طبقه بندی متن، ما باید از پلت فرم لینوکس استفاده کنیم. آن را در بخش بعدی خواهیم دید.
خراش دادن مقالات ویکی پدیا
در این مرحله، مقالات مورد نیاز ویکیپدیا را پاک میکنیم. به اسکریپت زیر نگاه کنید:
artificial_intelligence = wikipedia.page("Artificial Intelligence").content
machine_learning = wikipedia.page("Machine Learning").content
deep_learning = wikipedia.page("Deep Learning").content
neural_network = wikipedia.page("Neural Network").content
artificial_intelligence = sent_tokenize(artificial_intelligence)
machine_learning = sent_tokenize(machine_learning)
deep_learning = sent_tokenize(deep_learning)
neural_network = sent_tokenize(neural_network)
artificial_intelligence.extend(machine_learning)
artificial_intelligence.extend(deep_learning)
artificial_intelligence.extend(neural_network)
برای خراشیدن ویکی پدیا page، می توانیم استفاده کنیم page روش از wikipedia مدول. نام page که می خواهید ضایع کنید به عنوان پارامتر به آن ارسال می شود page روش. روش برمی گردد WikipediaPage شی، که سپس می توانید از آن برای بازیابی استفاده کنید page مطالب از طریق content ویژگی، همانطور که در اسکریپت بالا نشان داده شده است.
سپس محتوای خراشیده شده از چهار صفحه ویکیپدیا با استفاده از آن به جملات تبدیل میشود sent_tokenize روش. را sent_tokenize متد لیست جملات را برمی گرداند. جملات چهار صفحه به طور جداگانه نشانه گذاری می شوند. در نهایت، جملات از چهار مقاله از طریق extend روش.
پیش پردازش داده ها
گام بعدی این است که داده های متنی خود را با حذف علائم نگارشی و اعداد پاک کنیم. همچنین داده ها را به حروف کوچک تبدیل می کنیم. کلمات موجود در دادههای ما به آنها تبدیل خواهند شد root فرم. همچنین کلمات توقف و کلمات با طول کمتر از 4 از مجموعه حذف می شوند.
را preprocess_text تابع، همانطور که در زیر تعریف شده است، وظایف پیش پردازش را انجام می دهد.
import re
from nltk.stem import WordNetLemmatizer
stemmer = WordNetLemmatizer()
def preprocess_text(document):
document = re.sub(r'\W', ' ', str(document))
document = re.sub(r'\s+(a-zA-Z)\s+', ' ', document)
document = re.sub(r'\^(a-zA-Z)\s+', ' ', document)
document = re.sub(r'\s+', ' ', document, flags=re.I)
document = re.sub(r'^b\s+', '', document)
document = document.lower()
tokens = document.split()
tokens = (stemmer.lemmatize(word) for word in tokens)
tokens = (word for word in tokens if word not in en_stop)
tokens = (word for word in tokens if len(word) > 3)
preprocessed_text = ' '.join(tokens)
return preprocessed_text
بیایید ببینیم که آیا تابع ما با پیش پردازش یک جمله ساختگی وظیفه مورد نظر را انجام می دهد:
sent = preprocess_text("Artificial intelligence, is the most advanced technology of the present era")
print(sent)
final_corpus = (preprocess_text(sentence) for sentence in artificial_intelligence if sentence.strip() !='')
word_punctuation_tokenizer = nltk.WordPunctTokenizer()
word_tokenized_corpus = (word_punctuation_tokenizer.tokenize(sent) for sent in final_corpus)
جمله از پیش پردازش شده به این صورت است:
artificial intelligence advanced technology present
میتوانید ببینید که علائم نگارشی و توقف کلمات حذف شدهاند و جملات به صورت کلمهنویسی شدهاند. همچنین کلمات با طول کمتر از 4 مانند “عصر” نیز حذف شده است. این انتخابها بهطور تصادفی برای این آزمون انتخاب شدهاند، بنابراین میتوانید کلماتی با طولهای کوچکتر یا بزرگتر را در مجموعه مجاز کنید.
ایجاد بازنمایی کلمات
ما مجموعه خود را از قبل پردازش کرده ایم. اکنون زمان ایجاد نمایش کلمات با استفاده از FastText است. بیایید ابتدا پارامترهای فوق را برای مدل FastText خود تعریف کنیم:
embedding_size = 60
window_size = 40
min_word = 5
down_sampling = 1e-2
اینجا embedding_size اندازه بردار جاسازی است. به عبارت دیگر، هر کلمه در پیکره ما به عنوان یک بردار 60 بعدی نشان داده می شود. را window_size اندازه تعداد کلماتی است که قبل و بعد از کلمه بر اساس وجود دارد روی که بازنمودهای کلمه برای کلمه یاد خواهد گرفت. این ممکن است مشکل به نظر برسد، با این حال در مدل skip-gram یک کلمه را به الگوریتم وارد میکنیم و خروجی کلمات متن است. اگر اندازه پنجره 40 باشد، برای هر ورودی 80 خروجی وجود دارد: 40 کلمه قبل از کلمه ورودی و 40 کلمه بعد از کلمه ورودی. واژه embeddings برای کلمه ورودی با استفاده از این 80 کلمه خروجی آموخته می شود.
هایپرپارامتر بعدی عبارت است از min_word، که حداقل فرکانس یک کلمه را در مجموعه ای که نمایش های کلمه برای آن تولید می شود را مشخص می کند. در نهایت، کلمه ای که بیشترین تکرار را دارد با عددی که توسط کلمه مشخص شده است، نمونه برداری می شود down_sampling صفت.
بیایید اکنون خود را ایجاد کنیم FastText مدلی برای بازنمایی کلمات
%%time
ft_model = FastText(word_tokenized_corpus,
size=embedding_size,
window=window_size,
min_count=min_word,
sample=down_sampling,
sg=1,
iter=100)
تمام پارامترهای موجود در اسکریپت بالا به جز sg. را sg پارامتر نوع مدلی را که می خواهیم ایجاد کنیم را مشخص می کند. مقدار 1 مشخص می کند که می خواهیم مدل skip-gram ایجاد کنیم. در حالی که صفر مدل کیسه کلمات را مشخص می کند که مقدار پیش فرض نیز می باشد.
اسکریپت بالا را اجرا کنید ممکن است مدتی طول بکشد تا اجرا شود. در دستگاه من آمار زمان اجرای کد بالا به شرح زیر است:
CPU times: user 1min 45s, sys: 434 ms, total: 1min 45s
Wall time: 57.2 s
بیایید اکنون کلمه نمایندگی برای کلمه “مصنوعی” را ببینیم. برای این کار می توانید از wv روش از FastText شیء کنید و نام کلمه را در یک لیست ارسال کنید.
print(ft_model.wv('artificial'))
در اینجا خروجی است:
(-3.7653010e-02 -4.5558015e-01 3.2035065e-01 -1.5289043e-01
4.0645871e-02 -1.8946664e-01 7.0426887e-01 2.8806925e-01
-1.8166199e-01 1.7566417e-01 1.1522485e-01 -3.6525184e-01
-6.4378887e-01 -1.6650060e-01 7.4625671e-01 -4.8166099e-01
2.0884991e-01 1.8067230e-01 -6.2647951e-01 2.7614883e-01
-3.6478557e-02 1.4782918e-02 -3.3124462e-01 1.9372456e-01
4.3028224e-02 -8.2326338e-02 1.0356739e-01 4.0792203e-01
-2.0596240e-02 -3.5974573e-02 9.9928051e-02 1.7191900e-01
-2.1196717e-01 6.4424530e-02 -4.4705093e-02 9.7391091e-02
-2.8846195e-01 8.8607501e-03 1.6514034e-01 -3.6626378e-01
-6.2017748e-04 -1.5083785e-01 -1.7499258e-01 7.1994811e-02
-1.9868813e-01 -3.1733567e-01 1.9832127e-01 1.2799081e-01
-7.6522082e-01 5.2335665e-02 -4.5766738e-01 -2.7947658e-01
3.7890410e-03 -3.8761377e-01 -9.3001537e-02 -1.7128626e-01
-1.2923178e-01 3.9627206e-01 -3.6673656e-01 2.2755004e-01)
در خروجی بالا می توانید یک وکتور 60 بعدی برای کلمه “مصنوعی” مشاهده کنید.
بیایید اکنون 5 کلمه مشابه را برای کلمات “مصنوعی”، “هوش”، “ماشین”، “شبکه”، “تکرار کننده”، “عمیق” پیدا کنیم. شما می توانید هر تعداد کلمه را انتخاب کنید. اسکریپت زیر کلمات مشخص شده را به همراه 5 کلمه مشابه چاپ می کند.
semantically_similar_words = {words: (item(0) for item in ft_model.wv.most_similar((words), topn=5))
for words in ('artificial', 'intelligence', 'machine', 'network', 'recurrent', 'deep')}
for k,v in semantically_similar_words.items():
print(k+":"+str(v))
خروجی به صورت زیر است:
artificial:('intelligence', 'inspired', 'book', 'academic', 'biological')
intelligence:('artificial', 'human', 'people', 'intelligent', 'general')
machine:('ethic', 'learning', 'concerned', 'argument', 'intelligence')
network:('neural', 'forward', 'deep', 'backpropagation', 'hidden')
recurrent:('rnns', 'short', 'schmidhuber', 'shown', 'feedforward')
deep:('convolutional', 'speech', 'network', 'generative', 'neural')
ما همچنین می توانیم شباهت کسینوس بین بردارها را برای هر دو کلمه پیدا کنیم، همانطور که در زیر نشان داده شده است:
print(ft_model.wv.similarity(w1='artificial', w2='intelligence'))
خروجی مقدار “0.7481” را نشان می دهد. مقدار می تواند بین 0 و 1 باشد. مقدار بالاتر به معنای شباهت بیشتر است.
تجسم شباهت های کلمه
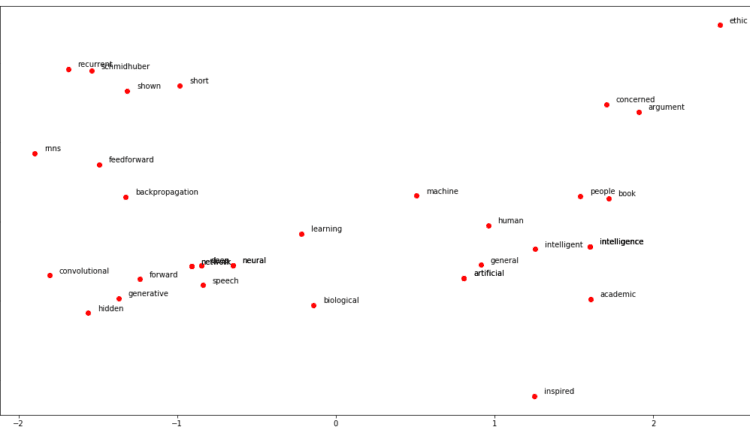
اگرچه هر کلمه در مدل ما به عنوان بردار 60 بعدی نشان داده می شود، می توانیم از تکنیک تحلیل مولفه اصلی برای یافتن دو جزء اصلی استفاده کنیم. سپس می توان از دو جزء اصلی برای ترسیم کلمات در یک فضای دو بعدی استفاده کرد. با این حال، ابتدا باید لیستی از تمام کلمات موجود در آن ایجاد کنیم semantically_similar_words فرهنگ لغت. اسکریپت زیر این کار را انجام می دهد:
from sklearn.decomposition import PCA
all_similar_words = sum(((k) + v for k, v in semantically_similar_words.items()), ())
print(all_similar_words)
print(type(all_similar_words))
print(len(all_similar_words))
در اسکریپت بالا، تمام جفتهای کلید-مقدار در را تکرار میکنیم semantically_similar_words فرهنگ لغت. هر کلید در فرهنگ لغت یک کلمه است. مقدار مربوطه فهرستی از تمام کلمات مشابه معنایی است. از آنجایی که ما 5 کلمه مشابه را برای لیستی از 6 کلمه پیدا کردیم، یعنی «مصنوعی»، «هوش»، «ماشین»، «شبکه»، «تکرارکننده»، «عمیق»، خواهید دید که 30 مورد در این فهرست وجود خواهد داشت. را all_similar_words فهرست
در مرحله بعد، ما باید کلمه بردار را برای تمام این 30 کلمه پیدا کنیم و سپس از PCA برای کاهش ابعاد بردارهای کلمه از 60 به 2 استفاده کنیم. سپس می توانیم از plt متد، که نام مستعار the matplotlib.pyplot روش رسم کلمات روی یک فضای برداری دو بعدی
اسکریپت زیر را برای تجسم کلمات اجرا کنید:
word_vectors = ft_model.wv(all_similar_words)
pca = PCA(n_components=2)
p_comps = pca.fit_transform(word_vectors)
word_names = all_similar_words
plt.figure(figsize=(18, 10))
plt.scatter(p_comps(:, 0), p_comps(:, 1), c='red')
for word_names, x, y in zip(word_names, p_comps(:, 0), p_comps(:, 1)):
plt.annotate(word_names, xy=(x+0.06, y+0.03), xytext=(0, 0), textcoords='offset points')
خروجی اسکریپت بالا به شکل زیر است:

در صفحه دوبعدی نیز میتوانید کلماتی را که اغلب با هم در متن اتفاق میافتند، نزدیک به هم ببینید. به عنوان مثال، کلمات “عمیق” و “شبکه” تقریباً همپوشانی دارند. به همین ترتیب، کلمات “فید فوروارد” و “پس انتشار” نیز بسیار نزدیک هستند.
اکنون می دانیم که چگونه با استفاده از FastText جاسازی های کلمه ایجاد کنیم. در بخش بعدی خواهیم دید که چگونه می توان از FastText برای کارهای طبقه بندی متن استفاده کرد.
FastText برای طبقه بندی متن
طبقه بندی متن به طبقه بندی داده های متنی به دسته های از پیش تعریف شده بر اساس اشاره دارد روی محتویات متن تجزیه و تحلیل احساسات، تشخیص هرزنامه، و تشخیص برچسب برخی از رایج ترین نمونه های موارد استفاده برای طبقه بندی متن هستند.
ماژول طبقه بندی متن FastText فقط از طریق لینوکس یا OSX قابل اجرا است. اگر کاربر ویندوز هستید، می توانید استفاده کنید Google Collaboratory برای اجرای ماژول طبقه بندی متن FastText. تمام اسکریپت های این بخش با استفاده از Google Colaboratory اجرا شده اند.
مجموعه داده
مجموعه داده های این مقاله را می توانید از اینجا دانلود کنید لینک کاگل. مجموعه داده شامل چندین فایل است، اما ما فقط به آن علاقه داریم yelp_review.csv فایل. این فایل حاوی بیش از 5.2 میلیون بررسی در مورد مشاغل مختلف از جمله رستوران ها، کافه ها، دندانپزشکان، پزشکان، سالن های زیبایی و غیره است. با این حال، به دلیل محدودیت های حافظه، ما فقط از 50000 رکورد اول برای آموزش مدل خود استفاده خواهیم کرد. در صورت تمایل می توانید با رکوردهای بیشتری امتحان کنید.
اجازه دهید import کتابخانه های مورد نیاز و بارگذاری مجموعه داده:
import pandas as pd
import numpy as np
yelp_reviews = pd.read_csv("/content/drive/My Drive/Colab Datasets/yelp_review_short.csv")
bins = (0,2,5)
review_names = ('negative', 'positive')
yelp_reviews('reviews_score') = pd.cut(yelp_reviews('stars'), bins, labels=review_names)
yelp_reviews.head()
در اسکریپت بالا ما بارگذاری می کنیم yelp_review_short.csv فایلی که شامل 50000 بررسی با pd.read_csv تابع.
ما مشکل خود را با تبدیل مقادیر عددی بررسی ها به مقوله ای ساده می کنیم. این کار با اضافه کردن یک ستون جدید انجام می شود،reviews_score، به مجموعه داده ما. اگر نظر کاربر دارای مقداری بین 1-2 باشد Stars ستون (که کسب و کار را رتبه بندی می کند روی مقیاس 1-5)، reviews_score ستون یک مقدار رشته ای خواهد داشت negative. اگر امتیاز بین 3-5 در Stars ستون، reviews_score ستون حاوی یک مقدار خواهد بود positive. این باعث می شود مشکل ما یک مشکل طبقه بندی باینری باشد.
در نهایت هدر دیتافریم مطابق شکل زیر چاپ می شود:

نصب FastText
مرحله بعدی این است که import مدل های FastText، که می توانند با استفاده از wget دستور از مخزن GitHub، همانطور که در اسکریپت زیر نشان داده شده است:
!wget https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
توجه داشته باشید: اگر دستور بالا را از لینوکس اجرا می کنید terminal، لازم نیست پیشوند بزنید ! قبل از دستور بالا در Google Colaboratory notebook، هر دستوری بعد از ! به عنوان یک فرمان پوسته و نه در مفسر پایتون اجرا می شود. بنابراین تمام دستورات غیر پایتون در اینجا با پیشوند هستند !.
اگر اسکریپت بالا را اجرا کنید و نتایج زیر را مشاهده کنید، به این معنی است که FastText با موفقیت دانلود شده است:
--2019-08-16 15:05:05-- https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
Resolving github.com (github.com)... 140.82.113.4
Connecting to github.com (github.com)|140.82.113.4|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://codeload.github.com/facebookresearch/fastText/zip/v0.1.0 (following)
--2019-08-16 15:05:05-- https://codeload.github.com/facebookresearch/fastText/zip/v0.1.0
Resolving codeload.github.com (codeload.github.com)... 192.30.255.121
Connecting to codeload.github.com (codeload.github.com)|192.30.255.121|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified (application/zip)
Saving to: ‘v0.1.0.zip’
v0.1.0.zip ( <=> ) 92.06K --.-KB/s in 0.03s
2019-08-16 15:05:05 (3.26 MB/s) - ‘v0.1.0.zip’ saved (94267)
مرحله بعدی این است که ماژول های FastText را از حالت فشرده خارج کنید. به سادگی دستور زیر را تایپ کنید:
!unzip v0.1.0.zip
در مرحله بعد، باید به دایرکتوری که در آن FastText را دانلود کرده اید بروید و سپس آن را اجرا کنید !make دستور اجرای باینری های ++C. مراحل زیر را اجرا کنید:
cd fastText-0.1.0
!make
اگر خروجی زیر را مشاهده کردید، به این معنی است که FastText با موفقیت نصب شده است روی ماشین شما
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/args.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/dictionary.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/productquantizer.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/matrix.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/qmatrix.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/vector.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/model.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/utils.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/fasttext.cc
c++ -pthread -std=c++0x -O3 -funroll-loops args.o dictionary.o productquantizer.o matrix.o qmatrix.o vector.o model.o utils.o fasttext.o src/main.cc -o fasttext
برای تایید نصب، دستور زیر را اجرا کنید:
!./fasttext
باید ببینید که این دستورات توسط FastText پشتیبانی می شوند:
usage: fasttext <command> <args>
The commands supported by FastText are:
supervised train a supervised classifier
quantize quantize a model to reduce the memory usage
test evaluate a supervised classifier
predict predict most likely labels
predict-prob predict most likely labels with probabilities
skipgram train a skipgram model
cbow train a cbow model
print-word-vectors print word vectors given a trained model
print-sentence-vectors print sentence vectors given a trained model
nn query for nearest neighbors
analogies query for analogies
طبقه بندی متن
قبل از آموزش مدل های FastText برای انجام طبقه بندی متن، لازم به ذکر است که FastText داده ها را در قالب خاصی می پذیرد که به شرح زیر است:
_label_tag This is sentence 1
_label_tag2 This is sentence 2.
اگر به مجموعه داده خود نگاه کنیم، در قالب مورد نظر نیست. متن با احساسات مثبت باید به این صورت باشد:
__label__positive burgers are very big portions here.
به طور مشابه، نظرات منفی باید به این صورت باشد:
__label__negative They do not use organic ingredients, but I thi...
اسکریپت زیر را فیلتر می کند reviews_score و text ستون هایی از مجموعه داده و سپس پیشوندها __label__ قبل از تمام مقادیر موجود در reviews_score ستون به طور مشابه، \n و \t با یک فاصله در جایگزین می شوند text ستون در نهایت دیتافریم به روز شده به شکل روی دیسک نوشته می شود yelp_reviews_updated.txt.
import pandas as pd
from io import StringIO
import csv
col = ('reviews_score', 'text')
yelp_reviews = yelp_reviews(col)
yelp_reviews('reviews_score')=('__label__'+ s for s in yelp_reviews('reviews_score'))
yelp_reviews('text')= yelp_reviews('text').replace('\n',' ', regex=True).replace('\t',' ', regex=True)
yelp_reviews.to_csv(r'/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt', index=False, sep=' ', header=False, quoting=csv.QUOTE_NONE, quotechar="", escapechar=" ")
حالا بیایید print رئیس به روز شده yelp_reviews چارچوب داده
yelp_reviews.head()
شما باید نتایج زیر را ببینید:
reviews_score text
0 __label__positive Super simple place but amazing nonetheless. It...
1 __label__positive Small unassuming place that changes their menu...
2 __label__positive Lester's is located in a beautiful neighborhoo...
3 __label__positive Love coming here. Yes the place always needs t...
4 __label__positive Had their chocolate almond croissant and it wa...
به طور مشابه، دم دیتافریم به شکل زیر است:
reviews_score text
49995 __label__positive This is an awesome consignment store! They hav...
49996 __label__positive Awesome laid back atmosphere with made-to-orde...
49997 __label__positive Today was my first appointment and I can hones...
49998 __label__positive I love this chic salon. They use the best prod...
49999 __label__positive This place is delicious. All their meats and s...
ما مجموعه داده خود را به شکل مورد نیاز تبدیل کرده ایم. مرحله بعدی این است که داده های خود را به مجموعه های قطار و آزمایش تقسیم کنیم. 80% داده یعنی 40000 رکورد اول از 50000 رکورد برای آموزش داده ها استفاده خواهد شد، در حالی که 20% داده (10000 رکورد آخر) برای ارزیابی عملکرد الگوریتم استفاده خواهد شد.
اسکریپت زیر داده ها را به مجموعه های آموزشی و آزمایشی تقسیم می کند:
!head -n 40000 "/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_train.txt"
!tail -n 10000 "/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_test.txt"
پس از اجرای اسکریپت بالا، yelp_reviews_train.txt فایلی تولید خواهد شد که حاوی داده های آموزشی است. به طور مشابه، به تازگی تولید شده است yelp_reviews_test.txt فایل حاوی داده های آزمایشی خواهد بود.
اکنون زمان آموزش الگوریتم طبقه بندی متن FastText است.
%%time
!./fasttext supervised -input "/content/drive/My Drive/Colab Datasets/yelp_reviews_train.txt" -output model_yelp_reviews
برای آموزش الگوریتم باید از آن استفاده کنیم supervised دستور داده و فایل ورودی را ارسال کنید. نام مدل بعد از آن مشخص می شود -output کلمه کلیدی. اسکریپت بالا منجر به یک مدل طبقه بندی متن آموزش دیده به نام می شود model_yelp_reviews.bin. در اینجا خروجی اسکریپت بالا آمده است:
Read 4M words
Number of words: 177864
Number of labels: 2
Progress: 100.0% words/sec/thread: 2548017 lr: 0.000000 loss: 0.246120 eta: 0h0m
CPU times: user 212 ms, sys: 48.6 ms, total: 261 ms
Wall time: 15.6 s
می توانید از طریق این مدل نگاهی بیندازید !ls دستور مطابق شکل زیر:
!ls
در اینجا خروجی است:
args.o Makefile quantization-results.sh
classification-example.sh matrix.o README.md
classification-results.sh model.o src
CONTRIBUTING.md model_yelp_reviews.bin tutorials
dictionary.o model_yelp_reviews.vec utils.o
eval.py PATENTS vector.o
fasttext pretrained-vectors.md wikifil.pl
fasttext.o productquantizer.o word-vector-example.sh
get-wikimedia.sh qmatrix.o yelp_reviews_train.txt
LICENSE quantization-example.sh
می توانی ببینی model_yelp_reviews.bin در لیست اسناد بالا
در نهایت برای تست مدل می توانید از test فرمان شما باید نام مدل و فایل تست را بعد از آن مشخص کنید test دستور، مطابق شکل زیر:
!./fasttext test model_yelp_reviews.bin "/content/drive/My Drive/Colab Datasets/yelp_reviews_test.txt"
خروجی اسکریپت بالا به شکل زیر است:
N 10000
P@1 0.909
R@1 0.909
Number of examples: 10000
اینجا P@1 اشاره به دقت و R@1به یادآوری اشاره دارد. می توانید ببینید که مدل ما به دقت و فراخوانی 0.909 می رسد که بسیار خوب است.
اکنون بیایید سعی کنیم متن خود را از علائم نگارشی، کاراکترهای خاص پاک کنیم و آن را به حروف کوچک تبدیل کنیم تا یکنواختی متن بهبود یابد. اسکریپت زیر مجموعه قطار را تمیز می کند:
!cat "/content/drive/My Drive/Colab Datasets/yelp_reviews_train.txt" | sed -e "s/\((.\!?,’/())\)/ \1 /g" | tr "(:upper:)" "(:lower:)" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_train_clean.txt"
و اسکریپت زیر مجموعه تست را پاک می کند:
"/content/drive/My Drive/Colab Datasets/yelp_reviews_test.txt" | sed -e "s/\((.\!?,’/())\)/ \1 /g" | tr "(:upper:)" "(:lower:)" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_test_clean.txt"
اکنون به آموزش مدل می پردازیم روی مجموعه آموزشی تمیز شده:
%%time
!./fasttext supervised -input "/content/drive/My Drive/Colab Datasets/yelp_reviews_train_clean.txt" -output model_yelp_reviews
و در نهایت از مدل آموزش دیده استفاده خواهیم کرد روی مجموعه آموزشی تمیز شده برای پیش بینی روی مجموعه تست تمیز شده:
!./fasttext test model_yelp_reviews.bin "/content/drive/My Drive/Colab Datasets/yelp_reviews_test_clean.txt"
خروجی اسکریپت فوق به صورت زیر است:
N 10000
P@1 0.915
R@1 0.915
Number of examples: 10000
شما می توانید افزایش جزئی در دقت و یادآوری مشاهده کنید. برای بهبود بیشتر مدل، می توانید دوره ها و میزان یادگیری مدل را افزایش دهید. اسکریپت زیر تعداد دوره ها را 30 و نرخ یادگیری را 0.5 تنظیم می کند.
%%time
!./fasttext supervised -input "/content/drive/My Drive/Colab Datasets/yelp_reviews_train_clean.txt" -output model_yelp_reviews -epoch 30 -lr 0.5
می توانید اعداد مختلف را امتحان کنید و ببینید آیا می توانید نتایج بهتری بگیرید. فراموش نکنید که نتایج خود را در نظرات به اشتراک بگذارید!
نتیجه
مدل FastText اخیراً در زمینه تعبیه کلمات و وظایف طبقهبندی متن به بهترین شکل به اثبات رسیده است روی بسیاری از مجموعه داده ها استفاده از آن در مقایسه با سایر مدل های جاسازی کلمه بسیار آسان و سریع است.
در این مقاله به طور خلاصه روش یافتن شباهت های معنایی بین کلمات مختلف با ایجاد جاسازی کلمات با استفاده از FastText را بررسی کردیم. قسمت دوم مقاله روش انجام طبقه بندی متن از طریق کتابخانه FastText را توضیح می دهد.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-20 16:33:09
