از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
پانداها یک کتابخانه پایتون برای تجزیه و تحلیل و دستکاری داده ها است. تقریبا تمام عملیات در pandas سیر در اطراف DataFrames، یک ساختار داده انتزاعی که برای مدیریت یک تن متریک داده طراحی شده است.
در حجم داده های متریک فوق الذکر، برخی از آنها به دلایل مختلف ناپدید می شوند. منجر به گم شدن (null/None/Nan) ارزش در ما DataFrame.
به همین دلیل است که در این مقاله، روش مدیریت داده های از دست رفته در پانداها را مورد بحث قرار خواهیم داد DataFrame.
بازرسی داده ها
مجموعه داده های دنیای واقعی به ندرت کامل هستند. آنها ممکن است حاوی مقادیر گم شده، انواع داده های اشتباه، کاراکترهای ناخوانا، خطوط اشتباه و غیره باشند.
اولین گام برای تجزیه و تحلیل صحیح داده ها، تمیز کردن و سازماندهی داده هایی است که بعداً از آنها استفاده خواهیم کرد. ما چند مشکل رایج مربوط به دادهها را که ممکن است در یک مجموعه داده رخ دهد، مورد بحث قرار خواهیم داد.
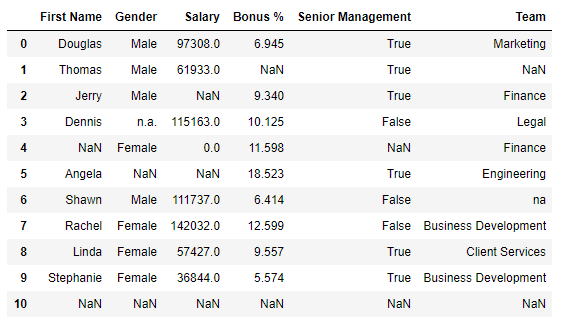
ما برای این کار با مجموعه داده های کارمندان کوچک کار خواهیم کرد. این .csv فایل به شکل زیر است:
First Name,Gender,Salary,Bonus %,Senior Management,Team
Douglas,Male,97308,6.945,TRUE,Marketing
Thomas,Male,61933,NaN,TRUE
Jerry,Male,NA,9.34,TRUE,Finance
Dennis,n.a.,115163,10.125,FALSE,Legal
,Female,0,11.598,,Finance
Angela,,,18.523,TRUE,Engineering
Shawn,Male,111737,6.414,FALSE,na
Rachel,Female,142032,12.599,FALSE,Business Development
Linda,Female,57427,9.557,TRUE,Client Services
Stephanie,Female,36844,5.574,TRUE,Business Development
,,,,,
اجازه دهید import آن را به یک DataFrame:
df = pd.read_csv('out.csv')
df
این منجر به:

با نگاهی دقیق تر به مجموعه داده، متوجه می شویم که Pandas به طور خودکار اختصاص می دهد NaN اگر مقدار یک ستون خاص یک رشته خالی باشد '' NA یا NaN. با این حال، مواردی وجود دارد که مقادیر گمشده با یک مقدار سفارشی، به عنوان مثال، رشته نمایش داده می شوند 'na' یا 0 برای یک ستون عددی
به عنوان مثال، ردیف 6 دارای مقدار است na برای Team ستون، در حالی که سطر 5 دارای مقدار است 0 برای Salary ستون
سفارشی کردن مقادیر داده های از دست رفته
در مجموعه داده ما، می خواهیم اینها را به عنوان مقادیر گم شده در نظر بگیریم:
- آ
0ارزش درSalaryستون - یک
naارزش درTeamستون
این را می توان با استفاده از na_values آرگومان برای تنظیم مقادیر گمشده سفارشی. این آرگومان یک فرهنگ لغت را نشان می دهد که در آن کلیدها یک نام ستون را نشان می دهند و مقدار مقادیر داده هایی را نشان می دهد که باید به عنوان گمشده در نظر گرفته شوند:
df = pd.read_csv('out.csv', na_values={"Salary" : (0), "Team" : ('na')})
df
این منجر به:

از سوی دیگر، اگر بخواهیم فهرستی از مقادیری را ترسیم کنیم که باید به عنوان مقادیر گمشده در تمام ستون ها در نظر گرفته شوند، می توانیم فهرستی از نامزدها را که می خواهیم به صورت سراسری به عنوان مقادیر گمشده در نظر بگیریم به na_values پارامتر:
missing_values = ("n.a.","NA","n/a", "na", 0)
df = pd.read_csv('out.csv', na_values = missing_values)
df
این منجر به:

توجه داشته باشید که در اینجا، مقدار Gender در ردیف 4 نیز قرار دارد NaN حالا از زمانی که تعریف کردیم n.a. به عنوان یک مقدار گم شده در بالا.
اینکه کدام پیاده سازی را انتخاب کنید به ماهیت مجموعه داده بستگی دارد.
برای مثال، برخی از ستونهای عددی در مجموعه داده ممکن است نیاز به درمان داشته باشند 0 به عنوان یک مقدار گم شده در حالی که ستون های دیگر ممکن است نباشند. بنابراین، می توانید از رویکرد اول استفاده کنید که در آن مقادیر گمشده را بر اساس سفارشی سازی می کنید روی ستون ها.
همینطور اگر بخواهیم درمان کنیم 0 به عنوان مثال به عنوان یک مقدار گمشده در سطح جهانی، می توانیم از روش دوم استفاده کنیم و فقط آرایه ای از چنین مقادیری را به na_values بحث و جدل.
زمانی که تمام مقادیر گم شده را شناسایی کردیم DataFrame و آنها را به درستی حاشیه نویسی کردیم، راه های مختلفی وجود دارد که می توانیم داده های از دست رفته را مدیریت کنیم.
حذف ردیف هایی با مقادیر از دست رفته
یک روش حذف تمام ردیف هایی است که حاوی مقادیر گم شده هستند. این را می توان به راحتی با dropna() تابع، به طور خاص به این اختصاص داده شده است:
df.dropna(axis=0,inplace=True)
این منجر به:

inplace = True تمام تغییرات موجود را ایجاد می کند DataFrame بدون برگرداندن مورد جدید بدون آن، شما باید آن را دوباره اختصاص دهید DataFrame به خودش
این axis آرگومان مشخص می کند که آیا با سطرها یا ستون ها کار می کنید – 0 ردیف بودن و 1 ستون بودن
میتوانید کنترل کنید که آیا میخواهید ردیفهای حاوی حداقل ۱ را حذف کنید NaN یا همه NaN مقادیر با تنظیم how پارامتر در dropna روش.
چگونه : {‘any’, ‘all’}
any: اگر مقدار NA وجود دارد، آن برچسب را رها کنیدall: اگر همه مقادیر NA هستند، آن برچسب را رها کنید
df.dropna(axis=0,inplace=True, how='all')
این فقط آخرین ردیف را از مجموعه داده حذف می کند how=all فقط در صورتی که تمام مقادیر در ردیف وجود نداشته باشد، یک ردیف حذف می شود.
به طور مشابه، برای رها کردن ستون های حاوی مقادیر از دست رفته، فقط تنظیم کنید axis=1 در dropna روش.
پر کردن مقادیر از دست رفته
اگر این ردیفها فراوان باشند، ممکن است بهترین روش حذف ردیفهای حاوی مقادیر از دست رفته نباشد. آنها ممکن است حاوی داده های ارزشمند در ستون های دیگر باشند و ما نمی خواهیم داده ها را به سمت وضعیت نادرست سوق دهیم.
در این حالت چندین گزینه برای تخصیص مقادیر مناسب داریم. رایج ترین آنها در زیر ذکر شده است:
- NA را با میانگین، میانه یا حالت داده پر کنید
- NA را با مقدار ثابت پر کنید
- Forward Fill یا Backward Fill NA
- داده ها را درون یابی کنید و NA را پر کنید
بیایید اینها را یکی یکی مرور کنیم.
مقادیر از دست رفته DataFrame را با میانگین ستون، میانه و حالت پر کنید
بیایید با fillna() روش. مقادیر علامت گذاری شده با NA را با مقادیری که شما به روش ارائه می دهید پر می کند.
برای مثال می توانید از .median()، .mode() و .mean() کارکرد روی یک ستون، و آن ها را به عنوان مقدار پر کنید:
df('Salary').fillna(df('Salary').median(), inplace=True)
df('Salary').fillna(int(df('Salary').mean()), inplace=True)
df('Salary').fillna(int(df('Salary').mode()), inplace=True)
حال، اگر حقوقی در ردیفهای فردی وجود نداشته باشد، از میانگین، حالت یا میانه برای پر کردن آن مقدار استفاده میشود. به این ترتیب، شما این افراد را از مجموعه داده حذف نمی کنید، و همچنین ارزش حقوق را تغییر نمی دهید.
اگرچه این روش کامل نیست، اما به شما امکان می دهد مقادیری را معرفی کنید که بر مجموعه داده کلی تأثیر نمی گذارد، زیرا مهم نیست که چند میانگین اضافه کنید، میانگین ثابت می ماند.
مقادیر از دست رفته DataFrame را با یک ثابت پر کنید
همچنین می توانید تصمیم بگیرید که مقادیر مشخص شده با NA را با یک مقدار ثابت پر کنید. به عنوان مثال، می توانید یک رشته یا مقدار عددی خاص را وارد کنید:
df('Salary').fillna(0, inplace=True)
حداقل، این ارزش ها در حال حاضر به جای ارزش های واقعی هستند na یا NaN.
به جلو پر کردن مقادیر از دست رفته DataFrame
این روش مقادیر از دست رفته را با اولین مقدار غیر مفقودی که قبل از آن رخ می دهد پر می کند:
df('Salary').fillna(method='ffill', inplace=True)
Backward Fill Missing DataFrame
این روش مقادیر از دست رفته را با اولین مقدار غیر مفقودی که بعد از آن رخ می دهد پر می کند:
df('Salary').fillna(method='bfill', inplace=True)
مقادیر از دست رفته DataFrame را با درون یابی پر کنید
در نهایت، این روش از درون یابی ریاضی برای تعیین مقداری استفاده می کند که به جای یک مقدار گم شده باشد:
df('Salary').interpolate(method='polynomial')
نتیجه
پاکسازی و پیش پردازش داده ها بخش بسیار مهمی از هر تحلیل داده و هر پروژه علم داده است.
در این مقاله به چندین تکنیک برای رسیدگی به دادههای از دست رفته پرداختیم که شامل سفارشیسازی مقادیر دادههای از دست رفته و نسبت دادن مقادیر دادههای از دست رفته با استفاده از روشهای مختلف از جمله میانگین، میانه، حالت، یک مقدار ثابت، پر کردن رو به جلو، پر کردن به عقب و درون یابی است.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-12 18:27:06
