از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
اگر شما یک مهندس یادگیری ماشین، دانشمند داده یا علاقهمندی هستید که هر از گاهی برای سرگرمی مدلهای یادگیری ماشین را توسعه میدهد، احتمالاً با Tensorflow آشنا هستید.
Tensorflow یک چارچوب متن باز و رایگان است که توسط Google Brain Team نوشته شده است و به زبان های Python، C++ و CUDA نوشته شده است. برای توسعه، آزمایش و استقرار مدلهای یادگیری ماشینی استفاده میشود.
در ابتدا TensorFlow از چندین پلتفرم و زبان های برنامه نویسی پشتیبانی کامل نداشت و برای آموزش مدل های یادگیری ماشینی خیلی سریع و کارآمد نبود، اما با گذشت زمان و پس از چند به روز رسانی، Tensorflow اکنون به عنوان چارچوبی برای توسعه در نظر گرفته می شود. ، آموزش و استقرار مدل های یادگیری ماشینی.
TensorFlow 1.x
Tensorflow 1.x نیز یک جهش بزرگ برای این چارچوب بود. بسیاری از ویژگی های جدید، عملکرد بهبود یافته و مشارکت های منبع باز را معرفی کرد. این API سطح بالایی را برای TensorFlow معرفی کرد که ساخت نمونه های اولیه را در کمترین زمان بسیار آسان کرد.
با Keras سازگار ساخته شد. اما نکته اصلی که توسعهدهندگان را آزار میدهد این بود که هنگام استفاده از TensorFlow تمایلی به استفاده از سادگی پایتون نداشتند.
در TensorFlow، هر مدل به صورت یک نمودار نمایش داده می شود و گره ها محاسبات موجود در نمودار را نشان می دهند. نمونه ای از آن است “برنامه نویسی نمادین” و در حالی که پایتون یک است “برنامه نویسی ضروری” زبان.
من به جزئیات زیاد نمی پردازم زیرا این از حوصله این مقاله خارج است. اما نکته اینجاست که با انتشار PyTorch (که بیشتر به سمت برنامه نویسی امری گرایش دارد و از رفتار پویای پایتون بهره می برد)، تازه واردان و دانشمندان تحقیقاتی متوجه شدند که PyTorch راحت تر از Tensorflow قابل درک و یادگیری است و در مدت کوتاهی PyTorch محبوبیت پیدا کرد. .
هر توسعهدهنده تنسورفلو همین را از تنسورفلو و تیم مغز گوگل میخواست. علاوه بر این، TensorFlow 1.x توسعه بسیاری را پشت سر گذاشت که منجر به بسیاری از APIها شد، به عنوان مثال، tf.layers, tf.contrib.layers, tf.keras و توسعه دهندگان گزینه های زیادی برای انتخاب داشتند که منجر به درگیری شد.
اعلام Tensorflow 2.0
کاملاً واضح بود که تیم تنسورفلو باید به این مسائل رسیدگی می کرد، بنابراین آنها تنسورفلو 2.0 را معرفی کردند.
این یک گام بزرگ بود زیرا برای رسیدگی به همه مسائل باید تغییرات بزرگی ایجاد می کردند. بسیاری از مردم با تجربه یادگیری دیگری مواجه شدند، اما پیشرفتها باعث شد ارزش یادگیری مجدد داشته باشد.
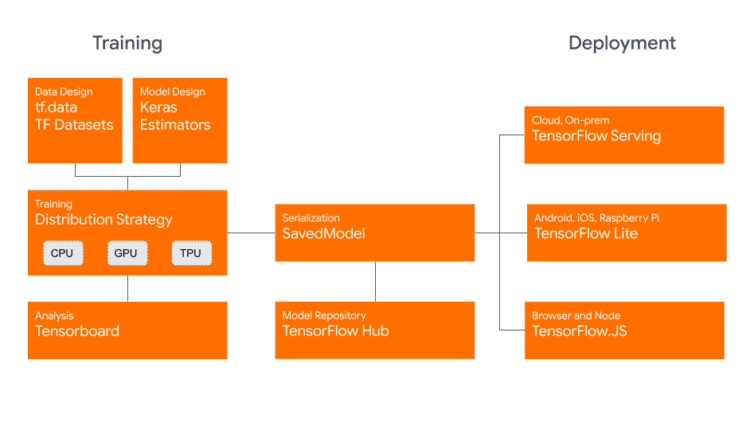
در مرحله آموزش با ما آشنا می شویم tf.data و Datasets که به ما اجازه می دهند import و process داده ها به راحتی سپس، با آموزش توزیع شده روی چندین CPU، GPU و TPU آشنا می شویم. برای سریال سازی می توانیم از SavedModel برای استقرار در TensorFlow Hub یا خدماتی مانند TensorFlow Serving، TensorFlow Lite یا TensorFlow.js:

اعتبار: blog.tensorflow.org
تازه های Tensorflow 2.0
در اینجا مروری کوتاه بر مهم ترین به روز رسانی هایی است که با Tensorflow 2 ارائه شده است.
1. استقرار مدل ها روی پلتفرم های متعدد
Tensorflow همیشه برای تولید بسیار مناسب بود، اما Tensorflow 2 سازگاری و برابری را در چندین پلتفرم بهبود بخشید.
این پلتفرم جدید را برای پشتیبانی معرفی کرد SavedModel فرمتی که به ما امکان می دهد مدل های تنسورفلو را ذخیره کنیم. نکته جدید در اینجا این است که می توانید مدل ذخیره شده خود را مستقر کنید روی هر پلت فرم، به عنوان مثال، روی دستگاه های موبایل یا اینترنت اشیا با استفاده از Tensorflow Lite یا Node.js با Tensorflow.js. همچنین می توانید از آن در محیط های تولیدی استفاده کنید سرویس تنسورفلو.
بیایید نگاهی به روش ذخیره یک مدل کامپایل بیندازیم:
import os
import tensorflow as tf
model = tf.keras.Sequential((
tf.keras.layers.Dense(5,actiavtion='relu',input_shape=(16,)),
tf.keras.layers.Dense(1,activation='sigmoid')))
model.compile(loss='binary_crossentropy',optimizer='adam')
save_path = path + "/version_number/"
save_path = os.path.join
tf.saved_model.save(model, save_path)
و شما بروید. اکنون می توانید آن را با استفاده از هر یک از سرویس های فوق الذکر مستقر کنید.
2. اعدام مشتاق
قبل از Tensorflow 2، باید یک جلسه برای اجرای مدل خود ایجاد می کردید. در واقع، اگر می خواستید print مقدار یک متغیر فقط برای اشکال زدایی، ابتدا باید یک جلسه ایجاد کرده و سپس a را بنویسید print بیانیه داخل آن جلسه
برای تغذیه دادههای ورودی به مدل، باید متغیرهایی کند و بیفایده ایجاد میکردید. اساساً، در Tensorflow 1.x، ابتدا کل نمودار را میسازید و سپس آن را اجرا میکنید، برخلاف ساخت آن. در حالی که در حال اجرا
این احساس ایستا و ناهموار بود، به خصوص برخلاف PyTorch، که به کاربران اجازه می داد در حین اجرا نمودارهای پویا ایجاد کنند.
خوشبختانه، این در Tensorflow 2.0 اصلاح شد که ما را با آن آشنا کرد اعدام مشتاقانه. بیایید نگاهی به روش ساخت یک نمودار در Tensorflow 1.x در مقابل 2.0 بیندازیم:
import tensorflow as tf
"""Creating the Graph"""
a = tf.Variable(4)
b = tf.Variable(5)
result = tf.multiply(a,b)
اکنون برای دسترسی به result متغیر، ما باید نمودار را در یک جلسه اجرا کنیم:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(result))
اکنون، به جای آن، می توانیم مستقیماً به آنها دسترسی داشته باشیم:
import tensorflow as tf
a = tf.Variable(4)
b = tf.Variable(5)
print(float(a*b))
3. ادغام Keras با Tensorflow
Keras یک API شبکه عصبی و یادگیری عمیق است که ساخته شده است روی بالای تنسورفلو
اکثر مردم قبل از حرکت با Keras شروع می کنند روی به Tensorflow یا PyTorch. این برای آزمایش سریع با شبکه های عصبی عمیق طراحی شده است و بنابراین ساده تر است.
قبل از Tensorflow 2.0، توسط کتابخانه پشتیبانی می شد، اما اینطور نبود یکپارچه. اکنون، این به طور رسمی یک API سطح بالا است. نیازی به نصب صریح آن نیست، با Tensorflow عرضه می شود و اکنون از طریق آن قابل دسترسی است tf.keras.
این در نتیجه منجر به پاکسازی و حذف API می شود tf.contrib.layers tf.layers، و غیره. tf.keras اکنون API قابل استفاده است. هر دو tf.contrib.layers و tf.layers همین کار را می کردند و با tf.keras، افزونگی سه گانه وجود خواهد داشت زیرا حاوی موارد است tf.keras.layers مدول.
این تیم همچنین یک راهنما کد خود را از Tensorflow 1.x به Tensorflow 2.0 ارتقا دهید زیرا بسیاری از بسته های قدیمی اکنون منسوخ شده اند.
4. tf.function دکوراتور
این نیز یکی از هیجان انگیزترین ویژگی های Tensorflow 2 است @tf.function دکوراتور به توابع پایتون اجازه می دهد تا به طور خودکار به آن تبدیل شوند نمودارهای تنسورفلو.
شما هنوز هم می توانید تمام مزایای اجرای مبتنی بر نمودار را داشته باشید و از شر برنامه نویسی سنگین مبتنی بر جلسه خلاص شوید. با استفاده از @tf.function دکوراتور به عملکردی مانند:
@tf.function
def multiply(a, b):
return a * b
multiply(tf.ones((2, 2)), tf.ones((2, 2)))
در صورت تعجب، این به طور خودکار با تکمیل می شود دستخط. نموداری تولید میکند که دقیقاً همان جلوههای تابعی را که ما تزئین کردهایم دارد.
5. آموزش با استفاده از محاسبات توزیع شده
Tensorflow 2.0 با عملکرد بهبود یافته برای آموزش با استفاده از GPU ارائه می شود. طبق گفته تیم، این نسخه 3 برابر سریعتر از Tensorflow 1.x است.
و از هم اکنون، تنسورفلو می تواند با TPU ها نیز کار کند. در واقع، شما می توانید با چندین TPU و GPU در یک رویکرد محاسباتی توزیع شده کار کنید.
می توانید در این مورد بیشتر بخوانید راهنمای رسمی.
6. tf.data و مجموعه داده ها
با tf.data، اکنون ساخت خطوط لوله داده سفارشی بسیار آسان است. نیازی به استفاده نیست feed_dict. tf.data از بسیاری از انواع فرمت های ورودی مانند متن، تصویر، ویدئو، سری زمانی و موارد دیگر پشتیبانی می کند.
این لوله های ورودی بسیار تمیز و کارآمد را فراهم می کند. مثلاً بگویید می خواهیم import یک فایل متنی با چند کلمه که از قبل پردازش شده و در یک مدل استفاده می شود. بیایید چند پیش پردازش کلاسیک را برای اکثر مشکلات NLP انجام دهیم.
بیایید ابتدا فایل را بخوانیم، همه کلمات را به حروف کوچک تبدیل کنیم و آنها را به یک لیست تقسیم کنیم:
import numpy as np
text_file = "file.txt"
text = open(text_file,'r').read()
text = text.lower()
text = text.split()
سپس، ما می خواهیم همه کلمات تکراری را حذف کنیم. این به راحتی با بسته بندی آنها در یک انجام می شود Set، تبدیل آن به a List و مرتب کردن آن:
words = sorted(list(set(text)))
اکنون که کلمات منحصربهفرد را مرتب کردهایم، از آنها واژگانی میسازیم. هر کلمه دارای یک شناسه رقمی منحصر به فرد خواهد بود که به آن اختصاص داده شده است:
vocab_to_int = {word:index for index, word in enumerate(words)}
int_to_vocab = np.array(words)
اکنون، برای تبدیل آرایه اعداد صحیح خود که کلمات را به یک مجموعه داده Tensorflow تبدیل می کنیم، از from_tensor_slices() عملکرد ارائه شده توسط tf.data.Dataset:
words_dataset = tf.data.Dataset.from_tensor_slices(words_as_int)
اکنون می توانیم عملیات را انجام دهیم روی این مجموعه داده، مانند دسته بندی آن به دنباله های کوچکتر:
seq_len = 50
sequences = words_dataset.batch(seq_len+1,drop_remainder=True)
اکنون، هنگام آموزش، میتوانیم به راحتی دستههایی را از شی Dataset دریافت کنیم:
for (batch_n,inp) in enumerate(dataset):
از طرف دیگر، می توانید مستقیماً مجموعه داده های موجود را در آن بارگیری کنید Dataset اشیاء:
import tensorflow_datasets as tfds
mnist_data = tfds.load("mnist")
mnist_train, mnist_test = mnist_data("train"), mnist_data("test")
7. tf.keras.Model
یک تازگی دوست داشتنی این است که مدل های سفارشی خود را با طبقه بندی فرعی تعریف کنید keras.Model کلاس
گرفتن یک اشاره از PyTorch، که به توسعه دهندگان اجازه می دهد تا با استفاده از کلاس های سفارشی مدل هایی ایجاد کنند (سفارشی کردن کلاس هایی که یک Layerو در نتیجه ساختار مدل را تغییر میدهد) – Tensorflow 2.0، از طریق Keras، به ما اجازه میدهد تا مدلهای سفارشی را نیز تعریف کنیم.
بیایید a ایجاد کنیم Sequential مانند مدلی که ممکن است از Tensorflow 1 استفاده کنید:
model = tf.keras.Sequential((
tf.keras.layers.Dense(512,activation='relu',input_shape=(784,)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10,activation='softmax')
))
در حال حاضر، به جای استفاده از Sequential مدل، بیایید مدل خود را با طبقه بندی فرعی بسازیم keras.Model کلاس:
class mnist_model(tf.keras.Model):
def __init__(self):
super(mnist_model,self).__init__()
self.dense1 = tf.keras.layers.Dense(512)
self.drop1 = tf.keras.layers.Dropout(0.2)
self.dense2 = tf.keras.layers.Dense(512)
self.drop2 = tf.keras.layers.Dropout(0.2)
self.dense3 = tf.keras.layers.Dense(10)
def call(self,x):
x = tf.nn.relu(self.dense1(x))
x = self.drop1(x)
x = tf.nn.relu(self.dense2(x))
x = self.drop2(x)
x = tf.nn.softmax(self.dense3(x))
return x
ما به طور مؤثر همان مدل را در اینجا ایجاد کردهایم، اگرچه این رویکرد به ما امکان میدهد تا به طور کامل مدلها را مطابق با نیاز خود سفارشیسازی و ایجاد کنیم.
8. tf.GradientTape
tf.GradientTape به شما امکان می دهد به طور خودکار گرادیان ها را محاسبه کنید. این در هنگام استفاده از حلقه های آموزشی سفارشی مفید است.
می توانید مدل خود را با استفاده از حلقه های آموزشی سفارشی به جای فراخوانی آموزش دهید model.fit. این به شما کنترل بیشتری روی آموزش می دهد process اگر می خواهید آن را تغییر دهید
جفت کردن حلقه های آموزشی سفارشی که توسط tf.GradientTape با مدل های سفارشی که توسط keras.Model به شما کنترل روی مدلها و آموزشهایی میدهد که قبلاً هرگز نداشتید.
اینها به سرعت به ویژگی های بسیار محبوب در جامعه تبدیل شدند. در اینجا روش ایجاد یک مدل سفارشی با توابع تزئین شده و یک حلقه آموزشی سفارشی آمده است:
"""Note: We'll be using the model created in the previous section."""
model = mnist_model()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
@tf.function
def step(model,x,y):
"""
model: in this case the mnist_model
x: input data in batches
y: True labels """
with tf.GradientTape() as tape:
predictions = model(x)
loss = loss_object(y,predictions)
trainable_variables = model.trainable_variables()
gradients = tape.gradient(loss,trainable_variables)
optimizer.apply_gradients(zip(gradients,trainable_variables))
return loss
حالا شما فقط می توانید تماس بگیرید step() با ارسال مدل و داده های آموزشی به صورت دسته ای با استفاده از یک حلقه عمل کنید.
نتیجه
با ورود Tensorflow 2.0، بسیاری از شکست ها مجدداً انجام شده است. از گسترش تنوع پشتیبانی سیستم و خدمات جدید گرفته تا مدلهای سفارشی و حلقههای آموزشی – Tensorflow 2.0 همچنین تجربه یادگیری جدیدی را برای تمرینکنندگان کهنهکار معرفی کرده است.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-16 20:25:03
