از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
این راهنما سومین و آخرین بخش از سه راهنما در مورد ماشینهای بردار پشتیبانی (SVM) است. در این راهنما، ما به کار با موارد استفاده از اسکناسهای جعلی ادامه میدهیم، خلاصهای سریع درباره ایده کلی پشت SVM خواهیم داشت، ترفند هسته چیست و انواع مختلف هستههای غیرخطی را با Scikit-Learn پیادهسازی میکنیم.
در سری کامل راهنمای SVM، علاوه بر یادگیری در مورد انواع دیگر SVM ها، شما همچنین با SVM ساده، پارامترهای از پیش تعریف شده SVM، فراپارامترهای C و Gamma و روش تنظیم آنها با جستجوی شبکه و اعتبار سنجی متقابل آشنا خواهید شد.
اگر میخواهید راهنماهای قبلی را بخوانید، میتوانید به دو راهنما اول نگاهی بیندازید یا ببینید کدام موضوعات بیشتر به شما علاقه دارند. در زیر جدول موضوعات تحت پوشش هر راهنما آمده است:
- پیاده سازی SVM و Kernel SVM با Scikit-Learn پایتون
- مورد استفاده: اسکناس را فراموش کنید
- پس زمینه SVM ها
- مدل SVM ساده (خطی).
- درباره مجموعه داده
- وارد کردن مجموعه داده
- کاوش مجموعه داده
- پیاده سازی SVM با Scikit-Learn
- تقسیم داده ها به مجموعه های قطار/آزمون
- آموزش مدل
- پیشگویی
- ارزیابی مدل
- تفسیر نتایج
- آشنایی با فراپارامترهای SVM
- فراپارامتر C
- فراپارامتر گاما
3. پیاده سازی دیگر طعم های SVM با Scikit-Learn پایتون
- ایده کلی SVM ها (یک خلاصه)
- هسته (ترفند) SVM
- پیاده سازی SVM هسته غیر خطی با Scikit-Learn
- واردات کتابخانه ها
- وارد کردن مجموعه داده
- تقسیم داده ها به ویژگی ها (X) و هدف (y)
- تقسیم داده ها به مجموعه های قطار/آزمایش
- آموزش الگوریتم
- هسته چند جمله ای
- پیشگویی
- ارزیابی الگوریتم
- هسته گاوسی
- پیش بینی و ارزیابی
- هسته سیگموئید
- پیش بینی و ارزیابی
- مقایسه عملکردهای غیر خطی هسته
بیایید قبل از دیدن تغییرات جالب هسته SVM به یاد بیاوریم که SVM چیست.
ایده کلی SVM ها
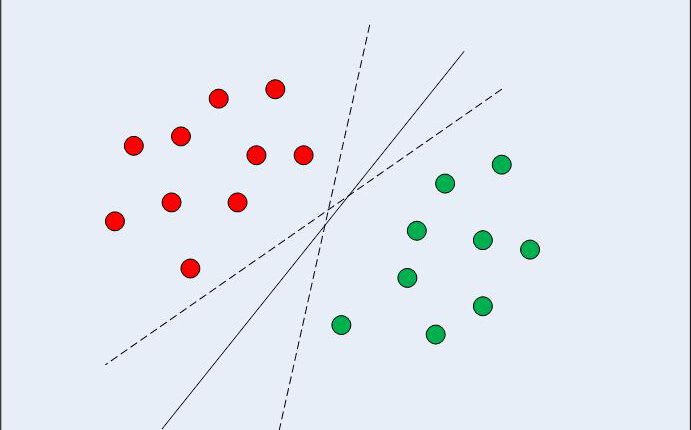
در مورد دادههای قابل جداسازی خطی در دو بعد (همانطور که در شکل 1 نشان داده شده است) رویکرد الگوریتم یادگیری ماشین معمولی تلاش برای یافتن مرزی است که دادهها را به گونهای تقسیم میکند که خطای طبقهبندی اشتباه به حداقل برسد. اگر به شکل 1 دقت کنید، متوجه می شوید که می تواند چندین مرز (بی نهایت) وجود داشته باشد که نقاط داده را به درستی تقسیم می کند. دو خط چین و همچنین خط یکپارچه همه طبقه بندی معتبر داده ها هستند.

شکل 1: مرزهای تصمیم گیری چندگانه
وقتی SVM انتخاب می کند مرز تصمیم گیری، مرزی را انتخاب می کند که فاصله بین خود و نزدیکترین نقاط داده کلاس ها را به حداکثر می رساند. ما قبلاً می دانیم که نزدیکترین نقاط داده بردارهای پشتیبانی هستند و فاصله را می توان با هر دو پارامتر تعیین کرد C و gamma هایپرپارامترها
در محاسبه آن مرز تصمیم، الگوریتم انتخاب میکند که چند نقطه در نظر گرفته شود و حاشیه تا کجا میتواند پیش برود – این مسئله حداکثر کردن حاشیه را پیکربندی میکند. SVM در حل این مشکل به حداکثر رساندن حاشیه، از بردارهای پشتیبان استفاده می کند (همانطور که در شکل 2 مشاهده می شود) و سعی می کند مقادیر بهینه را که فاصله حاشیه را بزرگتر نگه می دارد، مشخص کند، در حالی که نقاط بیشتری را به درستی با توجه به تابعی که استفاده می شود طبقه بندی می کند. داده ها را جدا کنید

شکل 2: مرز تصمیم با بردارهای پشتیبانی
به همین دلیل است که SVM با سایر الگوریتمهای طبقهبندی متفاوت است، زمانی که صرفاً یک مرز تصمیم را پیدا نمیکند، بلکه در نهایت مرز تصمیمگیری بهینه را پیدا میکند.
ریاضیات پیچیده ای وجود دارد که از آمار و روش های محاسباتی در پس یافتن بردارهای پشتیبان، محاسبه حاشیه بین مرز تصمیم گیری و بردارهای پشتیبانی، و به حداکثر رساندن آن حاشیه دخیل است. این بار به جزئیات روش اجرای ریاضیات نمی پردازیم.
همیشه مهم است که عمیقتر غواصی کنید و مطمئن شوید که الگوریتمهای یادگیری ماشین نوعی طلسم اسرارآمیز نیستند، اگرچه ندانستن همه جزئیات ریاضی در این زمان مانع از اجرای الگوریتم و به دست آوردن نتایج نمیشود.
هسته (ترفند) SVM
در بخش قبل، ما ایده کلی SVM را به خاطر آورده و سازماندهی کرده ایم – ببینیم چگونه می توان از آن برای یافتن مرز تصمیم گیری بهینه برای داده های قابل جداسازی خطی استفاده کرد. با این حال، در مورد داده های غیرخطی قابل تفکیک، مانند آنچه در شکل 3 نشان داده شده است، از قبل می دانیم که یک خط مستقیم نمی تواند به عنوان مرز تصمیم استفاده شود.

شکل 3: داده های غیرخطی قابل تفکیک
بلکه میتوانیم از نسخه اصلاحشده SVM که در ابتدا در مورد آن صحبت کردیم، به نام Kernel SVM استفاده کنیم.
اساساً، کاری که SVM هسته انجام خواهد داد این است که دادههای غیرخطی قابل تفکیک ابعاد پایینتر را به شکل متناظر آن در ابعاد بالاتر نمایش دهد. این یک ترفند است، زیرا هنگام نمایش داده های غیرخطی قابل تفکیک در ابعاد بالاتر، شکل داده ها به گونه ای تغییر می کند که قابل تفکیک می شود. به عنوان مثال، زمانی که به 3 بعد فکر می کنیم، نقاط داده از هر کلاس می تواند در یک بعد متفاوت تخصیص داده شود و آن را قابل تفکیک کند. یکی از راههای افزایش ابعاد دادهها میتواند از طریق توانمندسازی آن باشد. باز هم، ریاضیات پیچیده ای در این مورد دخیل است، اما برای استفاده از SVM لازم نیست نگران آن باشید. بلکه میتوانیم از کتابخانه Scikit-Learn پایتون برای پیادهسازی و استفاده از هستههای غیرخطی به همان روشی که از خطی استفاده کردهایم استفاده کنیم.
پیاده سازی SVM هسته غیر خطی با Scikit-Learn
در این بخش، از همان مجموعه داده برای پیشبینی واقعی یا جعلی بودن یک اسکناس با توجه به چهار ویژگی که قبلاً میدانیم، استفاده خواهیم کرد.
خواهید دید که بقیه مراحل، مراحل معمولی یادگیری ماشین هستند و نیاز به توضیح بسیار کمی دارند تا زمانی که به قسمتی برسیم که SVM های هسته غیرخطی خود را آموزش می دهیم.
واردات کتابخانه ها
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
وارد کردن مجموعه داده
data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ("variance", "skewness", "curtosis", "entropy", "class")
bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()mes)
تقسیم داده ها به ویژگی ها (X) و هدف (y)
X = bankdata.drop('class', axis=1)
y = bankdata('class')
تقسیم داده ها به مجموعه های قطار/آزمون
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
آموزش الگوریتم
برای آموزش کرنل SVM از همان استفاده خواهیم کرد SVC کلاس Scikit-Learn’s svm کتابخانه تفاوت در مقدار پارامتر هسته the نهفته است SVC کلاس
در مورد SVM ساده، ما از “خطی” به عنوان مقدار پارامتر هسته استفاده کرده ایم. با این حال، همانطور که قبلا ذکر کردیم، برای کرنل SVM، میتوانیم از هستههای گاوسی، چند جملهای، سیگموئیدی یا قابل محاسبه استفاده کنیم. ما هستههای چند جملهای، گاوسی و سیگموید را پیادهسازی میکنیم و به معیارهای نهایی آن نگاه میکنیم تا ببینیم کدام یک با کلاسهای ما با متریک بالاتر مطابقت دارد.
1. هسته چند جمله ای
در جبر، چند جمله ای عبارتی از شکل زیر است:
$$
2a*b^3 + 4a – 9
$$
این دارای متغیرهایی مانند a و b، ثابت ها، در مثال ما، 9 و ضرایب (ثابت همراه با متغیرها)، مانند 2 و 4. را 3 درجه چند جمله ای در نظر گرفته می شود.
انواع داده هایی وجود دارد که می توان آنها را هنگام استفاده از یک تابع چند جمله ای به بهترین شکل توصیف کرد، در اینجا، کاری که هسته انجام می دهد این است که داده های ما را به چند جمله ای نگاشت می کند که درجه آن را انتخاب می کنیم. هرچه درجه بالاتر باشد، تابع بیشتر سعی می کند به داده ها نزدیک شود، بنابراین مرز تصمیم انعطاف پذیرتر است (و مستعد بیش از حد برازش) – هر چه درجه کمتر باشد، کمترین انعطاف پذیری را دارد.
بنابراین، برای اجرای هسته چند جمله ای، علاوه بر انتخاب poly هسته، ما همچنین یک مقدار برای the ارسال می کنیم degree پارامتر از SVC کلاس کد زیر است:
from sklearn.svm import SVC
svc_poly = SVC(kernel='poly', degree=8)
svc_poly.fit(X_train, y_train)
پیشگویی
اکنون، زمانی که الگوریتم را آموزش دادیم، مرحله بعدی پیشبینی است روی داده های تست
همانطور که قبلا انجام داده ایم، می توانیم اسکریپت زیر را برای این کار اجرا کنیم:
y_pred_poly = svclassifier.predict(X_test)
ارزیابی الگوریتم
طبق معمول، مرحله نهایی ارزیابی است روی هسته چند جمله ای از آنجایی که کد گزارش طبقه بندی و ماتریس سردرگمی را چند بار تکرار کرده ایم، اجازه دهید آن را به تابعی تبدیل کنیم که display_results پس از دریافت مربوطه y_test، y_pred و عنوان به ماتریس سردرگمی Seaborn با cm_title:
def display_results(y_test, y_pred, cm_title):
cm = confusion_matrix(y_test,y_pred)
sns.heatmap(cm, annot=True, fmt='d').set_title(cm_title)
print(classification_report(y_test,y_pred))
اکنون میتوانیم تابع را فراخوانی کنیم و به نتایج بهدستآمده با هسته چند جملهای نگاه کنیم:
cm_title_poly = "Confusion matrix with polynomial kernel"
display_results(y_test, y_pred_poly, cm_title_poly)
خروجی به شکل زیر است:
precision recall f1-score support
0 0.69 1.00 0.81 148
1 1.00 0.46 0.63 127
accuracy 0.75 275
macro avg 0.84 0.73 0.72 275
weighted avg 0.83 0.75 0.73 275

اکنون می توانیم همان مراحل را برای هسته های گاوسی و سیگموئیدی تکرار کنیم.
2. هسته گاوسی
برای استفاده از هسته گاوسی، فقط باید مشخص کنیم rbf به عنوان ارزش برای kernel پارامتر کلاس SVC:
svc_gaussian = SVC(kernel='rbf', degree=8)
svc_gaussian.fit(X_train, y_train)
هنگام کاوش بیشتر این هسته، می توانید از جستجوی شبکه ای برای ترکیب آن با موارد مختلف نیز استفاده کنید C و gamma ارزش های.
پیش بینی و ارزیابی
y_pred_gaussian = svc_gaussian.predict(X_test)
cm_title_gaussian = "Confusion matrix with Gaussian kernel"
display_results(y_test, y_pred_gaussian, cm_title_gaussian)
خروجی SVM هسته گاوسی به صورت زیر است:
precision recall f1-score support
0 1.00 1.00 1.00 148
1 1.00 1.00 1.00 127
accuracy 1.00 275
macro avg 1.00 1.00 1.00 275
weighted avg 1.00 1.00 1.00 275

3. هسته سیگموئید
در نهایت، اجازه دهید از یک هسته سیگموئید برای پیاده سازی Kernel SVM استفاده کنیم. به اسکریپت زیر دقت کنید:
svc_sigmoid = SVC(kernel='sigmoid')
svc_sigmoid.fit(X_train, y_train)
برای استفاده از هسته sigmoid، باید “sigmoid” را به عنوان مقدار برای آن مشخص کنید kernel پارامتر از SVC کلاس
پیش بینی و ارزیابی
y_pred_sigmoid = svc_sigmoid.predict(X_test)
cm_title_sigmoid = "Confusion matrix with Sigmoid kernel"
display_results(y_test, y_pred_sigmoid, cm_title_sigmoid)
خروجی Kernel SVM با هسته Sigmoid به شکل زیر است:
precision recall f1-score support
0 0.67 0.71 0.69 148
1 0.64 0.59 0.61 127
accuracy 0.65 275
macro avg 0.65 0.65 0.65 275
weighted avg 0.65 0.65 0.65 275

مقایسه عملکردهای غیر خطی هسته
اگر به طور خلاصه عملکرد انواع مختلف هسته های غیر خطی را با هم مقایسه کنیم، ممکن است به نظر برسد که هسته سیگموئید کمترین معیارها را دارد، بنابراین بدترین عملکرد را دارد.
در میان هستههای گاوسی و چندجملهای، میتوانیم ببینیم که هسته گاوسی به نرخ پیشبینی کامل 100% دست یافته است – که معمولاً مشکوک است و ممکن است نشاندهنده بیشرفتگی باشد، در حالی که هسته چند جملهای 68 نمونه از کلاس 1 را به اشتباه طبقهبندی کرده است.
بنابراین، هیچ قانون سخت و سریعی وجود ندارد که کدام هسته بهترین عملکرد را در هر سناریو یا در سناریوی فعلی ما بدون جستجوی بیشتر برای فراپارامترها، درک در مورد هر شکل تابع، کاوش در دادهها، و مقایسه آموزش و نتایج آزمایش برای دیدن اینکه آیا الگوریتم تعمیم می دهد.
همه چیز در مورد آزمایش همه هسته ها و انتخاب هسته ای با ترکیبی از پارامترها و آماده سازی داده ها است که نتایج مورد انتظار را با توجه به زمینه پروژه شما ارائه می دهد.
نتیجه
در این مقاله یک جمع بندی سریع انجام دادیم روی SVM ها، در مورد ترفند هسته مطالعه کردند و طعم های مختلف SVM های غیر خطی را پیاده سازی کردند.
پیشنهاد می کنم هر کرنل را پیاده سازی کنید و ادامه دهید. می توانید ریاضیات مورد استفاده برای ایجاد هر یک از هسته های مختلف، دلیل ایجاد آنها و تفاوت های مربوط به فراپارامترهای آنها را بررسی کنید. به این ترتیب، شما در مورد تکنیک ها و اینکه چه نوع هسته ای برای اعمال بهتر است، یاد خواهید گرفت روی زمینه و داده های موجود
داشتن درک روشنی از روش عملکرد هر کرنل و زمان استفاده از آنها قطعا به شما در سفرتان کمک خواهد کرد. به ما اطلاع دهید که پیشرفت چگونه پیش می رود و کدنویسی خوشحال کننده است!
(برچسبها به ترجمه)# python
منتشر شده در 1402-12-31 22:11:05
