از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
الگوریتم جنگل تصادفی یکی از انعطافپذیرترین، قدرتمندترین و پرکاربردترین الگوریتمها برای طبقه بندی و رگرسیون، ساخته شده به عنوان یک مجموعه درختان تصمیم.
اگر با اینها آشنا نیستید – نگران نباشید، ما همه این مفاهیم را پوشش خواهیم داد.
در این دست های عمیق -روی راهنمای، ما یک بینش روی چگونه درختان تصمیم کار می کنند، چگونه مجموعه سازی طبقه بندی کننده ها و رگرسیون های فردی را تقویت می کند، جنگل های تصادفی چیست و با استفاده از Python و Scikit-Learn، از طریق یک پروژه کوچک انتها به انتها، یک طبقه بندی کننده و رگرسیون جنگل تصادفی بسازید و به یک سوال تحقیقاتی پاسخ دهید.
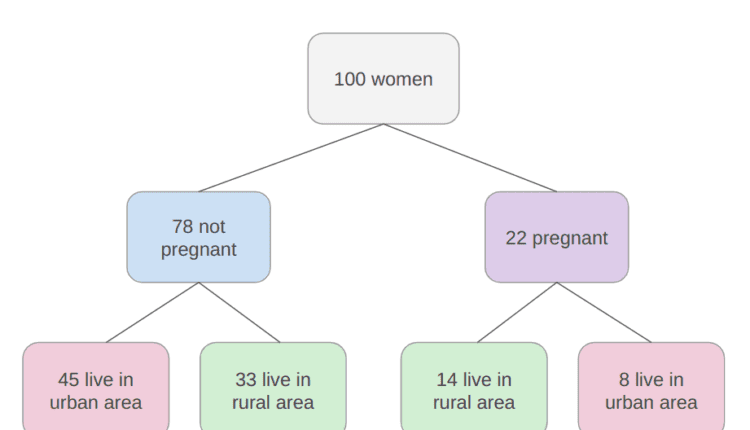
در نظر بگیرید که در حال حاضر بخشی از یک گروه تحقیقاتی هستید که دادههای مربوط به زنان را تجزیه و تحلیل میکند. این گروه 100 رکورد داده را جمع آوری کرده است و می خواهد بتواند آن سوابق اولیه را با تقسیم بندی زنان به دسته ها سازماندهی کند: باردار بودن یا نبودن و زندگی در مناطق روستایی یا شهری. محققان میخواهند بفهمند که در هر دسته چند زن خواهند بود.
یک ساختار محاسباتی وجود دارد که دقیقاً این کار را انجام می دهد درخت ساختار با استفاده از ساختار درختی، میتوانید تقسیمبندیهای مختلف را برای هر دسته نشان دهید.
درختان تصمیم
چگونه می توان گره های یک درخت را پر کرد؟ اینجاست که درختان تصمیم مورد توجه قرار گیرد.
ابتدا می توانیم رکوردها را بر اساس بارداری تقسیم کنیم، بعد از آن می توانیم با زندگی در مناطق شهری یا روستایی آنها را تقسیم کنیم. توجه داشته باشید که ما میتوانیم این کار را به ترتیب متفاوتی انجام دهیم، ابتدا بر اساس منطقهای که زنان زندگی میکنند و پس از آن بر اساس وضعیت بارداری آنها تقسیم میکنیم. از اینجا می توان دریافت که درخت دارای یک سلسله مراتب ذاتی است. علاوه بر سازماندهی اطلاعات، یک درخت اطلاعات را به صورت سلسله مراتبی سازماندهی می کند – ترتیب ظاهر شدن اطلاعات مهم است و در نتیجه به درختان مختلف منتهی می شود.
در زیر، نمونه ای از درختی است که توضیح داده شده است:

در تصویر درخت، 7 مربع وجود دارد، یکی روی بالا که در مجموع 100 زن را شامل می شود، این مربع بالا با دو مربع زیر متصل است که زنان را بر اساس تقسیم می کند. روی تعداد آنها 78 باردار و 22 باردار است و از هر دو مربع قبلی چهار مربع وجود دارد. دو تا متصل به هر مربع بالا که زنان را بر اساس تقسیم می کند روی منطقه آنها، برای غیر باردار، 45 در منطقه شهری، 33 در منطقه روستایی و برای باردار، 14 در منطقه روستایی و 8 در منطقه شهری زندگی می کنند. فقط با نگاه کردن به درخت، به راحتی می توان آن تقسیم بندی ها را فهمید و دید که چگونه هر “لایه” از لایه های قبلی مشتق شده است، آن لایه ها همان درخت هستند. سطوح، سطوح توصیف می کنند عمق از درخت:

در تصویر بالا توجه کنید که اولین سطح درخت است سطح 0 که در آن تنها یک مربع وجود دارد، به دنبال آن سطح 1 که در آن دو مربع وجود دارد، و سطح 2 که در آن چهار مربع وجود دارد. این یک است عمق 2 درخت
در سطح 0 مربعی است که درخت را به وجود می آورد، اولین مورد نامیده می شود root node، این root دو تا دارد گره های کودک در سطح 1، که هستند گره های والد به چهار گره در سطح 2. ببینید که “مربع” هایی که تاکنون ذکر کردیم، در واقع نامیده می شوند. گره ها; و هر قبلی node والد گره های زیر است که فرزندان آن هستند. گره های فرزند هر سطح که والد یکسانی دارند نامیده می شوند خواهر و برادرهمانطور که در تصویر بعدی قابل مشاهده است:

در تصویر قبلی، سطح 1 را نیز به عنوان نشان می دهیم گره های داخلی، هنگامی که آنها بین root و آخرین گره ها که عبارتند از گره های برگ. گره های برگ آخرین قسمت درخت هستند، اگر از 100 زن اولیه بگوییم چه تعداد باردار هستند و در مناطق روستایی زندگی می کنند، می توانیم با نگاه کردن به برگ ها این کار را انجام دهیم. بنابراین عدد موجود در برگها به اولین سوال تحقیق پاسخ می دهد.
اگر رکوردهای جدیدی از زنان وجود داشته باشد، و درختی که قبلاً برای طبقه بندی آنها استفاده می شد، اکنون برای تصمیم گیری در مورد اینکه آیا یک زن می تواند یا نمی تواند بخشی از این تحقیق باشد، استفاده می شد، آیا همچنان کار می کند؟ این درخت از همان معیارها استفاده می کند و یک زن در صورت بارداری و زندگی در یک منطقه روستایی واجد شرایط شرکت در آن خواهد بود.

با مشاهده تصویر بالا می بینیم که پاسخ سوالات هر درخت است node – “آیا او یک شرکت کننده است؟”، “آیا او باردار است؟”، “آیا او در یک منطقه روستایی زندگی می کند؟” – بله، بله، و بله، بنابراین به نظر می رسد که درخت واقعا می تواند منجر به تصمیم گیری شود، در این مورد در صورتی که زن بتواند در تحقیق شرکت کند.
این است ذات درخت تصمیم در، به صورت دستی انجام می شود. با استفاده از یادگیری ماشینی، میتوانیم مدلی بسازیم که این درخت را بهطور خودکار برای ما بسازد، به گونهای که دقت تصمیمات نهایی را به حداکثر برسانیم.
توجه داشته باشید: در علوم کامپیوتر انواع مختلفی از درختان وجود دارد، مانند درختان دودویی، درختان عمومی، درختان AVL، درختان اسپلی، درختان سیاه قرمز، درختان b و غیره. در اینجا، ما تمرکز می کنیم. روی ارائه یک ایده کلی از درخت تصمیم چیست. اگر بستگی دارد روی پاسخ الف آره یا نه سوال برای هر کدام node و بنابراین هر کدام node دارد حداکثر دو فرزند، هنگامی که به گونه ای مرتب شوند که گره های “کوچکتر” باشند روی در سمت چپ، این درخت تصمیم را به عنوان طبقه بندی می کند درختان دوتایی.
در مثال های قبلی، مشاهده کنید که درخت چگونه می تواند طبقه بندی کردن دادههای جدید بهعنوان شرکتکننده یا غیرشرکتکننده، یا سؤالات را میتوان به «چند شرکتکننده؟»، «چند نفر باردار هستند؟»، «چند نفر در یک منطقه روستایی زندگی میکنند؟» تغییر داد. تعداد شرکت کنندگان باردار که در یک منطقه روستایی زندگی می کنند.
وقتی داده ها طبقه بندی می شوند، به این معنی است که درخت a را انجام می دهد طبقه بندی وظیفه، و هنگامی که مقدار داده پیدا شد، درخت در حال انجام a است پسرفت وظیفه. این بدان معنی است که درخت تصمیم می تواند برای هر دو کار – طبقه بندی و رگرسیون استفاده شود.
اکنون که میدانیم درخت تصمیم چیست، چگونه میتوان از آن استفاده کرد و از چه نامگذاری برای توصیف آن استفاده میشود، میتوانیم درباره محدودیتهای آن تعجب کنیم.
درک جنگل های تصادفی
اگر برخی از شرکتکنندگان زنده باشند، چه اتفاقی برای تصمیمگیری میافتد؟ روی تقسیم بین شهری و روستایی؟ آیا درخت این رکورد را به روستایی یا شهری اضافه می کند؟ تطبیق این دادهها در ساختاری که در حال حاضر داریم سخت به نظر میرسد، زیرا برش نسبتاً واضح است.
همچنین، چه می شود اگر یک زن که زندگی می کند روی یک قایق در تحقیق شرکت می کند، آیا روستایی در نظر گرفته می شود یا شهری؟ همانند مورد قبلی، طبقه بندی با توجه به گزینه های موجود در درخت، یک نقطه داده چالش برانگیز است.
با کمی بیشتر فکر کردن در مورد مثال درخت تصمیم، میتوانیم ببینیم که میتواند دادههای جدید را به درستی طبقهبندی کند، با توجه به اینکه قبلاً از الگویی که درخت قبلاً دارد پیروی میکند – اما وقتی رکوردهایی وجود داشته باشند که با دادههای اولیه که درخت را تعریف کردهاند متفاوت باشند، ساختار درختی بسیار سفت و سخت است و باعث می شود رکوردها قابل طبقه بندی نباشند.
این بدان معنی است که درخت تصمیم می تواند سختگیرانه و محدود باشد. یک درخت تصمیم ایدهآل انعطافپذیرتر بوده و میتواند دادههای نادیده ظریفتری را در خود جای دهد.
راه حل: درست همانطور که “دو جفت چشم بهتر از یک جفت می بینند”، دو مدل نیز معمولاً پاسخ دقیق تری نسبت به یکی دارند. با در نظر گرفتن تنوع در بازنمایی دانش (که در ساختار درختی رمزگذاری شده است)، استحکام ساختارهای کمی متفاوت بین چندین درخت مشابه دیگر محدود کننده نیست، زیرا کاستی های یک درخت را می توان توسط درخت دیگری جبران کرد. با ترکیب بسیاری از درختان با هم، ما یک جنگل.
با توجه به پاسخ به سؤال اولیه، ما قبلاً می دانیم که در برگ درختان کدگذاری می شود – اما وقتی درختان زیادی به جای یک درخت داشته باشیم چه تغییری می کند؟
اگر درخت ها برای یک طبقه بندی ترکیب شوند، نتیجه با اکثریت پاسخ ها تعریف می شود، این به نام رای اکثریت; و در صورت رگرسیون عدد داده شده توسط هر درخت در جنگل خواهد بود متوسط.
گروه آموزشی و مدل گروه
این روش به عنوان شناخته شده است یادگیری گروهی. وقتی از یادگیری گروهی استفاده میکنید، میتوانید هر الگوریتمی را با هم ترکیب کنید، تا زمانی که بتوانید اطمینان حاصل کنید که خروجی میتواند با سایر خروجیها تجزیه و ترکیب شود (به صورت دستی یا با استفاده از کتابخانههای موجود). به طور معمول، شما چندین مدل از یک نوع را با هم ترکیب میکنید، مانند چندین درخت تصمیم، اما فقط محدود به پیوستن به مجموعههای همان مدل نیستید.
Ensembling یک روش عملا تضمین شده برای تعمیم بهتر به یک مشکل، و کاهش اندک افزایش عملکرد است. در برخی موارد، مدلهای ترکیبی به a قابل توجه افزایش قدرت پیش بینی، و گاهی اوقات، فقط اندک. این بستگی دارد روی مجموعه داده ای که آموزش می دهید و ارزیابی می کنید onو همچنین خود مدل ها.
به هم پیوستن درختان تصمیم گیری نتیجه می دهد قابل توجه عملکرد در مقایسه با درختان منفرد افزایش می یابد. این رویکرد در جوامع تحقیقاتی و یادگیری ماشین کاربردی رایج شد و به قدری رایج بود که مجموعه درختهای تصمیم به صورت محاورهای نامگذاری شد. جنگلو نوع رایج جنگلی که در حال ایجاد بود (جنگلی از درختان تصمیم روی زیرمجموعه ای تصادفی از ویژگی ها) این نام را رایج کرد جنگل های تصادفی.
با توجه به استفاده در مقیاس وسیع، کتابخانههایی مانند Scikit-Learn پوششهایی را برای آن پیادهسازی کردهاند RandomForestRegressorشن RandomForestClassifiers، ساخته شده است روی در بالای پیاده سازی درخت تصمیم خود، به محققان اجازه می دهد تا از ساخت مجموعه های خود اجتناب کنند.
بیایید به جنگل های تصادفی شیرجه بزنیم!
الگوریتم جنگل تصادفی چگونه کار می کند؟
مراحل زیر در هنگام اجرای الگوریتم جنگل تصادفی وجود دارد:
- تعدادی رکورد تصادفی را انتخاب کنید، می تواند هر عددی باشد، مانند 4، 20، 76، 150 یا حتی 2000 از مجموعه داده (به نام ن سوابق). تعداد بستگی دارد روی عرض مجموعه داده، هرچه گسترده تر، بزرگتر باشد ن می تواند باشد. اینجاست که تصادفی بخشی از نام الگوریتم از آن گرفته شده است!
- بر اساس درخت تصمیم بسازید روی آن ها ن رکوردهای تصادفی؛
- با توجه به تعداد درختان تعریف شده برای الگوریتم، یا تعداد درختان در جنگل، مراحل 1 و 2 را تکرار کنید.
- بعد از مرحله 3، مرحله نهایی می آید که پیش بینی نتایج است:
- در صورت طبقه بندی: هر درخت در جنگل دسته ای را که رکورد جدید به آن تعلق دارد را پیش بینی می کند. پس از آن، رکورد جدید به دسته ای اختصاص می یابد که رای اکثریت را کسب کند.
- در صورت رگرسیون: هر درخت در جنگل مقداری را برای رکورد جدید پیشبینی میکند و ارزش پیشبینی نهایی با میانگین کل مقادیر پیشبینیشده توسط همه درختان جنگل محاسبه میشود.
هر درخت مناسب است روی یک زیرمجموعه تصادفی از ویژگیها لزوماً از برخی ویژگیهای دیگر اطلاعی ندارند، که با ترکیب کردن اصلاح میشود، در حالی که هزینه محاسباتی را پایینتر نگه میدارد.
با یک شهود روی روش کار درختان و درک درستی از جنگل های تصادفی – تنها چیزی که باقی می ماند تمرین ساختن، آموزش و تنظیم آنهاست. روی داده ها!
ساخت و آموزش مدل های تصادفی جنگل با Scikit-Learn
مثالهایی که تاکنون استفاده شدهاند، دلیلی داشتند که شامل بارداری، محل زندگی و زنان میشد.
در سال 2020، محققان بنگلادش متوجه شدند که مرگ و میر در میان زنان باردار هنوز بسیار بالا است، به ویژه با توجه به زنانی که در مناطق روستایی زندگی می کنند. به همین دلیل، آنها از سیستم نظارت IOT استفاده کردند تجزیه و تحلیل خطر سلامت مادر. سیستم IOT دادهها را از بیمارستانها، کلینیکهای اجتماعی و مراقبتهای بهداشتی مادران از مناطق روستایی بنگلادش جمعآوری کرد.
سپس دادههای جمعآوریشده در یک فایل با مقدار جدا شده با کاما (csv) سازماندهی شد و در آن آپلود شد. مخزن یادگیری ماشین UCI.
این دادههایی است که ما از آن برای تمرین استفاده میکنیم و سعی میکنیم بفهمیم که آیا یک زن باردار مبتلا به این بیماری است کم، متوسط یا بالا خطر مرگ و میر
توجه داشته باشید: می توانید مجموعه داده را دانلود کنید اینجا.
استفاده از جنگل تصادفی برای طبقه بندی
از آنجایی که می خواهیم بدانیم آیا زن دارای یک کم، متوسط یا بالا خطر مرگ و میر، به این معنی است که ما یک طبقه بندی با سه کلاس انجام خواهیم داد. هنگامی که یک مسئله بیش از دو کلاس داشته باشد، a نامیده می شود چند کلاسه مشکل، برخلاف الف دودویی مشکل (معمولاً بین دو کلاس انتخاب می کنید 0 و 1).
در این مثال اول، ما یک مدل طبقهبندی چند کلاسه را با طبقهبندیکننده جنگل تصادفی و Scikit-Learn پایتون پیادهسازی میکنیم.
ما مراحل معمول یادگیری ماشین را برای حل این مشکل دنبال خواهیم کرد، که شامل بارگذاری کتابخانه ها، خواندن داده ها، مشاهده آمار خلاصه و ایجاد تجسم داده ها برای درک بهتر آن است. سپس، پیش پردازش و تقسیم داده ها به دنبال تولید، آموزش و ارزیابی مدل.
واردات کتابخانه ها
ما از پانداها برای خواندن دادهها، از Seaborn و Matplotlib برای تجسم آنها و از NumPy برای روشهای کاربردی عالی استفاده خواهیم کرد:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
وارد کردن مجموعه داده
کد زیر مجموعه داده را وارد کرده و آن را در a بارگذاری می کند python DataFrame:
dataset = pd.read_csv("../../datasets/random-forest/maternal_health_risk.csv")
برای نگاه کردن به پنج خط اول داده ها، دستور را اجرا می کنیم head() دستور:
dataset.head()
این خروجی:
Age SystolicBP DiastolicBP BS BodyTemp HeartRate RiskLevel
0 25 130 80 15.0 98.0 86 high risk
1 35 140 90 13.0 98.0 70 high risk
2 29 90 70 8.0 100.0 80 high risk
3 30 140 85 7.0 98.0 70 high risk
4 35 120 60 6.1 98.0 76 low risk
در اینجا میتوانیم تمام ویژگیهای جمعآوریشده در طول تحقیق را مشاهده کنیم.
- سن: سن به سال.
- سیستولیک BP: مقدار بالای فشار خون بر حسب میلی متر جیوه، یک ویژگی مهم در دوران بارداری.
- فشار خون دیاستولیک: مقدار کمتر فشار خون در میلی متر جیوه، یکی دیگر از ویژگی های مهم در دوران بارداری.
- BS: سطح گلوکز خون بر حسب غلظت مولی، mmol/L.
- ضربان قلب: ضربان قلب در حالت استراحت بر حسب ضربان در دقیقه.
- سطح خطر: سطح خطر در دوران بارداری.
- BodyTemp: دمای بدن
اکنون که بیشتر در مورد آنچه اندازه گیری می شود فهمیدیم، می توانیم انواع داده ها را با آن بررسی کنیم info():
dataset.info()
این نتیجه در:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1014 entries, 0 to 1013
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 1014 non-null int64
1 SystolicBP 1014 non-null int64
2 DiastolicBP 1014 non-null int64
3 BS 1014 non-null float64
4 BodyTemp 1014 non-null float64
5 HeartRate 1014 non-null int64
6 RiskLevel 1014 non-null object
dtypes: float64(2), int64(4), object(1)
memory usage: 55.6+ KB
از نگاه کردن به RangeIndex خط، می بینیم که 1014 رکورد و ستون وجود دارد Non-Null Count به اطلاع می رساند که داده ها هیچ مقدار گمشده ای ندارند. این بدان معناست که برای داده های از دست رفته نیازی به درمان نداریم!
در Dtype ستون، ما می توانیم نوع هر متغیر را ببینیم. در حال حاضر، float64 ستون هایی از این قبیل BS و BodyTemp دارای مقادیر عددی هستند که ممکن است در هر محدوده متفاوت باشد، مانند 15.0، 15.51، 15.76، 17.28، که آنها را می سازد. پیوسته عددی (شما همیشه می توانید یک عدد 0 را به یک عدد ممیز شناور بی نهایت اضافه کنید). از سوی دیگر متغیرهایی مانند Age، SystolicBP، DiastolicBP، و HeartRate از نوع هستند int64، این بدان معنی است که اعداد فقط بر اساس واحد تغییر می کنند، مانند 11، 12، 13، 14 – ضربان قلب 77.78 نخواهیم داشت، یا 77 یا 78 است – اینها هستند. از نظر عددی گسسته ارزش های. و ما هم داریم RiskLevel با یک object نوع، معمولاً نشان می دهد که متغیر یک متن است و احتمالاً باید آن را به یک عدد تبدیل کنیم. از آنجایی که سطح ریسک از پایین به بالا رشد می کند، یک نظم ضمنی در دسته ها وجود دارد، این نشان می دهد که به طور قطعی ترتیبی متغیر.
توجه داشته باشید: مهم است که به نوع هر داده نگاه کنید و ببینید آیا با توجه به زمینه آن معنا دارد یا خیر. به عنوان مثال، داشتن نیمی از واحد ضربان قلب منطقی نیست، بنابراین به این معنی است که نوع عدد صحیح برای یک مقدار گسسته کافی است. وقتی این اتفاق نمی افتد، می توانید نوع داده ها را با پانداها تغییر دهید. astype() ویژگی – df('column_name').astype('type').
پس از بررسی انواع داده ها، می توانیم استفاده کنیم describe() برای نگاه کردن به برخی از آمارهای توصیفی، مانند مقادیر میانگین هر ستون، انحراف استاندارد، چندک ها، مقادیر حداقل و حداکثر داده:
dataset.describe().T
کد بالا نمایش می دهد:
count mean std min 25% 50% 75% max
Age 1014.0 29.871795 13.474386 10.0 19.0 26.0 39.0 70.0
SystolicBP 1014.0 113.198225 18.403913 70.0 100.0 120.0 120.0 160.0
DiastolicBP 1014.0 76.460552 13.885796 49.0 65.0 80.0 90.0 100.0
BS 1014.0 8.725986 3.293532 6.0 6.9 7.5 8.0 19.0
BodyTemp 1014.0 98.665089 1.371384 98.0 98.0 98.0 98.0 103.0
HeartRate 1014.0 74.301775 8.088702 7.0 70.0 76.0 80.0 90.0
RiskLevel 1014.0 0.867850 0.807353 0.0 0.0 1.0 2.0 2.0
توجه داشته باشید که برای اکثر ستون ها، منظور داشتن ارزش ها از انحراف معیار (STD) – این نشان می دهد که داده ها لزوماً از توزیع آماری خوب پیروی نمی کنند. اگر این کار را می کرد، در پیش بینی ریسک به مدل کمک می کرد. کاری که در اینجا میتوان انجام داد این است که دادهها را از قبل پردازش کنیم تا نمایانتر شوند، گویی دادههایی از کل جمعیت جهان یا بیشتر است. عادی شده است. اما، یک مزیت هنگام استفاده از مدل های جنگل تصادفی برای طبقه بندی، این است که ساختار درختی ذاتی می تواند با داده هایی که نرمال سازی نشده اند به خوبی برخورد کند، پس از تقسیم آن بر مقدار در هر سطح درخت برای هر متغیر.
همچنین، چون از درختها استفاده میکنیم و کلاس حاصل با رأیگیری به دست میآید، ما ذاتاً بین مقادیر مختلف مقایسه نمیکنیم، فقط بین انواع یکسانی از مقادیر مقایسه میکنیم، بنابراین تنظیم ویژگیها در مقیاس یکسان در این مورد ضروری نیست. مورد. این بدان معنی است که مدل طبقه بندی جنگل تصادفی است مقیاس ثابت، و نیازی به انجام مقیاس بندی ویژگی ندارید.
در این مورد، مرحله ای که در پیش پردازش داده ها می توانیم برداریم، تبدیل دسته بندی است RiskLevel ستون به یک عددی
تجسم داده ها
قبل از تبدیل RiskLevelبیایید همچنین با مشاهده ترکیب نقاط برای هر جفت ویژگی با Scatterplot و روش توزیع نقاط با تجسم منحنی هیستوگرام، داده ها را به سرعت تجسم کنیم. برای این کار از Seaborn’s استفاده می کنیم pairplot() که هر دو طرح را با هم ترکیب می کند. هر دو نمودار را برای هر ترکیب ویژگی ایجاد می کند و نقاط رنگی را با توجه به سطح خطر آنها با کد نمایش می دهد hue ویژگی:
g = sns.pairplot(dataset, hue='RiskLevel')
g.fig.suptitle("Scatterplot and histogram of pairs of variables color coded by risk level",
fontsize = 14,
y=1.05);
کد بالا تولید می کند:

وقتی به طرح نگاه می کنیم، وضعیت ایده آل این است که بین منحنی ها و نقطه ها جدایی واضحی وجود داشته باشد. همانطور که می بینیم، سه نوع کلاس خطر عمدتاً با هم مخلوط شده اند، از آنجایی که درختان به صورت داخلی خطوطی را هنگام تعیین فاصله بین نقاط ترسیم می کنند، می توانیم فرض کنیم که درختان بیشتری در جنگل ممکن است بتوانند فضاهای بیشتری را محدود کرده و نقاط را بهتر طبقه بندی کنند.
با تجزیه و تحلیل داده های اکتشافی اولیه انجام شده، می توانیم آن را پیش پردازش کنیم RiskLevel ستون
پیش پردازش داده ها برای طبقه بندی
برای اطمینان از اینکه فقط سه کلاس وجود دارد RiskLevel در داده های ما، و اینکه هیچ مقدار دیگری به اشتباه اضافه نشده است، می توانیم استفاده کنیم unique() برای نمایش مقادیر منحصر به فرد ستون:
dataset('RiskLevel').unique()
این خروجی:
array(('high risk', 'low risk', 'mid risk'), dtype=object)
کلاس ها بررسی می شوند، اکنون مرحله بعدی تبدیل هر مقدار به یک عدد است. از آنجایی که نظمی بین طبقه بندی ها وجود دارد، می توانیم از مقادیر 0، 1 و 2 برای نشان دادن استفاده کنیم کم، متوسط و بالا خطرات راههای زیادی برای تغییر مقادیر ستونها به دنبال پایتون وجود دارد ساده بهتر از پیچیده است شعار، ما استفاده خواهیم کرد .replace() روش، و به سادگی آنها را با نمایش عدد صحیح خود جایگزین کنید:
dataset('RiskLevel') = dataset('RiskLevel').replace('low risk', 0).replace('mid risk', 1).replace('high risk', 2)
پس از جایگزینی مقادیر، می توانیم داده ها را به آنچه برای آموزش مدل استفاده می شود، تقسیم کنیم امکانات یا ایکسو آنچه می خواهیم پیش بینی کنیم، برچسب ها یا y:
y = dataset('RiskLevel')
X = dataset.drop(('RiskLevel'), axis=1)
از وقتی که X و y مجموعه ها آماده هستند، می توانیم از Scikit-Learn استفاده کنیم train_test_split() روش برای تقسیم بیشتر آنها به قطار و مجموعه های آزمایشی:
from sklearn.model_selection import train_test_split
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=SEED)
در اینجا، ما از 20٪ داده ها برای آزمایش و 80٪ برای آموزش استفاده می کنیم.
آموزش RandomForestClassifier
Scikit-Learn مجموعه های اجرا شده را تحت sklearn.ensemble مدول. مجموعه ای از درختان تصمیم که برای طبقه بندی استفاده می شود، که در آن اکثریت رای گرفته می شود، به عنوان اجرا می شود RandomForestClassifier.
با داشتن قطار و مجموعه تست، می توانیم import را RandomForestClassifier کلاس و ایجاد مدل. برای شروع، بیایید با تنظیم، یک جنگل با سه درخت ایجاد کنیم n_estimators پارامتر به عنوان 3، و با داشتن هر درخت سه سطح، با تنظیم max_depthبه 2:
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=3,
max_depth=2,
random_state=SEED)
توجه داشته باشید: مقدار پیش فرض برای n_estimators است 100. این قدرت پیشبینی و تعمیم مجموعه را افزایش میدهد، اما ما یک مجموعه کوچکتر ایجاد میکنیم تا تجسم و بازرسی آن را آسانتر کنیم. فقط با 3 درخت – می توانیم آنها را تجسم و بررسی کنیم به صورت دستی برای ایجاد بیشتر شهود خود از هر دو درختان و وابستگی مشترک آنها. همین امر برای max_depth، که است None، به این معنی که درختان می توانند عمیق تر و عمیق تر شوند تا داده ها را در صورت نیاز مطابقت دهند.
برای تطبیق مدل در اطراف داده ها – ما آن را صدا می کنیم fit() روش، عبور در ویژگی ها و برچسب های آموزشی:
rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
اکنون میتوانیم برچسبهای پیشبینیشده را با برچسبهای واقعی مقایسه کنیم تا ارزیابی کنیم که مدل چقدر خوب عمل کرده است! قبل از ارزیابی مدل، اجازه دهید نگاهی به مجموعه بیاندازیم.
برای نگاهی عمیق تر به مدل، می توانیم هر یک از درختان و روش تقسیم داده ها را تجسم کنیم. این را می توان با استفاده از tree ماژول ساخته شده در Scikit-Learn، و سپس حلقه زدن از طریق هر یک از برآوردگرهای مجموعه:
from sklearn import tree
features = X.columns.values
classes = ('0', '1', '2')
for estimator in rfc.estimators_:
print(estimator)
plt.figure(figsize=(12,6))
tree.plot_tree(estimator,
feature_names=features,
class_names=classes,
fontsize=8,
filled=True,
rounded=True)
plt.show()
کد بالا نمودارهای درختی را نمایش می دهد:



به تفاوت این سه درخت توجه کنید. اولین مورد با شروع می شود BS ویژگی، دوم با DiastolicBP، و سوم با BS از نو. اگر چه سومی به تعداد متفاوتی از نمونه ها نگاه می کند. در شاخه سمت راست، دو درخت اول نیز تصمیم می گیرند از آن استفاده کنند Age در سطح برگ، در حالی که درخت سوم به پایان می رسد BS ویژگی. تنها با سه تخمینگر، واضح است که چگونه افزایش مقیاس، نمایشی غنی و متنوع از دانش را ارائه میدهد که میتواند با موفقیت در یک مدل بسیار دقیق ترکیب شود.
هر چه تعداد درختان در جنگل بیشتر باشد، مدل می تواند متنوع تر باشد. با این حال، مانند بسیاری از درختان، بازدهی کاهش می یابد روی یک زیرمجموعه تصادفی از ویژگی ها، کمی درختان مشابه وجود خواهد داشت که تنوع زیادی در مجموعه ارائه نمی دهند و شروع به داشتن می کنند. قدرت رای بیش از حد و گروه را کج کنید تا بیش از حد مناسب باشد روی مجموعه داده آموزشی، به تعمیم مجموعه اعتبار سنجی آسیب می رساند.
قبلاً فرضیه ای در مورد داشتن درختان بیشتر و اینکه چگونه می تواند نتایج مدل را بهبود بخشد، وجود داشت. بیایید نگاهی به نتایج بیندازیم، یک مدل جدید تولید کنیم و ببینیم آیا این فرضیه وجود دارد یا خیر!
ارزیابی RandomForestClassifier
Scikit-Learn ایجاد خطوط پایه را با ارائه a آسان می کند DummyClassifier، که پیش بینی ها را خروجی می دهد بدون استفاده از ویژگی های ورودی (خروجی های کاملا تصادفی). اگر مدل شما بهتر از DummyClassifier، مقداری یادگیری اتفاق می افتد! برای به حداکثر رساندن یادگیری – می توانید با استفاده از a به طور خودکار ابرپارامترهای مختلف را آزمایش کنید RandomizedSearchCV یا GridSearchCV. علاوه بر داشتن یک خط مبنا، می توانید عملکرد مدل خود را از لنز چندین معیار ارزیابی کنید.
برخی از معیارهای طبقه بندی سنتی که می توانند برای ارزیابی الگوریتم استفاده شوند عبارتند از: دقت، یادآوری، امتیاز f1، دقت و ماتریس سردرگمی. در اینجا یک توضیح مختصر است روی هر یک از آنها:
- دقت، درستی: وقتی هدف ما این است که بفهمیم چه مقادیر پیشبینی درستی توسط طبقهبندیکننده ما صحیح در نظر گرفته شده است. دقت آن مقادیر مثبت واقعی را بر نمونه هایی که به عنوان مثبت پیش بینی شده بودند تقسیم می کند.
$$
دقت = \frac{\text{موارد مثبت واقعی}}{\text{موارد مثبت واقعی} + \text{مورد مثبت نادرست}}
$$
- به خاطر آوردن: معمولاً همراه با دقت محاسبه می شود تا بفهمیم چه تعداد از مثبت های واقعی توسط طبقه بندی کننده ما شناسایی شده اند. فراخوان با تقسیم مثبت های واقعی بر هر چیزی که باید مثبت پیش بینی می شد محاسبه می شود.
$$
recall = \frac{\text{مورد مثبت واقعی}}{\text{مورد مثبت واقعی} + \text{منفی های غلط}}
$$
- امتیاز F1: متعادل است یا میانگین هارمونیک دقت و یادآوری کمترین مقدار 0 و بیشترین مقدار 1 است. When
f1-scoreبرابر با 1 است، به این معنی است که همه کلاس ها به درستی پیش بینی شده اند – این یک امتیاز بسیار سخت برای به دست آوردن با داده های واقعی است (تقریبا همیشه استثنا وجود دارد).
$$
\text{f1-score} = 2* \frac{\text{precision} * \text{recall}}{\text{precision} + \text{recal}}
$$
-
ماتریس سردرگمی: زمانی که باید بدانیم چه مقدار از نمونه ها را درست یا غلط گرفته ایم هر کلاس. مقادیری که درست و به درستی پیش بینی شده بودند نامیده می شوند نکات مثبت واقعیمواردی که مثبت پیش بینی شده بودند اما مثبت نبودند نامیده می شوند مثبت کاذب. همان نامگذاری از منفی های واقعی و منفی های کاذب برای مقادیر منفی استفاده می شود.
-
دقت: تشریح می کند که طبقه بندی کننده ما چند پیش بینی درست انجام داده است. کمترین مقدار دقت 0 و بیشترین مقدار 1 است. این مقدار معمولاً در 100 ضرب می شود تا یک درصد بدست آید:
$$
دقت = \frac{\text{تعداد پیشبینیهای صحیح}}{\text{تعداد کل پیشبینیها}}
$$
توجه داشته باشید: دستیابی به دقت 100% عملا غیرممکن است روی هر داده واقعی که می خواهید یادگیری ماشینی را در آن اعمال کنید. اگر یک طبقهبندی کننده دقت 100% یا حتی یک نتیجه نزدیک به 100% مشاهده کردید – شک داشته باشید و ارزیابی را انجام دهید. یکی از دلایل رایج این مسائل نشت داده ها (نشت بخشی از تست آموزشی به مجموعه تست، به طور مستقیم یا غیر مستقیم) است. هیچ اتفاق نظری وجود ندارد روی “یک دقت خوب” چیست، در درجه اول به این دلیل که بستگی دارد روی داده های شما – گاهی اوقات، دقت 70٪ بالا خواهد بود! گاهی اوقات، این دقت بسیار پایین خواهد بود. به طور کلیبیش از 70 درصد برای بسیاری از مدل ها کافی است، اما این است روی محقق دامنه برای تعیین.
می توانید اسکریپت زیر را اجرا کنید import کتابخانه های لازم و مشاهده نتایج:
from sklearn.metrics import classification_report, confusion_matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d').set_title('Maternal risks confusion matrix (0 = low risk, 1 = medium risk, 2 = high risk)')
print(classification_report(y_test,y_pred))
خروجی چیزی شبیه به این خواهد بود:
precision recall f1-score support
0 0.53 0.89 0.66 80
1 0.57 0.17 0.26 76
2 0.74 0.72 0.73 47
accuracy 0.58 203
macro avg 0.61 0.59 0.55 203
weighted avg 0.59 0.58 0.53 203

در گزارش طبقه بندی، توجه داشته باشید که فراخوان بالا است، 0.89 برای کلاس 0، هر دو دقت و فراخوان برای کلاس 2، 0.74، 0.72 بالا هستند – و برای کلاس 1، آنها کم هستند، به خصوص فراخوانی 0.17 و دقت 0.57. . رابطه بین فراخوانی و دقت برای هر سه کلاس به صورت جداگانه در تصویر ثبت شده است F1 امتیاز، که میانگین هارمونیک بین یادآوری و دقت است – مدل در حال انجام است باشه برای کلاس 0، برای کلاس 1 نسبتاً بد و برای کلاس 2 مناسب است.
این مدل در هنگام شناسایی بسیار مشکل دارد موارد با خطر متوسط.
دقت بهدستآمده توسط طبقهبندیکننده تصادفی جنگل ما با تنها 3 درخت برابر است 0.58 (58٪) – این بدان معنی است که کمی بیش از نیمی از نتایج را درست می گیرد. این دقت پایینی است و شاید بتوان با افزودن درختان بیشتر آن را بهبود بخشید.
با نگاهی به ماتریس سردرگمی، میتوانیم ببینیم که بیشتر اشتباهات مربوط به طبقهبندی 52 رکورد با خطر متوسط به عنوان کم خطر است، که بینش بیشتری به یادآوری پایین کلاس 1 میدهد. بیماران در معرض خطر
یکی دیگر از مواردی که می توان برای ایجاد بینش بیشتر بررسی کرد این است که طبقه بندی کننده هنگام پیش بینی چه ویژگی هایی را بیشتر در نظر می گیرد. این یک قدم مهم برای برداشتن است سیستم های یادگیری ماشینی قابل توضیحو به شناسایی و کاهش تعصب در مدل ها کمک می کند.
برای دیدن آن، ما می توانیم به feature_importances_ ویژگی طبقه بندی کننده این به ما لیستی از درصدها را می دهد، بنابراین ما نیز می توانیم به آن دسترسی داشته باشیم feature_names_in_ ویژگی برای دریافت نام هر ویژگی، سازماندهی آنها در یک دیتافریم، مرتب کردن آنها از بالاترین به پایین ترین و رسم نتیجه:
features_df = pd.DataFrame({'features': rfc.feature_names_in_, 'importances': rfc.feature_importances_ })
features_df_sorted = features_df.sort_values(by='importances', ascending=False)
g = sns.barplot(data=features_df_sorted, x='importances', y ='features', palette="rocket")
sns.despine(bottom = True, left = True)
g.set_title('Feature importances')
g.set(xlabel=None)
g.set(ylabel=None)
g.set(xticks=())
for value in g.containers:
g.bar_label(value, padding=2)

توجه داشته باشید که چگونه طبقه بندی کننده بیشتر در نظر دارد قند خون، سپس کمی فشار دیاستولیک، دمای بدن و فقط کمی سن برای تصمیم گیری، این ممکن است به خاطر کم مربوط باشد. روی کلاس 1، شاید داده های ریسک متوسط مربوط به ویژگی هایی باشد که مدل چندان مورد توجه قرار نمی گیرد. برای بررسی این موضوع می توانید سعی کنید بیشتر با اهمیت ویژگی ها بازی کنید و ببینید آیا تغییر می کند یا خیر روی مدل بر ویژگیهای مورد استفاده تأثیر میگذارد، همچنین اگر بین برخی از ویژگیها و کلاسهای پیشبینیشده رابطه معناداری وجود داشته باشد.
در نهایت زمان آن رسیده است که یک مدل جدید با درختان بیشتری تولید کنیم تا ببینیم چگونه بر نتایج تأثیر می گذارد. بیایید ایجاد کنیم rfc_ جنگلی با 900 درخت، 8 سطح و همان دانه. آیا نتایج بهبود خواهد یافت؟
rfc_ = RandomForestClassifier(n_estimators=900,
max_depth=7,
random_state=SEED)
rfc_.fit(X_train, y_train)
y_pred = rfc_.predict(X_test)
محاسبه و نمایش معیارها:
cm_ = confusion_matrix(y_test, y_pred)
sns.heatmap(cm_, annot=True, fmt='d').set_title('Maternal risks confusion matrix (0 = low risk, 1 = medium risk, 2 = high risk) for 900 trees with 8 levels')
print(classification_report(y_test,y_pred))
این خروجی:
precision recall f1-score support
0 0.68 0.86 0.76 80
1 0.75 0.58 0.65 76
2 0.90 0.81 0.85 47
accuracy 0.74 203
macro avg 0.78 0.75 0.75 203
weighted avg 0.76 0.74 0.74 203

این نشان می دهد که چگونه افزودن درختان بیشتر و درختان تخصصی تر (سطوح بالاتر)، معیارهای ما را بهبود بخشیده است. ما هنوز فراخوانی کمی برای کلاس 1 داریم، اما دقت در حال حاضر 74٪ است. امتیاز F1 هنگام طبقهبندی موارد پرخطر 0.85 است، به این معنی که در مقایسه با 0.73 در مدل قبلی، موارد پرخطر اکنون راحتتر شناسایی میشوند!
در یک پروژه روزمره، شناسایی موارد پرخطر، به عنوان مثال با معیاری مشابه با دقت، که به عنوان نیز شناخته میشود، ممکن است مهمتر باشد. حساسیت در آمار سعی کنید برخی از پارامترهای مدل را تغییر دهید و نتایج را مشاهده کنید.
تا به حال، ما به درک کلی از روش استفاده از جنگل تصادفی برای طبقه بندی داده ها دست یافته ایم – در بخش بعدی، می توانیم از همان مجموعه داده به روشی متفاوت استفاده کنیم تا ببینیم چگونه همان مدل مقادیر را با رگرسیون پیش بینی می کند.
استفاده از جنگل های تصادفی برای رگرسیون
در این بخش روش استفاده از الگوریتم جنگل تصادفی را برای حل مسائل رگرسیون با استفاده از Scikit-Learn مطالعه خواهیم کرد. مراحل انجام شده برای پیاده سازی این الگوریتم تقریباً مشابه مراحل انجام شده برای طبقه بندی است، علاوه بر نوع مدل، و نوع داده های پیش بینی شده – که اکنون مقادیر پیوسته خواهند بود – تنها یک تفاوت در آماده سازی داده ها وجود دارد.
از آنجایی که رگرسیون برای مقادیر عددی – بیایید یک مقدار عددی را از مجموعه داده انتخاب کنیم. ما دیدیم که قند خون در طبقه بندی مهم بود، بنابراین باید بر اساس آن قابل پیش بینی باشد روی سایر ویژگی ها (از آنجایی که اگر با برخی از ویژگی ها مرتبط باشد، آن ویژگی نیز با آن ارتباط دارد).
پس از آنچه برای طبقه بندی انجام داده ایم، ابتدا اجازه دهید import کتابخانه ها و همان مجموعه داده اگر قبلاً این کار را برای مدل طبقه بندی انجام داده اید، می توانید از این قسمت صرف نظر کنید و مستقیماً به تهیه داده ها برای آموزش بروید.
واردات کتابخانه ها و داده ها
import pandas as pd
import numpy as np
import maplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("../../datasets/random-forest/maternal_health_risk.csv")
پیش پردازش داده برای رگرسیون
این یک کار رگرسیونی است، بنابراین به جای پیشبینی کلاسها، میتوانیم یکی از ستونهای عددی مجموعه داده را پیشبینی کنیم. در این مثال، BS ستون پیش بینی خواهد شد. این یعنی y داده ها شامل خواهد شد داده های قند خون، و X داده ها شامل تمام ویژگی ها به جز قند خون می شود. پس از جداسازی X و y داده ها، می توانیم قطار و مجموعه های آزمایشی را تقسیم کنیم:
from sklearn.model_selection import train_test_split
SEED = 42
y = dataset('BS')
X = dataset.drop(('BS'), axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=SEED)
آموزش RandomForestRegressor
اکنون که مجموعه داده خود را مقیاسبندی کردهایم، زمان آن رسیده است که الگوریتم خود را برای حل این مشکل رگرسیون آموزش دهیم، تا کمی آن را تغییر دهیم – مدلی با 20 درخت در جنگل و هر کدام با 4 سطح ایجاد میکنیم. برای انجام این کار می توانید کد زیر را اجرا کنید:
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=20,
max_depth=3,
random_state=SEED)
rfr.fit(X_train, y_train)
y_pred = rfr.predict(X_test)
شما می توانید جزئیات همه پارامترهای را پیدا کنید RandomForestRegressor در اسناد رسمی.
از آنجایی که ترسیم و مشاهده 20 درخت به زمان و زمان نیاز دارد، میتوانیم اولین مورد را ترسیم کنیم تا تفاوت آن با درخت طبقهبندی را بررسی کنیم:
from sklearn import tree
features = X.columns
first_tree = rfr.estimators_(0)
plt.figure(figsize=(15,6))
tree.plot_tree(first_tree,
feature_names=features,
fontsize=8,
filled=True,
rounded=True);

توجه داشته باشید که درخت رگرسیون از قبل دارای یک مقدار تخصیص داده شده به داده هایی است که می افتد روی هر یک node. این مقادیری هستند که هنگام ترکیب 20 درخت به طور میانگین محاسبه می شوند. به دنبال کارهایی که با طبقهبندی انجام دادیم، میتوانید اهمیت ویژگیها را نیز ترسیم کنید تا ببینید مدل رگرسیون چه متغیرهایی را هنگام محاسبه مقادیر بیشتر در نظر میگیرد.
وقت آن است که هنگام حل یک مشکل یادگیری ماشینی به مرحله آخر و نهایی بروید و عملکرد الگوریتم را ارزیابی کنید!
ارزیابی RandomForestRegressor
برای مشکلات رگرسیون، معیارهای مورد استفاده برای ارزیابی یک الگوریتم عبارتند از میانگین خطای مطلق (MAE)، میانگین مربع خطا (MSE) و root میانگین مربعات خطا (RMSE).
- میانگین خطای مطلق (MAE): وقتی مقادیر پیش بینی شده را از مقادیر واقعی کم می کنیم، خطاها را به دست می آوریم، مقادیر مطلق آن خطاها را جمع می کنیم و میانگین آنها را به دست می آوریم. این متریک تصوری از خطای کلی برای هر پیشبینی مدل ارائه میدهد، هرچه کوچکتر (نزدیک به صفر) بهتر باشد.
$$
mae = (\frac{1}{n})\sum_{i=1}^{n}\left | واقعی – پیش بینی شده \right |
$$
توجه داشته باشید: همچنین ممکن است با y و ŷ علامت گذاری در معادلات این y اشاره به مقادیر واقعی و ŷ به مقادیر پیش بینی شده
- میانگین مربعات خطا (MSE): شبیه به متریک MAE است، اما مقادیر مطلق خطاها را مربع می کند. همچنین، مانند MAE، هرچه کوچکتر یا نزدیکتر به 0 باشد، بهتر است. مقدار MSE مربع است تا خطاهای بزرگ حتی بزرگتر شود. یکی از مواردی که باید به آن دقت کرد، این است که معمولاً به دلیل اندازه مقادیر آن و این واقعیت که آنها در مقیاس یکسانی از داده ها نیستند، تفسیر آن سخت است.
$$
mse = \sum_{i=1}^{D}(واقعی – پیش بینی شده)^2
$$
- ریشه میانگین مربعات خطا (RMSE): سعی می کند با گرفتن مربع، مشکل تفسیر مطرح شده در MSE را حل کند root از مقدار نهایی آن، به طوری که آن را به همان واحدهای داده کاهش دهیم. وقتی نیاز به نمایش یا نشان دادن ارزش واقعی داده ها با خطا داریم، تفسیر آسان تر و خوب است. این نشان میدهد که دادهها چقدر ممکن است متفاوت باشند، بنابراین، اگر RMSE 4.35 داشته باشیم، مدل ما میتواند خطا داشته باشد یا به این دلیل که 4.35 را به مقدار واقعی اضافه کرده است یا برای رسیدن به مقدار واقعی به 4.35 نیاز دارد. هرچه به 0 نزدیکتر باشد، بهتر است.
$$
rmse = \sqrt{ \sum_{i=1}^{D}(واقعی – پیش بینی شده)^2}
$$
ما می توانیم از هر یک از این سه معیار استفاده کنیم مقایسه کنید مدل ها (در صورت نیاز به انتخاب یکی). همچنین میتوانیم همان مدل رگرسیون را با مقادیر آرگومانهای مختلف یا با دادههای مختلف مقایسه کنیم و سپس معیارهای ارزیابی را در نظر بگیریم. این به عنوان شناخته شده است تنظیم هایپرپارامتر – تنظیم فراپارامترهایی که بر الگوریتم یادگیری تأثیر می گذارند و مشاهده نتایج.
هنگام انتخاب بین مدل ها، مدل هایی که کمترین خطا را دارند معمولا عملکرد بهتری دارند. هنگام پایش مدلها، اگر معیارها بدتر میشد، نسخه قبلی مدل بهتر بود، یا تغییرات قابلتوجهی در دادهها وجود داشت که مدل بدتر از عملکردش بود.
برای یافتن این مقادیر می توانید کد زیر را وارد کنید:
from sklearn.metrics import mean_absolute_error, mean_squared_error
print('Mean Absolute Error:', mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(mean_squared_error(y_test, y_pred)))
خروجی باید این باشد:
Mean Absolute Error: 1.127893702896059
Mean Squared Error: 3.0802988503933326
Root Mean Squared Error: 1.755078018320933
با 20 درخت، root میانگین مربعات خطا 1.75 است که کم است، اما با این وجود – با افزایش تعداد درختان و آزمایش با سایر پارامترها، این خطا احتمالاً می تواند حتی کوچکتر شود.
مزایای استفاده از جنگل تصادفی
مانند هر الگوریتم دیگری، استفاده از آن مزایا و معایبی دارد. در دو بخش بعدی نگاهی به مزایا و معایب استفاده از جنگل تصادفی برای طبقهبندی و رگرسیون خواهیم داشت.
- الگوریتم جنگل تصادفی مغرضانه نیست، زیرا چندین درخت وجود دارد و هر درخت آموزش دیده است. روی زیر مجموعه ای تصادفی از داده ها اساساً الگوریتم جنگل تصادفی متکی است روی قدرت “جمعیت”؛ بنابراین درجه کلی سوگیری الگوریتم کاهش می یابد.
- این الگوریتم بسیار پایدار است. حتی اگر یک نقطه داده جدید در مجموعه داده معرفی شود، الگوریتم کلی تأثیر چندانی نمیگذارد، زیرا دادههای جدید ممکن است روی یک درخت تأثیر بگذارند، اما تأثیرگذاری بر همه درختها برای آن بسیار سخت است.
- الگوریتم جنگل تصادفی زمانی به خوبی کار می کند که هم ویژگی های دسته بندی و هم ویژگی های عددی داشته باشید.
- الگوریتم جنگل تصادفی همچنین زمانی به خوبی کار می کند که داده ها دارای مقادیر گم شده باشند یا مقیاس بندی نشده باشند.
معایب استفاده از جنگل تصادفی
- عیب اصلی جنگل های تصادفی در پیچیدگی آنها نهفته است. آنها به منابع محاسباتی بسیار بیشتری نیاز دارند، زیرا تعداد زیادی درخت تصمیم به هم پیوسته اند، هنگام آموزش مجموعه های بزرگ. اگرچه – با سخت افزار مدرن، آموزش حتی یک جنگل تصادفی بزرگ زمان زیادی نمی برد.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-02 18:47:03
