از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
نرخ یادگیری یک فراپارامتر مهم در شبکه های یادگیری عمیق است – و مستقیماً آن را دیکته می کند درجه که بهروزرسانیهایی برای وزنها انجام میشود، که تخمین زده میشود برخی از عملکردهای تلفات داده شده را به حداقل برساند. در SGD:
$$
weight_{t+1} = weight_t – lr * \frac{derror}{dweight_t}
$$
با نرخ یادگیری از 0، وزن به روز شده به خود بازگشته است – وزنتی. نرخ یادگیری عملاً کلیدی است که میتوانیم آن را برای فعال یا غیرفعال کردن یادگیری بچرخانیم، و با کنترل مستقیم درجه بهروزرسانی وزن، تأثیر عمدهای بر میزان یادگیری در حال وقوع دارد.
بهینه سازهای مختلف از نرخ های یادگیری متفاوت استفاده می کنند – اما مفهوم اساسی یکسان باقی می ماند. نیازی به گفتن نیست که میزان یادگیری موضوع بسیاری از مطالعات، مقالات و معیارهای پزشکان بوده است.
به طور کلی، تقریباً همه موافقند که نرخ یادگیری ثابت آن را کاهش نمیدهد، و نوعی کاهش نرخ یادگیری در اکثر تکنیکهایی اتفاق میافتد که میزان یادگیری را در طول تمرین تنظیم میکنند – چه یکنواخت، کسینوس، مثلثی یا انواع دیگر. کاهش.
تکنیکی که در سالهای اخیر جای پای خود را پیدا کرده است گرم کردن میزان یادگیری، که می تواند عملاً با هر تکنیک کاهش دیگری جفت شود.
گرم کردن نرخ یادگیری
ایده پشت گرم کردن نرخ یادگیری ساده است. در مراحل اولیه تمرین – وزنه ها از حالت ایده آل خود فاصله دارند. این به معنای به روز رسانی های بزرگ در سراسر صفحه است که می تواند به عنوان “اصلاحات بیش از حد” برای هر وزن در نظر گرفته شود – که در آن به روز رسانی شدید وزنه دیگر ممکن است به روز رسانی وزن دیگری را نفی کند و مراحل اولیه تمرین را ناپایدارتر کند.
این تغییرات برطرف میشوند، اما میتوان با داشتن یک نرخ یادگیری کوچک برای شروع، رسیدن به وضعیت پایینتر از بهینهتر با ثباتتر، و سپس اعمال نرخ یادگیری بزرگتر از آنها جلوگیری کرد. میتوانید بهجای ضربه زدن با آنها، شبکه را بهنوعی بهروزرسانی کنید.
این گرم کردن نرخ یادگیری است! شروع با نرخ یادگیری کم (یا 0) و افزایش به نرخ یادگیری شروع (چیزی که به هر حال با آن شروع می کنید). این افزایش می تواند هر تابعی را واقعاً دنبال کند، اما معمولاً خطی است.
پس از رسیدن به نرخ اولیه، برنامه های دیگری مانند واپاشی کسینوس، کاهش خطی و غیره را می توان برای کاهش تدریجی نرخ تا پایان تمرین اعمال کرد. گرم کردن میزان یادگیری معمولاً بخشی از یک برنامه دو زمانبندی است، جایی که گرم کردن LR اولین بار است، در حالی که برنامه دیگری پس از رسیدن نرخ به نقطه شروع انجام میشود.
در این راهنما، ما یک گرم کردن نرخ یادگیری را در Keras/TensorFlow به صورت یک اجرا می کنیم keras.optimizers.schedules.LearningRateSchedule زیر کلاس و keras.callbacks.Callback پاسخ به تماس نرخ یادگیری از افزایش می یابد 0 به target_lr و واپاشی کسینوس را اعمال کنید، زیرا این یک برنامه ثانویه بسیار رایج است. طبق معمول، Keras پیادهسازی راهحلهای انعطافپذیر را به روشهای مختلف و ارسال آنها با شبکه شما ساده میکند.
توجه داشته باشید: پیاده سازی عمومی و الهام گرفته شده است اجرای کراس تونی از ترفندهای ذکر شده در “مجموعه ای از ترفندها برای طبقه بندی تصویر با شبکه های عصبی کانولوشن”.
نرخ یادگیری با Keras Callbacks
سادهترین راه برای پیادهسازی هر زمانبندی نرخ یادگیری، ایجاد تابعی است که از آن استفاده میکند lr پارامتر (float32)، آن را از طریق تغییر شکل می دهد و آن را برمی گرداند. سپس این تابع ارسال می شود روی به LearningRateScheduler تماس برگشتی، که تابع را برای نرخ یادگیری اعمال می کند.
در حال حاضر tf.keras.callbacks.LearningRateScheduler() عدد دوره را به تابعی که برای محاسبه نرخ یادگیری استفاده می کند، منتقل می کند، که بسیار درشت است. LR Warmup باید انجام شود روی هر یک گام (دسته ای)، نه دوره، بنابراین ما باید a را استخراج کنیم global_step (در همه ادوار) برای محاسبه نرخ یادگیری به جای آن، و زیر کلاس Callback کلاس برای ایجاد یک فراخوان سفارشی به جای ارسال تابع، زیرا باید در آرگومان ها ارسال کنیم روی هر فراخوانی، که در هنگام انتقال تابع غیرممکن است:
def func():
return ...
keras.callbacks.LearningRateScheduler(func)
این رویکرد زمانی مطلوب است که سطح بالایی از سفارشیسازی را نمیخواهید و نمیخواهید با روشی که Keras رفتار میکند تداخل داشته باشید. lrو به خصوص اگر میخواهید از تماسهای برگشتی مانند ReduceLROnPlateau() از آنجایی که فقط می تواند با یک float-based کار کند lr. بیایید یک گرم کردن نرخ یادگیری را با استفاده از یک فراخوان Keras، با یک تابع راحت شروع کنیم:
def lr_warmup_cosine_decay(global_step,
warmup_steps,
hold = 0,
total_steps=0,
start_lr=0.0,
target_lr=1e-3):
learning_rate = 0.5 * target_lr * (1 + np.cos(np.pi * (global_step - warmup_steps - hold) / float(total_steps - warmup_steps - hold)))
warmup_lr = target_lr * (global_step / warmup_steps)
if hold > 0:
learning_rate = np.where(global_step > warmup_steps + hold,
learning_rate, target_lr)
learning_rate = np.where(global_step < warmup_steps, warmup_lr, learning_rate)
return learning_rate
در هر مرحله، نرخ یادگیری و سرعت یادگیری گرم کردن (هر دو عنصر برنامه) را با توجه به start_lr و target_lr. start_lr معمولا در شروع خواهد شد 0.0، در حالی که target_lr بستگی دارد روی شبکه و بهینه ساز شما – 1e-3 ممکن است پیشفرض خوبی نباشد، بنابراین هنگام فراخوانی روش، مطمئن شوید که هدف خود را برای شروع LR تنظیم کنید.
اگر global_step در آموزش بالاتر از warmup_steps ما تنظیم کرده ایم – از برنامه واپاشی کسینوس LR استفاده می کنیم. اگر نه، به این معنی است که ما هنوز در حال گرم کردن هستیم، بنابراین از گرم کننده LR استفاده می شود. اگر hold آرگومان تنظیم شده است، ما آن را نگه می داریم target_lr برای آن تعداد قدم بعد از گرم کردن و قبل از واپاشی کسینوس. np.where() یک نحو عالی برای این ارائه می دهد:
np.where(condition, value_if_true, value_if_false)
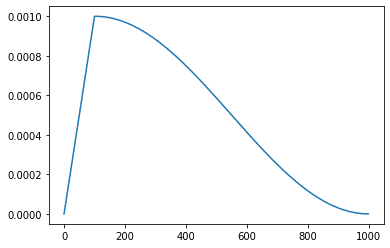
می توانید عملکرد را با موارد زیر تجسم کنید:
steps = np.arange(0, 1000, 1)
lrs = ()
for step in steps:
lrs.append(lr_warmup_cosine_decay(step, total_steps=len(steps), warmup_steps=100, hold=10))
plt.plot(lrs)

اکنون، ما می خواهیم از این تابع به عنوان بخشی از یک فراخوانی استفاده کنیم و مرحله بهینه ساز را به عنوان قسمت عبور دهیم global_step به جای یک عنصر از یک آرایه دلخواه – یا می توانید محاسبات را در کلاس انجام دهید. بیایید زیر کلاس Callback کلاس:
from keras import backend as K
class WarmupCosineDecay(keras.callbacks.Callback):
def __init__(self, total_steps=0, warmup_steps=0, start_lr=0.0, target_lr=1e-3, hold=0):
super(WarmupCosineDecay, self).__init__()
self.start_lr = start_lr
self.hold = hold
self.total_steps = total_steps
self.global_step = 0
self.target_lr = target_lr
self.warmup_steps = warmup_steps
self.lrs = ()
def on_batch_end(self, batch, logs=None):
self.global_step = self.global_step + 1
lr = model.optimizer.lr.numpy()
self.lrs.append(lr)
def on_batch_begin(self, batch, logs=None):
lr = lr_warmup_cosine_decay(global_step=self.global_step,
total_steps=self.total_steps,
warmup_steps=self.warmup_steps,
start_lr=self.start_lr,
target_lr=self.target_lr,
hold=self.hold)
K.set_value(self.model.optimizer.lr, lr)
ابتدا سازنده کلاس را تعریف می کنیم و فیلدهای آن را پیگیری می کنیم. در هر دسته ای که به پایان می رسد، گام جهانی را افزایش می دهیم، LR فعلی را یادداشت می کنیم و آن را به لیست LR ها تا کنون اضافه می کنیم. در ابتدای هر دسته – ما LR را با استفاده از آن محاسبه می کنیم lr_warmup_cosine_decay() عملکرد و LR را به عنوان LR فعلی بهینه ساز تنظیم کنید. این کار با backend انجام می شود set_value().
با انجام این کار – کافیست کل مراحل (طول/اندازه_دسته*دوران) را محاسبه کنید و بخشی از آن عدد را برای خود انتخاب کنید. warmup_steps:
total_steps = len(train_set)*config('EPOCHS')
warmup_steps = int(0.05*total_steps)
callback = WarmupCosineDecay(total_steps=total_steps,
warmup_steps=warmup_steps,
hold=int(warmup_steps/2),
start_lr=0.0,
target_lr=1e-3)
در نهایت، مدل خود را بسازید و پاسخ تماس را در آن ارائه کنید fit() زنگ زدن:
model = keras.applications.EfficientNetV2B0(weights=None,
classes=n_classes,
input_shape=(224, 224, 3))
model.compile(loss="sparse_categorical_crossentropy",
optimizer='adam',
jit_compile=True,
metrics=('accuracy'))
در پایان آموزش، می توانید LR های تغییر یافته را از طریق:
lrs = callback.lrs
plt.plot(lrs)

اگر تاریخچه یک مدل آموزش دیده با و بدون گرم کردن LR را ترسیم کنید – تفاوت مشخصی در پایداری تمرین مشاهده خواهید کرد:

نرخ یادگیری با زیر کلاس LearningRateSchedule
یک جایگزین برای ایجاد یک تماس، ایجاد یک است LearningRateSchedule زیر کلاس، که LR را دستکاری نمی کند – آن را جایگزین می کند. این رویکرد به شما امکان میدهد کمی بیشتر به پشتیبان Keras/TensorFlow وارد شوید، اما وقتی استفاده میشود، نمیتوان آن را با سایر تماسهای مرتبط با LR ترکیب کرد، مانند ReduceLROnPlateau()، که با LR ها به عنوان اعداد ممیز شناور سروکار دارد.
علاوه بر این، استفاده از کلاس فرعی از شما میخواهد که آن را سریالسازی کنید (overload get_config()) به عنوان بخشی از مدل، اگر می خواهید وزن مدل را ذخیره کنید. نکته دیگری که باید به آن توجه کرد این است که کلاس انتظار دارد به طور انحصاری با آن کار کند tf.Tensorس خوشبختانه، تنها تفاوت در روش کار ما تماس خواهد بود tf.func() بجای np.func() از آنجایی که API های TensorFlow و NumPy به طرز شگفت انگیزی مشابه و سازگار هستند.
بیایید راحتی را بازنویسی کنیم lr_warmup_cosine_decay() تابعی برای استفاده از عملیات TensorFlow به جای آن:
def lr_warmup_cosine_decay(global_step,
warmup_steps,
hold = 0,
total_steps=0,
start_lr=0.0,
target_lr=1e-3):
learning_rate = 0.5 * target_lr * (1 + tf.cos(tf.constant(np.pi) * (global_step - warmup_steps - hold) / float(total_steps - warmup_steps - hold)))
warmup_lr = target_lr * (global_step / warmup_steps)
if hold > 0:
learning_rate = tf.where(global_step > warmup_steps + hold,
learning_rate, target_lr)
learning_rate = tf.where(global_step < warmup_steps, warmup_lr, learning_rate)
return learning_rate
با تابع convenience، میتوانیم زیر کلاسبندی کنیم LearningRateSchedule کلاس روی هر کدام __call__() (دسته ای)، LR را با استفاده از تابع محاسبه می کنیم و آن را برمی گردانیم. شما به طور طبیعی می توانید محاسبه را در کلاس زیر کلاس نیز بسته بندی کنید.
نحو تمیزتر از Callback زیر کلاس، در درجه اول به این دلیل که ما به آن دسترسی داریم step میدان، به جای پیگیری آن روی خودمان است، اما کار با ویژگی های کلاس را نیز تا حدودی سخت می کند – به ویژه، استخراج lr از tf.Tensor() به هر نوع دیگری برای پیگیری در یک لیست. این را می توان با اجرای در حالت مشتاق از نظر فنی دور زد، اما برای پیگیری LR برای اهداف اشکال زدایی باعث ناراحتی می شود و بهتر است از آن اجتناب شود:
class WarmUpCosineDecay(keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, start_lr, target_lr, warmup_steps, total_steps, hold):
super().__init__()
self.start_lr = start_lr
self.target_lr = target_lr
self.warmup_steps = warmup_steps
self.total_steps = total_steps
self.hold = hold
def __call__(self, step):
lr = lr_warmup_cosine_decay(global_step=step,
total_steps=self.total_steps,
warmup_steps=self.warmup_steps,
start_lr=self.start_lr,
target_lr=self.target_lr,
hold=self.hold)
return tf.where(
step > self.total_steps, 0.0, lr, name="learning_rate"
)
پارامترها یکسان هستند و می توان آنها را به همان روش قبلی محاسبه کرد:
total_steps = len(train_set)*config('EPOCHS')
warmup_steps = int(0.05*total_steps)
schedule = WarmUpCosineDecay(start_lr=0.0, target_lr=1e-3, warmup_steps=warmup_steps, total_steps=total_steps, hold=warmup_steps)
و خط لوله آموزشی فقط از این جهت متفاوت است که LR بهینه ساز را روی مقدار تنظیم می کنیم schedule:
model = keras.applications.EfficientNetV2B0(weights=None,
classes=n_classes,
input_shape=(224, 224, 3))
model.compile(loss="sparse_categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(learning_rate=schedule),
jit_compile=True,
metrics=('accuracy'))
history3 = model.fit(train_set,
epochs = config('EPOCHS'),
validation_data=valid_set)
اگر می خواهید مدل را ذخیره کنید، WarmupCosineDecay برنامه باید نادیده گرفته شود get_config() روش:
def get_config(self):
config = {
'start_lr': self.start_lr,
'target_lr': self.target_lr,
'warmup_steps': self.warmup_steps,
'total_steps': self.total_steps,
'hold': self.hold
}
return config
در نهایت، هنگام بارگذاری مدل، باید a را پاس کنید WarmupCosineDecay به عنوان یک شی سفارشی:
model = keras.models.load_model('weights.h5',
custom_objects={'WarmupCosineDecay', WarmupCosineDecay})
نتیجه
در این راهنما، نگاهی به شهود پشت گرم کردن نرخ یادگیری انداختهایم – یک تکنیک رایج برای دستکاری نرخ یادگیری در حین آموزش شبکههای عصبی.
ما گرم کردن نرخ یادگیری را با واپاشی کسینوس، رایجترین نوع کاهش LR همراه با گرم کردن، اجرا کردهایم. شما میتوانید هر تابع دیگری را برای کاهش پیادهسازی کنید، یا اصلاً نرخ یادگیری را کاهش ندهید – آن را به سایر فراخوانها واگذار کنید ReduceLROnPlateau(). ما گرم کردن نرخ یادگیری را به عنوان یک Keras Callback، و همچنین یک برنامه بهینه ساز Keras پیاده سازی کرده ایم و نرخ یادگیری را در طول دوره ها ترسیم کرده ایم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-03 11:14:03
