از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
این K-نزدیکترین همسایه (KNN) الگوریتم نوعی از الگوریتم یادگیری ماشینی نظارت شده است که برای طبقه بندی، رگرسیون و همچنین تشخیص موارد دور از دسترس استفاده می شود. اجرای آن در ابتدایی ترین شکل آن بسیار آسان است اما می تواند کارهای نسبتاً پیچیده ای را انجام دهد. این یک الگوریتم یادگیری تنبل است زیرا فاز آموزشی تخصصی ندارد. در عوض، از تمام داده ها برای آموزش استفاده می کند، در حالی که یک نقطه یا نمونه داده جدید را طبقه بندی (یا پسرفت) می کند.
KNN یک است الگوریتم یادگیری ناپارامتریک، به این معنی که چیزی در مورد داده های اساسی فرض نمی کند. این یک ویژگی بسیار مفید است زیرا بیشتر دادههای دنیای واقعی واقعاً از هیچ فرض نظری پیروی نمیکنند، مانند جداییپذیری خطی، توزیع یکنواخت و غیره.
در این راهنما، خواهیم دید که چگونه KNN را می توان با کتابخانه Scikit-Learn پایتون پیاده سازی کرد. قبل از آن، ابتدا چگونگی استفاده از KNN و توضیح تئوری پشت آن را بررسی خواهیم کرد. پس از آن، ما نگاهی به مجموعه داده مسکن کالیفرنیا ما برای نشان دادن الگوریتم KNN و چندین تغییر آن استفاده خواهیم کرد. اول از همه، روش پیادهسازی الگوریتم KNN برای رگرسیون را بررسی میکنیم، و به دنبال آن پیادهسازی طبقهبندی KNN و تشخیص پرت را خواهیم داشت. در پایان با برخی از مزایا و معایب الگوریتم نتیجه گیری می کنیم.
چه زمانی باید از KNN استفاده کنید؟
فرض کنید میخواهید یک آپارتمان اجاره کنید و اخیراً متوجه شدهاید که همسایه دوستتان ممکن است آپارتمان او را ظرف ۲ هفته اجاره دهد. از آنجایی که آپارتمان نیست روی هنوز یک وب سایت اجاره ای، چگونه می توانید ارزش اجاره آن را تخمین بزنید؟
فرض کنید دوست شما 1200 دلار اجاره می دهد. ارزش اجاره شما ممکن است در حدود این عدد باشد، اما آپارتمان ها دقیقاً یکسان نیستند (جهت، مساحت، کیفیت مبلمان و غیره)، بنابراین، خوب است که داده های بیشتری داشته باشید. روی آپارتمان های دیگر
با پرس و جو از سایر همسایه ها و نگاهی به آپارتمان های همان ساختمان که لیست شده بود روی یک وب سایت اجاره ای، نزدیک ترین سه اجاره آپارتمان همسایه 1200 دلار، 1210 دلار، 1210 دلار و 1215 دلار است. آن آپارتمان ها هستند روی همان بلوک و طبقه آپارتمان دوست شما.
آپارتمان های دیگری که دورتر هستند، روی در همان طبقه، اما در یک بلوک متفاوت، اجاره بهای 1400 دلار، 1430 دلار، 1500 دلار و 1470 دلار وجود دارد. به نظر می رسد به دلیل داشتن نور بیشتر از خورشید در عصر گران تر هستند.
با توجه به نزدیکی آپارتمان، به نظر می رسد اجاره شما حدود 1210 دلار باشد. این ایده کلی از آنچه است K-نزدیکترین همسایگان (KNN) الگوریتم انجام می دهد! بر اساس داده های جدید طبقه بندی یا پسرفت می کند روی نزدیکی آن به داده های موجود
مثال را به تئوری تبدیل کنید
هنگامی که ارزش تخمینی یک عدد پیوسته است، مانند ارزش اجاره، KNN برای آن استفاده می شود پسرفت. اما ما همچنین میتوانیم آپارتمانها را به دستههای مبتنی بر تقسیم کنیم روی برای مثال حداقل و حداکثر اجاره. هنگامی که مقدار گسسته است، آن را به یک دسته تبدیل می کند، KNN برای آن استفاده می شود طبقه بندی.
همچنین این امکان وجود دارد که تخمین بزنیم کدام همسایه ها آنقدر با دیگران تفاوت دارند که احتمالاً از پرداخت اجاره منصرف می شوند. این همانند تشخیص اینکه کدام نقاط داده آنقدر دور هستند که در هیچ مقدار یا دسته ای قرار نمی گیرند، زمانی که این اتفاق می افتد، از KNN برای تشخیص بیرونی.
در مثال ما، ما قبلاً اجاره هر آپارتمان را میدانستیم، به این معنی که دادههای ما برچسبگذاری شده بودند. KNN از دادههای برچسبگذاریشده قبلی استفاده میکند، که باعث میشود یک الگوریتم یادگیری نظارت شده.
پیادهسازی KNN در ابتداییترین شکل آن بسیار آسان است، و در عین حال وظایف کاملاً پیچیدهای را انجام میدهد، طبقهبندی، رگرسیون، یا تشخیص نقاط پرت.
هر بار که یک نقطه جدید به داده ها اضافه می شود، KNN فقط از یک قسمت از داده ها برای تصمیم گیری در مورد مقدار (رگرسیون) یا کلاس (طبقه بندی) آن نقطه اضافه شده استفاده می کند. از آنجایی که لازم نیست دوباره به همه نکات نگاه کند، این باعث می شود که یک الگوریتم یادگیری تنبل.
KNN همچنین هیچ چیزی در مورد ویژگی های داده های زیربنایی فرض نمی کند، انتظار ندارد داده ها در برخی از انواع توزیع، مانند یکنواخت، یا به صورت خطی قابل تفکیک قرار گیرند. این بدان معنی است که یک است الگوریتم یادگیری ناپارامتریک. این یک ویژگی بسیار مفید است زیرا بیشتر داده های دنیای واقعی واقعاً از هیچ فرض نظری پیروی نمی کنند.
تجسم کاربردهای مختلف KNN
همانطور که نشان داده شد، شهود پشت الگوریتم KNN یکی از مستقیم ترین الگوریتم های یادگیری ماشینی تحت نظارت است. الگوریتم ابتدا مقدار را محاسبه می کند فاصله یک نقطه داده جدید به تمام نقاط داده آموزشی دیگر.
توجه داشته باشید: فاصله را می توان به روش های مختلف اندازه گیری کرد. برای نام بردن چند معیار می توانید از فرمول Minkowski، Euclidean، Manhattan، Mahalanobis یا Hamming استفاده کنید. با داده های ابعادی بالا، فاصله اقلیدسی اغلب شروع به شکست می کند (بعد بالا… عجیب است)، و به جای آن از فاصله منهتن استفاده می شود.
پس از محاسبه فاصله، KNN تعدادی از نزدیکترین نقاط داده را انتخاب می کند – 2، 3، 10، یا واقعاً، هر عدد صحیح. این تعداد امتیاز (2، 3، 10، و غیره) برابر است ک در K-Nearest Neighbors!
در مرحله آخر، اگر یک کار رگرسیونی باشد، KNN میانگین وزنی مجموع K-نزدیک ترین نقاط را برای پیش بینی محاسبه می کند. اگر یک کار طبقه بندی باشد، نقطه داده جدید به کلاسی که اکثر K-نزدیک ترین نقاط انتخاب شده به آن تعلق دارند، اختصاص داده می شود.
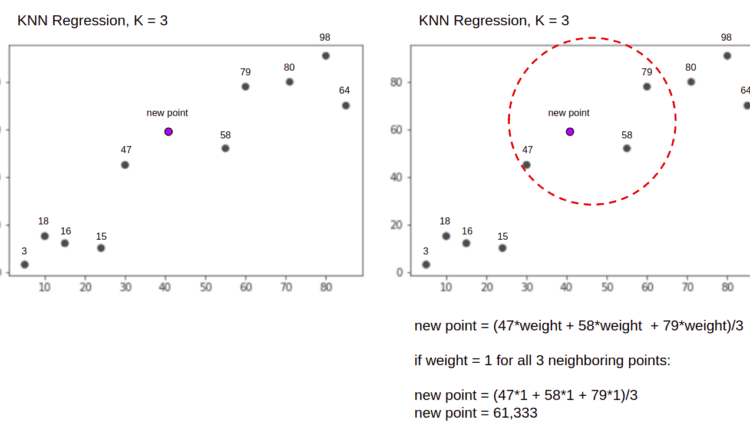
بیایید با کمک یک مثال ساده الگوریتم را در عمل مجسم کنیم. مجموعه داده ای را با دو متغیر و K 3 در نظر بگیرید.
هنگام انجام رگرسیون، وظیفه یافتن مقدار یک نقطه داده جدید است روی میانگین مجموع وزنی 3 نزدیکترین نقطه.
KNN با K = 3، چه زمانی برای رگرسیون استفاده می شود:


الگوریتم KNN با محاسبه فاصله نقطه جدید از تمام نقاط شروع می شود. سپس 3 نقطه با کمترین فاصله تا نقطه جدید را پیدا می کند. این در شکل دوم بالا نشان داده شده است که در آن سه نزدیکترین نقطه، 47، 58، و 79 محاصره شده اند. پس از آن، مجموع وزنی را محاسبه می کند 47، 58 و 79 – در این حالت اوزان برابر با 1 است – ما همه امتیازها را مساوی در نظر می گیریم، اما می توانیم وزن های مختلفی را نیز بر اساس تعیین کنیم. روی فاصله پس از محاسبه جمع وزنی، مقدار امتیاز جدید می باشد 61,33.
و هنگام انجام یک طبقهبندی، وظیفه KNN این است که یک نقطه داده جدید را در قسمت طبقهبندی کند "Purple" یا "Red" کلاس
KNN با K = 3، چه زمانی برای طبقه بندی استفاده می شود:


الگوریتم KNN مانند قبل با محاسبه فاصله نقطه جدید از تمام نقاط، یافتن 3 نزدیکترین نقطه با کمترین فاصله از نقطه جدید شروع می شود و سپس به جای محاسبه عدد، اختصاص می دهد. نقطه جدید به کلاسی که اکثریت سه نقطه نزدیک به آن تعلق دارد، کلاس قرمز. بنابراین نقطه داده جدید به عنوان طبقه بندی می شود "Red".
تشخیص پرت process با هر دو بالا متفاوت است، در هنگام اجرای آن پس از اجرای رگرسیون و طبقه بندی بیشتر در مورد آن صحبت خواهیم کرد.
توجه داشته باشید: کد ارائه شده در این آموزش با موارد زیر اجرا و تست شده است Jupyter notebook.
مجموعه داده های مسکن کالیفرنیا Scikit-Learn
ما قصد داریم از مجموعه داده مسکن کالیفرنیا برای نشان دادن روش عملکرد الگوریتم KNN. مجموعه داده از سرشماری سال 1990 ایالات متحده به دست آمده است. یک ردیف از مجموعه داده سرشماری یک گروه بلوکی را نشان می دهد.
در این بخش، جزئیات مجموعه داده های مسکن کالیفرنیا را بررسی می کنیم، بنابراین می توانید درک بصری از داده هایی که با آنها کار خواهیم کرد به دست آورید. قبل از شروع کار بسیار مهم است که اطلاعات خود را بشناسید روی آی تی.
آ مسدود کردن گروه کوچکترین واحد جغرافیایی است که اداره سرشماری ایالات متحده داده های نمونه را برای آن منتشر می کند. علاوه بر گروه بلوک، اصطلاح دیگری که استفاده میشود، خانوار است، خانوار گروهی از افراد ساکن در یک خانه است.
مجموعه داده از نه ویژگی تشکیل شده است:
MedInc– درآمد متوسط در گروه بلوکیHouseAge– میانه سن خانه در یک گروه بلوکیAveRooms– میانگین تعداد اتاق (ارائه شده برای هر خانوار)AveBedrms– میانگین تعداد اتاق خواب (ارائه شده برای هر خانوار)Population– بلوک جمعیت گروهAveOccup– میانگین تعداد اعضای خانوارLatitude– بلوک عرض جغرافیایی گروهLongitude– طول گروه بلوکMedHouseVal– میانگین ارزش خانه برای مناطق کالیفرنیا (صدها هزار دلار)
مجموعه داده است در حال حاضر بخشی از کتابخانه Scikit-Learn است، ما فقط نیاز داریم import آن را به عنوان یک دیتافریم بارگذاری کنید:
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing(as_frame=True)
df = california_housing.frame
وارد کردن مستقیم داده ها از Scikit-Learn، بیش از ستون ها و اعداد را وارد می کند و شامل توضیحات داده ها به عنوان Bunch شی – بنابراین ما فقط آن را استخراج کردیم frame. جزئیات بیشتر از مجموعه داده در دسترس است اینجا.
اجازه دهید import پانداها و به چند ردیف اول داده نگاهی بیاندازید:
import pandas as pd
df.head()
با اجرای کد، پنج ردیف اول مجموعه داده ما نمایش داده می شود:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
در این راهنما استفاده خواهیم کرد MedInc، HouseAge، AveRooms، AveBedrms، Population، AveOccup، Latitude، Longitude برای پیش بینی MedHouseVal. چیزی شبیه به روایت انگیزه ما.
بیایید اکنون مستقیماً به اجرای الگوریتم KNN برای رگرسیون بپردازیم.
رگرسیون با K-نزدیکترین همسایگان با Scikit-Learn
تا اینجا، ما با مجموعه داده خود آشنا شدیم و اکنون میتوانیم به مراحل دیگر در الگوریتم KNN برویم.
پیش پردازش داده ها برای رگرسیون KNN
پیش پردازش جایی است که اولین تفاوت بین وظایف رگرسیون و طبقه بندی ظاهر می شود. از آنجایی که این بخش تماماً در مورد رگرسیون است، مجموعه داده های خود را بر این اساس آماده خواهیم کرد.
برای رگرسیون، ما نیاز به پیشبینی ارزش خانه متوسط دیگری داریم. برای انجام این کار، ما تعیین می کنیم MedHouseVal به y و تمام ستون های دیگر به X فقط با انداختن MedHouseVal:
y = df('MedHouseVal')
X = df.drop(('MedHouseVal'), axis = 1)
با نگاهی به توضیحات متغیرهایمان، میتوانیم متوجه شویم که تفاوتهایی در اندازهگیریها داریم. برای جلوگیری از حدس زدن، بیایید از آن استفاده کنیم describe() روش بررسی:
X.describe().T
این نتیجه در:
count mean std min 25% 50% 75% max
MedInc 20640.0 3.870671 1.899822 0.499900 2.563400 3.534800 4.743250 15.000100
HouseAge 20640.0 28.639486 12.585558 1.000000 18.000000 29.000000 37.000000 52.000000
AveRooms 20640.0 5.429000 2.474173 0.846154 4.440716 5.229129 6.052381 141.909091
AveBedrms 20640.0 1.096675 0.473911 0.333333 1.006079 1.048780 1.099526 34.066667
Population 20640.0 1425.476744 1132.462122 3.000000 787.000000 1166.000000 1725.000000 35682.000000
AveOccup 20640.0 3.070655 10.386050 0.692308 2.429741 2.818116 3.282261 1243.333333
Latitude 20640.0 35.631861 2.135952 32.540000 33.930000 34.260000 37.710000 41.950000
Longitude 20640.0 -119.569704 2.003532 -124.350000 -121.800000 -118.490000 -118.010000 -114.310000
در اینجا، ما می توانیم ببینیم که mean ارزش MedInc تقریبا است 3.87 و mean ارزش HouseAge در مورد است 28.64، که آن را 7.4 برابر بزرگتر می کند MedInc. سایر ویژگی ها نیز تفاوت هایی در میانگین و انحراف معیار دارند – برای مشاهده آن، به آن نگاه کنید mean و std ارزش ها را مشاهده کنید و مشاهده کنید که چگونه از یکدیگر فاصله دارند. برای MedInc std تقریبا است 1.9، برای HouseAge، std است 12.59 و همین امر در مورد سایر ویژگی ها نیز صدق می کند.
ما از یک الگوریتم مبتنی بر استفاده می کنیم روی فاصله و الگوریتمهای مبتنی بر فاصله به شدت از دادههایی رنج میبرند که اینطور نیستند روی همان مقیاس، مانند این داده ها. مقیاس نقاط ممکن است (و در عمل، تقریباً همیشه) فاصله واقعی بین مقادیر را مخدوش کند.
برای اجرای Feature Scaling، از Scikit-Learn استفاده خواهیم کرد StandardScaler کلاس بعد اگر مقیاس گذاری را در حال حاضر اعمال کنیم (قبل از تقسیم آزمون قطار)، محاسبه به طور موثر شامل داده های آزمایشی می شود. نشتی اطلاعات داده ها را در بقیه خط لوله آزمایش کنید. این نوع نشت داده متأسفانه معمولاً نادیده گرفته می شود که منجر به یافته های غیرقابل تکرار یا توهم می شود.
تقسیم داده ها به مجموعه های قطار و تست
برای اینکه بتوانیم دادههای خود را بدون نشتی مقیاسبندی کنیم، اما همچنین برای ارزیابی نتایج و جلوگیری از تطبیق بیش از حد، مجموعه دادههای خود را به دو بخش قطار و آزمایش تقسیم میکنیم.
یک راه ساده برای ایجاد تقسیمهای قطار و آزمایش، این است train_test_split روش از Scikit-Learn. تقسیم در نقطه ای به صورت خطی تقسیم نمی شود، اما X% و Y% را به صورت تصادفی نمونه برداری می کند. برای ساختن این process قابل تکرار (برای اینکه روش همیشه از همان نقاط داده نمونه برداری کند)، مقدار را تنظیم می کنیم random_state استدلال به معین SEED:
from sklearn.model_selection import train_test_split
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=SEED)
این قطعه کد 75 درصد از داده ها را برای آموزش و 25 درصد از داده ها را برای آزمایش نمونه برداری می کند. با تغییر در test_size به عنوان مثال، به 0.3، می توانید با 70٪ از داده ها تمرین کنید و با 30٪ تست کنید.
با استفاده از 75 درصد داده ها برای آموزش و 25 درصد برای آزمایش، از 20640 رکورد، مجموعه آموزشی شامل 15480 و مجموعه آزمایشی شامل 5160 است. ما می توانیم با چاپ طول مجموعه داده کامل و داده های تقسیم شده به سرعت آن اعداد را بررسی کنیم. :
len(X)
len(X_train)
len(X_test)
عالی! اکنون میتوانیم مقیاسکننده داده را متناسب کنیم روی را X_train تنظیم کنید و هر دو را مقیاس کنید X_train و X_test بدون درز هیچ اطلاعاتی از X_test به X_train.
مقیاس بندی ویژگی برای رگرسیون KNN
با واردات StandardScalerبا نمونهبرداری از آن، برازش آن بر اساس دادههای قطار ما (جلوگیری از نشت)، و تبدیل مجموعه دادههای قطار و آزمایش، میتوانیم مقیاسبندی ویژگی را انجام دهیم:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
توجه داشته باشید: از آنجا که شما اغلب تماس بگیرید scaler.fit(X_train) به دنبال scaler.transform(X_train) – می توانید با یک مجرد تماس بگیرید scaler.fit_transform(X_train) به دنبال scaler.transform(X_test) تا تماس کوتاه تر شود!
اکنون داده های ما مقیاس شده است! مقیاسکننده فقط نقاط داده را حفظ میکند و نام ستونها را هنگام اعمال حفظ نمیکند روی آ DataFrame. بیایید دوباره داده ها را با نام ستون ها در یک DataFrame سازماندهی کنیم و استفاده کنیم describe() برای مشاهده تغییرات در mean و std:
col_names=('MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude')
scaled_df = pd.DataFrame(X_train, columns=col_names)
scaled_df.describe().T
این به ما می دهد:
count mean std min 25% 50% 75% max
MedInc 15480.0 2.074711e-16 1.000032 -1.774632 -0.688854 -0.175663 0.464450 5.842113
HouseAge 15480.0 -1.232434e-16 1.000032 -2.188261 -0.840224 0.032036 0.666407 1.855852
AveRooms 15480.0 -1.620294e-16 1.000032 -1.877586 -0.407008 -0.083940 0.257082 56.357392
AveBedrms 15480.0 7.435912e-17 1.000032 -1.740123 -0.205765 -0.108332 0.007435 55.925392
Population 15480.0 -8.996536e-17 1.000032 -1.246395 -0.558886 -0.227928 0.262056 29.971725
AveOccup 15480.0 1.055716e-17 1.000032 -0.201946 -0.056581 -0.024172 0.014501 103.737365
Latitude 15480.0 7.890329e-16 1.000032 -1.451215 -0.799820 -0.645172 0.971601 2.953905
Longitude 15480.0 2.206676e-15 1.000032 -2.380303 -1.106817 0.536231 0.785934 2.633738
مشاهده کنید که اکنون همه انحرافات استاندارد چگونه هستند 1 و وسایل کوچکتر شده است. این چیزی است که داده های ما را می سازد یکنواخت تر! بیایید یک رگرسیون مبتنی بر KNN را آموزش و ارزیابی کنیم.
آموزش و پیش بینی رگرسیون KNN
API بصری و پایدار Scikit-Learn باعث میشود آموزش پسروندهها و طبقهبندیکنندهها بسیار ساده باشد. اجازه دهید import را KNeighborsRegressor کلاس از sklearn.neighbors ماژول، آن را نمونه سازی کنید، و آن را با داده های قطار ما مطابقت دهید:
from sklearn.neighbors import KNeighborsRegressor
regressor = KNeighborsRegressor(n_neighbors=5)
regressor.fit(X_train, y_train)
در کد بالا، n_neighbors ارزش برای است ک، یا تعداد همسایه هایی که الگوریتم برای انتخاب یک مقدار متوسط خانه جدید در نظر می گیرد. 5 مقدار پیش فرض برای است KNeighborsRegressor(). هیچ مقدار ایده آلی برای K وجود ندارد و پس از آزمایش و ارزیابی انتخاب می شود، اما برای شروع، 5 یک مقدار رایج برای KNN است و بنابراین به عنوان مقدار پیش فرض تنظیم شده است.
مرحله آخر پیش بینی است روی داده های تست ما برای انجام این کار، اسکریپت زیر را اجرا کنید:
y_pred = regressor.predict(X_test)
اکنون میتوانیم ارزیابی کنیم که مدل ما چقدر به دادههای جدیدی تعمیم مییابد که برچسبهایی (واقعیت زمینی) برای آنها داریم – مجموعه آزمایشی!
ارزیابی الگوریتم برای رگرسیون KNN
متداول ترین معیارهای رگرسیون مورد استفاده برای ارزیابی الگوریتم عبارتند از میانگین خطای مطلق (MAE)، میانگین مربع خطا (MSE) root میانگین مربعات خطا (RMSE) و ضریب تعیین (R2):
- میانگین خطای مطلق (MAE): وقتی مقادیر پیش بینی شده را از مقادیر واقعی کم می کنیم، خطاها را بدست می آوریم، مقادیر مطلق آن خطاها را جمع می کنیم و میانگین آنها را بدست می آوریم. این متریک تصوری از خطای کلی برای هر پیشبینی مدل ارائه میدهد، هرچه کوچکتر (نزدیک به 0) بهتر باشد:
$$
mae = (\frac{1}{n})\sum_{i=1}^{n}\left | واقعی – پیش بینی شده \right |
$$
توجه داشته باشید: همچنین ممکن است با y و ŷ (به عنوان y-hat بخوانید) نماد در معادلات. این y اشاره به مقادیر واقعی و ŷ به مقادیر پیش بینی شده
- میانگین مربعات خطا (MSE): شبیه به متریک MAE است، اما مقادیر مطلق خطاها را مربع می کند. همچنین، مانند MAE، هرچه کوچکتر یا نزدیکتر به 0 باشد، بهتر است. مقدار MSE مربع است تا خطاهای بزرگ حتی بزرگتر شود. یکی از مواردی که باید به آن دقت کرد این است که معمولاً به دلیل اندازه مقادیر آن و این واقعیت که آنها نیستند، تفسیر آن سخت است. روی مقیاس مشابه داده ها
$$
mse = \sum_{i=1}^{D}(واقعی – پیش بینی شده)^2
$$
- ریشه میانگین مربعات خطا (RMSE): سعی می کند با بدست آوردن مربع، مشکل تفسیر مطرح شده در MSE را حل کند root از مقدار نهایی آن، به طوری که آن را به همان واحدهای داده کاهش دهیم. وقتی نیاز به نمایش یا نشان دادن ارزش واقعی داده ها با خطا داریم، تفسیر آسان تر و خوب است. این نشان میدهد که دادهها چقدر ممکن است متفاوت باشند، بنابراین، اگر RMSE 4.35 داشته باشیم، مدل ما میتواند خطا داشته باشد یا به این دلیل که 4.35 را به مقدار واقعی اضافه کرده است یا برای رسیدن به مقدار واقعی به 4.35 نیاز دارد. هرچه به 0 نزدیکتر باشد، بهتر است.
$$
rmse = \sqrt{ \sum_{i=1}^{D}(واقعی – پیش بینی شده)^2}
$$
این mean_absolute_error() و mean_squared_error() روش های sklearn.metrics همانطور که در قطعه زیر مشاهده می شود می توان برای محاسبه این معیارها استفاده کرد:
from sklearn.metrics import mean_absolute_error, mean_squared_error
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = mean_squared_error(y_test, y_pred, squared=False)
print(f'mae: {mae}')
print(f'mse: {mse}')
print(f'rmse: {rmse}')
خروجی اسکریپت بالا به شکل زیر است:
mae: 0.4460739527131783
mse: 0.4316907430948294
rmse: 0.6570317671884894
R2 را می توان به طور مستقیم با score() روش:
regressor.score(X_test, y_test)
کدام خروجی ها:
0.6737569252627673
نتایج نشان میدهد که خطای کلی الگوریتم KNN ما و میانگین خطا تقریباً وجود دارد 0.44، و 0.43. همچنین، RMSE نشان میدهد که با اضافه کردن، میتوانیم از مقدار واقعی دادهها بالاتر یا پایینتر برویم 0.65 یا تفریق 0.65. چقدر خوبه
بیایید بررسی کنیم که قیمت ها چگونه است:
y.describe()
count 20640.000000
mean 2.068558
std 1.153956
min 0.149990
25% 1.196000
50% 1.797000
75% 2.647250
max 5.000010
Name: MedHouseVal, dtype: float64
میانگین این است 2.06 و انحراف معیار از میانگین است 1.15 بنابراین نمره ما از ~0.44 واقعاً ستاره ای نیست، اما خیلی بد نیست.
با R2، هر چه به 1 نزدیکتر باشیم (یا 100)، بهتر است. R2 میزان تغییرات داده ها یا داده ها را نشان می دهد واریانس درک می شوند یا توضیح داد توسط KNN.
$$
R^2 = 1 – \frac{\sum(واقعی – پیش بینی شده)^2}{\sum(واقعی – واقعی \ میانگین)^2}
$$
با ارزش 0.67، می بینیم که مدل ما 67 درصد از واریانس داده ها را توضیح می دهد. در حال حاضر بیش از 50٪ است که خوب است، اما خیلی خوب نیست. آیا راهی وجود دارد که بتوانیم بهتر عمل کنیم؟
ما از یک K از پیش تعیین شده با مقدار استفاده کرده ایم 5بنابراین، ما از 5 همسایه برای پیش بینی اهداف خود استفاده می کنیم که لزوما بهترین عدد نیست. برای اینکه بفهمیم کدام عدد ایدهآل Ks است، میتوانیم خطاهای الگوریتم خود را تجزیه و تحلیل کنیم و K را انتخاب کنیم که تلفات را به حداقل میرساند.
یافتن بهترین K برای رگرسیون KNN
در حالت ایدهآل، میبینید که کدام معیار بیشتر با زمینه شما مطابقت دارد – اما معمولاً آزمایش همه معیارها جالب است. هر زمان که توانستید همه آنها را آزمایش کنید، این کار را انجام دهید. در اینجا، روش انتخاب بهترین K را تنها با استفاده از میانگین خطای مطلق نشان خواهیم داد، اما می توانید آن را به هر متریک دیگری تغییر دهید و نتایج را مقایسه کنید.
برای این کار یک حلقه for ایجاد می کنیم و مدل هایی اجرا می کنیم که از 1 تا X همسایه دارند. در هر فعل و انفعال، MAE را محاسبه کرده و تعداد Ks را همراه با نتیجه MAE رسم می کنیم:
error = ()
for i in range(1, 40):
knn = KNeighborsRegressor(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
mae = mean_absolute_error(y_test, pred_i)
error.append(mae)
حالا بیایید طرح را ترسیم کنیم errors:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red',
linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('K Value MAE')
plt.xlabel('K Value')
plt.ylabel('Mean Absolute Error')

با نگاهی به نمودار، به نظر می رسد کمترین مقدار MAE زمانی است که K باشد 12. بیایید نگاهی دقیق تر به نمودار داشته باشیم تا با ترسیم داده های کمتر مطمئن شویم:
plt.figure(figsize=(12, 6))
plt.plot(range(1, 15), error(:14), color='red',
linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('K Value MAE')
plt.xlabel('K Value')
plt.ylabel('Mean Absolute Error')

همچنین می توانید کمترین خطا و شاخص آن نقطه را با استفاده از توکار به دست آورید min() عملکرد (کار می کند روی lists) یا لیست را به یک آرایه NumPy تبدیل کنید و آن را دریافت کنید argmin() (شاخص عنصر با کمترین مقدار):
import numpy as np
print(min(error))
print(np.array(error).argmin())
شروع کردیم به شمردن همسایه ها روی 1، در حالی که آرایه ها بر اساس 0 هستند، بنابراین شاخص یازدهم 12 همسایه است!
این بدان معناست که ما به 12 همسایه نیاز داریم تا بتوانیم نقطه ای با کمترین خطای MAE را پیش بینی کنیم. میتوانیم مدل و معیارها را دوباره با 12 همسایه برای مقایسه نتایج اجرا کنیم:
knn_reg12 = KNeighborsRegressor(n_neighbors=12)
knn_reg12.fit(X_train, y_train)
y_pred12 = knn_reg12.predict(X_test)
r2 = knn_reg12.score(X_test, y_test)
mae12 = mean_absolute_error(y_test, y_pred12)
mse12 = mean_squared_error(y_test, y_pred12)
rmse12 = mean_squared_error(y_test, y_pred12, squared=False)
print(f'r2: {r2}, \nmae: {mae12} \nmse: {mse12} \nrmse: {rmse12}')
خروجی کد زیر است:
r2: 0.6887495617137436,
mae: 0.43631325936692505
mse: 0.4118522151025172
rmse: 0.6417571309323467
با 12 همسایه، مدل KNN ما اکنون 69 درصد از واریانس داده ها را توضیح می دهد و کمی کمتر از دست داده است. 0.44 به 0.43، 0.43 به 0.41، و 0.65 به 0.64 با معیارهای مربوطه این یک پیشرفت بزرگ نیست، اما با این وجود یک پیشرفت است.
توجه داشته باشید: در ادامه این تحلیل، انجام یک تجزیه و تحلیل داده های اکتشافی (EDA) همراه با تجزیه و تحلیل باقیمانده ممکن است به انتخاب ویژگی ها و دستیابی به نتایج بهتر کمک کند.
قبلاً روش استفاده از KNN برای رگرسیون را دیدهایم – اما اگر بخواهیم یک نقطه را به جای پیشبینی ارزش آن طبقهبندی کنیم، چه میشود؟ اکنون میتوانیم روش استفاده از KNN برای طبقهبندی را بررسی کنیم.
طبقه بندی با استفاده از K-Nearest Neighbors با Scikit-Learn
در این کار، به جای پیش بینی یک مقدار پیوسته، می خواهیم کلاسی را که این گروه های بلوک به آن تعلق دارند، پیش بینی کنیم. برای انجام این کار، میتوانیم میانگین ارزش خانه برای مناطق را به گروههایی با محدودههای متفاوت ارزش خانه تقسیم کنیم سطل زباله.
هنگامی که می خواهید از یک مقدار پیوسته برای طبقه بندی استفاده کنید، معمولاً می توانید داده ها را بن کنید. به این ترتیب می توانید به جای مقادیر، گروه ها را پیش بینی کنید.
پیش پردازش داده ها برای طبقه بندی
بیایید سطل های داده را ایجاد کنیم تا مقادیر پیوسته خود را به دسته ها تبدیل کنیم:
df("MedHouseValCat") = pd.qcut(df("MedHouseVal"), 4, retbins=False, labels=(1, 2, 3, 4))
سپس، می توانیم مجموعه داده خود را به ویژگی ها و برچسب های آن تقسیم کنیم:
y = df('MedHouseValCat')
X = df.drop(('MedHouseVal', 'MedHouseValCat'), axis = 1)
از آنجایی که ما استفاده کرده ایم MedHouseVal ستون برای ایجاد سطل، ما نیاز به رها کردن MedHouseVal ستون و MedHouseValCat ستون از X. به این ترتیب، DataFrame شامل 8 ستون اول مجموعه داده (یعنی ویژگی ها، ویژگی ها) خواهد بود در حالی که ما y فقط شامل MedHouseValCat برچسب اختصاص داده شده
توجه داشته باشید: همچنین می توانید ستون ها را با استفاده از .iloc() به جای انداختن آنها هنگام رها کردن، فقط توجه داشته باشید که باید اختصاص دهید y مقادیر قبل از تخصیص X مقادیر، زیرا شما نمی توانید یک ستون حذف شده از a را اختصاص دهید DataFrame به یک شی دیگر در حافظه
تقسیم داده ها به مجموعه های قطار و تست
همانطور که با رگرسیون انجام شد، مجموعه داده را نیز به دو بخش آموزشی و آزمایشی تقسیم خواهیم کرد. از آنجایی که ما داده های متفاوتی داریم، باید این کار را تکرار کنیم process:
from sklearn.model_selection import train_test_split
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=SEED)
ما از مقدار استاندارد Scikit-Learn 75% داده قطار و 25% داده تست دوباره استفاده خواهیم کرد. این بدان معناست که ما همان رکوردهای قطار و آزمایش را خواهیم داشت که در رگرسیون قبلی وجود داشت.
مقیاس بندی ویژگی برای طبقه بندی
از آنجایی که ما با همان مجموعه داده پردازش نشده و واحدهای اندازه گیری متفاوت آن سر و کار داریم، مجدداً مقیاس بندی ویژگی را به همان روشی که برای داده های رگرسیونی خود انجام دادیم انجام خواهیم داد:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
آموزش و پیش بینی برای طبقه بندی
پس از باینینگ، تقسیم و مقیاس بندی داده ها، در نهایت می توانیم یک طبقه بندی کننده قرار دهیم روی آی تی. برای پیش بینی، دوباره از 5 همسایه به عنوان خط مبنا استفاده می کنیم. شما همچنین می توانید نمونه سازی کنید KNeighbors_ کلاس بدون هیچ آرگومان و به طور خودکار از 5 همسایه استفاده می کند. در اینجا، به جای واردات KNeighborsRegressor، ما خواهیم کرد import را KNeighborsClassifier، کلاس:
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier()
classifier.fit(X_train, y_train)
پس از نصب KNeighborsClassifier، می توانیم کلاس های داده های تست را پیش بینی کنیم:
y_pred = classifier.predict(X_test)
زمان ارزیابی پیش بینی ها است! آیا پیشبینی کلاسها رویکرد بهتری نسبت به پیشبینی مقادیر در این مورد خواهد بود؟ بیایید الگوریتم را ارزیابی کنیم تا ببینیم چه اتفاقی می افتد.
ارزیابی KNN برای طبقه بندی
برای ارزیابی طبقهبندی کننده KNN نیز میتوانیم از آن استفاده کنیم score روش، اما یک متریک متفاوت را اجرا می کند زیرا ما یک طبقه بندی کننده نمره می دهیم و نه یک رگرسیون. معیار اصلی برای طبقه بندی است accuracy – توضیح می دهد که طبقه بندی کننده ما چند پیش بینی درست انجام داده است. کمترین مقدار دقت 0 و بیشترین مقدار 1 است. معمولاً آن مقدار را در 100 ضرب می کنیم تا یک درصد بدست آوریم.
$$
دقت = \frac{\text{تعداد پیشبینیهای صحیح}}{\text{تعداد کل پیشبینیها}}
$$
توجه داشته باشید: به دست آوردن دقت 100% بسیار سخت است روی هر گونه داده واقعی، اگر چنین اتفاقی بیفتد، آگاه باشید که ممکن است نشت یا مشکلی در حال رخ دادن باشد – اتفاق نظر وجود ندارد روی یک مقدار دقت ایده آل است و همچنین وابسته به زمینه است. بسته به روی را هزینه خطا (چه بد است اگر به طبقه بندی کننده اعتماد کنیم و معلوم شود که اشتباه است)، یک نرخ خطای قابل قبول ممکن است 5٪، 10٪ یا حتی 30٪ باشد.
بیایید طبقه بندی کننده خود را امتیاز دهیم:
acc = classifier.score(X_test, y_test)
print(acc)
با نگاه کردن به امتیاز به دست آمده، می توانیم نتیجه بگیریم که طبقه بندی کننده ما 62٪ از کلاس های ما را درست به دست آورده است. این در حال حاضر به تجزیه و تحلیل کمک می کند، اگرچه تنها با دانستن آنچه طبقه بندی کننده درست انجام داده است، بهبود آن دشوار است.
4 کلاس در مجموعه داده ما وجود دارد – اگر طبقه بندی کننده ما دریافت کند چه می شود 90 درصد از کلاس های 1، 2 و 3 درست است، اما تنها 30 درصد از کلاس 4 درست است?
یک شکست سیستمیک برخی از کلاسها، بر خلاف یک شکست متوازن مشترک بین کلاسها، میتواند هر دو امتیاز دقت 62 درصد را به همراه داشته باشد. دقت معیار واقعاً خوبی برای ارزیابی واقعی نیست – اما به عنوان یک پروکسی خوب عمل می کند. اغلب اوقات، با مجموعه داده های متعادل، دقت 62 درصد نسبتاً یکنواخت پخش می شود. همچنین، در اغلب موارد، مجموعه دادهها متعادل نیستند، بنابراین ما به نقطه اول بازگشتهایم و دقت یک معیار ناکافی است.
ما می توانیم با استفاده از معیارهای دیگر به نتایج عمیق تر نگاه کنیم تا بتوانیم آن را تعیین کنیم. این مرحله نیز با رگرسیون متفاوت است، در اینجا ما استفاده خواهیم کرد:
- ماتریس سردرگمی: برای اینکه بدانیم چقدر درست یا غلط کردیم هر کلاس. مقادیری که درست و به درستی پیش بینی شده بودند نامیده می شوند نکات مثبت واقعی آنهایی که به عنوان مثبت پیش بینی شده بودند اما مثبت نبودند نامیده می شوند مثبت کاذب. همان نامگذاری از منفی های واقعی و منفی های کاذب برای مقادیر منفی استفاده می شود.
- دقت، درستی: برای درک اینکه چه مقادیر پیشبینی درستی توسط طبقهبندیکننده ما صحیح در نظر گرفته شده است. دقت آن مقادیر مثبت واقعی را بر هر چیزی که به عنوان مثبت پیش بینی شده بود تقسیم می کند.
$$
دقت = \frac{\text{مثبت واقعی}}{\text{مثبت واقعی} + \متن{مثبت نادرست}}
$$
- به خاطر آوردن: برای درک اینکه چه تعداد از موارد مثبت واقعی توسط طبقه بندی کننده ما شناسایی شده است. فراخوان با تقسیم مثبت های واقعی بر هر چیزی که باید مثبت پیش بینی می شد محاسبه می شود.
$$
recall = \frac{\text{true positive}}{\text{true positive} + \text{غیر غلط}}
$$
- امتیاز F1: آیا متعادل یا میانگین هارمونیک دقت و یادآوری کمترین مقدار 0 و بیشترین مقدار 1 است. When
f1-scoreبرابر با 1 است، به این معنی است که همه کلاس ها به درستی پیش بینی شده اند – این یک امتیاز بسیار سخت برای به دست آوردن با داده های واقعی است (تقریبا همیشه استثنا وجود دارد).
$$
\text{f1-score} = 2* \frac{\text{precision} * \text{recall}}{\text{precision} + \text{recal}}
$$
توجه داشته باشید: یک امتیاز F1 وزنی نیز وجود دارد، و فقط یک F1 است که وزن یکسانی را برای همه کلاس ها اعمال نمی کند. وزن معمولاً توسط کلاس ها تعیین می شود حمایت کردن – چند نمونه از امتیاز F1 (نسبت برچسب های متعلق به یک کلاس خاص) “پشتیبانی” می کنند. هرچه پشتیبانی کمتر باشد (نمونه های کمتری از یک کلاس)، وزن F1 برای آن کلاس کمتر است، زیرا غیرقابل اعتمادتر است.
این confusion_matrix() و classification_report() روش های sklearn.metrics ماژول را می توان برای محاسبه و نمایش تمام این معیارها استفاده کرد. این confusion_matrix بهتر است با استفاده از نقشه حرارتی تجسم شود. گزارش طبقه بندی قبلاً به ما می دهد accuracy، precision، recall، و f1-score، اما شما همچنین می توانید import هر یک از این معیارها از sklearn.metrics.
برای بدست آوردن معیارها، قطعه زیر را اجرا کنید:
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
classes_names = ('class 1','class 2','class 3', 'class 4')
cm = pd.DataFrame(confusion_matrix(yc_test, yc_pred),
columns=classes_names, index = classes_names)
sns.heatmap(cm, annot=True, fmt='d');
print(classification_report(y_test, y_pred))
خروجی اسکریپت بالا به شکل زیر است:

precision recall f1-score support
1 0.75 0.78 0.76 1292
2 0.49 0.56 0.53 1283
3 0.51 0.51 0.51 1292
4 0.76 0.62 0.69 1293
accuracy 0.62 5160
macro avg 0.63 0.62 0.62 5160
weighted avg 0.63 0.62 0.62 5160
نتایج نشان می دهد که KNN توانسته است تمام 5160 رکورد در مجموعه آزمایشی را با دقت 62 درصد طبقه بندی کند که بالاتر از حد متوسط است. پشتیبانی ها نسبتاً برابر هستند (توزیع یکنواخت کلاس ها در مجموعه داده)، بنابراین F1 وزن دار و F1 بدون وزن تقریباً یکسان خواهند بود.
ما همچنین می توانیم نتیجه معیارهای هر یک از 4 کلاس را مشاهده کنیم. از آن جا، ما می توانیم متوجه آن شویم class 2 کمترین دقت، کمترین را داشت recall، و کمترین f1-score. Class 3 درست پشت سر است class 2 برای داشتن کمترین امتیاز، و پس از آن، ما داریم class 1 با بهترین نمرات به دنبال آن class 4.
با نگاه کردن به ماتریس سردرگمی، می توانیم متوجه شویم که:
class 1بیشتر اشتباه گرفته شدclass 2در 238 موردclass 2برایclass 1در 256 مدخل، و برایclass 3در 260 موردclass 3بیشتر اشتباه شده بودclass 2، 374 مدخل وclass 4، در 193 موردclass 4به اشتباه به عنوان طبقه بندی شدclass 3برای 339 ورودی، و به عنوانclass 2در 130 مورد
همچنین، توجه داشته باشید که مورب مقادیر مثبت واقعی را نشان می دهد، وقتی به آن نگاه می کنید، به وضوح می بینید که class 2 و class 3 دارای کمترین مقادیر درست پیش بینی شده است.
با این نتایج، میتوانیم با بررسی بیشتر آنها به تحلیل عمیقتر برویم تا بفهمیم چرا این اتفاق افتاده است، و همچنین درک کنیم که آیا 4 کلاس بهترین راه برای جمع کردن دادهها هستند یا خیر. شاید ارزش هایی از class 2 و class 3 خیلی به هم نزدیک بودند، بنابراین تشخیص آنها از هم سخت شد.
همیشه سعی کنید داده ها را با تعداد سطل های مختلف تست کنید تا ببینید چه اتفاقی می افتد.
علاوه بر تعداد دلخواه bin های داده، تعداد دلخواه دیگری نیز وجود دارد که ما انتخاب کرده ایم، تعداد همسایگان K. همان تکنیکی را که برای کار رگرسیون به کار بردیم، میتوان برای طبقهبندی در هنگام تعیین تعداد Kهایی که یک مقدار متریک را به حداکثر یا حداقل میرسانند، اعمال کرد.
یافتن بهترین K برای طبقه بندی KNN
بیایید آنچه را که برای رگرسیون انجام شده است تکرار کنیم و نمودار مقادیر K و متریک مربوطه را برای مجموعه تست رسم کنیم. همچنین میتوانید معیاری را انتخاب کنید که با شرایط شما مطابقت دارد، در اینجا ما انتخاب میکنیم f1-score.
به این ترتیب، ما طرح f1-score برای مقادیر پیش بینی شده مجموعه تست برای همه مقادیر K بین 1 تا 40.
اول ما import را f1_score از جانب sklearn.metrics و سپس مقدار آن را برای تمام پیشبینیهای طبقهبندیکننده K-Nearest Neighbors محاسبه کنید، که در آن K از 1 تا 40 متغیر است:
from sklearn.metrics import f1_score
f1s = ()
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
f1s.append(f1_score(y_test, pred_i, average='weighted'))
مرحله بعدی ترسیم نمودار است f1_score مقادیر در مقابل مقادیر K تفاوت رگرسیون در این است که به جای انتخاب مقدار K که خطا را به حداقل می رساند، این بار مقداری را انتخاب می کنیم که مقدار را به حداکثر می رساند. f1-score.
اسکریپت زیر را برای ایجاد طرح اجرا کنید:
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), f1s, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('F1 Score K Value')
plt.xlabel('K Value')
plt.ylabel('F1 Score')
نمودار خروجی به شکل زیر است:

از خروجی، می توانیم ببینیم که f1-score زمانی که مقدار K باشد بالاترین مقدار است 15. بیایید طبقهبندیکننده خود را با 15 همسایه دوباره آموزش دهیم و ببینیم با نتایج گزارش طبقهبندی ما چه میکند:
classifier15 = KNeighborsClassifier(n_neighbors=15)
classifier15.fit(X_train, y_train)
y_pred15 = classifier15.predict(X_test)
print(classification_report(y_test, y_pred15))
این خروجی:
precision recall f1-score support
1 0.77 0.79 0.78 1292
2 0.52 0.58 0.55 1283
3 0.51 0.53 0.52 1292
4 0.77 0.64 0.70 1293
accuracy 0.63 5160
macro avg 0.64 0.63 0.64 5160
weighted avg 0.64 0.63 0.64 5160
توجه داشته باشید که معیارهای ما با 15 همسایه بهبود یافته است، ما دقت 63٪ و بالاتر داریم. precision، recall، و f1-scores، اما هنوز باید بیشتر به سطل ها نگاه کنیم تا بفهمیم چرا f1-score برای کلاس ها 2 و 3 هنوز کم است
علاوه بر استفاده از KNN برای رگرسیون و تعیین مقادیر بلوک و برای طبقهبندی، برای تعیین کلاسهای بلوک – ما همچنین میتوانیم از KNN برای تشخیص اینکه کدام مقادیر میانگین بلوکها با اکثر آنها متفاوت هستند – آنهایی که از آنچه بیشتر دادهها انجام میدهند پیروی نمیکنند استفاده کنیم. به عبارت دیگر، ما می توانیم از KNN برای تشخیص نقاط پرت.
پیادهسازی KNN برای تشخیص بیرونی با Scikit-Learn
تشخیص پرت از روش دیگری استفاده می کند که با آنچه قبلاً برای رگرسیون و طبقه بندی انجام داده بودیم متفاوت است.
در اینجا، خواهیم دید که هر یک از همسایگان چقدر از یک نقطه داده فاصله دارند. بیایید از 5 همسایه پیش فرض استفاده کنیم. برای یک نقطه داده، فاصله هر یک از K-نزدیکترین همسایه را محاسبه خواهیم کرد. برای انجام آن، ما انجام خواهیم داد import الگوریتم KNN دیگری از Scikit-learn که برای رگرسیون یا طبقه بندی خاص نیست و به سادگی نامیده می شود. NearestNeighbors.
پس از وارد کردن، a را نمونه می کنیم NearestNeighbors کلاس با 5 همسایه – شما همچنین می توانید آن را با 12 همسایه برای شناسایی نقاط پرت در مثال رگرسیون ما یا با 15 نمونه سازی کنید تا برای مثال طبقه بندی نیز همین کار را انجام دهید. سپس دادههای قطار خود را جا داده و از آن استفاده میکنیم kneighbors() روشی برای یافتن فاصله های محاسبه شده برای هر نقطه داده و شاخص های همسایه:
from sklearn.neighbors import NearestNeighbors
nbrs = NearestNeighbors(n_neighbors = 5)
nbrs.fit(X_train)
distances, indexes = nbrs.kneighbors(X_train)
اکنون ما 5 فاصله برای هر نقطه داده داریم – فاصله بین خود و 5 همسایه اش، و شاخصی که آنها را شناسایی می کند. بیایید نگاهی به سه نتیجه اول و شکل آرایه بیندازیم تا این موضوع را بهتر تجسم کنیم.
برای مشاهده شکل سه فاصله اول، اجرا کنید:
distances(:3), distances.shape
(array(((0. , 0.12998939, 0.15157687, 0.16543705, 0.17750354),
(0. , 0.25535314, 0.37100754, 0.39090243, 0.40619693),
(0. , 0.27149697, 0.28024623, 0.28112326, 0.30420656))),
(3, 5))
توجه کنید که 3 ردیف با 5 فاصله وجود دارد. همچنین میتوانیم به نمایههای همسایگان نگاه کنیم:
indexes(:3), indexes(:3).shape
این نتیجه در:
(array((( 0, 8608, 12831, 8298, 2482),
( 1, 4966, 5786, 8568, 6759),
( 2, 13326, 13936, 3618, 9756))),
(3, 5))
در خروجی بالا می توانیم شاخص های هر یک از 5 همسایه را مشاهده کنیم. اکنون میتوانیم به محاسبه میانگین 5 فاصله ادامه دهیم و نموداری رسم کنیم که هر ردیف را میشمارد. روی محور X و هر میانگین فاصله را نمایش می دهد روی محور Y:
dist_means = distances.mean(axis=1)
plt.plot(dist_means)
plt.title('Mean of the 5 neighbors distances for each data point')
plt.xlabel('Count')
plt.ylabel('Mean Distances')

توجه داشته باشید که بخشی از نمودار وجود دارد که در آن فاصله های میانگین دارای مقادیر یکنواخت هستند. آن نقطه محور Y که در آن میانگین ها خیلی زیاد یا خیلی پایین نیستند، دقیقاً همان نقطه ای است که برای قطع مقادیر پرت باید شناسایی کنیم.
در این مورد، جایی است که میانگین فاصله 3 است. بیایید دوباره نمودار را با یک خط نقطه چین افقی رسم کنیم تا بتوانیم آن را تشخیص دهیم:
dist_means = distances.mean(axis=1)
plt.plot(dist_means)
plt.title('Mean of the 5 neighbors distances for each data point with cut-off line')
plt.xlabel('Count')
plt.ylabel('Mean Distances')
plt.axhline(y = 3, color = 'r', linestyle = '--')

این خط میانگین فاصله ای را نشان می دهد که در بالای آن همه مقادیر متفاوت است. این بدان معنی است که تمام نقاط با a mean فاصله بالا 3 پرت ما هستند ما می توانیم با استفاده از شاخص های آن نقاط را دریابیم np.where(). این روش یا خروجی خواهد داشت True یا False برای هر شاخص با توجه به mean بالای 3 وضعیت:
import numpy as np
outlier_index = np.where(dist_means > 3)
outlier_index
خروجی کد بالا:
(array(( 564, 2167, 2415, 2902, 6607, 8047, 8243, 9029, 11892,
12127, 12226, 12353, 13534, 13795, 14292, 14707)),)
اکنون ما شاخص های نقطه پرت خود را داریم. بیایید آنها را در چارچوب داده پیدا کنیم:
outlier_values = df.iloc(outlier_index)
outlier_values
این نتیجه در:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
564 4.8711 27.0 5.082811 0.944793 1499.0 1.880803 37.75 -122.24 2.86600
2167 2.8359 30.0 4.948357 1.001565 1660.0 2.597809 36.78 -119.83 0.80300
2415 2.8250 32.0 4.784232 0.979253 761.0 3.157676 36.59 -119.44 0.67600
2902 1.1875 48.0 5.492063 1.460317 129.0 2.047619 35.38 -119.02 0.63800
6607 3.5164 47.0 5.970639 1.074266 1700.0 2.936097 34.18 -118.14 2.26500
8047 2.7260 29.0 3.707547 1.078616 2515.0 1.977201 33.84 -118.17 2.08700
8243 2.0769 17.0 3.941667 1.211111 1300.0 3.611111 33.78 -118.18 1.00000
9029 6.8300 28.0 6.748744 1.080402 487.0 2.447236 34.05 -118.78 5.00001
11892 2.6071 45.0 4.225806 0.903226 89.0 2.870968 33.99 -117.35 1.12500
12127 4.1482 7.0 5.674957 1.106998 5595.0 3.235975 33.92 -117.25 1.24600
12226 2.8125 18.0 4.962500 1.112500 239.0 2.987500 33.63 -116.92 1.43800
12353 3.1493 24.0 7.307323 1.460984 1721.0 2.066026 33.81 -116.54 1.99400
13534 3.7949 13.0 5.832258 1.072581 2189.0 3.530645 34.17 -117.33 1.06300
13795 1.7567 8.0 4.485173 1.120264 3220.0 2.652389 34.59 -117.42 0.69500
14292 2.6250 50.0 4.742236 1.049689 728.0 2.260870 32.74 -117.13 2.03200
14707 3.7167 17.0 5.034130 1.051195 549.0 1.873720 32.80 -117.05 1.80400
تشخیص ما به پایان رسیده است. اینگونه است که ما هر نقطه داده ای را که از روند کلی داده منحرف می شود، تشخیص می دهیم. میتوانیم ببینیم که 16 نقطه در دادههای قطار ما وجود دارد که باید بیشتر مورد بررسی، بررسی، شاید درمان یا حتی حذف از دادههای ما (اگر به اشتباه وارد شده باشند) برای بهبود نتایج است. این نقاط ممکن است ناشی از اشتباهات تایپی، ناهماهنگی مقادیر میانگین بلوک یا حتی هر دو باشد.
مزایا و معایب KNN
در این بخش، برخی از مزایا و معایب استفاده از الگوریتم KNN را ارائه خواهیم کرد.
طرفداران
- اجرای آن آسان است
- این یک الگوریتم یادگیری تنبل است و بنابراین نیازی به آموزش ندارد روی تمام نقاط داده (فقط با استفاده از K-Nearest همسایگان برای پیش بینی). این باعث می شود الگوریتم KNN بسیار سریعتر از سایر الگوریتم هایی باشد که نیاز به آموزش با کل مجموعه داده مانند ماشین های بردار پشتیبانی، رگرسیون خطی و غیره دارند.
- از آنجایی که KNN قبل از انجام پیشبینی نیازی به آموزش ندارد، میتوان دادههای جدید را بهطور یکپارچه اضافه کرد
- برای کار با KNN فقط دو پارامتر لازم است، یعنی مقدار K و تابع فاصله
منفی
- الگوریتم KNN با دادههای ابعادی بالا به خوبی کار نمیکند، زیرا با تعداد ابعاد زیاد، فاصله بین نقاط “عجیب” میشود و معیارهای فاصلهای که استفاده میکنیم ثابت نمیمانند.
- در نهایت، الگوریتم KNN با ویژگی های طبقه بندی به خوبی کار نمی کند زیرا یافتن فاصله بین ابعاد با ویژگی های طبقه بندی دشوار است.
نتیجه
KNN یک الگوریتم ساده و در عین حال قدرتمند است. می توان از آن برای بسیاری از وظایف مانند رگرسیون، طبقه بندی، یا تشخیص پرت استفاده کرد.
KNN به طور گسترده برای یافتن شباهت اسناد و تشخیص الگو استفاده شده است. همچنین برای توسعه سیستمهای توصیهگر و برای کاهش ابعاد و مراحل پیش پردازش برای بینایی کامپیوتر – بهویژه وظایف تشخیص چهره، استفاده شده است.
در این راهنما – ما از طریق رگرسیون، طبقهبندی و تشخیص نقاط پرت با استفاده از پیادهسازی Scikit-Learn از الگوریتم K-Nearest Neighbor عبور کردهایم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-04 02:19:03
