از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
Keras یک API سطح بالا است که معمولاً با کتابخانه TensorFlow استفاده میشود و مانع ورود بسیاری را کاهش داده و ایجاد مدلها و سیستمهای یادگیری عمیق را دموکراتیک کرده است.
هنگامی که به تازگی شروع به کار می کنید، یک API سطح بالا که بیشتر کارهای درونی را انتزاعی می کند به افراد کمک می کند تا اصول اولیه را درک کنند و شهودی برای شروع ایجاد کنند. با این حال، تمرینکنندگان طبیعتاً میخواهند شهود قویتری از آنچه در زیر سرپوش اتفاق میافتد ایجاد کنند تا هم بینش عملی به دست آورند و هم درک عمیقتری از چگونه مدل آنها یاد می گیرد.
در بسیاری از موارد، نگاهی به یادگیری مفید است process یک شبکه عصبی عمیق، آزمایش چگونگی پیشبینی مقادیر روی هر دوره یادگیری، و حفظ ارزش ها.
این مقادیر ذخیره شده را می توان برای تجسم پیش بینی ها، با استفاده از کتابخانه هایی مانند Matplotlib یا Seaborn استفاده کرد، یا می تواند در یک گزارش برای تجزیه و تحلیل بیشتر در سیستم های هوشمند ذخیره شود، یا به سادگی توسط یک انسان تجزیه و تحلیل شود. ما معمولاً آن را استخراج می کنیم منحنی های یادگیری یک مدل برای به دست آوردن درک بهتری از روش عملکرد آن در طول زمان – اما منحنی های یادگیری منعکس کننده آن هستند معنی از دست دادن در طول زمان، و شما به آن نمی رسید دیدن عملکرد مدل تا پایان آموزش چگونه است.
Keras یک ویژگی فوق العاده دارد – پاسخ به تماس ها که تکه کدهایی هستند که در حین آموزش فراخوانی می شوند و می توان از آنها برای سفارشی سازی آموزش استفاده کرد process. معمولاً، شما از تماسهای برگشتی برای ذخیره مدل در صورت عملکرد خوب استفاده میکنید، در صورت مناسب بودن بیش از حد، آموزش را متوقف میکنید، یا در غیر این صورت به مراحل یادگیری واکنش نشان میدهید یا بر مراحل یادگیری تأثیر میگذارید. process.
این باعث می شود پاسخ به تماس ها انتخاب طبیعی برای اجرای پیش بینی ها روی هر دسته یا دوره، و ذخیره نتایج، و در این راهنما – ما نگاهی به روش اجرای یک پیش بینی خواهیم داشت روی مجموعه تست، نتایج را تجسم کنید و آنها را به عنوان تصویر ذخیره کنید، روی هر دوره آموزشی در کراس.
توجه داشته باشید: ما یک مدل یادگیری عمیق ساده با استفاده از Keras در بخشهای بعدی میسازیم، اما تمرکز زیادی روی آن نخواهد داشت. روی پیاده سازی یا مجموعه داده این به معنای راهنمایی برای ساخت مدل های رگرسیون نیست، بلکه یک مدل است است برای نشان دادن روش عملکرد برگشت تماس به درستی مورد نیاز است.
اگر علاقه مند به خواندن بیشتر در مورد هستید چگونه برای ساخت این مدل ها و روش بدست آوردن آنها بسیار دقیق به جای فقط دقیق – پیش بینی قیمت خانه گسترده و دقیق ما – یادگیری ماشینی با پایتون را بخوانید!
ساخت و ارزیابی یک مدل یادگیری عمیق با Keras
بیایید یک مدل Keras ساده برای اهداف تصویری بسازیم. ما از طریق این بخش با حداقل تمرکز و توجه سرعت خواهیم گرفت – این یک راهنما نیست روی ساخت مدل های رگرسیون ما با آن کار خواهیم کرد مجموعه داده مسکن کالیفرنیا، از طریق Scikit-Learn به دست آمده است datasets ماژول، که مجموعه داده ای است که برای پسرفت.
بریم جلو و import کتابخانه ها و روش های استاتیکی که ما استفاده خواهیم کرد:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
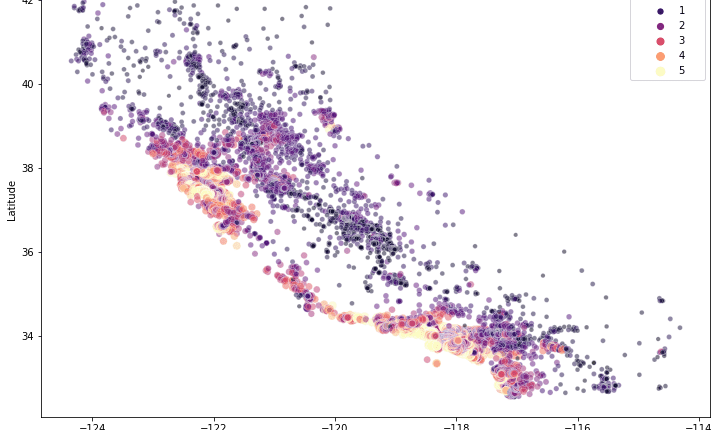
اکنون، بیایید مجموعه داده را بارگیری کنیم، آن را به یک مجموعه آموزشی و آزمایشی تقسیم کنیم (مجموعه اعتبارسنجی را بعداً تقسیم خواهیم کرد)، و مکان خانه ها را تجسم کنیم تا بررسی کنیم که آیا داده ها به درستی بارگیری شده اند یا خیر:
X, y = fetch_california_housing(as_frame=True, return_X_y=True)
x_train, x_test, y_train, y_test = train_test_split(x, y)
plt.figure(figsize=(12, 8))
sns.scatterplot(data=x, x='Longitude', y='Latitude', size=y, alpha=0.5, hue=y, palette='magma')
plt.show()

شبیه کالیفرنیا! از آنجایی که داده ها به درستی بارگذاری شده اند، می توانیم یک مدل Keras متوالی ساده تعریف کنیم:
checkpoint = keras.callbacks.ModelCheckpoint("california.h5", save_best_only=True)
model = keras.Sequential((
keras.layers.Dense(64, activation='relu', kernel_initializer='normal', kernel_regularizer="l2", input_shape=(x_train.shape(1))),
keras.layers.Dropout(0.2),
keras.layers.BatchNormalization(),
keras.layers.Dense(64, activation='relu', kernel_initializer='normal', kernel_regularizer="l2"),
keras.layers.Dropout(0.2),
keras.layers.BatchNormalization(),
keras.layers.Dense(1)
))
model.compile(loss='mae',
optimizer=keras.optimizers.RMSprop(learning_rate=1e-2, decay=0.1),
metrics=('mae'))
history = model.fit(
x_train, y_train,
epochs=150,
batch_size=64,
validation_split=0.2,
callbacks=(checkpoint)
)
در اینجا، ما یک MLP ساده داریم، با کمی Dropout و Batch Normalization برای مبارزه با بیشبرازش، بهینهسازی شده با RMSprop بهینه ساز و الف میانگین خطای مطلق ضرر – زیان. ما مدل را برای 150 دوره، با تقسیم اعتبار، نصب کرده ایم 0.2، و الف ModelCheckpoint برای ذخیره وزن ها در یک فایل. اجرای این نتیجه می شود:
...
Epoch 150/150
387/387 (==============================) - 3s 7ms/step - loss: 0.6279 - mae: 0.5976 - val_loss: 0.6346 - val_mae: 0.6042
ما میتوانیم منحنیهای یادگیری را تجسم کنیم تا بینش اساسی در مورد روش انجام آموزش به دست آوریم، اما این کل داستان را به ما نمیگوید – اینها فقط مجموع مجموعههای آموزشی و اعتبارسنجی در طول آموزش هستند:
model_history = pd.DataFrame(history.history)
model_history('epoch') = history.epoch
fig, ax = plt.subplots(1, figsize=(8,6))
num_epochs = model_history.shape(0)
ax.plot(np.arange(0, num_epochs), model_history("mae"),
label="Training MAE")
ax.plot(np.arange(0, num_epochs), model_history("val_mae"),
label="Validation MAE")
ax.legend()
plt.tight_layout()
plt.show()
این منجر به:

و ما می توانیم مدل خود را با:
model.evaluate(x_test, y_test)
162/162 (==============================) - 0s 2ms/step - loss: 0.5695 - mae: 0.5451 - mape: 32.2959
همانطور که متغیر هدف در مضرب اندازه گیری می شود 100000 دلار، یعنی شبکه ما تا حدودی قیمت را از دست می دهد 54000 دلار، که یک است میانگین درصد مطلق خطا از ~ 32٪. اکثر روشهای سنتی یادگیری ماشین مانند رگرسیون جنگل تصادفی، حتی پس از پیشپردازش دادههای گستردهتر برای این مجموعه داده 52000 دلار، با فراپارامترهای تنظیم شده – بنابراین این در واقع یک نتیجه بسیار مناسب است، اگرچه می توان آن را با پیش پردازش بیشتر، تنظیم بهتر و معماری های مختلف بهبود بخشید.
نکته اینجا ساختن یک مدل به خصوص دقیق نبود، اما ما مجموعه داده ای را انتخاب کردیم که با استفاده از آن مدل خیلی سریع همگرا نشود، بنابراین می توانیم رقص آن را در اطراف متغیرهای هدف مشاهده کنیم.
روشی گویاتر برای ارزیابی اینکه چگونه کار مدل از کل جدا می شود میانگین خطای مطلق و میانگین درصد مطلق خطا به طور کامل، و ما می توانیم یک نمودار پراکنده از قیمت های پیش بینی شده بر خلاف قیمت های واقعی. اگر آنها برابر باشند – نشانگرهای رسم شده یک مسیر مستقیم را به صورت مورب دنبال می کنند. برای مرجع و دامنه – ما همچنین می توانیم یک خط مورب رسم کنیم و ارزیابی کنیم که هر نشانگر چقدر به خط نزدیک است:
test_predictions = model.predict(x_test)
test_labels = y_test
fig, ax = plt.subplots(figsize=(8,4))
plt.scatter(test_labels, test_predictions, alpha=0.6,
color='#FF0000', lw=1, ec='black')
lims = (0, 5)
plt.plot(lims, lims, lw=1, color='#0000FF')
plt.ticklabel_format(useOffset=False, style='plain')
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.xlim(lims)
plt.ylim(lims)
plt.tight_layout()
plt.show()
اجرای این کد نتیجه می دهد:

این شبکه خانههای ارزانتر را بیش از حد قیمتگذاری میکند و خانههای گرانتر را زیر قیمت میگذارد – و برآوردها دامنه بسیار سخاوتمندانهای دارند (با برخی پیشبینیها) روی حق کاملاً خارج از محدوده است – هرچند، این اتفاق می افتد زیرا ما مجموعه داده و بسیاری از قیمت خانه ها را پاک نکرده ایم هستند در هنگام واردات در آن مقدار محدود می شود).
این بینشی نیست که از منحنیهای یادگیری دریافت میکنید، و شبکهای که اثر معکوس داشت – قیمتگذاری کمتر از خانههای ارزانتر و قیمتگذاری بیش از حد خانههای گرانقیمت ممکن است MAE و MAPE یکسانی داشته باشد، اما رفتار کاملا متفاوتی داشته باشد.
چیزی که ما نیز به آن علاقه مندیم این است چگونه مدل به اینجا رسید و چگونه این پیش بینی ها در طول زمان و یادگیری تغییر کردند process. این فقط نقطه پایان آموزش است process، و برای رسیدن به اینجا کمی آموزش لازم بود.
بیایید جلو برویم و بنویسیم پاسخ به تماس سفارشی برای افزودن به لیست تماس های موجود در آموزش process، که یک پیش بینی را اجرا می کند روی مجموعه تست روی هر دوره، پیش بینی ها را تجسم کنید و آنها را به عنوان یک تصویر ذخیره کنید.
پیشبینی سفارشی پاسخ به تماس Keras با طرحها
درست همانطور که ما از آن استفاده کرده ایم ModelCheckpoint برای بررسی اینکه آیا یک مدل در بهترین حالت خود قرار دارد یا خیر روی هر دوره، و ذخیره آن در یک .h5 فایل و آن را ادامه دهید – می توانیم a بنویسیم پاسخ به تماس سفارشی که پیش بینی ها را اجرا می کند، آنها را تجسم می کند و تصاویر را ذخیره می کند روی دیسک ما
ایجاد یک تماس سفارشی به گسترش آن خلاصه می شود Callback کلاس و نادیده گرفتن هر یک از روش هایی که ارائه می دهد – آنهایی که شما نکن لغو، رفتار پیش فرض خود را حفظ کنند:
class PerformancePlotCallback(keras.callbacks.Callback):
def on_train_end(self, logs=None):
...
def on_epoch_begin(self, epoch, logs=None):
...
def on_epoch_end(self, epoch, logs=None):
...
def on_test_begin(self, logs=None):
...
def on_test_end(self, logs=None):
...
بسته به روی چه زمانی اگر می خواهید با استفاده از مدل آموزشی خود پیش بینی کنید، روش مناسب را انتخاب خواهید کرد. معیار خوبی برای چگونگی پیشرفت آن است دوران، بنابراین در پایان هر دوره آموزشی، مدل را آزمایش می کنیم روی مجموعه تست ما
ما به راهی نیاز داریم که مجموعه آزمایشی را برای پاسخ به تماس ارائه کنیم، زیرا این داده خارجی است. ساده ترین راه برای انجام این کار، تعریف a است سازنده که مجموعه تست را می پذیرد و ارزیابی می کند مدل فعلی روی آن، به شما یک نتیجه ثابت می دهد:
class PerformancePlotCallback(keras.callbacks.Callback):
def __init__(self, x_test, y_test):
self.x_test = x_test
self.y_test = y_test
def on_epoch_end(self, epoch, logs=None):
print('Evaluating Model...')
print('Model Evaluation: ', self.model.evaluate(self.x_test))
این فراخوان ساده مجموعه آزمایشی خانه ها و متغیرهای هدف مربوطه را می پذیرد و خود را ارزیابی می کند روی هر دوره، چاپ نتیجه به console، درست در کنار خروجی معمولی Keras.
اگر بخواهیم نمونه سازی کنیم و این callback را به مدل اضافه کنیم، و fit() باز هم نتیجه ای متفاوت از قبل خواهیم دید:
performance_simple = PerformancePlotCallback(x_test, y_test)
history = model.fit(
x_train, y_train,
epochs=150,
validation_split=0.2,
callbacks=(performance_simple)
)
این منجر به:
Epoch 1/150
387/387 (==============================) - 3s 7ms/step - loss: 1.0785 - mae: 1.0140 - val_loss: 0.9455 - val_mae: 0.8927
Evaluating Model...
162/162 (==============================) - 0s 1ms/step - loss: 0.0528 - mae: 0.0000e+00
Model Evaluation: (0.05277165770530701, 0.0)
Epoch 2/150
387/387 (==============================) - 3s 7ms/step - loss: 0.9048 - mae: 0.8553 - val_loss: 0.8547 - val_mae: 0.8077
Evaluating Model...
162/162 (==============================) - 0s 1ms/step - loss: 0.0471 - mae: 0.0000e+00
Model Evaluation: (0.04705655574798584, 0.0)
...
عالی! مدل در حال ارزیابی خود است روی هر دوره، روی دادههایی که به تماس برگشت دادهایم. اکنون، بیایید پاسخ تماس را تغییر دهیم تا پیشبینیها را بهجای چاپ آنها در خروجیهای به هم ریخته، تجسم کند.
برای سادهتر کردن کارها، برای ذخیره تصاویر در یک پوشه، پاسخ تماس را دریافت میکنیم تا بعداً بتوانیم آنها را در یک ویدیو یا یک Gif به هم پیوند دهیم. روی. ما همچنین شامل یک model_name در سازنده برای کمک به ما در تمایز مدل ها هنگام تولید تصاویر و نام فایل های آنها:
class PerformancePlotCallback(keras.callbacks.Callback):
def __init__(self, x_test, y_test, model_name):
self.x_test = x_test
self.y_test = y_test
self.model_name = model_name
def on_epoch_end(self, epoch, logs={}):
y_pred = self.model.predict(self.x_test)
fig, ax = plt.subplots(figsize=(8,4))
plt.scatter(y_test, y_pred, alpha=0.6,
color='#FF0000', lw=1, ec='black')
lims = (0, 5)
plt.plot(lims, lims, lw=1, color='#0000FF')
plt.ticklabel_format(useOffset=False, style='plain')
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.xlim(lims)
plt.ylim(lims)
plt.tight_layout()
plt.title(f'Prediction Visualization Keras Callback - Epoch: {epoch}')
plt.savefig('model_train_images/'+self.model_name+"_"+str(epoch))
plt.close()
در اینجا، یک شکل Matplotlib ایجاد می کنیم روی هر دوره، و نمودار پراکنده ای از قیمت های پیش بینی شده را در برابر قیمت های واقعی ترسیم کنید. علاوه بر این، ما یک خط مرجع مورب اضافه کردهایم – هر چه نشانگرهای نمودار پراکندگی ما به خط مورب نزدیکتر باشد، پیشبینیهای مدل ما دقیقتر بود.
سپس طرح از طریق ذخیره می شود plt.savefig() با نام مدل و شماره دوره، همراه با عنوانی آموزنده که به شما امکان می دهد بدانید مدل در کدام دوره در طول آموزش است.
حال، بیایید دوباره از این بازخوانی سفارشی استفاده کنیم و نام مدل را علاوه بر x_test و y_test مجموعه ها:
checkpoint = keras.callbacks.ModelCheckpoint("california.h5", save_best_only=True)
performance = PerformancePlotCallback(x_test, y_test, "california_model")
history = model.fit(
x_train, y_train,
epochs=150,
validation_split=0.2,
callbacks=(checkpoint, performance)
)
را PerformancePlotCallback در نوسان کامل می رود و در پوشه تعیین شده تصویری از عملکرد تولید می کند روی هر دوره را model_train_images پوشه اکنون با 150 نمودار پر شده است:

اکنون می توانید از ابزار مورد علاقه خود برای پیوند دادن تصاویر به یک ویدیو یا یک فایل Gif استفاده کنید یا به سادگی آنها را به صورت دستی مطالعه کنید. در اینجا یک Gif از مدلی است که ما برای آموزش ساختیم روی این داده:

نتیجه
در این راهنما، ما یک مدل ساده برای پیشبینی قیمت یک خانه در مجموعه دادههای مسکن کالیفرنیا با دقت بسیار خوبی ساختهایم. سپس نگاهی به روش نوشتن یک فراخوان سفارشی Keras برای آزمایش عملکرد یک مدل یادگیری عمیق و تجسم آن در طول آموزش انداخته ایم. روی هر دوره
ما اقدام به ذخیره این تصاویر در دیسک کرده ایم و یک Gif از آنها ایجاد کرده ایم که به ما دیدگاه متفاوتی می دهد روی تمرین process نسبت به چیزی که از تجزیه و تحلیل منحنی های یادگیری یک مدل به دست می آوریم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-07 19:11:03
