از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
اجازه دهید عنوان بالقوه تحریک آمیز را با این مقدمه بیان کنم:
درست است، هیچ کس نمی خواهد بیش از حد مدلهای نهایی، درست مثل چیزی که هیچکس نمیخواهد کم تناسب مدل های پایانی
مدل های Overfit عملکرد عالی روی داده های آموزشی، اما نمی توانند به خوبی به نمونه های جدید تعمیم دهند. چیزی که در نهایت به آن دست مییابید، مدلی است که به یک مدل کاملاً کدگذاری شده و متناسب با یک مجموعه داده خاص نزدیک میشود.
مدل های Underfit نمی توانند به داده های جدید تعمیم دهند، اما نمی توانند مجموعه آموزشی اصلی را نیز مدل کنند.
این مدل درست داده ای است که به گونه ای با داده ها مطابقت دارد که مقادیر پیش بینی کننده خوبی را در مجموعه آموزش، اعتبار سنجی و تست و همچنین نمونه های جدید انجام دهد.
تطبیق بیش از حد در مقابل دانشمندان داده
مبارزه با بیشبرازشها مورد توجه قرار گرفته است، زیرا برای یک تازهکار وسوسهانگیزتر و وسوسهانگیزتر است که وقتی سفر یادگیری ماشینی خود را شروع میکند، مدلهای اضافهفیت ایجاد کند. در سراسر کتابها، پستهای وبلاگ و دورهها، یک سناریوی مشترک ارائه میشود:
“این مدل دارای یک میزان دقت 100%! عالیه! یا نه. در واقع، به شدت به مجموعه دادهها و هنگام آزمایش آن تناسب دارد روی نمونه های جدید، آن را انجام می دهد با فقط X%، که برابر با حدس زدن تصادفی است.”
پس از این بخش ها، کل فصل های کتاب و دوره به آن اختصاص داده شده است مبارزه با بیش از حد مناسب و روش اجتناب از آن این کلمه به عنوان یک ننگ شد به طور کلی چیز بد. و اینجاست که مفهوم کلی مطرح می شود:
“من باید به هر قیمتی از بیش از حد جلوگیری کنم.”
به آن توجه بیشتری نسبت به عدم تناسب داده شده است، که به همان اندازه “بد” است. شایان ذکر است که «بد» یک اصطلاح دلخواه است و هیچ یک از این شرایط ذاتاً «خوب» یا «بد» نیستند. برخی ممکن است ادعا کنند که مدل های بیش از حد از نظر فنی بیشتر هستند مفید، زیرا حداقل عملکرد خوبی دارند روی برخی از داده ها در حالی که مدل های زیرنویس عملکرد خوبی دارند روی اطلاعاتی وجود ندارد، اما توهم موفقیت کاندیدای خوبی برای غلبه بر این مزیت است.
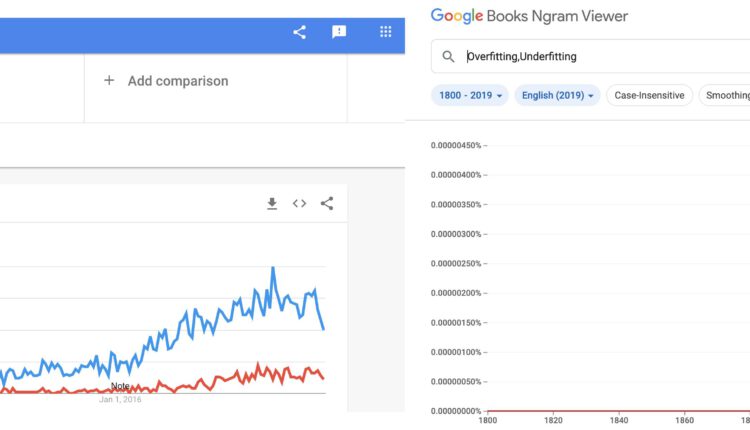
برای مرجع ، بیایید مشورت کنیم Google Trends و Google Ngram Viewer. Google Trends روندهای دادههای جستجو را نمایش میدهد، در حالی که Google Ngram Viewer تعداد وقوع آن را میشمارد n-گرم (توالی از n مواردی مانند کلمات) در ادبیات، تجزیه و تحلیل تعداد زیادی کتاب در طول اعصار:

همه در مورد بیش از حد و بیشتر در زمینه اجتناب از آن صحبت می کنند – که اغلب اوقات مردم را به یک تصور کلی سوق می دهد ذاتا یک چیز بد.
این هست درست است، واقعی، به الف درجه. بله – شما نمی خواهید که مدل پایان بیش از حد بیش از حد افزایش یابد ، در غیر این صورت ، عملاً بی فایده است. اما شما بلافاصله به مدل پایان نمی رسید – بارها و بارها آن را با هایپرپارامترهای مختلف تغییر می دهید. در طی این process جایی است که شما نباید به دیدن اتفاقات بیش از حد توجه کرد – این یک نشانه خوب، اگر چه، نتیجه خوبی نیست.
چقدر بیش از حد بد نیست به همان اندازه که ساخته شده است
یک مدل و معماری که توانایی بیش از حد برازش را دارد، اگر آن را ساده کنید (و/یا داده ها را تغییر دهید) به احتمال زیاد توانایی تعمیم خوبی به نمونه های جدید را دارد.
- بعضی اوقات ، فقط مربوط به مدل نیست ، همانطور که بعداً می بینیم.
اگر یک مدل می توان بیش از حد، آن را به اندازه کافی است ظرفیت آنتروپیک برای استخراج ویژگی ها (به روشی معنی دار و غیر معنادار) از داده ها. از آنجا، یا این است که مدل بیش از ظرفیت آنتروپیک مورد نیاز (پیچیدگی/قدرت) دارد یا اینکه خود داده کافی نیست (مورد بسیار رایج).
بیانیه معکوس نیز می تواند صحیح باشد ، اما به ندرت. اگر مدل یا معماری معینی مناسب نیست، میتوانید مدل را تغییر دهید تا ببینید آیا ویژگیهای خاصی را انتخاب میکند یا خیر، اما نوع مدل ممکن است برای این کار اشتباه باشد و شما نتوانید دادهها را با آن تطبیق دهید. مهم است که چه کاری انجام می دهید برخی از مدل ها فقط در سطحی از دقت گیر می کنند، زیرا نمی توانند ویژگی های کافی برای تمایز بین کلاس های خاص یا پیش بینی مقادیر را استخراج کنند.
که در پخت و پز، یک قیاس معکوس ایجاد می شود. بهتر است زودتر از نمک کمتری در خورش استفاده کنید روی، همانطور که همیشه می توانید بعداً نمک اضافه کنید تا طعم آن را بخورید ، اما سخت است که یک بار از قبل آن را بردارید.
که در فراگیری ماشین – برعکس است. بهتر است یک مدل overfit داشته باشید، سپس آن را ساده کنید، هایپرپارامترها را تغییر دهید، داده ها را تقویت کنید و غیره را به خوبی تعمیم دهید، اما انجام برعکس آن (در تنظیمات عملی) دشوارتر است. اجتناب از نصب بیش از حد قبل از این اتفاق ممکن است خیلی خوب شما را از یافتن مدل مناسب و/یا معماری برای مدت زمان طولانی تر دور کند.
در عمل ، و در برخی از جذاب ترین موارد استفاده از یادگیری ماشین و یادگیری عمیق ، کار خواهید کرد روی مجموعه داده هایی که در آن مشکل دارید. اینها مجموعههای دادهای هستند که معمولاً از آنها استفاده نمیکنید، بدون اینکه توانایی پیدا کردن مدلها و معماریهایی را داشته باشید که بتوانند به خوبی تعمیم داده و ویژگیها را استخراج کنند.
همچنین شایان ذکر است که تفاوت بین آنچه من می گویم بیش از حد واقعی و اضافه تناسب جزئی. مدلی که از یک مجموعه داده استفاده می کند و به دقت 60 ٪ دست می یابد روی مجموعه آموزشی، تنها با 40% روی مجموعههای اعتبارسنجی و آزمایش بیش از حد بخشی از دادهها را برازش میکنند. با این حال، اینطور نیست واقعا بیش از حد مناسب به معنای تحت الشعاع قرار دادن کل مجموعه داده، و دستیابی به نرخ دقت نزدیک به 100٪ (کاذب)، در حالی که اعتبارسنجی و مجموعه های آزمایشی آن، مثلاً 40٪ پایین است.
مدلی که تا حدی بیش از حد از آن استفاده می کند ، آن چیزی نیست که بتواند با ساده سازی به خوبی تعمیم دهد ، همانطور که ندارد کافی ظرفیت آنتروپیک برای تناسب واقعی (بیش از). به محض انجام، استدلال من اعمال می شود، اگرچه موفقیت را تضمین نمی کند، همانطور که در بخش های بعدی توضیح داده شد.
مطالعه موردی – استدلال بیش از حد دوستانه
این مجموعه داده ارقام دست نویس MNIST، گردآوری شده توسط Yann LeCun یکی از مجموعه داده های معیار کلاسیک است که برای مدل های طبقه بندی آموزشی استفاده می شود. LeCun به طور گسترده ای به عنوان یکی از بنیانگذاران یادگیری عمیق در نظر گرفته می شود – با مشارکت در این زمینه که اکثر آنها نمی توانند در کمربند خود قرار دهند، و مجموعه داده ارقام دست نویس MNIST یکی از اولین معیارهای اصلی مورد استفاده برای مراحل اولیه شبکه های عصبی کانولوشن بود. .
همچنین این مجموعه داده بیش از حد مورد استفاده قرار گرفته است، به طور بالقوه.
هیچ مشکلی در خود مجموعه داده وجود ندارد، و نه با LeCun که آن را ایجاد کرده است – در واقع بسیار خوب است، اما یافتن نمونه به مثال روی همان مجموعه داده آنلاین کسل کننده است. در یک نقطه – ما خودمان را بیش از حد آماده می کنیم نگاه کردن به آن چقدر؟ در اینجا تلاش من برای فهرست کردن ده رقم اول MNIST از بالای سر من است:
5, 0, 4, 1, 9, 2, 2, 4, 3
چه کار کردم؟
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
(X_train_full, Y_train_full), (X_test, Y_test) = keras.datasets.mnist.load_data()
X_valid, X_train = X_train_full(:5000)/255.0, X_train_full(5000:)/255.0
Y_valid, Y_train = Y_train_full(:5000), Y_train_full(5000:)
X_test = X_test/255.0
fig, ax = plt.subplots(1, 10, figsize=(10,2))
for i in range(10):
ax(i).imshow(X_train_full(i))
ax(i).axis('off')
plt.subplots_adjust(wspace=1)
plt.show()

تقریباً وجود دارد.
من از این فرصت برای درخواست عمومی از همه سازندگان محتوا استفاده خواهم کرد که از این مجموعه داده فراتر از قسمت های مقدماتی استفاده نکنند، جایی که می توان از سادگی مجموعه داده برای کاهش مانع ورود استفاده کرد. لطفا.
علاوه بر این، این مجموعه داده ساختن مدلی را که مناسب نیست دشوار می کند. این خیلی ساده است – و حتی یک نسبتاً کوچک Perceptron چند لایه (MLP) طبقه بندی کننده ساخته شده با تعداد بصری لایه ها و نورون ها در هر لایه می تواند به راحتی به دقت بالای 98 درصد برسد. روی مجموعه آموزش ، آزمایش و اعتبار سنجی. اینجا یک Jupyter نوت بوک از یک MLP ساده دستیابی به دقت 98 ~ روی هم مجموعههای آموزش، اعتبارسنجی و تست، که من با پیشفرضهای معقول ایجاد کردم.
من حتی به خود زحمت نداده ام که آن را تنظیم کنم تا عملکرد بهتری نسبت به تنظیمات اولیه داشته باشد.
مجموعه داده های CIFAR10 و CIFAR100
بیایید از مجموعه دادهای استفاده کنیم که پیچیدهتر از ارقام دستنویس MNIST است، و باعث میشود یک MLP ساده کمتر شود، اما به اندازهای ساده است که به یک CNN با اندازه مناسب اجازه میدهد واقعاً بیش از حد مناسب باشد. روی آی تی. یک کاندیدای خوب است مجموعه داده CIFAR.
10 کلاس تصویر در CIFAR10 و 100 در CIFAR100 وجود دارد. علاوه بر این، مجموعه داده CIFAR100 دارای 20 خانواده است مشابه کلاسها، به این معنی که شبکه علاوه بر این باید تفاوتهای جزئی بین کلاسهای مشابه، اما متفاوت را بیاموزد. اینها به عنوان شناخته می شوند “برچسب های خوب” (100) و “برچسب های درشت” (20) و پیشبینی اینها برابر است با پیشبینی طبقه خاص یا فقط خانوادهای که به آن تعلق دارد.
برای مثال، در اینجا یک سوپرکلاس (برچسب درشت) و زیر کلاسها (برچسبهای ظریف) وجود دارد:
| سوپرکلاس | زیر کلاس ها |
| ظروف غذا | بطری، کاسه، قوطی، فنجان، بشقاب |
یک فنجان یک استوانه است، شبیه به قوطی نوشابه، و ممکن است برخی بطری ها نیز چنین باشند. از آنجایی که این ویژگیهای سطح پایین نسبتاً مشابه هستند، به راحتی میتوان همه آنها را در نظر گرفت “غذا container” دسته، اما انتزاع سطح بالاتر مورد نیاز است تا به درستی حدس بزنیم که آیا چیزی a است یا خیر “فنجان” یا الف “می توان”.
چیزی که این کار را سختتر میکند این است که CIFAR10 دارای 6000 تصویر در هر کلاس است، در حالی که CIFAR100 دارای 600 تصویر در هر کلاس است که به شبکه تصاویر کمتری برای یادگیری تفاوتهای بسیار ظریف میدهد. فنجان های بدون دسته وجود دارند و قوطی های بدون برجستگی نیز وجود دارند. از یک نمایه – ممکن است تشخیص آنها خیلی آسان نباشد.

اینجاست که مثلاً الف پرسپترون چند لایه به سادگی قدرت انتزاعی برای یادگیری را ندارد و محکوم به شکست است که به طرز وحشتناکی نادرست است. شبکه های عصبی کانولوشنال بر اساس ساخته شده اند روی را نئوگنیترون، که نکاتی را از علوم اعصاب و تشخیص الگوی سلسله مراتبی که مغز انجام می دهد گرفته شده است. این شبکه ها می توانند ویژگی هایی مانند این را استخراج کنند و در این کار برتری پیدا کنند. به حدی که غالباً بهخوبی بر روی هم قرار میگیرند و در نهایت نمیتوان آنها را همانطور که هست استفاده کرد – جایی که ما معمولاً به خاطر توانایی تعمیم بخشی از دقت را قربانی میکنیم.
بیایید دو معماری شبکه متفاوت را آموزش دهیم روی مجموعه داده های CIFAR10 و CIFAR100 به عنوان تصویری از نظر من.
همچنین در اینجاست که میتوانیم ببینیم که چگونه حتی زمانی که یک شبکه بیش از حد برازش میکند، تضمینی نیست که خود شبکه در صورت سادهسازی، قطعاً به خوبی تعمیم مییابد – اگر سادهسازی شود، ممکن است قادر به تعمیم نباشد، اگرچه گرایشی وجود دارد. شبکه ممکن است باشد درست، اما داده ها ممکن است کافی نباشد
در مورد CIFAR100 – فقط 500 تصویر برای آموزش (و 100 تصویر برای آزمایش) در هر کلاس برای یک CNN ساده کافی نیست. واقعا خوب تعمیم دهید روی کل 100 کلاس، و ما باید برای کمک به آن، افزایش داده را انجام دهیم. حتی با افزایش دادهها، ممکن است شبکه بسیار دقیقی به دست نیاوریم زیرا کارهای زیادی میتوانید برای دادهها انجام دهید. اگر همین معماری به خوبی عمل کند روی CIFAR10، اما نه CIFAR100 – به این معنی است که به سادگی نمی تواند از برخی از جزئیات ریزدانه تر که تفاوت را بین اجسام استوانه ای که به عنوان مثال “فنجان”، “قوطی” و “بطری” می نامیم، متمایز کند.
این اکثریت قریب به اتفاق از معماری شبکه های پیشرفته که به دقت بالایی دست می یابند روی مجموعه داده CIFAR100 افزایش داده را انجام می دهد یا مجموعه آموزشی را گسترش می دهد.
بیشتر آنها بایدو این نشانه مهندسی بد نیست. در واقع – این واقعیت که ما میتوانیم این مجموعه دادهها را گسترش دهیم و به شبکهها کمک کنیم تا بهتر تعمیم پیدا کنند، نشانهای از نبوغ مهندسی است.
بهعلاوه، من از هر انسانی دعوت میکنم اگر متقاعد شده است که طبقهبندی تصاویر با تصاویری به کوچکی 32×32 کار سختی نیست، امتحان کند و حدس بزند که اینها چیستند:

است تصویر 4 چند پرتقال؟ توپ های پینگ پنگ؟ زرده تخم مرغ؟ خوب، احتمالاً زرده تخم مرغ نیست، اما این نیاز به دانش قبلی دارد روی “تخم مرغ” چیست و آیا احتمال دارد زرده ها را در حالت نشسته پیدا کنید روی جدولی که یک شبکه نخواهد داشت. میزان دانش قبلی که ممکن است در مورد جهان داشته باشید و میزان تأثیر آن بر آنچه که می بینید را در نظر بگیرید.
وارد کردن داده ها
ما از Keras بهعنوان کتابخانه یادگیری عمیق انتخابی استفاده خواهیم کرد، اما در صورت تمایل میتوانید کتابخانههای دیگر یا حتی مدلهای سفارشی خود را دنبال کنید.
اما ابتدا، اجازه دهید آن را بارگذاری کنیم، داده ها را در یک مجموعه آموزشی، آزمایشی و اعتبار سنجی جدا کنیم، و مقادیر تصویر را عادی کنیم. 0..1:
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
(X_train_full, Y_train_full), (X_test, Y_test) = keras.datasets.cifar10.load_data()
X_valid, X_train = X_train_full(:5000)/255.0, X_train_full(5000:)/255.0
Y_valid, Y_train = Y_train_full(:5000), Y_train_full(5000:)
X_test = X_test/255.0
سپس، اجازه دهید برخی از تصاویر موجود در مجموعه داده را تجسم کنیم تا ایده ای در مورد آنچه که در مقابل آن قرار داریم به دست آوریم:
fig, ax = plt.subplots(5, 5, figsize=(10, 10))
ax = ax.ravel()
class_names = ('Airplane', 'Automobile', 'Bird', 'Cat', 'Deer', 'Dog', 'Frog', 'Horse', 'Ship', 'Truck')
for i in range(25):
ax(i).imshow(X_train_full(i))
ax(i).set_title(class_names(Y_train_full(i)(0)))
ax(i).axis('off')
plt.subplots_adjust(wspace=1)
plt.show()

عدم تناسب پرسپترون چندلایه
تقریباً مهم نیست که ما چه کاری انجام می دهیم، MLP آنقدر خوب عمل نمی کند. قطعاً به سطحی از دقت بر اساس خواهد رسید روی توالی خام اطلاعاتی که وارد می شود – اما این تعداد محدود است و احتمالاً خیلی زیاد نخواهد بود.
شبکه در یک نقطه شروع به نصب بیش از حد میکند و توالیهای مشخص دادهها را نشان میدهد، اما همچنان دقت پایینی خواهد داشت. روی مجموعه آموزشی حتی در هنگام نصب بیش از حد، که بهترین زمان برای متوقف کردن آموزش آن است، زیرا به سادگی نمی تواند به خوبی با داده ها سازگار شود. می دانید شبکه های آموزشی ردپای کربن دارند.
بیایید یک را اضافه کنیم EarlyStopping برای جلوگیری از اجرای شبکه فراتر از نقطه عقل سلیم، و تنظیم کنید epochs به عددی فراتر از آنچه که آن را اجرا خواهیم کرد (بنابراین EarlyStopping می تواند وارد شود).
ما از Sequential API برای اضافه کردن چند لایه استفاده خواهیم کرد BatchNormalization و کمی از Dropout. آنها به تعمیم کمک می کنند و ما حداقل می خواهیم تلاش کردن برای اینکه این مدل چیزی یاد بگیرد.
هایپرپارامترهای اصلی که می توانیم در اینجا تغییر دهیم عبارتند از: تعداد لایه ها، اندازه آنها، توابع فعال سازی، مقداردهی اولیه هسته و نرخ انصراف، و در اینجا یک تنظیم “مناسب” وجود دارد:
checkpoint = keras.callbacks.ModelCheckpoint("simple_dense.h5", save_best_only=True)
early_stopping = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
model = keras.Sequential((
keras.layers.Flatten(input_shape=(32, 32, 3)),
keras.layers.BatchNormalization(),
keras.layers.Dense(75),
keras.layers.Dense((50), activation='elu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.1),
keras.layers.Dense((50), activation='elu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.1),
keras.layers.Dense(10, activation='softmax')
))
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Nadam(learning_rate=1e-4),
metrics=("accuracy"))
history = model.fit(X_train,
Y_train,
epochs=150,
validation_data=(X_valid, Y_valid),
callbacks=(checkpoint, early_stopping))
بیایید ببینیم آیا فرضیه آغازین درست است یا خیر – شروع به یادگیری و تعمیم تا حدی می کند، اما در نهایت دقت پایینی خواهد داشت. روی هم مجموعه آموزشی و هم مجموعه تست و اعتبار سنجی، که منجر به دقت کلی پایین می شود.
برای CIFAR10، شبکه به خوبی عمل می کند:
Epoch 1/150
1407/1407 (==============================) - 5s 3ms/step - loss: 1.9706 - accuracy: 0.3108 - val_loss: 1.6841 - val_accuracy: 0.4100
...
Epoch 50/150
1407/1407 (==============================) - 4s 3ms/step - loss: 1.2927 - accuracy: 0.5403 - val_loss: 1.3893 - val_accuracy: 0.5122
بیایید نگاهی به تاریخچه یادگیری آن بیندازیم:
pd.DataFrame(history.history).plot()
plt.show()
model.evaluate(X_test, Y_test)

313/313 (==============================) - 0s 926us/step - loss: 1.3836 - accuracy: 0.5058
(1.383605718612671, 0.5058000087738037)
دقت کلی تا 50% می رسد و شبکه خیلی سریع به اینجا می رسد و شروع به فلات می کند. 5/10 تصاویر به درستی طبقه بندی شده به نظر می رسد مانند پرتاب یک سکه ، اما به یاد داشته باشید که در اینجا 10 کلاس وجود دارد ، بنابراین اگر به طور تصادفی حدس می زدند ، می توانست روی حدس متوسط یک تصویر از ده. بیایید به مجموعه داده CIFAR100 برویم، که همچنین به شبکه ای با حداقل کمی قدرت بیشتر نیاز دارد، زیرا نمونه های آموزشی کمتری در هر کلاس وجود دارد و همچنین تعداد کلاس های بسیار بالاتری وجود دارد:
checkpoint = keras.callbacks.ModelCheckpoint("bigger_dense.h5", save_best_only=True)
early_stopping = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
(X_train_full, Y_train_full), (X_test, Y_test) = keras.datasets.cifar100.load_data()
model1 = keras.Sequential((
keras.layers.Flatten(input_shape=(32, 32, 3)),
keras.layers.BatchNormalization(),
keras.layers.Dense(256, activation='relu', kernel_initializer="he_normal"),
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.1),
keras.layers.Dense(100, activation='softmax')
))
model1.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Nadam(learning_rate=1e-4),
metrics=("accuracy"))
history = model1.fit(X_train,
Y_train,
epochs=150,
validation_data=(X_valid, Y_valid),
callbacks=(checkpoint, early_stopping))
عملکرد شبکه نسبتاً بد است:
Epoch 1/150
1407/1407 (==============================) - 13s 9ms/step - loss: 4.2260 - accuracy: 0.0836 - val_loss: 3.8682 - val_accuracy: 0.1238
...
Epoch 24/150
1407/1407 (==============================) - 12s 8ms/step - loss: 2.3598 - accuracy: 0.4006 - val_loss: 3.3577 - val_accuracy: 0.2434
و بیایید تاریخچه پیشرفت آن را ترسیم کنیم و همچنین آن را ارزیابی کنیم روی مجموعه تست (که احتمالاً به خوبی مجموعه اعتبار سنجی عمل می کند):
pd.DataFrame(history.history).plot()
plt.show()
model.evaluate(X_test, Y_test)

313/313 (==============================) - 0s 2ms/step - loss: 3.2681 - accuracy: 0.2408
(3.2681326866149902, 0.24079999327659607)
همانطور که انتظار می رفت، شبکه نتوانست داده ها را به خوبی درک کند. در نهایت دقت اضافه 40% و دقت واقعی 24% داشت.
دقت به 40% محدود شد – اینطور نبود واقعا قادر به تطبیق بیش از حد مجموعه داده ها است، حتی اگر با برخی از قسمت های آن که با توجه به معماری محدود قادر به تشخیص آن بود، بیش از حد برازش داشته باشد. این مدل ظرفیت آنتروپیک لازم را ندارد تا به خاطر استدلال من واقعاً بیش از حد مناسب باشد.
این مدل و معماری آن به سادگی برای این کار مناسب نیست – و در حالی که ما می توانیم از نظر فنی آن را به دست بیاوریم (بیش از آن) متناسب باشد ، اما هنوز هم در طولانی مدت مشکلاتی خواهد داشت. به عنوان مثال، اجازه دهید آن را به یک شبکه بزرگتر تبدیل کنیم، که از نظر تئوری به آن اجازه می دهد الگوهای پیچیده تری را تشخیص دهد:
model2 = keras.Sequential((
keras.layers.Flatten(input_shape=(32, 32, 3)),
keras.layers.BatchNormalization(),
keras.layers.Dense(512, activation='relu', kernel_initializer="he_normal"),
keras.layers.Dense(256, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.1),
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.1),
keras.layers.Dense(100, activation='softmax')
))
اگرچه، این اصلاً بهتر نیست:
Epoch 24/150
1407/1407 (==============================) - 28s 20ms/step - loss: 2.1202 - accuracy: 0.4507 - val_loss: 3.2796 - val_accuracy: 0.2528
این بسیار پیچیدهتر است (چگالی منفجر میشود)، اما به سادگی نمیتواند خیلی بیشتر استخراج کند:
model1.summary()
model2.summary()
Model: "sequential_17"
...
Total params: 845,284
Trainable params: 838,884
Non-trainable params: 6,400
_________________________________________________________________
Model: "sequential_18"
...
Total params: 1,764,324
Trainable params: 1,757,412
Non-trainable params: 6,912
بیش از حد برازش شبکه عصبی کانولوشنال روی CIFAR10
حالا بیایید سعی کنیم کاری متفاوت انجام دهیم. تغییر به یک CNN به طور قابل توجهی به استخراج ویژگیها از مجموعه داده کمک میکند و در نتیجه به مدل اجازه میدهد براستی overfit، به دقت بسیار بالاتر (توهم) می رسد.
ما آن را بیرون می اندازیم EarlyStopping تماس بگیرید تا اجازه دهید کار خود را انجام دهد. علاوه بر این، ما استفاده نخواهیم کرد Dropout لایه ها، و در عوض سعی کنید شبکه را مجبور کنید تا ویژگی ها را از طریق لایه های بیشتری یاد بگیرد.
توجه داشته باشید: خارج از زمینه تلاش برای اثبات استدلال، این توصیه وحشتناکی خواهد بود. این برعکس کاری است که می خواهید در پایان انجام دهید. Dropout به شبکهها کمک میکند تا با وادار کردن نورونهایی که رها نشدهاند، سستی را دریافت کنند، بهتر تعمیم پیدا کنند. اجبار شبکه به یادگیری از طریق لایه های بیشتر به احتمال زیاد منجر به یک مدل اضافه برازش می شود.
دلیل اینکه من به طور هدفمند این کار را انجام می دهم این است که به شبکه اجازه می دهم به طور وحشتناکی بیش از حد مناسب شود نشانه ای از توانایی آن در تشخیص واقعی ویژگی ها، قبل از ساده سازی و اضافه کردن آن Dropout تا واقعاً به آن اجازه تعمیم داده شود. اگر به دقت (توهم) بالایی برسد، می تواند بسیار بیشتر از مدل MLP استخراج کند، به این معنی که می توانیم ساده سازی آن را آغاز کنیم.
اجازه دهید یک بار دیگر از API متوالی برای ساخت یک CNN استفاده کنیم روی مجموعه داده CIFAR10:
checkpoint = keras.callbacks.ModelCheckpoint("overcomplicated_cnn_cifar10.h5", save_best_only=True)
model = keras.models.Sequential((
keras.layers.Conv2D(64, 3, activation='relu',
kernel_initializer="he_normal",
kernel_regularizer=keras.regularizers.l2(l=0.01),
padding='same',
input_shape=(32, 32, 3)),
keras.layers.Conv2D(64, 3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 2, activation='relu', padding='same'),
keras.layers.Conv2D(128, 2, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(64, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, 3, activation='relu', padding='same'),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(10, activation='softmax')
))
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
metrics=("accuracy"))
model.summary()
history = model.fit(X_train,
Y_train,
epochs=150,
batch_size=64,
validation_data=(X_valid, Y_valid),
callbacks=(checkpoint))
عالی، خیلی سریع اضافه می شود! تنها در چند دوره، شروع به تطبیق بیش از حد داده ها کرد و در دوره 31، با دقت اعتبار سنجی کمتر، به 98 درصد رسید:
Epoch 1/150
704/704 (==============================) - 149s 210ms/step - loss: 1.9561 - accuracy: 0.4683 - val_loss: 2.5060 - val_accuracy: 0.3760
...
Epoch 31/150
704/704 (==============================) - 149s 211ms/step - loss: 0.0610 - accuracy: 0.9841 - val_loss: 1.0433 - val_accuracy: 0.6958
از آنجایی که تنها 10 کلاس خروجی وجود دارد، حتی اگر ما سعی کردیم آن را بیش از حد نصب کنیم زیاد با ایجاد یک CNN بزرگ غیر ضروری، صحت اعتبارسنجی هنوز نسبتاً بالاست.
ساده سازی شبکه عصبی کانولوشنال روی CIFAR10
حالا بیایید آن را ساده کنیم تا ببینیم با یک معماری معقول تر چگونه عمل می کند. اضافه می کنیم BatchNormalization و Dropout زیرا هر دو به تعمیم کمک می کنند:
checkpoint = keras.callbacks.ModelCheckpoint("simplified_cnn_cifar10.h5", save_best_only=True)
early_stopping = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
model = keras.models.Sequential((
keras.layers.Conv2D(32, 3, activation='relu', kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(l=0.01), padding='same', input_shape=(32, 32, 3)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(32, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(64, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.5),
keras.layers.Flatten(),
keras.layers.Dense(32, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.3),
keras.layers.Dense(10, activation='softmax')
))
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
metrics=("accuracy"))
model.summary()
history = model.fit(X_train,
Y_train,
epochs=150,
batch_size=64,
validation_data=(X_valid, Y_valid),
callbacks=(checkpoint, early_stopping))
این مدل دارای تعداد (متوسط) 323146 پارامتر قابل آموزش است، در مقایسه با 1،579،178 از CNN قبلی. عملکرد آن چگونه است؟
Epoch 1/150
704/704 (==============================) - 91s 127ms/step - loss: 2.1327 - accuracy: 0.3910 - val_loss: 1.5495 - val_accuracy: 0.5406
...
Epoch 52/150
704/704 (==============================) - 89s 127ms/step - loss: 0.4091 - accuracy: 0.8648 - val_loss: 0.4694 - val_accuracy: 0.8500
در واقع به دقت 85% بسیار مناسبی می رسد! تیغ اوکام دوباره می زند. بیایید نگاهی به برخی از نتایج بیاندازیم:
y_preds = model.predict(X_test)
print(y_preds(1))
print(np.argmax(y_preds(1)))
fig, ax = plt.subplots(6, 6, figsize=(10, 10))
ax = ax.ravel()
for i in range(0, 36):
ax(i).imshow(X_test(i))
ax(i).set_title("Actual: %s\nPred: %s" % (class_names(Y_test(i)(0)), class_names(np.argmax(y_preds(i)))))
ax(i).axis('off')
plt.subplots_adjust(wspace=1)
plt.show()

طبقه بندی نادرست اصلی دو تصویر در این مجموعه کوچک است – یک سگ به عنوان گوزن طبقه بندی شد (به اندازه کافی قابل احترام) ، اما یک نزدیکی از یک پرنده EMU به عنوان یک گربه طبقه بندی شد (به اندازه کافی خنده دار ، بنابراین ما اجازه خواهیم داد که آن را بکشید).
بیش از حد برازش شبکه عصبی کانولوشن روی CIFAR100
وقتی به سراغ مجموعه داده CIFAR100 می رویم چه اتفاقی می افتد؟
checkpoint = keras.callbacks.ModelCheckpoint("overcomplicated_cnn_model_cifar100.h5", save_best_only=True)
early_stopping = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
model = keras.models.Sequential((
keras.layers.Conv2D(32, 3, activation='relu', kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(l=0.01), padding='same', input_shape=(32, 32, 3)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(32, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(64, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(64, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(256, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, activation='softmax')
))
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
metrics=("accuracy"))
model.summary()
history = model.fit(X_train,
Y_train,
epochs=150,
batch_size=64,
validation_data=(X_valid, Y_valid),
callbacks=(checkpoint))
Epoch 1/150
704/704 (==============================) - 97s 137ms/step - loss: 4.1752 - accuracy: 0.1336 - val_loss: 3.9696 - val_accuracy: 0.1392
...
Epoch 42/150
704/704 (==============================) - 95s 135ms/step - loss: 0.1543 - accuracy: 0.9572 - val_loss: 4.1394 - val_accuracy: 0.4458
فوق العاده! دقت 96% روی مجموعه آموزشی! هنوز دقت اعتبار 44% را نگران نکنید. بیایید مدل را خیلی سریع ساده کنیم تا آن را به تعمیم بهتری برسانیم.
عدم تعمیم بعد از ساده سازی
و اینجاست که مشخص می شود که توانایی بیش از حد مناسب نیست ضمانت که این مدل در صورت ساده سازی بهتر می تواند تعمیم یابد. در مورد CIFAR100 ، در هر کلاس نمونه های آموزشی زیادی وجود ندارد ، و این احتمالاً از یادگیری خوب مدل قبلی جلوگیری می کند. بیایید آن را امتحان کنیم:
checkpoint = keras.callbacks.ModelCheckpoint("simplified_cnn_model_cifar100.h5", save_best_only=True)
early_stopping = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
model = keras.models.Sequential((
keras.layers.Conv2D(32, 3, activation='relu', kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(l=0.01), padding='same', input_shape=(32, 32, 3)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(32, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(64, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(128, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.5),
keras.layers.Flatten(),
keras.layers.Dense(256, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.3),
keras.layers.Dense(100, activation='softmax')
))
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-3),
metrics=("accuracy"))
history = model.fit(X_train,
Y_train,
epochs=150,
batch_size=64,
validation_data=(X_valid, Y_valid),
callbacks=(checkpoint, early_stopping))
Epoch 1/150
704/704 (==============================) - 96s 135ms/step - loss: 4.4432 - accuracy: 0.1112 - val_loss: 3.7893 - val_accuracy: 0.1702
...
Epoch 48/150
704/704 (==============================) - 92s 131ms/step - loss: 1.2550 - accuracy: 0.6370 - val_loss: 1.7147 - val_accuracy: 0.5466
این فلات است و واقعا نمی تواند داده ها را تعمیم دهد. در این مورد، ممکن است تقصیر مدل نباشد – شاید برای کار مناسب باشد، به خصوص با توجه به دقت بالا روی مجموعه داده CIFAR10، که شکل ورودی یکسان و تصاویر مشابه در مجموعه داده دارد. به نظر میرسد که این مدل میتواند با اشکال کلی دقیق باشد، اما نه تمایز بین اشکال ظریف.
مدل ساده تر در واقع از نظر دقت اعتبار سنجی بهتر از پیچیده تر عمل می کند – بنابراین CNN پیچیده تر این جزئیات خوب را به هیچ وجه بهتر نمی کند. در اینجا، مشکل به احتمال زیاد در این واقعیت نهفته است که تنها 500 تصویر آموزشی در هر کلاس وجود دارد که واقعاً کافی نیست. در شبکه پیچیده تر ، این منجر به بیش از حد می شود ، زیرا تنوع کافی وجود ندارد – در صورت ساده کردن برای جلوگیری از بیش از حد ، این امر باعث می شود که مجدداً کمرنگ شود ، هیچ تنوع وجود ندارد.
به همین دلیل است که اکثریت قریب به اتفاق مقالاتی که قبلاً پیوند داده شده اند و اکثریت قریب به اتفاق شبکه ها داده های مجموعه داده CIFAR100 را افزایش می دهند.
این واقعاً مجموعه داده ای نیست که به راحتی بتوان دقت بالایی برای آن به دست آورد onبرخلاف مجموعه داده ارقام دستنویس MNIST، و یک سیانان ساده مانند آنچه ما میسازیم، احتمالاً آن را برای دقت بالا کاهش نمیدهد. فقط تعداد کلاس های کاملاً خاص را به خاطر بسپارید، برخی از تصاویر چقدر بی اطلاع هستند و چقدر دانش قبلی انسانها باید بین اینها تشخیص دهند.
بیایید با افزودن چند تصویر و گسترش مصنوعی داده های آموزشی تمام تلاش خود را بکنیم تا حداقل سعی کنیم دقت بالاتری داشته باشیم. به خاطر داشته باشید که CIFAR100 یک مجموعه داده واقعاً دشوار برای دستیابی به دقت بالا است. روی با مدل های ساده مدل های پیشرفته از تکنیک های متفاوت و جدید برای از بین بردن خطاها استفاده می کنند و بسیاری از این مدل ها حتی CNN ها – آنها هستند مبدل ها.
اگر دوست دارید نگاهی به چشم انداز این مدل ها بیندازید، PapersWithCode مجموعه ای زیبا از مقالات، کد منبع و نتایج را انجام داده است.
افزایش داده ها با کلاس ImageDataGenerator Keras
آیا افزایش داده کمکی خواهد کرد؟ معمولاً این کار را می کند، اما با یک جدی عدم وجود داده های آموزش مانند ما با آن روبرو هستیم ، فقط می توانید با چرخش های تصادفی ، چرخش ، کشت و غیره انجام دهید. اگر یک معماری نتواند به خوبی تعمیم دهد روی یک مجموعه داده، احتمالاً آن را از طریق افزایش داده ها تقویت خواهید کرد، اما احتمالاً زیاد نخواهد بود.
همانطور که گفته شد، بیایید از Keras استفاده کنیم ImageDataGenerator کلاس برای تولید برخی داده های آموزشی جدید با تغییرات تصادفی، به امید بهبود دقت مدل. اگر بهبود یابد ، نباید با مقدار زیادی باشد ، و به احتمال زیاد دوباره می تواند به صورت جزئی از مجموعه داده ها بدون توانایی تعمیم خوب یا کاملاً بیش از حد داده ها بازگردد.
با توجه به تغییرات تصادفی ثابت در دادهها، مدل کمتر برازش میکند روی به همان تعداد دورهها، زیرا تغییرات باعث میشود به دادههای «جدید» تطبیق یابد. بیایید آن را برای مثلاً 300 دوره اجرا کنیم، که به طور قابل توجهی بیشتر از بقیه شبکه هایی است که ما آموزش داده ایم. بدون این امکان پذیر است عمده مجدداً به دلیل تغییرات تصادفی ایجاد شده در تصاویر در حالی که آنها در حال جریان هستند، بیش از حد مناسب است:
checkpoint = keras.callbacks.ModelCheckpoint("augmented_cnn.h5", save_best_only=True)
model = keras.models.Sequential((
keras.layers.Conv2D(64, 3, activation='relu', kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(l=0.01), padding='same', input_shape=(32, 32, 3)),
keras.layers.Conv2D(64, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(128, 2, activation='relu', padding='same'),
keras.layers.Conv2D(128, 2, activation='relu', padding='same'),
keras.layers.Conv2D(128, 2, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.Conv2D(256, 3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(2),
keras.layers.Dropout(0.4),
keras.layers.Flatten(),
keras.layers.Dense(512, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.3),
keras.layers.Dense(100, activation='softmax')
))
train_datagen = ImageDataGenerator(rotation_range=30,
height_shift_range=0.2,
width_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
valid_datagen = ImageDataGenerator()
train_datagen.fit(X_train)
valid_datagen.fit(X_valid)
train_generator = train_datagen.flow(X_train, Y_train, batch_size=128)
valid_generator = valid_datagen.flow(X_valid, Y_valid, batch_size=128)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-3, decay=1e-6),
metrics=("accuracy"))
history = model.fit(train_generator,
epochs=300,
batch_size=128,
steps_per_epoch=len(X_train)//128,
validation_data=valid_generator,
callbacks=(checkpoint))
Epoch 1/300
351/351 (==============================) - 16s 44ms/step - loss: 5.3788 - accuracy: 0.0487 - val_loss: 5.3474 - val_accuracy: 0.0440
...
Epoch 300/300
351/351 (==============================) - 15s 43ms/step - loss: 1.0571 - accuracy: 0.6895 - val_loss: 2.0005 - val_accuracy: 0.5532

عملکرد مدل با ~55٪ روی مجموعه اعتبار سنجی، و هنوز هم تا حدی بیش از حد برازش داده است. این val_loss از پایین رفتن متوقف شده است و حتی با ارتفاعی بالاتر کاملاً صخره ای است batch_size.
این شبکه به سادگی نمی تواند داده ها را با دقت بالا بیاموزد و متناسب کند ، حتی اگر تغییرات آن دارای ظرفیت آنتروپی برای افزایش بیش از حد داده ها باشد.
نتیجه؟
تناسب بیش از حد ذاتاً چیز بدی نیست – فقط همین است یک چیز. نه ، شما نمی خواهید مدل های انتهایی بیش از حد ، اما نباید به عنوان طاعون رفتار کرد و حتی می تواند نشانه خوبی باشد که یک مدل با توجه به داده های بیشتر و یک مرحله ساده سازی می تواند بهتر عمل کند. این به هیچ وجه تضمین نشده است و مجموعه داده CIFAR100 به عنوان نمونه ای از مجموعه داده ای استفاده شده است که تعمیم به خوبی به آن آسان نیست.
نکته این سر و صدا کردن، باز هم مخالف نبودن – بلکه تحریک بحث است روی موضوعی که به نظر نمی رسد جایگاه زیادی داشته باشد.
من کی هستم که این ادعا را داشته باشم؟
فقط کسی که در خانه نشسته و با شیفتگی عمیق نسبت به فردا، این هنر را تمرین می کند.
آیا من توانایی اشتباه کردن را دارم؟
خیلی زیاد.
چگونه باید این قطعه را بگیرید؟
آن را همانطور که ممکن است بگیرید – خودتان فکر کنید که آیا منطقی است یا نه. اگر شما نکن فکر می کنم من برای توجه به این موضوع مناسب نیستم، به من اطلاع دهید. اگر فکر می کنید من اشتباه می کنم روی این – به هر حال، لطفا احساس کنید به من اطلاع دهید و کلمات خود را کوچک نکنید. 🙂
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-08 14:01:05
