از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
کتابخانه های تجسم داده های زیادی در پایتون وجود دارد، با این حال Matplotlib محبوب ترین کتابخانه در بین همه آنهاست. محبوبیت Matplotlib به دلیل قابلیت اطمینان و کاربردی بودن آن است – قادر است هر دو طرح ساده و پیچیده را با کد کمی ایجاد کند. شما همچنین می توانید طرح ها را به روش های مختلف سفارشی کنید.
در این آموزش به آن خواهیم پرداخت روش ترسیم Stack Plots در Matplotlib.
نمودارهای پشته ای برای رسم داده های خطی، به صورت عمودی، و در کنار هم قرار دادن هر نمودار خطی استفاده می شود روی یکی دیگر. به طور معمول، آنها برای تولید نمودارهای تجمعی استفاده می شوند.
وارد کردن داده ها
ما از یک مجموعه داده استفاده خواهیم کرد روی واکسیناسیون کووید-19، از دنیای ما در داده ها، به طور خاص، مجموعه داده ای که حاوی واکسیناسیون های تجمعی در هر کشور است.
ما با وارد کردن تمام کتابخانههایی که نیاز داریم شروع میکنیم. خوب import پانداها برای خواندن و تجزیه مجموعه داده، NumPy برای تولید مقادیر برای محور X، و ما البته باید import ماژول PyPlot از Matplotlib:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
بیایید نگاهی به آن بیندازیم DataFrame ما استفاده خواهیم کرد:
dataframe = pd.read_csv("cumulative-covid-vaccinations.csv")
print(dataframe.head(25))
ما به Entity و total_vaccinations. در حالی که ما می توانستیم استفاده کنیم Date همچنین این ویژگی برای به دست آوردن درک بهتری از روش انجام واکسیناسیون است روز به روز، ما اولین ورودی را به عنوان روز 0 و آخرین مدخل به عنوان روز N:
Entity Code Date total_vaccinations
0 Albania ALB 2021-01-10 0
1 Albania ALB 2021-01-12 128
2 Albania ALB 2021-01-13 188
3 Albania ALB 2021-01-14 266
4 Albania ALB 2021-01-15 308
5 Albania ALB 2021-01-16 369
...
16 Albania ALB 2021-02-22 6728
17 Albania ALB 2021-02-25 10135
18 Albania ALB 2021-03-01 14295
19 Albania ALB 2021-03-03 15793
20 Albania ALB 2021-03-10 21613
21 Algeria DZA 2021-01-29 0
22 Algeria DZA 2021-01-30 30
23 Algeria DZA 2021-02-19 75000
24 Andorra AND 2021-01-25 576
این مجموعه داده نیاز به پیش پردازش دارد، زیرا این یک مورد خاص است. اگرچه، قبل از پیش پردازش آن، بیایید با روش ترسیم Stack Plots به طور کلی آشنا شویم.
طرح پشته ای در Matplotlib
پلات های پشته ای برای تجسم نمودارهای خطی متعدد به صورت انباشته استفاده می شوند روی روی هم با یک نمودار خطی منظم، رابطه بین X و Y را ترسیم می کنید. در اینجا، ما چندین ویژگی Y را ترسیم می کنیم روی یک محور X مشترک، یک روی بالای دیگری:
import matplotlib.pyplot as plt
x = (1, 2, 3, 4, 5)
y1 = (5, 6, 4, 5, 7)
y2 = (1, 6, 4, 5, 6)
y3 = (1, 1, 2, 3, 2)
fig, ax = plt.subplots()
ax.stackplot(x, y1, y2, y3)
plt.show()
این نتیجه در:

از آنجایی که پرداختن به لیست های متعدد مانند این کمی سخت است، می توانید به سادگی از یک فرهنگ لغت استفاده کنید که در آن هر کدام yn ویژگی یک ورودی است:
import matplotlib.pyplot as plt
x = (1, 2, 3, 4, 5)
y_values = {
"y1": (5, 6, 4, 5, 7),
"y2": (1, 6, 4, 5, 6),
"y3" : (1, 1, 2, 3, 2)
}
fig, ax = plt.subplots()
ax.stackplot(x, y_values.values())
plt.show()
این نتیجه در:

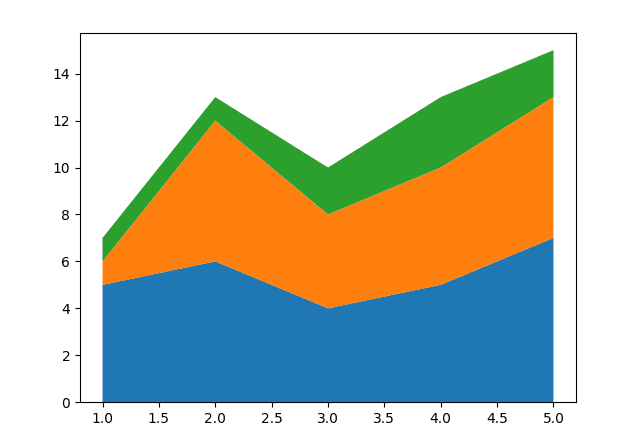
از آنجایی که این نوع طرح به راحتی می تواند شما را در پشته ها گم کند، افزودن برچسب های متصل به رنگ ها با تنظیم keys() از y_values فرهنگ لغت به عنوان labels استدلال، و اضافه کردن یک افسانه به طرح:
import matplotlib.pyplot as plt
x = (1, 2, 3, 4, 5)
y_values = {
"y1": (5, 6, 4, 5, 7),
"y2": (1, 6, 4, 5, 6),
"y3" : (1, 1, 2, 3, 2)
}
fig, ax = plt.subplots()
ax.stackplot(x, y_values.values(), labels=y_values.keys())
ax.legend(loc='upper left')
plt.show()
حال، این نتیجه می شود:

توجه داشته باشید: طول این لیست ها باید همینطور باشد. شما نمی توانید نقشه بکشید y1 با 3 مقدار و y2 با 5 مقدار
این ما را به مجموعه داده های واکسیناسیون کووید-19 می رساند. ما مجموعه داده را از قبل پردازش می کنیم تا به شکل دیکشنری مانند این باشد و واکسن های تجمعی داده شده به جمعیت عمومی را رسم کنیم.
بیایید با گروه بندی مجموعه داده بر اساس شروع کنیم Entity و total_vaccinations، از آنجایی که هر کدام Entity در حال حاضر ورودی های متعددی دارد. همچنین، ما می خواهیم موجودیت های نامگذاری شده را حذف کنیم World و European Union، از آنجایی که آنها موجودیت های راحتی هستند، برای مواردی که ممکن است بخواهید فقط یک خط تجمعی را رسم کنید اضافه شده است.
در مورد ما، به طور موثر بیش از دو برابر خواهد شد total_vaccination شمارش کنید، زیرا آنها شامل مقادیر ترسیم شده از قبل هر کشور، به عنوان موجودیت های منفرد هستند:
dataframe = pd.read_csv("cumulative-covid-vaccinations.csv")
indices = dataframe((dataframe('Entity') == 'World') | (dataframe('Entity') == 'European Union')).index
dataframe.drop(indices, inplace=True)
countries_vaccinations = dataframe.groupby('Entity')('total_vaccinations').apply(list)
این منجر به شکل کاملاً متفاوتی از مجموعه داده می شود – به جای اینکه هر ورودی مختص به خود را داشته باشد Entity/total_vaccinations ورودی، هر کدام Entity الف خواهد داشت فهرست از مجموع واکسیناسیون آنها در طول روز:
Entity
Albania (0, 128, 188, 266, 308, 369, 405, 447, 483, 51...
Algeria (0, 30, 75000)
Andorra (576, 1036, 1291, 1622, 2141, 2390, 2526, 3611...
...
Croatia (7864, 12285, 13798, 20603, 24985, 30000, 3455...
Cyprus (3901, 6035, 10226, 17739, 25519, 32837, 44429...
Czechia (1261, 3560, 7017, 10496, 11813, 12077, 13335,...
حالا بیایید این را تبدیل کنیم Series به یک فرهنگ لغت بروید و ببینید که چگونه به نظر می رسد:
cv_dict = countries_vaccinations.to_dict()
print(cv_dict)
این نتیجه در:
{
'Albania': (0, 128, 188, 266, 308, 369, 405, 447, 483, 519, 549, 550, 1127, 1701, 3049, 4177, 6728, 10135, 14295, 15793, 21613),
'Algeria': (0, 30, 75000),
'Andorra': (576, 1036, 1291, 1622, 2141, 2390, 2526, 3611, 4914),
...
}
با این حال، اینجا یک مشکل وجود دارد. اگر شکلهای آنها یکسان نباشد، نمیتوانیم این ورودیها را ترسیم کنیم. الجزایر 3 ورودی دارد، در حالی که آندورا برای مثال 9 ورودی دارد. برای مبارزه با این موضوع، میخواهیم کلیدی را با بیشترین مقدار و تعداد مقادیر پیدا کنیم.
سپس، یک فرهنگ لغت جدید بسازید (برای اصلاح فرهنگ لغت اصلی در حین تکرار از طریق آن توصیه نمی شود) و درج کنید 0s برای هر روز گمشده در گذشته، از آنجایی که وجود داشته است 0 کل واکسیناسیون در آن روزها:
max_key, max_value = max(cv_dict.items(), key = lambda x: len(set(x(1))))
cv_dict_full = {}
for k,v in cv_dict.items():
if len(v) < len(max_value):
trailing_zeros = (0)*(len(max_value)-len(v))
cv_dict_full(k) = trailing_zeros+v
else:
cv_dict_full(k) = v
print(cv_dict_full)
در اینجا، ما به سادگی بررسی می کنیم که آیا طول لیست در هر ورودی کوتاهتر از طول لیست با حداکثر طول است یا خیر. اگر اینطور است، تفاوت بین آن ها را به صفر اضافه می کنیم و آن مقدار را به لیست اصلی مقادیر اضافه می کنیم.
حالا اگر ما print در این فرهنگ لغت جدید، چیزی در این زمینه خواهیم دید:
{
'Albania': (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 128, 188, 266, 308, 369, 405, 447, 483, 519, 549, 550, 1127, 1701, 3049, 4177, 6728, 10135, 14295, 15793, 21613),
'Algeria': (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 30, 75000),
'Andorra': (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 576, 1036, 1291, 1622, 2141, 2390, 2526, 3611, 4914),
...
}
کشوری که بیشترین مقادیر ورودی را دارد:
print(max_key, len(max_value))
اکنون که مجموعه داده خود را به طور کامل آماده کردهایم و میتوانیم آن را همانطور که Stack Plots را قبل از آن ترسیم کردهایم رسم کنیم، بیایید روزها را تولید کرده و رسم کنیم:
dates = np.arange(0, len(max_value))
fig, ax = plt.subplots()
ax.stackplot(dates, cv_dict_full.values(), labels=cv_dict_full.keys())
ax.legend(loc='upper left', ncol=4)
ax.set_title('Cumulative Covid Vaccinations')
ax.set_xlabel('Day')
ax.set_ylabel('Number of people')
plt.show()
از آنجایی که کشورهای زیادی در جهان وجود دارد، افسانه نسبتاً فشرده خواهد بود، بنابراین ما آن را در 4 ستون قرار داده ایم تا حداقل در طرح قرار گیرد:

نتیجه
در این آموزش، روش ترسیم Stack Plots ساده، و همچنین روش پیش پردازش مجموعه داده ها و شکل دادن به داده ها برای تناسب با Stack Plots، با استفاده از Pandas و Matplotlib پایتون را بررسی کرده ایم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً ما را بررسی کنید بسته کتاب روی تجسم داده ها در پایتون:
تجسم داده ها در پایتون با Matplotlib و Pandas کتابی است که طراحی شده است تا مبتدیان مطلق را با دانش پایه پایتون به Pandas و Matplotlib ببرد و به آنها اجازه دهد پایه ای قوی برای کار پیشرفته با این کتابخانه ها بسازند – از طرح های ساده گرفته تا طرح های سه بعدی متحرک با دکمه های تعاملی.
این به عنوان یک راهنمای عمیق عمل می کند که همه چیزهایی را که باید در مورد پانداها و Matplotlib بدانید، از جمله روش ساخت انواع طرح هایی که در خود کتابخانه تعبیه نشده اند را به شما آموزش می دهد.
تجسم داده ها در پایتونکتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را از طریق دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید. به طور خاص، در طول ۱۱ فصل، این کتاب ۹ کتابخانه پایتون را پوشش میدهد: Pandas، Matplotlib، Seaborn، Bokeh، Altair، Plotly، GGPlot، GeoPandas و VisPy.
این به عنوان یک راهنمای عملی و منحصر به فرد برای تجسم داده ها، در مجموعه ای از ابزارهایی که ممکن است در حرفه خود استفاده کنید، عمل می کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-11 15:49:06
