از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
Matplotlib یکی از پرکاربردترین کتابخانه های تجسم داده در پایتون است. بیشتر محبوبیت Matplotlib از گزینه های سفارشی سازی آن ناشی می شود – می توانید تقریباً هر عنصری را از آن تغییر دهید. سلسله مراتب اشیاء.
در این آموزش نگاهی به این خواهیم داشت روش تغییر اندازه نشانگر در نمودار پراکندگی Matplotlib.
وارد کردن داده ها
ما استفاده خواهیم کرد شادی جهانی مجموعه داده و مقایسه کنید امتیاز شادی در برابر ویژگی های مختلف برای دیدن اینکه چه چیزی بر شادی درک شده در جهان تأثیر می گذارد:
import pandas as pd
df = pd.read_csv('worldHappiness2019.csv')
سپس، میتوانیم به راحتی اندازه نشانگرهای مورد استفاده برای نمایش ورودیهای این مجموعه داده را دستکاری کنیم.
تغییر اندازه نشانگر در Matplotlib Scatter Plot
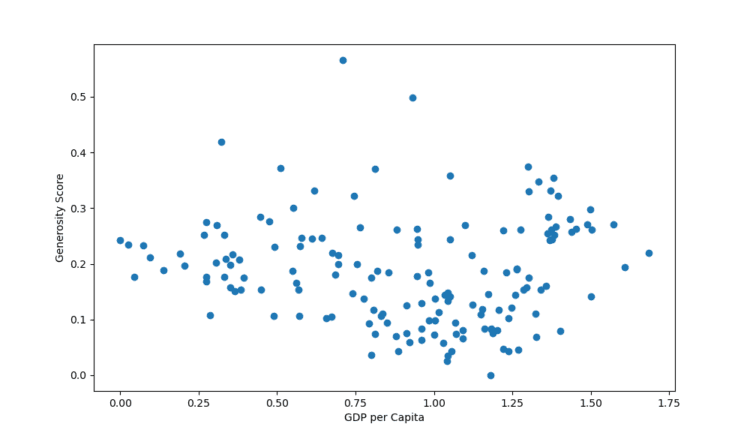
بیایید با ترسیم امتیاز سخاوت در برابر تولید ناخالص داخلی سرانه شروع کنیم:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('worldHappiness2019.csv')
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(x = df('GDP per capita'), y = df('Generosity'))
plt.xlabel("GDP per Capita")
plt.ylabel("Generosity Score")
plt.show()
این نتیجه در:

حال، فرض کنید میخواهیم اندازه هر نشانگر را بر اساس افزایش دهیم روی شادی ادراک شده ساکنان آن کشور. امتیاز شادی یک لیست است که مستقیماً از آن می آید df، بنابراین این می تواند با لیست های دیگر نیز کار کند.
برای تغییر اندازه نشانگرها از عبارت استفاده می کنیم s استدلال، برای scatter() تابع. این خواهد بود markersize استدلال برای plot() تابع:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('worldHappiness2019.csv')
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(x = df('GDP per capita'), y = df('Generosity'), s = df('Score')*25)
plt.xlabel("GDP per Capita")
plt.ylabel("Generosity Score")
plt.show()
ما همچنین مقدار هر عنصر در لیست را در عدد دلخواه 25 ضرب کرده ایم، زیرا آنها از رتبه بندی شده اند 0..1. اگر از آنها در مقادیر اصلی خود استفاده کنیم، این نشانگرهای بسیار کوچکی تولید می کند.
این در حال حاضر منجر به:

یا بهتر از این، به جای اینکه همه چیز را به طور خام در 25 ضرب کنیم، چون مقادیر به هر حال مشابه هستند، می توانیم کاری شبیه به این انجام دهیم:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('worldHappiness2019.csv')
size = df('Score').to_numpy()
s = (3*s**2 for s in size)
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(x = df('GDP per capita'), y = df('Generosity'), s = s)
plt.xlabel("GDP per Capita")
plt.ylabel("Generosity Score")
plt.show()
داشتن آن مهم است s به همان طول لیست کنید x و y، به عنوان هر مقدار از s اکنون برای آنها اعمال می شود. اگر لیست کوتاه تر یا طولانی تر باشد، کد شکسته می شود.
در اینجا، ما مقادیر را از the استخراج کرده ایم Score ستون، آنها را کوچک کرد و اندازه را دوباره به نمودار پراکندگی اعمال کرد:

اندازه نشانگر جهانی را در طرح پراکندگی Matplotlib تنظیم کنید
اگر میخواهید اندازه نشانگر را از یک متغیر جدا کنید، و فقط میخواهید یک اندازه استاندارد و جهانی از نشانگرها را در نمودار پراکنده تنظیم کنید، میتوانید به سادگی یک مقدار را برای آن ارسال کنید. s:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('worldHappiness2019.csv')
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(x = df('GDP per capita'), y = df('Generosity'), s = 100)
plt.xlabel("GDP per Capita")
plt.ylabel("Generosity Score")
plt.show()
این در حال حاضر منجر به:

نتیجه
در این آموزش، روش تغییر اندازه نشانگر را در Matplotlib Scatter Plot بررسی کردیم.
اگر به تجسم دادهها علاقه دارید و نمیدانید از کجا شروع کنید، حتماً ما را بررسی کنید بسته کتاب روی تجسم داده ها در پایتون:
تجسم داده ها در پایتون با Matplotlib و Pandas کتابی است که برای جذب مبتدیان مطلق به پانداها و Matplotlib با دانش پایه پایتون طراحی شده است و به آنها اجازه می دهد تا پایه ای قوی برای کار پیشرفته با این کتابخانه ها ایجاد کنند – از طرح های ساده گرفته تا طرح های سه بعدی متحرک با دکمه های تعاملی.
این به عنوان یک راهنمای عمیق عمل می کند که همه چیزهایی را که باید در مورد پانداها و Matplotlib بدانید، از جمله روش ساخت انواع طرح هایی که در خود کتابخانه تعبیه نشده اند را به شما آموزش می دهد.
تجسم داده ها در پایتون، کتابی برای توسعه دهندگان پایتون مبتدی تا متوسط، شما را از طریق دستکاری ساده داده ها با پانداها راهنمایی می کند، کتابخانه های ترسیم هسته ای مانند Matplotlib و Seaborn را پوشش می دهد و به شما نشان می دهد که چگونه از کتابخانه های اعلامی و تجربی مانند Altair استفاده کنید. به طور خاص، در طول ۱۱ فصل، این کتاب ۹ کتابخانه پایتون را پوشش میدهد: Pandas، Matplotlib، Seaborn، Bokeh، Altair، Plotly، GGPlot، GeoPandas و VisPy.
این به عنوان یک راهنمای عملی و منحصر به فرد برای تجسم داده ها، در مجموعه ای از ابزارهایی که ممکن است در حرفه خود استفاده کنید، عمل می کند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-14 15:11:07
