از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
Pandas یکی از رایج ترین کتابخانه های پایتون برای مدیریت و تجسم داده ها است. را کتابخانه پانداها کلاس ها و عملکردهایی را ارائه می دهد که می توانند برای خواندن، دستکاری و تجسم کارآمد داده ها، ذخیره شده در فرمت های مختلف فایل استفاده شوند.
در این مقاله، فایلهای JSON را با استفاده از پایتون و پاندا میخوانیم و مینویسیم.
فایل JSON چیست؟
نشانه گذاری شی جاوا اسکریپت (JSON) فرمت داده ای است که داده ها را به شکل قابل خواندن توسط انسان ذخیره می کند. در حالی که از نظر فنی می توان از آن برای ذخیره سازی استفاده کرد، فایل های JSON در درجه اول برای سریال سازی و تبادل اطلاعات بین مشتری و سرور استفاده می شود.
اگرچه از جاوا اسکریپت مشتق شده است، اما پلتفرم-آگنوستیک است و یک قالب گسترده و مورد استفاده است – بیشتر در API های REST.
ایجاد یک فایل JSON
برای ایجاد فایل های JSON از طریق پایتون، داده ها باید به روش خاصی ذخیره شوند. روش های مختلفی برای ذخیره این داده ها با استفاده از پایتون وجود دارد. برخی از روش ها در این مقاله مورد بحث قرار گرفته است.
ابتدا با استفاده از پایتون یک فایل ایجاد می کنیم و سپس از طریق پانداها روی آن می خوانیم و می نویسیم.
ایجاد داده های JSON از طریق فرهنگ لغت تودرتو
در پایتون، برای ایجاد داده های JSON، می توانید از دیکشنری های تودرتو استفاده کنید. هر مورد در فرهنگ لغت بیرونی مربوط به یک ستون در فایل JSON است.
کلید هر مورد سرصفحه ستون و مقدار آن فرهنگ لغت دیگری است که از ردیف هایی در آن ستون خاص تشکیل شده است. بیایید یک فرهنگ لغت ایجاد کنیم که بتوان از آن برای ایجاد یک فایل JSON استفاده کرد که رکوردی از بیماران خیالی را ذخیره می کند:
patients = {
"Name":{"0":"John","1":"Nick","2":"Ali","3":"Joseph"},
"Gender":{"0":"Male","1":"Male","2":"Female","3":"Male"},
"Nationality":{"0":"UK","1":"French","2":"USA","3":"Brazil"},
"Age" :{"0":10,"1":25,"2":35,"3":29}
}
در اسکریپت بالا، اولین مورد مربوط به Name ستون مقدار مورد شامل یک فرهنگ لغت است که در آن آیتم های فرهنگ لغت نشان دهنده ردیف ها هستند. کلیدهای اقلام فرهنگ لغت داخلی با شماره فهرست سطرها مطابقت دارند، جایی که مقادیر نشان دهنده مقادیر ردیف هستند.
از آنجایی که ممکن است تجسم آن کمی سخت باشد، در اینجا یک نمایش بصری وجود دارد:

در Name ستون، اولین رکورد در شاخص 0 ذخیره می شود که مقدار رکورد در آن قرار دارد John، به طور مشابه، مقدار ذخیره شده در ردیف دوم از Name ستون است Nick و غیره روی.
ایجاد داده های JSON از طریق فهرست دیکشنری ها
راه دیگری برای ایجاد داده های JSON از طریق فهرست فرهنگ لغت است. هر مورد در لیست شامل یک فرهنگ لغت و هر فرهنگ لغت نشان دهنده یک ردیف است. این رویکرد بسیار خواناتر از استفاده از دیکشنری های تو در تو است.
بیایید لیستی ایجاد کنیم که بتوان از آن برای ایجاد یک فایل JSON استفاده کرد که اطلاعات مربوط به خودروهای مختلف را ذخیره می کند:
cars = (
{"Name":"Honda", "Price": 10000, "Model":2005, "Power": 1300},
{"Name":"Toyota", "Price": 12000, "Model":2010, "Power": 1600},
{"Name":"Audi", "Price": 25000, "Model":2017, "Power": 1800},
{"Name":"Ford", "Price": 28000, "Model":2009, "Power": 1200},
)
هر مورد فرهنگ لغت مربوط به یک ردیف در یک فایل JSON است. برای مثال اولین مورد در اولین فرهنگ لغت مقدار را ذخیره می کند Honda در Name ستون به طور مشابه، ارزش Price ستون در سطر اول خواهد بود 10000 و غیره روی.
نوشتن داده در یک فایل JSON از طریق پایتون
با فرهنگ لغت تودرتو و فهرستی از دیکشنری ها، می توانیم این داده ها را در یک فایل JSON ذخیره کنیم. برای رسیدن به این هدف، از json ماژول و dump() روش:
import json
with open('E:/datasets/patients.json', 'w') as f:
json.dump(patients, f)
with open('E:/datasets/cars.json', 'w') as f:
json.dump(cars, f)
اکنون دو فایل JSON داریم – patients.json و cars.json. مرحله بعدی خواندن این فایل ها از طریق کتابخانه Pandas است.
اگر میخواهید درباره خواندن و نوشتن JSON در فایل در Core Python اطلاعات بیشتری کسب کنید، ما شما را تحت پوشش قرار دادهایم!
خواندن فایل های JSON با پانداها
برای خواندن یک فایل JSON از طریق پانداها، از آن استفاده می کنیم read_json() روش و مسیر فایلی را که می خواهیم بخوانیم ارسال کنید. این روش یک Pandas را برمی گرداند DataFrame که داده ها را در قالب ستون و ردیف ذخیره می کند.
اگرچه، ابتدا باید Pandas را نصب کنیم:
$ pip install pandas
خواندن JSON از Local فایل ها
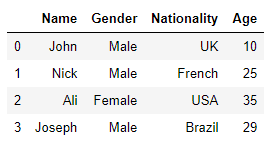
اسکریپت زیر را می خواند patients.json فایل از دایرکتوری سیستم محلی است و نتیجه را در قسمت ذخیره می کند patients_df چارچوب داده سپس هدر دیتافریم از طریق آن چاپ می شود head() روش:
import pandas as pd
patients_df = pd.read_json('E:/datasets/patients.json')
patients_df.head()
اجرای این کد باید نتیجه دهد:
به طور مشابه، اسکریپت زیر را می خواند cars.json فایل را از سیستم محلی و سپس فراخوانی می کند head() روش روی را cars_df به print سربرگ:
cars_df = pd.read_json('E:/datasets/cars.json')
cars_df.head()
اجرای این کد باید نتیجه دهد:
خواندن JSON از Remote Files
را read_json() روش فقط به خواندن فایل های محلی محدود نمی شود. همچنین می توانید فایل های JSON واقع شده را بخوانید روی سرورهای راه دور فقط باید مسیر فایل JSON راه دور را به فراخوانی تابع منتقل کنید.
بخوانیم و print از سر مجموعه داده عنبیه – یک مجموعه داده بسیار محبوب حاوی اطلاعاتی در مورد گل های مختلف زنبق:
import pandas as pd
iris_data = pd.read_json("https://raw.githubusercontent.com/domoritz/maps/master/data/iris.json")
iris_data.head()
اجرای این کد باید به ما منجر شود:

نوشتن فایل های داده JSON از طریق پانداها
برای تبدیل دیتافریم پاندا به فایل JSON، از to_json() تابع روی dataframe، و مسیر فایل به زودی را به عنوان پارامتر ارسال کنید.
بیایید یک فایل JSON از tips مجموعه داده ای که برای تجسم داده ها در کتابخانه Seaborn گنجانده شده است.
اول از همه، بیایید Seaborn را نصب کنیم:
$ pip install seaborn
سپس، اجازه دهید import و نکات آن را در یک مجموعه داده بارگذاری کنید:
import seaborn as sns
dataset = sns.load_dataset('tips')
dataset.head()
این دیتاست به این صورت است:
Seaborn’s load_dataset() تابع یک پاندا را برمی گرداند DataFrame، بنابراین بارگذاری مجموعه داده مانند این به ما امکان می دهد به سادگی آن را فراخوانی کنیم to_json() تابع تبدیل آن
هنگامی که مجموعه داده را در دست گرفتیم، بیایید محتوای آن را در یک فایل JSON ذخیره کنیم. ما راه اندازی کرده ایم datasets دایرکتوری برای این:
dataset.to_json('E:/datasets/tips.json')
پیمایش به E:/datasets دایرکتوری، باید ببینید tips.json. با باز کردن فایل، میتوانیم JSON را ببینیم که مربوط به رکوردهای موجود در دیتافریم Pandas است tips مجموعه داده:
{
"total_bill":{
"0":16.99,
"1":10.34,
"2":21.01,
"3":23.68,
"4":24.59,
"5":25.29,
...
}
"tip":{
"0":1.01,
"1":1.66,
"2":3.5,
"3":3.31,
"4":3.61,
"5":4.71,
...
}
"sex":{
"0":"Female",
"1":"Male",
"2":"Male",
"3":"Male",
"4":"Female",
"5":"Male",
...
}
"smoker":{
"0":"No",
"1":"No",
"2":"No",
"3":"No",
"4":"No",
"5":"No",
...
}
...
نتیجه
JSON یک فرمت پرکاربرد برای ذخیره سازی و تبادل داده بین مشتری و سرور است. توسعه دهندگان اغلب از این قالب بر روی فرمت هایی مانند XML استفاده می کنند زیرا سبک و خوانا است.
در این مقاله، روش خواندن و نوشتن فایلهای JSON با استفاده از کتابخانه محبوب پانداهای پایتون – از فایلهای محلی گرفته تا راه دور را پوشش دادهایم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-17 15:26:05
