از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
در علوم کامپیوتر، دادهها را میتوان به روشهای مختلف نشان داد و طبیعتاً هر یک از آنها مزایا و معایب خود را در زمینههای خاصی دارد.
از آنجایی که کامپیوترها قادر به انجام این کار نیستند process داده های طبقه بندی شده از آنجایی که این دستهها برای آنها معنی ندارند، اگر میخواهیم کامپیوتری بتواند آن را داشته باشد، باید این اطلاعات را آماده کنیم process آی تی.
این عمل نامیده می شود پیش پردازش. بخش بزرگی از پیش پردازش است رمزگذاری – نمایش تک تک داده ها به گونه ای که کامپیوتر بتواند آن را درک کند (نام تحت اللفظی به معنای “تبدیل به کد کامپیوتر” است).
در بسیاری از شاخه های علوم کامپیوتر، به ویژه یادگیری ماشین و طراحی مدارهای دیجیتال، رمزگذاری یک داغ به طور گسترده استفاده می شود.
در این مقاله توضیح خواهیم داد که رمزگذاری تک داغ چیست و آن را با استفاده از چند گزینه رایج در پایتون پیاده سازی می کنیم. پانداها و Scikit-Learn. ما همچنین کارایی آن را با انواع دیگر نمایش در رایانه، نقاط قوت و ضعف و همچنین کاربردهای آن مقایسه خواهیم کرد.
رمزگذاری تک داغ چیست؟
رمزگذاری تک داغ نوعی نمایش برداری است که در آن همه عناصر در یک بردار 0 هستند، به جز یکی که 1 را به عنوان مقدار خود دارد، جایی که 1 نشان دهنده a است boolean مشخص کردن یک دسته از عنصر
همچنین یک پیاده سازی مشابه به نام وجود دارد رمزگذاری یک سرد، که در آن همه عناصر یک بردار 1 هستند، به جز یکی که مقدار آن 0 است.
برای مثال، (0, 0, 0, 1, 0) و (1 ,0, 0, 0, 0) می تواند چند نمونه از بردارهای یک داغ باشد. یک تکنیک مشابه با این یکی که برای نمایش داده ها نیز استفاده می شود، خواهد بود متغیرهای ساختگی در آمار
این بسیار متفاوت از سایر طرحهای رمزگذاری است، که همگی به بیتهای متعدد اجازه میدهند 1 را به عنوان مقدار خود داشته باشند. در زیر جدولی وجود دارد که نمایش اعداد 0 تا 7 را در کدهای باینری، خاکستری و یک داغ مقایسه می کند:
| اعشاری | دودویی | کد خاکستری | یک داغ |
|---|---|---|---|
| 0 | 000 | 000 | 0000000 |
| 1 | 001 | 001 | 0000001 |
| 2 | 010 | 011 | 0000010 |
| 3 | 011 | 010 | 0000100 |
| 4 | 100 | 110 | 0001000 |
| 5 | 101 | 111 | 0010000 |
| 6 | 110 | 101 | 0100000 |
| 7 | 111 | 100 | 1000000 |
عملاً برای هر بردار یک گرمی میپرسیم n سوالات، کجا n تعداد دسته هایی است که داریم:
آیا این عدد 1 است؟ آیا این شماره 2 است؟ … این عدد 7 است؟
هر “0” “نادرست” است و هنگامی که یک “1” را در یک بردار بزنیم، پاسخ سوال “درست” است.
رمزگذاری تک داغ ویژگی های طبقه بندی را به قالبی تبدیل می کند که با الگوریتم های طبقه بندی و رگرسیون بهتر کار می کند. در روش هایی که چندین نوع نمایش داده ضروری است بسیار مفید است.
به عنوان مثال، برخی از بردارها ممکن است برای رگرسیون بهینه باشند (تقریبی بر اساس توابع روی مقادیر بازگشتی قبلی)، و برخی ممکن است برای طبقه بندی بهینه باشند (دسته بندی به مجموعه ها/کلاس های ثابت، معمولا باینری):
| برچسب | شناسه |
|---|---|
| توت فرنگی | 1 |
| سیب | 2 |
| هندوانه | 3 |
| لیمو | 4 |
| هلو | 5 |
| نارنجی | 6 |
در اینجا ما شش ورودی نمونه از داده های طبقه بندی داریم. نوع رمزگذاری مورد استفاده در اینجا نامیده می شود “رمزگذاری برچسب” – و بسیار ساده است: ما فقط یک ID برای یک مقدار طبقه بندی می کنیم.
رایانه ما اکنون می داند که چگونه این دسته ها را نشان دهد، زیرا می داند چگونه با اعداد کار کند. با این حال، این روش رمزگذاری چندان مؤثر نیست، زیرا به طور طبیعی به اعداد بالاتر وزن بیشتری می دهد.
منطقی نیست که بگوییم دسته ما از “توت فرنگی” بزرگتر یا کوچکتر از “سیب” است، یا اضافه کردن دسته “لیمو” به “هلو” به ما یک دسته “پرتقال” می دهد، زیرا این مقادیر مناسب نیستند. ترتیبی
اگر این دستهها را در رمزگذاری یکطرفه نشان دهیم، در واقع ردیفها را با ستونها جایگزین میکنیم. ما این کار را با ایجاد یکی انجام می دهیم boolean ستون برای هر یک از دسته بندی های داده شده ما، جایی که فقط یکی از این ستون ها می تواند جای بگیرد روی مقدار 1 برای هر نمونه:
| توت فرنگی | سیب | هندوانه | لیمو | هلو | نارنجی | شناسه |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 2 |
| 0 | 0 | 1 | 0 | 0 | 0 | 3 |
| 0 | 0 | 0 | 1 | 0 | 0 | 4 |
| 0 | 0 | 0 | 0 | 1 | 0 | 5 |
| 0 | 0 | 0 | 0 | 0 | 1 | 6 |
از جداول بالا میتوانیم ببینیم که ارقام بیشتری در نمایش تک داغ در مقایسه با کد باینری یا خاکستری مورد نیاز است. برای n ارقام، رمزگذاری تک داغ فقط می تواند نشان دهد n مقادیر، در حالی که رمزگذاری باینری یا خاکستری می تواند نشان دهد 2n با استفاده از مقادیر n ارقام
پیاده سازی
پانداها
بیایید به یک مثال ساده نگاهی بیندازیم که چگونه میتوانیم مقادیر را از یک ستون طبقهبندی در مجموعه داده خود به همتاهای عددی آنها، از طریق طرح رمزگذاری یکطرف تبدیل کنیم.
ما یک مجموعه داده بسیار ساده ایجاد خواهیم کرد – لیستی از کشورها و شناسه آنها:
import pandas as pd
ids = (11, 22, 33, 44, 55, 66, 77)
countries = ('Spain', 'France', 'Spain', 'Germany', 'France')
df = pd.DataFrame(list(zip(ids, countries)),
columns=('Ids', 'Countries'))
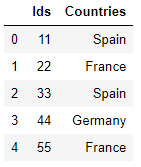
در اسکریپت بالا یک پاندا ایجاد می کنیم چارچوب داده، تماس گرفت df با استفاده از دو لیست به عنوان مثال ids و countries. اگر تماس بگیرید head() روش روی چارچوب داده، باید نتیجه زیر را ببینید:
df.head()

را Countries ستون حاوی مقادیر طبقه بندی است. ما می توانیم مقادیر موجود در را تبدیل کنیم Countries ستون به بردارهای کدگذاری شده یک داغ با استفاده از get_dummies() تابع:
y = pd.get_dummies(df.Countries, prefix='Country')
print(y.head())
گذشتیم Country به عنوان ارزش برای prefix ویژگی از get_dummies() متد، از این رو می توانید رشته را ببینید Country پیشوند قبل از هدر هر یک از ستون های کدگذاری شده یک داغ در خروجی.
با اجرای این کد به دست می آید:
Country_France Country_Germany Country_Spain
0 0 0 1
1 1 0 0
2 0 0 1
3 0 1 0
4 1 0 0
Scikit-Learn
یک جایگزین می تواند استفاده از یک کتابخانه محبوب دیگر – Scikit-Learn باشد. این هر دو را ارائه می دهد OneHotEncoder کلاس و LabelBinarizer کلاس برای این منظور
ابتدا، اجازه دهید با وارد کردن شروع کنیم LabelBinarizer:
from sklearn.preprocessing import LabelBinarizer
و سپس، با استفاده از همان دیتافریم قبلی، بیایید آن را نمونهسازی کنیم LabelBinarizer و مناسب آن:
y = LabelBinarizer().fit_transform(df.Countries)
چاپ y نتیجه داد:
((0 0 1)
(1 0 0)
(0 0 1)
(0 1 0)
(1 0 0))
اگرچه، این تقریباً به زیبایی رویکرد پانداها نیست.
به طور مشابه، ما می توانیم استفاده کنیم OneHotEncoder کلاس که برخلاف کلاس قبلی از داده های چند ستونی پشتیبانی می کند:
from sklearn.preprocessing import OneHotEncoder
و سپس، بیایید یک لیست را پر کنیم و آن را در رمزگذار قرار دهیم:
x = ((11, "Spain"), (22, "France"), (33, "Spain"), (44, "Germany"), (55, "France"))
y = OneHotEncoder().fit_transform(x).toarray()
print(y)
با اجرای این کار به دست می آید:
((1. 0. 0. 0. 0. 0. 0. 1.)
(0. 1. 0. 0. 0. 1. 0. 0.)
(0. 0. 1. 0. 0. 0. 0. 1.)
(0. 0. 0. 1. 0. 0. 1. 0.)
(0. 0. 0. 0. 1. 1. 0. 0.))
کاربردهای رمزگذاری تک داغ
رمزگذاری تک داغ بیشترین کاربرد خود را در زمینههای یادگیری ماشین و طراحی مدار دیجیتال داشته است.
فراگیری ماشین
همانطور که در بالا گفته شد، کامپیوترها با داده های طبقه بندی شده خیلی خوب نیستند. در حالی که ما داده های طبقه بندی را به خوبی درک می کنیم، این به دلیل نوعی دانش پیش نیاز است که رایانه ها ندارند.
بیشتر تکنیک ها و مدل های یادگیری ماشین با یک مجموعه داده بسیار محدود (معمولا باینری) کار می کنند. شبکههای عصبی دادهها را مصرف میکنند و نتایجی را در محدوده تولید میکنند 0..1 و به ندرت از این محدوده فراتر خواهیم رفت.
به طور خلاصه، اکثریت قریب به اتفاق الگوریتم های یادگیری ماشین داده های نمونه را دریافت می کنند (“داده های آموزشی“) که ویژگی ها از آن استخراج می شوند روی این ویژگی ها، یک مدل ریاضی ایجاد می شود، که سپس برای پیش بینی یا تصمیم گیری بدون برنامه ریزی صریح برای انجام این وظایف استفاده می شود.
یک مثال عالی می تواند طبقه بندی باشد، که در آن ورودی می تواند از نظر فنی نامحدود باشد، اما خروجی معمولاً به چند کلاس محدود می شود. در مورد طبقه بندی باینری (مثلاً ما یک شبکه عصبی را برای طبقه بندی گربه ها و سگ ها آموزش می دهیم)، ما نقشه ای از 0 برای گربه ها، و 1 برای سگ ها
بیشتر اوقات، داده های آموزشی مایل به انجام پیش بینی هستیم روی است طبقه بندی شدهمانند مثال با میوه ذکر شده در بالا. باز هم، در حالی که این برای ما بسیار منطقی است، خود کلمات برای الگوریتم هیچ معنایی ندارند زیرا آنها را درک نمی کند.
استفاده از رمزگذاری تک داغ برای نمایش داده ها در این الگوریتم ها نیست از نظر فنی ضروری است، اما بسیار مفید است اگر بخواهیم یک پیاده سازی کارآمد داشته باشیم.
طراحی مدار دیجیتال
بسیاری از مدارهای دیجیتال پایه برای نمایش مقادیر ورودی/خروجی خود از نماد یک داغ استفاده می کنند.
برای مثال می توان از آن برای نشان دادن وضعیت a استفاده کرد ماشین حالت محدود. اگر نوع دیگری از نمایش، مانند خاکستری یا باینری، استفاده شود، یک رمزگشا برای تعیین وضعیت مورد نیاز است، زیرا آنها به طور طبیعی سازگار نیستند. برعکس، یک ماشین حالت محدود یک داغ نیازی به رمزگشا ندارد، زیرا اگر نهمین بیت بالا است، ماشین به طور منطقی در نهمین حالت.
یک مثال خوب از یک ماشین حالت محدود a شمارنده حلقه – نوعی شمارنده متشکل از فلیپ فلاپ های متصل به یک شیفت رجیستر که در آن خروجی یک فلیپ فلاپ به ورودی دیگری متصل می شود.
فلیپ فلاپ اول در این شمارنده نشان دهنده حالت اول، دومی نشان دهنده حالت دوم و غیره است روی. در ابتدا، تمام فلیپ فلاپهای دستگاه روی «0» تنظیم شدهاند، به جز مورد اول که روی «1» تنظیم شده است.
لبه ساعت بعدی که به فلیپ فلاپ می رسد، یک بیت داغ را به فلیپ فلاپ دوم می رساند. بیت داغ به این صورت تا آخرین حالت پیش می رود و پس از آن دستگاه به حالت اول باز می گردد.
نمونه دیگری از استفاده از رمزگذاری یک داغ در طراحی مدارهای دیجیتال می تواند یک رمزگشای آدرس، که یک ورودی کد باینری یا خاکستری را می گیرد و سپس آن را به یک داغ برای خروجی تبدیل می کند و همچنین یک رمزگذار اولویت (در تصویر زیر نشان داده شده است).
دقیقا برعکس است و ورودی یک گرم را می گیرد و آن را به باینری یا خاکستری تبدیل می کند:

مزایا و معایب رمزگذاری One-hot
مانند هر نوع رمزگذاری دیگری، one-hot دارای نکات خوب و همچنین جنبه های مشکل ساز است.
مزایای
یک مزیت بزرگ رمزگذاری تک داغ این است که تعیین وضعیت یک ماشین هزینه کم و ثابتی دارد، زیرا تنها کاری که باید انجام دهد دسترسی به یک فلیپ فلاپ است. تغییر وضعیت دستگاه تقریباً به همان سرعت است، زیرا فقط باید به دو فلیپ فلاپ دسترسی داشته باشد.
یکی دیگر از چیزهای عالی در مورد رمزگذاری یکطرف، اجرای آسان آن است. طراحی و اصلاح مدارهای دیجیتالی ساخته شده در این نماد بسیار آسان است. تشخیص حالت های غیرقانونی در ماشین حالت محدود نیز آسان است.
یک پیادهسازی تک داغ به عنوان سریعترین آن شناخته میشود، که به ماشین حالت اجازه میدهد با سرعت کلاک سریعتری نسبت به هر کدگذاری دیگر آن ماشین حالت کار کند.
معایب
یکی از معایب اصلی رمزگذاری تک داغ، این واقعیت است که در بالا ذکر شد نمی تواند بسیاری از ارزش ها را نشان دهد (برای n ایالات، ما نیاز داریم n ارقام – یا فلیپ فلاپ). به همین دلیل است که اگر بخواهیم برای مثال یک شمارنده حلقه 15 حالته یک داغ پیاده سازی کنیم، به 15 فلیپ فلاپ نیاز داریم، در حالی که اجرای باینری تنها به سه فلیپ فلاپ نیاز دارد.
این امر آن را به ویژه برای دستگاه های PAL غیر عملی می کند و همچنین می تواند بسیار گران باشد، اما از فلیپ فلاپ های فراوان FPGA بهره می برد.
مشکل دیگر این نوع رمزگذاری این است که بسیاری از حالتهای موجود در یک ماشین حالت محدود غیرقانونی هستند – برای هر n حالت های معتبر وجود دارد (2n – n) غیر قانونی نکته خوب این است که همانطور که قبلاً گفته شد، تشخیص این حالت های غیرقانونی بسیار آسان است (یک گیت XOR کافی است)، بنابراین مراقبت از آنها خیلی سخت نیست.
نتیجه
از آنجایی که رمزگذاری تک داغ بسیار ساده است، درک و استفاده از آن در عمل آسان است. جای تعجب نیست که این محبوبیت در دنیای علوم کامپیوتر بسیار زیاد است.
با توجه به این واقعیت که معایب نیست خیلی بد، کاربرد وسیع آن دیده می شود. در پایان، مزایای آن به وضوح بیشتر از معایب آن است، به همین دلیل است که این نوع پیاده سازی قطعا برای مدت طولانی در آینده باقی خواهد ماند.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-17 18:45:05
