از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
PyTorch و TensorFlow کتابخانه ها دو مورد از رایج ترین کتابخانه های پایتون برای یادگیری عمیق هستند. PyTorch توسط فیس بوک توسعه داده شده است، در حالی که TensorFlow یک پروژه گوگل است. در این مقاله خواهید دید که چگونه می توان از کتابخانه PyTorch برای حل مشکلات طبقه بندی استفاده کرد.
مسائل طبقهبندی به دسته مشکلات یادگیری ماشین تعلق دارند که با توجه به مجموعهای از ویژگیها، وظیفه پیشبینی یک مقدار گسسته است. پیشبینی سرطانی بودن یا نبودن تومور، یا اینکه دانشآموز احتمالاً در امتحان موفق میشود یا رد میشود، از نمونههای رایج مشکلات طبقهبندی هستند.
در این مقاله با توجه به ویژگی های خاص یک مشتری بانک، پیش بینی می کنیم که آیا مشتری پس از 6 ماه بانک را ترک می کند یا خیر. پدیده ای که در آن مشتری سازمان را ترک می کند، ریزش مشتری نیز نامیده می شود. بنابراین، وظیفه ما این است که بر اساس ریزش مشتری پیش بینی کنیم روی ویژگی های مختلف مشتری
قبل از ادامه، فرض بر این است که سطح متوسطی از زبان برنامه نویسی پایتون دارید و کتابخانه PyTorch را نصب کرده اید. همچنین، دانش مفاهیم اولیه یادگیری ماشین ممکن است کمک کند. اگر PyTorch را نصب نکرده اید، می توانید با موارد زیر این کار را انجام دهید pip دستور:
$ pip install pytorch
مجموعه داده
مجموعه داده ای که می خواهیم در این مقاله استفاده کنیم به صورت رایگان در اینجا موجود است لینک کاگل. اجازه دهید import کتابخانه های مورد نیاز و مجموعه داده در برنامه پایتون ما:
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ما می توانیم استفاده کنیم read_csv() روش از pandas کتابخانه به import فایل CSV که شامل مجموعه داده ما است.
dataset = pd.read_csv(r'E:Datasets\customer_data.csv')
اجازه دهید print شکل مجموعه داده ما:
dataset.shape
خروجی:
(10000, 14)
خروجی نشان می دهد که مجموعه داده دارای 10 هزار رکورد و 14 ستون است.
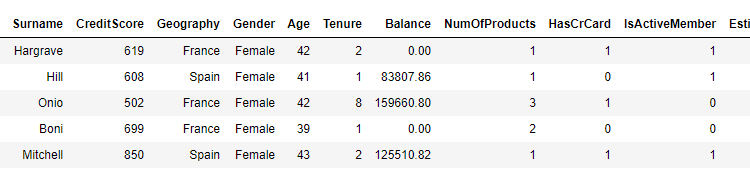
ما می توانیم استفاده کنیم head() روش قالب داده پانداها به print پنج ردیف اول مجموعه داده ما.
dataset.head()
خروجی:

شما می توانید 14 ستون را در مجموعه داده ما ببینید. مستقر روی در 13 ستون اول، وظیفه ما پیش بینی مقدار برای ستون 14 است Exited. لازم به ذکر است که مقادیر 13 ستون اول 6 ماه قبل از مقدار برای Exited ستون به دست آمد زیرا وظیفه پیش بینی ریزش مشتری پس از 6 ماه از زمان ثبت اطلاعات مشتری است.
تجزیه و تحلیل داده های اکتشافی
بیایید تجزیه و تحلیل داده های اکتشافی را انجام دهیم روی مجموعه داده ما ما ابتدا نسبت مشتری را که واقعاً پس از 6 ماه بانک را ترک کرده است، پیش بینی می کنیم و از نمودار پای برای تجسم استفاده می کنیم.
بیایید ابتدا اندازه نمودارهای پیش فرض را افزایش دهیم:
fig_size = plt.rcParams("figure.figsize")
fig_size(0) = 10
fig_size(1) = 8
plt.rcParams("figure.figsize") = fig_size
اسکریپت زیر طرح دایره ای را ترسیم می کند Exited ستون
dataset.Exited.value_counts().plot(kind='pie', autopct='%1.0f%%', colors=('skyblue', 'orange'), explode=(0.05, 0.05))
خروجی:

خروجی نشان می دهد که در مجموعه داده ما، 20٪ از مشتریان بانک را ترک کردند. در اینجا 1 متعلق به حالتی است که مشتری بانک را ترک کرده است، جایی که 0 به سناریویی اشاره دارد که مشتری بانک را ترک نکرده است.
بیایید تعداد مشتریان را از همه مکانهای جغرافیایی در مجموعه داده ترسیم کنیم:
sns.countplot(x='Geography', data=dataset)
خروجی:

خروجی نشان می دهد که تقریبا نیمی از مشتریان متعلق به فرانسه هستند، در حالی که نسبت مشتریان متعلق به اسپانیا و آلمان هر کدام 25 درصد است.
اکنون بیایید تعداد مشتریان از هر مکان جغرافیایی منحصر به فرد را به همراه اطلاعات ریزش مشتری ترسیم کنیم. ما می توانیم استفاده کنیم countplot() تابع از seaborn کتابخانه برای انجام این کار
sns.countplot(x='Exited', hue='Geography', data=dataset)
خروجی:

خروجی نشان می دهد که اگرچه تعداد کلی مشتریان فرانسوی دو برابر تعداد مشتریان اسپانیایی و آلمانی است، نسبت مشتریانی که بانک را ترک کرده اند برای مشتریان فرانسوی و آلمانی یکسان است. به همین ترتیب، تعداد کلی مشتریان آلمانی و اسپانیایی یکسان است، اما تعداد مشتریان آلمانی که بانک را ترک کرده اند، دو برابر مشتریان اسپانیایی است که نشان می دهد مشتریان آلمانی پس از 6 ماه بیشتر احتمال دارد بانک را ترک کنند.
در این مقاله، ما اطلاعات مربوط به بقیه ستون های مجموعه داده خود را به صورت بصری رسم نمی کنیم، اما اگر می خواهید این کار را انجام دهید، مقاله من را بررسی کنید. روی روش انجام تجزیه و تحلیل داده های اکتشافی با Python Seaborn Library.
پیش پردازش داده ها
قبل از اینکه مدل PyTorch خود را آموزش دهیم، باید داده های خود را از قبل پردازش کنیم. اگر به مجموعه داده نگاه کنید، می بینید که دو نوع ستون دارد: عددی و دسته بندی. ستون های عددی حاوی اطلاعات عددی هستند. CreditScore، Balance، Ageو غیره به همین ترتیب، Geography و Gender ستونهای طبقهبندی هستند زیرا حاوی اطلاعات طبقهبندی مانند مکان و جنسیت مشتریان هستند. چند ستون وجود دارد که می توان آنها را به عنوان عددی و همچنین طبقه بندی کرد. به عنوان مثال، HasCrCard ستون می تواند 1 یا 0 را به عنوان مقادیر خود داشته باشد. با این حال HasCrCard ستون حاوی اطلاعاتی درباره داشتن یا نداشتن کارت اعتباری مشتری است. توصیه میشود که ستونهایی را که میتوان هم بهعنوان مقولهای و هم عددی در نظر گرفت، بهعنوان طبقهبندی در نظر گرفت. با این حال، کاملاً به دانش دامنه مجموعه داده بستگی دارد.
بیایید دوباره print تمام ستونهای مجموعه داده ما را دریابیم و بفهمیم که کدام یک از ستونها را میتوان عددی و کدام ستونها را بهعنوان طبقهبندی کرد. این columns ویژگی یک Dataframe تمام نام ستون ها را چاپ می کند:
dataset.columns
خروجی:
Index(('RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography',
'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard',
'IsActiveMember', 'EstimatedSalary', 'Exited'),
dtype='object')
از ستونهای مجموعه داده ما، ما از آن استفاده نخواهیم کرد RowNumber، CustomerId، و Surname ستونها زیرا مقادیر این ستونها کاملاً تصادفی هستند و هیچ ارتباطی با خروجی ندارند. به عنوان مثال، نام خانوادگی مشتری هیچ تاثیری ندارد روی آیا مشتری بانک را ترک خواهد کرد یا خیر. در بین بقیه ستون ها، Geography، Gender، HasCrCard، و IsActiveMember ستون ها را می توان به عنوان ستون های طبقه بندی کرد. بیایید لیستی از این ستون ها ایجاد کنیم:
categorical_columns = ('Geography', 'Gender', 'HasCrCard', 'IsActiveMember')
تمام ستون های باقی مانده به جز Exited ستون را می توان به عنوان ستون های عددی در نظر گرفت.
numerical_columns = ('CreditScore', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'EstimatedSalary')
در نهایت، خروجی (مقادیر از Exited ستون) در outputs متغیر.
outputs = ('Exited')
ما لیستی از ستون های دسته بندی، عددی و خروجی ایجاد کرده ایم. با این حال، در حال حاضر نوع ستون های طبقه بندی طبقه بندی نشده است. با اسکریپت زیر می توانید نوع تمام ستون های مجموعه داده را بررسی کنید:
dataset.dtypes
خروجی:
RowNumber int64
CustomerId int64
Surname object
CreditScore int64
Geography object
Gender object
Age int64
Tenure int64
Balance float64
NumOfProducts int64
HasCrCard int64
IsActiveMember int64
EstimatedSalary float64
Exited int64
dtype: object
شما می توانید ببینید که نوع برای Geography و Gender ستون ها شی و نوع برای است HasCrCard و IsActive ستون int64 است. ما باید انواع ستون های دسته بندی را به تبدیل کنیم category. ما می توانیم این کار را با استفاده از astype() عملکرد، همانطور که در زیر نشان داده شده است:
for category in categorical_columns:
dataset(category) = dataset(category).astype('category')
حال اگر دوباره انواع ستونها را در مجموعه داده ما رسم کنید، باید نتایج زیر را ببینید:
dataset.dtypes
خروجی
RowNumber int64
CustomerId int64
Surname object
CreditScore int64
Geography category
Gender category
Age int64
Tenure int64
Balance float64
NumOfProducts int64
HasCrCard category
IsActiveMember category
EstimatedSalary float64
Exited int64
dtype: object
بیایید اکنون تمام دسته بندی ها را در قسمت مشاهده کنیم Geography ستون:
dataset('Geography').cat.categories
خروجی:
Index(('France', 'Germany', 'Spain'), dtype='object')
هنگامی که نوع داده ستون را به دسته تغییر می دهید، به هر دسته در ستون یک کد منحصر به فرد اختصاص می یابد. برای مثال، بیایید پنج ردیف اول را رسم کنیم Geography ستون و print مقادیر کد برای پنج ردیف اول:
dataset('Geography').head()
خروجی:
0 France
1 Spain
2 France
3 France
4 Spain
Name: Geography, dtype: category
Categories (3, object): (France, Germany, Spain)
اسکریپت زیر کدهای مربوط به مقادیر پنج ردیف اول را ترسیم می کند Geography ستون:
dataset('Geography').head().cat.codes
خروجی:
0 0
1 2
2 0
3 0
4 2
dtype: int8
خروجی نشان می دهد که فرانسه با کد 0 و اسپانیا کد 2 شده است.
هدف اصلی از جداسازی ستونهای طبقهبندی از ستونهای عددی این است که مقادیر موجود در ستون عددی را میتوان مستقیماً به شبکههای عصبی تغذیه کرد. با این حال، مقادیر ستونهای دستهبندی ابتدا باید به انواع عددی تبدیل شوند. کدگذاری مقادیر در ستون طبقه بندی تا حدی وظیفه تبدیل عددی ستون های طبقه بندی را حل می کند.
از آنجایی که ما از PyTorch برای آموزش مدل استفاده خواهیم کرد، باید ستون های دسته بندی و عددی خود را به تانسور تبدیل کنیم.
ابتدا ستون های دسته بندی را به تانسور تبدیل می کنیم. در PyTorch، تانسورها را می توان از طریق آرایه های numpy ایجاد کرد. ابتدا دادههای چهار ستون طبقهبندی شده را به آرایههای numpy تبدیل میکنیم و سپس تمام ستونها را به صورت افقی روی هم قرار میدهیم، همانطور که در اسکریپت زیر نشان داده شده است:
geo = dataset('Geography').cat.codes.values
gen = dataset('Gender').cat.codes.values
hcc = dataset('HasCrCard').cat.codes.values
iam = dataset('IsActiveMember').cat.codes.values
categorical_data = np.stack((geo, gen, hcc, iam), 1)
categorical_data(:10)
اسکریپت بالا ده رکورد اول را از ستون های طبقه بندی شده، به صورت افقی چاپ می کند. خروجی به صورت زیر است:
خروجی:
array(((0, 0, 1, 1),
(2, 0, 0, 1),
(0, 0, 1, 0),
(0, 0, 0, 0),
(2, 0, 1, 1),
(2, 1, 1, 0),
(0, 1, 1, 1),
(1, 0, 1, 0),
(0, 1, 0, 1),
(0, 1, 1, 1)), dtype=int8)
حال برای ایجاد یک تانسور از آرایه numpy فوق الذکر، می توانید به سادگی آرایه را به tensor کلاس از torch مدول. به یاد داشته باشید، برای ستون های طبقه بندی شده، نوع داده باید باشد torch.int64.
categorical_data = torch.tensor(categorical_data, dtype=torch.int64)
categorical_data(:10)
خروجی:
tensor(((0, 0, 1, 1),
(2, 0, 0, 1),
(0, 0, 1, 0),
(0, 0, 0, 0),
(2, 0, 1, 1),
(2, 1, 1, 0),
(0, 1, 1, 1),
(1, 0, 1, 0),
(0, 1, 0, 1),
(0, 1, 1, 1)))
در خروجی، می توانید ببینید که آرایه numpy داده های طبقه بندی شده اکنون به یک تبدیل شده است. tensor هدف – شی.
به همین ترتیب، می توانیم ستون های عددی خود را به تانسور تبدیل کنیم:
numerical_data = np.stack((dataset(col).values for col in numerical_columns), 1)
numerical_data = torch.tensor(numerical_data, dtype=torch.float)
numerical_data(:5)
خروجی:
tensor(((6.1900e+02, 4.2000e+01, 2.0000e+00, 0.0000e+00, 1.0000e+00, 1.0135e+05),
(6.0800e+02, 4.1000e+01, 1.0000e+00, 8.3808e+04, 1.0000e+00, 1.1254e+05),
(5.0200e+02, 4.2000e+01, 8.0000e+00, 1.5966e+05, 3.0000e+00, 1.1393e+05),
(6.9900e+02, 3.9000e+01, 1.0000e+00, 0.0000e+00, 2.0000e+00, 9.3827e+04),
(8.5000e+02, 4.3000e+01, 2.0000e+00, 1.2551e+05, 1.0000e+00, 7.9084e+04)))
در خروجی، می توانید پنج ردیف اول حاوی مقادیر شش ستون عددی در مجموعه داده ما را ببینید.
مرحله آخر تبدیل آرایه numpy خروجی به a است tensor هدف – شی.
outputs = torch.tensor(dataset(outputs).values).flatten()
outputs(:5)
خروجی:
tensor((1, 0, 1, 0, 0))
اجازه دهید شکل داده های دسته بندی، داده های عددی و خروجی مربوطه را رسم کنیم:
print(categorical_data.shape)
print(numerical_data.shape)
print(outputs.shape)
خروجی:
torch.Size((10000, 4))
torch.Size((10000, 6))
torch.Size((10000))
قبل از اینکه بتوانیم مدل خود را آموزش دهیم یک مرحله بسیار مهم وجود دارد. ما ستون های دسته بندی خود را به عددی تبدیل کردیم که در آن یک مقدار منحصر به فرد با یک عدد صحیح نشان داده می شود. به عنوان مثال، در Geography در ستون، دیدیم که فرانسه با 0 و آلمان با 1 نشان داده شده است. ما می توانیم از این مقادیر برای آموزش مدل خود استفاده کنیم. با این حال، راه بهتر این است که به جای یک عدد صحیح، مقادیر را در یک ستون طبقهبندی به شکل یک بردار N بعدی نشان دهیم. یک بردار قادر به گرفتن اطلاعات بیشتر است و می تواند روابط بین مقادیر مقوله ای مختلف را به روش مناسب تری پیدا کند. بنابراین، مقادیر را در ستونهای طبقهبندی به شکل بردارهای N بعدی نشان خواهیم داد. این process تعبیه نامیده می شود.
ما باید اندازه تعبیه (ابعاد برداری) را برای تمام ستون های دسته بندی تعریف کنیم. هیچ قانون سخت و سریعی در مورد تعداد ابعاد وجود ندارد. یک قانون سرانگشتی خوب برای تعریف اندازه جاسازی برای یک ستون، تقسیم تعداد مقادیر منحصر به فرد در ستون بر 2 (اما نه بیشتر از 50) است. به عنوان مثال، برای Geography ستون، تعداد مقادیر منحصر به فرد 3 است. اندازه تعبیه مربوطه برای Geography ستون 3/2 = 1.5 = 2 (دور کردن) خواهد بود.
اسکریپت زیر یک تاپل ایجاد می کند که شامل تعداد مقادیر منحصر به فرد و اندازه ابعاد برای تمام ستون های طبقه بندی می شود:
categorical_column_sizes = (len(dataset(column).cat.categories) for column in categorical_columns)
categorical_embedding_sizes = ((col_size, min(50, (col_size+1)//2)) for col_size in categorical_column_sizes)
print(categorical_embedding_sizes)
خروجی:
((3, 2), (2, 1), (2, 1), (2, 1))
یک مدل یادگیری عمیق تحت نظارت، مانند مدلی که در این مقاله توسعه میدهیم، با استفاده از دادههای آموزشی آموزش داده میشود و عملکرد مدل ارزیابی میشود. روی مجموعه داده آزمایشی بنابراین، ما باید مجموعه داده های خود را به مجموعه های آموزشی و آزمایشی تقسیم کنیم، همانطور که در اسکریپت زیر نشان داده شده است:
total_records = 10000
test_records = int(total_records * .2)
categorical_train_data = categorical_data(:total_records-test_records)
categorical_test_data = categorical_data(total_records-test_records:total_records)
numerical_train_data = numerical_data(:total_records-test_records)
numerical_test_data = numerical_data(total_records-test_records:total_records)
train_outputs = outputs(:total_records-test_records)
test_outputs = outputs(total_records-test_records:total_records)
ما 10 هزار رکورد در مجموعه داده خود داریم که 80 درصد رکوردها یعنی 8000 رکورد برای آموزش مدل استفاده می شود در حالی که 20 درصد رکوردهای باقی مانده برای ارزیابی عملکرد مدل ما استفاده می شود. توجه کنید، در اسکریپت بالا، داده های دسته بندی و عددی و همچنین خروجی ها به مجموعه های آموزشی و آزمایشی تقسیم شده اند.
برای تأیید اینکه داده ها را به درستی به مجموعه های آموزشی و آزمایشی تقسیم کرده ایم، اجازه دهید print مدت زمان سوابق آموزش و آزمون:
print(len(categorical_train_data))
print(len(numerical_train_data))
print(len(train_outputs))
print(len(categorical_test_data))
print(len(numerical_test_data))
print(len(test_outputs))
خروجی:
8000
8000
8000
2000
2000
2000
ایجاد یک مدل برای پیش بینی
ما داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کرده ایم، اکنون زمان آن است که مدل خود را برای آموزش تعریف کنیم. برای انجام این کار، می توانیم یک کلاس به نام تعریف کنیم Model، که برای آموزش مدل استفاده خواهد شد. به اسکریپت زیر نگاه کنید:
class Model(nn.Module):
def __init__(self, embedding_size, num_numerical_cols, output_size, layers, p=0.4):
super().__init__()
self.all_embeddings = nn.ModuleList((nn.Embedding(ni, nf) for ni, nf in embedding_size))
self.embedding_dropout = nn.Dropout(p)
self.batch_norm_num = nn.BatchNorm1d(num_numerical_cols)
all_layers = ()
num_categorical_cols = sum((nf for ni, nf in embedding_size))
input_size = num_categorical_cols + num_numerical_cols
for i in layers:
all_layers.append(nn.Linear(input_size, i))
all_layers.append(nn.ReLU(inplace=True))
all_layers.append(nn.BatchNorm1d(i))
all_layers.append(nn.Dropout(p))
input_size = i
all_layers.append(nn.Linear(layers(-1), output_size))
self.layers = nn.Sequential(*all_layers)
def forward(self, x_categorical, x_numerical):
embeddings = ()
for i,e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical(:,i)))
x = torch.cat(embeddings, 1)
x = self.embedding_dropout(x)
x_numerical = self.batch_norm_num(x_numerical)
x = torch.cat((x, x_numerical), 1)
x = self.layers(x)
return x
اگر تا به حال با PyTorch کار نکرده اید، کد بالا ممکن است ترسناک به نظر برسد، با این حال سعی می کنم آن را برای شما تجزیه کنم.
در خط اول، a را اعلام می کنیم Model کلاسی که از the به ارث می برد Module کلاس از PyTorch’s nn مدول. در سازنده کلاس (the __init__() روش) پارامترهای زیر ارسال می شود:
embedding_size: شامل اندازه جاسازی برای ستون های دسته بندی شده استnum_numerical_cols: تعداد کل ستون های عددی را ذخیره می کندoutput_size: اندازه لایه خروجی یا تعداد خروجی های ممکن.layers: لیستی که شامل تعداد نورون برای همه لایه ها است.p: خروج با مقدار پیش فرض 0.5
در داخل سازنده، چند متغیر مقداردهی اولیه می شوند. اولا، all_embeddings متغیر شامل لیستی از ModuleList اشیاء برای تمام ستون های طبقه بندی شده. این embedding_dropout مقدار حذف را برای همه لایه ها ذخیره می کند. در نهایت، batch_norm_num لیستی از BatchNorm1d اشیاء برای تمام ستون های عددی.
در مرحله بعد، برای یافتن اندازه لایه ورودی، تعداد ستون های دسته بندی و عددی با هم جمع شده و در input_size متغیر. پس از آن، الف for حلقه تکرار می شود و لایه های مربوطه به آن اضافه می شوند all_layers فهرست لایه های اضافه شده عبارتند از:
Linear: برای محاسبه حاصل ضرب نقطه ای بین ورودی ها و ماتریس های وزنی استفاده می شودReLu: که به عنوان یک تابع فعال سازی اعمال می شودBatchNorm1d: برای اعمال نرمال سازی دسته ای به ستون های عددی استفاده می شودDropout: برای جلوگیری از نصب بیش از حد استفاده می شود
بعد از for حلقه، لایه خروجی به لیست لایه ها اضافه می شود. از آنجایی که می خواهیم تمام لایه های شبکه عصبی به صورت متوالی اجرا شوند، لیست لایه ها به nn.Sequential کلاس
بعد، در forward روش، هر دو ستون دسته بندی و عددی به عنوان ورودی ارسال می شوند. جاسازی ستون های طبقه بندی شده در خطوط زیر انجام می شود.
embeddings = ()
for i, e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical(:,i)))
x = torch.cat(embeddings, 1)
x = self.embedding_dropout(x)
نرمال سازی دسته ای ستون های عددی با اسکریپت زیر اعمال می شود:
x_numerical = self.batch_norm_num(x_numerical)
در نهایت، ستون های طبقه بندی شده تعبیه شده است x و ستون های عددی x_numerical به هم الحاق می شوند و به ترتیب منتقل می شوند layers.
آموزش مدل
برای آموزش مدل، ابتدا باید یک شی از the ایجاد کنیم Model کلاسی که در قسمت آخر تعریف کردیم.
model = Model(categorical_embedding_sizes, numerical_data.shape(1), 2, (200,100,50), p=0.4)
می بینید که اندازه جاسازی ستون های دسته بندی، تعداد ستون های عددی، اندازه خروجی (در مورد ما 2) و نورون ها در لایه های پنهان را پاس می کنیم. می بینید که ما سه لایه پنهان داریم که به ترتیب 200، 100 و 50 نورون دارند. در صورت تمایل می توانید هر سایز دیگری را انتخاب کنید.
اجازه دهید print مدل ما و ببینید که چگونه به نظر می رسد:
print(model)
خروجی:
Model(
(all_embeddings): ModuleList(
(0): Embedding(3, 2)
(1): Embedding(2, 1)
(2): Embedding(2, 1)
(3): Embedding(2, 1)
)
(embedding_dropout): Dropout(p=0.4)
(batch_norm_num): BatchNorm1d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(layers): Sequential(
(0): Linear(in_features=11, out_features=200, bias=True)
(1): ReLU(inplace)
(2): BatchNorm1d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.4)
(4): Linear(in_features=200, out_features=100, bias=True)
(5): ReLU(inplace)
(6): BatchNorm1d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.4)
(8): Linear(in_features=100, out_features=50, bias=True)
(9): ReLU(inplace)
(10): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): Dropout(p=0.4)
(12): Linear(in_features=50, out_features=2, bias=True)
)
)
می بینید که در اولین لایه خطی مقدار the in_features متغیر 11 است زیرا ما 6 ستون عددی داریم و مجموع ابعاد تعبیه شده برای ستون های طبقه بندی شده 5 است، بنابراین 6+5 = 11. به همین ترتیب، در آخرین لایه، out_features دارای مقدار 2 است زیرا ما فقط 2 خروجی ممکن داریم.
قبل از اینکه بتوانیم مدل خود را واقعاً آموزش دهیم، باید تابع ضرر و بهینهسازی را که برای آموزش مدل استفاده میشود، تعریف کنیم. از آنجایی که ما در حال حل یک مشکل طبقه بندی هستیم، از آن استفاده خواهیم کرد از دست دادن آنتروپی متقابل. برای تابع بهینه ساز، از بهینه ساز آدام.
اسکریپت زیر تابع ضرر و بهینه ساز را تعریف می کند:
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
اکنون ما همه چیز مورد نیاز برای آموزش مدل را داریم. اسکریپت زیر مدل را آموزش می دهد:
epochs = 300
aggregated_losses = ()
for i in range(epochs):
i += 1
y_pred = model(categorical_train_data, numerical_train_data)
single_loss = loss_function(y_pred, train_outputs)
aggregated_losses.append(single_loss)
if i%25 == 1:
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
optimizer.zero_grad()
single_loss.backward()
optimizer.step()
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}')
تعداد دوره ها روی 300 تنظیم شده است، به این معنی که برای آموزش مدل، مجموعه داده کامل 300 بار استفاده می شود. آ for حلقه 300 بار اجرا می شود و در طی هر تکرار، ضرر با استفاده از تابع ضرر محاسبه می شود. ضرر در طول هر تکرار به ضمیمه می شود aggregated_loss فهرست برای به روز رسانی وزنه ها، backward() عملکرد از single_loss شی نامیده می شود. در نهایت، step() روش از optimizer تابع گرادیان را به روز می کند. از دست دادن پس از هر 25 دوره چاپ می شود.
خروجی اسکریپت بالا به شرح زیر است:
epoch: 1 loss: 0.71847951
epoch: 26 loss: 0.57145703
epoch: 51 loss: 0.48110831
epoch: 76 loss: 0.42529839
epoch: 101 loss: 0.39972275
epoch: 126 loss: 0.37837571
epoch: 151 loss: 0.37133673
epoch: 176 loss: 0.36773482
epoch: 201 loss: 0.36305946
epoch: 226 loss: 0.36079505
epoch: 251 loss: 0.35350436
epoch: 276 loss: 0.35540250
epoch: 300 loss: 0.3465710580
اسکریپت زیر زیان ها را در برابر دوران ها ترسیم می کند:
plt.plot(range(epochs), aggregated_losses)
plt.ylabel('Loss')
plt.xlabel('epoch');
خروجی:

خروجی نشان می دهد که در ابتدا ضرر به سرعت کاهش می یابد. پس از حدود 250 دوره، کاهش بسیار کمی در ضرر وجود دارد.
پیشگویی
آخرین مرحله پیش بینی است روی داده های تست برای انجام این کار، ما به سادگی نیاز به عبور از categorical_test_data و numerical_test_data به model کلاس سپس مقادیر بازگشتی را می توان با مقادیر خروجی آزمایشی واقعی مقایسه کرد. اسکریپت زیر پیش بینی می کند روی کلاس تست و افت آنتروپی متقاطع را برای داده های تست چاپ می کند.
with torch.no_grad():
y_val = model(categorical_test_data, numerical_test_data)
loss = loss_function(y_val, test_outputs)
print(f'Loss: {loss:.8f}')
خروجی:
Loss: 0.36855841
از دست دادن روی مجموعه تست 0.3685 است که کمی بیشتر از 0.3465 به دست آمده است روی مجموعه آموزشی که نشان می دهد مدل ما کمی بیش از حد مناسب است.
توجه به این نکته مهم است که از آنجایی که ما مشخص کردیم که لایه خروجی ما شامل 2 نورون خواهد بود، هر پیش بینی حاوی 2 مقدار خواهد بود. برای مثال، 5 مقدار پیشبینیشده اول به این صورت است:
print(y_val(:5))
خروجی:
tensor((( 1.2045, -1.3857),
( 1.3911, -1.5957),
( 1.2781, -1.3598),
( 0.6261, -0.5429),
( 2.5430, -1.9991)))
ایده پشت چنین پیشبینیهایی این است که اگر خروجی واقعی 0 باشد، مقدار شاخص 0 باید بیشتر از مقدار شاخص 1 باشد و بالعکس. با اسکریپت زیر میتوانیم ایندکس بزرگترین مقدار موجود در لیست را بازیابی کنیم:
y_val = np.argmax(y_val, axis=1)
خروجی:
حالا دوباره print پنج مقدار اول برای y_val لیست:
print(y_val(:5))
خروجی:
tensor((0, 0, 0, 0, 0))
از آنجایی که در فهرست خروجیهای پیشبینیشده اولیه، برای پنج رکورد اول، مقادیر در شاخصهای صفر بزرگتر از مقادیر شاخصهای اول هستند، میتوانیم ۰ را در پنج ردیف اول خروجیهای پردازش شده ببینیم.
در نهایت می توانیم از confusion_matrix، accuracy_score، و classification_report کلاس ها از sklearn.metrics ماژول برای یافتن مقادیر دقت، دقت و فراخوانی مجموعه تست، همراه با ماتریس سردرگمی.
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
print(confusion_matrix(test_outputs,y_val))
print(classification_report(test_outputs,y_val))
print(accuracy_score(test_outputs, y_val))
خروجی:
((1527 83)
( 224 166))
precision recall f1-score support
0 0.87 0.95 0.91 1610
1 0.67 0.43 0.52 390
micro avg 0.85 0.85 0.85 2000
macro avg 0.77 0.69 0.71 2000
weighted avg 0.83 0.85 0.83 2000
0.8465
خروجی نشان می دهد که مدل ما به دقت 84.65% دست می یابد که با توجه به این واقعیت که ما به طور تصادفی تمام پارامترها را برای مدل شبکه عصبی خود انتخاب کردیم بسیار چشمگیر است. من پیشنهاد می کنم که سعی کنید پارامترهای مدل مانند تقسیم قطار/تست، تعداد و اندازه لایه های پنهان و غیره را تغییر دهید تا ببینید آیا می توانید نتایج بهتری بگیرید یا خیر.
نتیجه
PyTorch یک کتابخانه یادگیری عمیق است که توسط فیس بوک توسعه یافته و می تواند برای کارهای مختلفی مانند طبقه بندی، رگرسیون و خوشه بندی استفاده شود. این مقاله روش استفاده از کتابخانه PyTorch را برای طبقه بندی داده های جدولی توضیح می دهد.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-19 22:49:05
