از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این بیست و دومین مقاله از سری مقالات من است روی پایتون برای NLP. در یکی از مقالات قبلی من روی در حل مسائل توالی با Keras، توضیح دادم که چگونه می توان بسیاری از مسائل توالی را حل کرد که در آن ورودی ها و خروجی ها در چندین مرحله زمانی تقسیم می شوند. را معماری seq2seq نوعی مدلسازی توالی چند به چند است و معمولاً برای کارهای مختلفی مانند خلاصهسازی متن، توسعه رباتهای گفتگو، مدلسازی مکالمه و ترجمه ماشین عصبی و غیره استفاده میشود.
در این مقاله روش ایجاد یک مدل ترجمه زبان را خواهیم دید که یکی از کاربردهای بسیار معروف ترجمه ماشینی عصبی است. ما از معماری seq2seq برای ایجاد مدل ترجمه زبان خود با استفاده از پایتون استفاده خواهیم کرد کراس کتابخانه
فرض بر این است که شما دانش خوبی دارید شبکه های عصبی مکرر، به ویژه LSTM. کد این مقاله در پایتون با کتابخانه Keras نوشته شده است. بنابراین، فرض بر این است که شما از زبان پایتون و همچنین کتابخانه Keras دانش خوبی دارید. بنابراین، بدون هیچ مقدمه ای، بیایید شروع کنیم.
کتابخانه ها و تنظیمات پیکربندی
به عنوان اولین قدم، ما این کار را انجام خواهیم داد import کتابخانه های مورد نیاز و مقادیر را برای پارامترهای مختلفی که در کد استفاده خواهیم کرد پیکربندی می کند. اول بیایید import کتابخانه های مورد نیاز:
import os, sys
from keras.models import Model
from keras.layers import Input, LSTM, GRU, Dense, Embedding
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
اسکریپت زیر را برای تنظیم مقادیر برای پارامترهای مختلف اجرا کنید:
BATCH_SIZE = 64
EPOCHS = 20
LSTM_NODES =256
NUM_SENTENCES = 20000
MAX_SENTENCE_LENGTH = 50
MAX_NUM_WORDS = 20000
EMBEDDING_SIZE = 100
مجموعه داده
مدل ترجمه زبانی که در این مقاله میخواهیم ایجاد کنیم، جملات انگلیسی را به همتایان فرانسوی خود ترجمه میکند. برای توسعه چنین مدلی به مجموعه داده ای نیاز داریم که شامل جملات انگلیسی و ترجمه فرانسوی آنها باشد. خوشبختانه، چنین مجموعه داده ای به صورت رایگان در دسترس است این لینک. فایل را دانلود کنید fra-eng.zip و آن را استخراج کنید. سپس آن را خواهید دید fra.txt فایل. در هر خط، فایل متنی حاوی یک جمله انگلیسی و ترجمه فرانسوی آن است که با یک برگه جدا شده است. 20 خط اول از fra.txt فایل شبیه به این است:
Go. Va !
Hi. Salut !
Hi. Salut.
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
Fire! Au feu !
Help! À l'aide !
Jump. Saute.
Stop! Ça suffit !
Stop! Stop !
Stop! Arrête-toi !
Wait! Attends !
Wait! Attendez !
Go روی. Poursuis.
Go روی. Continuez.
Go روی. Poursuivez.
Hello! Bonjour !
Hello! Salut !
این مدل شامل بیش از 170000 رکورد است، اما ما فقط از 20000 رکورد اول برای آموزش مدل خود استفاده خواهیم کرد. در صورت تمایل می توانید از رکوردهای بیشتری استفاده کنید.
پیش پردازش داده ها
مدلهای ترجمه ماشین عصبی اغلب مبتنی هستند روی را seq2seq معماری. معماری seq2seq یک معماری رمزگذار-رمزگشا است که از دو شبکه LSTM تشکیل شده است: رمزگذار LSTM و رمزگشا LSTM. ورودی رمزگذار LSTM جمله زبان اصلی است. ورودی رمزگشا LSTM جمله به زبان ترجمه شده با نشانه شروع جمله است. خروجی عبارت هدف واقعی با نشانه پایان جمله است.
در مجموعه داده ما، ما نیازی به این کار نداریم process ورودی، با این حال، ما باید دو نسخه از جمله ترجمه شده تولید کنیم: یکی با نشانه شروع جمله و دیگری با نشانه پایان جمله. این اسکریپت است که این کار را انجام می دهد:
input_sentences = ()
output_sentences = ()
output_sentences_inputs = ()
count = 0
for line in open(r'/content/drive/My Drive/datasets/fra.txt', encoding="utf-8"):
count += 1
if count > NUM_SENTENCES:
break
if '\t' not in line:
continue
input_sentence, output = line.rstrip().split('\t')
output_sentence = output + ' <eos>'
output_sentence_input = '<sos> ' + output
input_sentences.append(input_sentence)
output_sentences.append(output_sentence)
output_sentences_inputs.append(output_sentence_input)
print("num samples input:", len(input_sentences))
print("num samples output:", len(output_sentences))
print("num samples output input:", len(output_sentences_inputs))
توجه داشته باشید: احتمالاً باید مسیر فایل را تغییر دهید fra.txt فایل روی کامپیوتر شما برای این کار
در اسکریپت بالا سه لیست ایجاد می کنیم input_sentences()، output_sentences()، و output_sentences_inputs(). بعد، در for حلقه fra.txt فایل خط به خط خوانده می شود. هر خط به دو رشته فرعی در موقعیتی که برگه رخ می دهد تقسیم می شود. رشته فرعی سمت چپ (جمله انگلیسی) در درج می شود input_sentences() فهرست رشته فرعی سمت راست برگه عبارت فرانسوی ترجمه شده مربوطه است. را <eos> نشانه ای که پایان جمله را نشان می دهد به جمله ترجمه شده پیشوند می شود و جمله حاصل به آن الحاق می شود. output_sentences() فهرست به طور مشابه، <sos> نشانه که مخفف “شروع جمله” است، در ابتدای جمله ترجمه شده الحاق می شود و نتیجه به عبارت اضافه می شود. output_sentences_inputs() فهرست حلقه خاتمه می یابد اگر تعداد جملات اضافه شده به لیست ها بیشتر از عدد باشد NUM_SENTENCES متغیر یعنی 20000.
در نهایت تعداد نمونه ها در سه لیست در خروجی نمایش داده می شود:
num samples input: 20000
num samples output: 20000
num samples output input: 20000
حالا به طور تصادفی print جمله ای از input_sentences()، output_sentences()، و output_sentences_inputs() لیست ها:
print(input_sentences(172))
print(output_sentences(172))
print(output_sentences_inputs(172))
در اینجا خروجی است:
I'm ill.
Je suis malade. <eos>
<sos> Je suis malade.
شما می توانید جمله اصلی را ببینید، یعنی I'm ill; ترجمه متناظر آن در خروجی، یعنی Je suis malade. <eos>. توجه کنید، در اینجا ما آن را داریم <eos> نشانه در پایان جمله به طور مشابه، برای ورودی به رمزگشا، ما داریم <sos> Je suis malade.
Tokenization و Padding
مرحله بعدی توکن کردن جملات اصلی و ترجمه شده و اعمال padding برای جملاتی است که از طول مشخصی بلندتر یا کوتاهتر هستند که در صورت ورودی، طول طولانی ترین جمله ورودی خواهد بود. و برای خروجی این طول طولانی ترین جمله در خروجی خواهد بود.
برای نشانه گذاری، Tokenizer کلاس از keras.preprocessing.text می توان از کتابخانه استفاده کرد. را tokenizer کلاس دو وظیفه را انجام می دهد:
- این یک جمله را به لیست مربوط به کلمه تقسیم می کند
- سپس کلمات را به اعداد صحیح تبدیل می کند
این بسیار مهم است زیرا الگوریتم های یادگیری عمیق و یادگیری ماشین با اعداد کار می کنند. اسکریپت زیر برای نشانه گذاری جملات ورودی استفاده می شود:
input_tokenizer = Tokenizer(num_words=MAX_NUM_WORDS)
input_tokenizer.fit_on_texts(input_sentences)
input_integer_seq = input_tokenizer.texts_to_sequences(input_sentences)
word2idx_inputs = input_tokenizer.word_index
print('Total unique words in the input: %s' % len(word2idx_inputs))
max_input_len = max(len(sen) for sen in input_integer_seq)
print("Length of longest sentence in input: %g" % max_input_len)
علاوه بر توکن سازی و تبدیل اعداد صحیح، word_index ویژگی از Tokenizer class یک فرهنگ لغت کلمه به فهرست را برمی گرداند که در آن کلمات کلیدها و اعداد صحیح مربوطه مقادیر هستند. اسکریپت بالا همچنین تعداد کلمات منحصر به فرد در فرهنگ لغت و طول طولانی ترین جمله را در ورودی چاپ می کند:
Total unique words in the input: 3523
Length of longest sentence in input: 6
به طور مشابه، جملات خروجی را می توان به همان روشی که در زیر نشان داده شده است نشانه گذاری کرد:
output_tokenizer = Tokenizer(num_words=MAX_NUM_WORDS, filters='')
output_tokenizer.fit_on_texts(output_sentences + output_sentences_inputs)
output_integer_seq = output_tokenizer.texts_to_sequences(output_sentences)
output_input_integer_seq = output_tokenizer.texts_to_sequences(output_sentences_inputs)
word2idx_outputs = output_tokenizer.word_index
print('Total unique words in the output: %s' % len(word2idx_outputs))
num_words_output = len(word2idx_outputs) + 1
max_out_len = max(len(sen) for sen in output_integer_seq)
print("Length of longest sentence in the output: %g" % max_out_len)
در اینجا خروجی است:
Total unique words in the output: 9561
Length of longest sentence in the output: 13
از مقایسه تعداد کلمات منحصر به فرد در ورودی و خروجی، می توان نتیجه گرفت که جملات انگلیسی معمولاً کوتاهتر هستند و تعداد کلمات کمتری دارند. روی متوسط، در مقایسه با جملات فرانسوی ترجمه شده است.
بعد، باید ورودی را pad کنیم. دلیل اضافه کردن ورودی و خروجی این است که جملات متنی می توانند طول متفاوتی داشته باشند، با این حال LSTM (الگوریتمی که می خواهیم مدل خود را آموزش دهیم) نمونه های ورودی با طول یکسان را انتظار دارد. بنابراین، باید جملات خود را به بردارهایی با طول ثابت تبدیل کنیم. یکی از راه های انجام این کار از طریق padding است.
در padding طول مشخصی برای جمله تعریف می شود. در مورد ما، طول طولانیترین جمله در ورودیها و خروجیها به ترتیب برای اضافه کردن جملات ورودی و خروجی استفاده میشود. طولانی ترین جمله در ورودی شامل 6 کلمه است. برای جملاتی که کمتر از 6 کلمه دارند، صفر در نمایه های خالی اضافه می شود. اسکریپت زیر padding را برای جملات ورودی اعمال می کند.
encoder_input_sequences = pad_sequences(input_integer_seq, maxlen=max_input_len)
print("encoder_input_sequences.shape:", encoder_input_sequences.shape)
print("encoder_input_sequences(172):", encoder_input_sequences(172))
اسکریپت بالا شکل جملات ورودی پر شده را چاپ می کند. دنباله اعداد صحیح برای جمله در نمایه 172 نیز چاپ شده است. در اینجا خروجی است:
encoder_input_sequences.shape: (20000, 6)
encoder_input_sequences(172): ( 0 0 0 0 6 539)
از آنجایی که 20000 جمله در ورودی وجود دارد و هر جمله ورودی 6 طول دارد، شکل ورودی اکنون (20000، 6) است. اگر به دنباله اعداد صحیح جمله در نمایه 172 جمله ورودی نگاه کنید، می بینید که سه صفر و به دنبال آن مقادیر 6 و 539 وجود دارد. ممکن است به یاد داشته باشید که جمله اصلی در شاخص 172 I'm ill. را tokenizer جمله را به دو کلمه تقسیم کرد I'm و ill، آنها را به اعداد صحیح تبدیل کرد و سپس با افزودن سه صفر در ابتدای دنباله اعداد صحیح متناظر برای جمله در نمایه 172 لیست ورودی، از پیش پد استفاده کرد.
برای تأیید اینکه عدد صحیح برای i'm و ill به ترتیب 6 و 539 هستند، می توانید کلمات را به آن منتقل کنید word2index_inputs فرهنگ لغت، همانطور که در زیر نشان داده شده است:
print(word2idx_inputs("i'm"))
print(word2idx_inputs("ill"))
خروجی:
6
539
به همین ترتیب، خروجی های رسیور و ورودی های رسیور به صورت زیر قرار می گیرند:
decoder_input_sequences = pad_sequences(output_input_integer_seq, maxlen=max_out_len, padding='post')
print("decoder_input_sequences.shape:", decoder_input_sequences.shape)
print("decoder_input_sequences(172):", decoder_input_sequences(172))
خروجی:
decoder_input_sequences.shape: (20000, 13)
decoder_input_sequences(172): ( 2 3 6 188 0 0 0 0 0 0 0 0 0)
جمله در شاخص 172 ورودی رمزگشا می باشد <sos> je suis malade.. اگر شما print اعداد صحیح مربوطه از word2idx_outputs فرهنگ لغت، باید 2، 3، 6 و 188 را چاپ شده ببینید روی را console، همانطور که در اینجا نشان داده شده است:
print(word2idx_outputs("<sos>"))
print(word2idx_outputs("je"))
print(word2idx_outputs("suis"))
print(word2idx_outputs("malade."))
خروجی:
2
3
6
188
در ادامه ذکر این نکته ضروری است که در مورد رسیور، post-padding اعمال می شود، به این معنی که صفرها در انتهای جمله اضافه می شوند. در رمزگذار، صفرها در قسمت قرار داده شده بودند شروع. دلیل این رویکرد این است که خروجی رمزگذار مبتنی است روی کلماتی که در انتهای جمله قرار می گیرند، بنابراین کلمات اصلی در انتهای جمله و صفرها در ابتدا قرار می گیرند. از طرف دیگر، در مورد رمزگشا، پردازش از ابتدای جمله شروع می شود و بنابراین پس padding انجام می شود. روی ورودی و خروجی رمزگشا
جاسازی های کلمه
من یک مقاله مفصل نوشته ام روی جاسازی های کلمه، که ممکن است بخواهید برای درک جاسازی کلمات در Keras بررسی کنید. این بخش فقط اجرای جاسازی های کلمه را برای ترجمه ماشین عصبی ارائه می دهد. با این حال مفهوم اصلی یکسان است.
از آنجایی که ما از مدلهای یادگیری عمیق استفاده میکنیم، و مدلهای یادگیری عمیق با اعداد کار میکنند، بنابراین باید کلمات خود را به نمایشهای برداری عددی مربوطه تبدیل کنیم. اما ما قبلاً کلمات خود را به اعداد صحیح تبدیل کردیم. بنابراین تفاوت بین نمایش اعداد صحیح و جاسازی کلمه چیست؟
دو تفاوت اصلی بین نمایش یک عدد صحیح و جاسازی کلمه وجود دارد. با نمایش عدد صحیح، یک کلمه فقط با یک عدد صحیح نمایش داده می شود. با نمایش برداری، یک کلمه با بردار 50، 100، 200 یا هر ابعادی که دوست دارید نشان داده می شود. از این رو، جاسازی کلمات اطلاعات بیشتری را در مورد کلمات به دست میآورد. ثانیا، نمایش یک عدد صحیح روابط بین کلمات مختلف را نشان نمی دهد. برعکس، تعبیه کلمات روابط بین کلمات را حفظ می کند. می توانید از جاسازی کلمات سفارشی استفاده کنید یا می توانید از جاسازی کلمات از پیش آموزش دیده استفاده کنید.
در این مقاله برای جملات انگلیسی یعنی ورودی ها از the استفاده می کنیم دستکش جاسازی کلمات برای جملات فرانسوی ترجمه شده در خروجی، از جاسازی کلمات سفارشی استفاده خواهیم کرد.
بیایید ابتدا جاسازی کلمه برای ورودی ها ایجاد کنیم. برای انجام این کار، باید بردارهای کلمه GloVe را در حافظه بارگذاری کنیم. سپس یک فرهنگ لغت ایجاد می کنیم که در آن کلمات کلید و بردارهای مربوطه مقادیر هستند، همانطور که در زیر نشان داده شده است:
from numpy import array
from numpy import asarray
from numpy import zeros
embeddings_dictionary = dict()
glove_file = open(r'/content/drive/My Drive/datasets/glove.6B.100d.txt', encoding="utf8")
for line in glove_file:
records = line.split()
word = records(0)
vector_dimensions = asarray(records(1:), dtype='float32')
embeddings_dictionary(word) = vector_dimensions
glove_file.close()
به یاد بیاورید که ما 3523 کلمه منحصر به فرد در ورودی داریم. ماتریسی ایجاد می کنیم که در آن شماره ردیف مقدار صحیح کلمه را نشان می دهد و ستون ها با ابعاد کلمه مطابقت دارند. این ماتریس حاوی کلمات جاسازی شده برای کلمات در جملات ورودی ما خواهد بود.
num_words = min(MAX_NUM_WORDS, len(word2idx_inputs) + 1)
embedding_matrix = zeros((num_words, EMBEDDING_SIZE))
for word, index in word2idx_inputs.items():
embedding_vector = embeddings_dictionary.get(word)
if embedding_vector is not None:
embedding_matrix(index) = embedding_vector
اول بیایید print تعبیه کلمه برای کلمه ill با استفاده از فرهنگ لغت جاسازی کلمه GloVe.
print(embeddings_dictionary("ill"))
خروجی:
( 0.12648 0.1366 0.22192 -0.025204 -0.7197 0.66147
0.48509 0.057223 0.13829 -0.26375 -0.23647 0.74349
0.46737 -0.462 0.20031 -0.26302 0.093948 -0.61756
-0.28213 0.1353 0.28213 0.21813 0.16418 0.22547
-0.98945 0.29624 -0.62476 -0.29535 0.21534 0.92274
0.38388 0.55744 -0.14628 -0.15674 -0.51941 0.25629
-0.0079678 0.12998 -0.029192 0.20868 -0.55127 0.075353
0.44746 -0.71046 0.75562 0.010378 0.095229 0.16673
0.22073 -0.46562 -0.10199 -0.80386 0.45162 0.45183
0.19869 -1.6571 0.7584 -0.40298 0.82426 -0.386
0.0039546 0.61318 0.02701 -0.3308 -0.095652 -0.082164
0.7858 0.13394 -0.32715 -0.31371 -0.14037 -0.73001
-0.49343 0.56445 0.61038 0.36777 -0.070182 0.44859
-0.61774 -0.18849 0.65592 0.44797 -0.10469 0.62512
-1.9474 -0.60622 0.073874 0.50013 -1.1278 -0.42066
-0.37322 -0.50538 0.59171 0.46534 -0.42482 0.83265
0.081548 -0.44147 -0.084311 -1.2304 )
در قسمت قبل دیدیم که نمایش عدد صحیح برای کلمه است ill 539 است. حال بیایید شاخص 539 کلمه ماتریس تعبیه را بررسی کنیم.
print(embedding_matrix(539))
خروجی:
( 0.12648 0.1366 0.22192 -0.025204 -0.7197 0.66147
0.48509 0.057223 0.13829 -0.26375 -0.23647 0.74349
0.46737 -0.462 0.20031 -0.26302 0.093948 -0.61756
-0.28213 0.1353 0.28213 0.21813 0.16418 0.22547
-0.98945 0.29624 -0.62476 -0.29535 0.21534 0.92274
0.38388 0.55744 -0.14628 -0.15674 -0.51941 0.25629
-0.0079678 0.12998 -0.029192 0.20868 -0.55127 0.075353
0.44746 -0.71046 0.75562 0.010378 0.095229 0.16673
0.22073 -0.46562 -0.10199 -0.80386 0.45162 0.45183
0.19869 -1.6571 0.7584 -0.40298 0.82426 -0.386
0.0039546 0.61318 0.02701 -0.3308 -0.095652 -0.082164
0.7858 0.13394 -0.32715 -0.31371 -0.14037 -0.73001
-0.49343 0.56445 0.61038 0.36777 -0.070182 0.44859
-0.61774 -0.18849 0.65592 0.44797 -0.10469 0.62512
-1.9474 -0.60622 0.073874 0.50013 -1.1278 -0.42066
-0.37322 -0.50538 0.59171 0.46534 -0.42482 0.83265
0.081548 -0.44147 -0.084311 -1.2304 )
می بینید که مقادیر ردیف 539 در ماتریس جاسازی شبیه به نمایش برداری کلمه است. ill در فرهنگ لغت GloVe، که تأیید میکند که ردیفها در ماتریس جاسازی، جاسازیهای کلمه مربوطه را از فرهنگ لغت جاسازی کلمه GloVe نشان میدهند. این ماتریس تعبیه کلمه برای ایجاد لایه جاسازی برای مدل LSTM ما استفاده خواهد شد.
اسکریپت زیر لایه جاسازی را برای ورودی ایجاد می کند:
embedding_layer = Embedding(num_words, EMBEDDING_SIZE, weights=(embedding_matrix), input_length=max_input_len)
ایجاد مدل
اکنون زمان آن است که مدل خود را توسعه دهیم. اولین کاری که باید انجام دهیم این است که خروجی های خود را تعریف کنیم، زیرا می دانیم که خروجی دنباله ای از کلمات خواهد بود. به یاد بیاورید که تعداد کل کلمات منحصر به فرد در خروجی 9562 است. بنابراین، هر کلمه در خروجی می تواند هر یک از 9562 کلمه باشد. طول یک جمله خروجی 13 است. و برای هر جمله ورودی، به یک جمله خروجی مربوطه نیاز داریم. بنابراین، شکل نهایی خروجی به صورت زیر خواهد بود:
(number of inputs, length of the output sentence, the number of words in the output)
اسکریپت زیر آرایه خروجی خالی را ایجاد می کند:
decoder_targets_one_hot = np.zeros((
len(input_sentences),
max_out_len,
num_words_output
),
dtype='float32'
)
اسکریپت زیر شکل رمزگشا را چاپ می کند:
decoder_targets_one_hot.shape
خروجی:
(20000, 13, 9562)
برای پیش بینی، لایه نهایی مدل یک لایه متراکم خواهد بود، بنابراین ما به خروجی ها به شکل بردارهای کدگذاری شده یک داغ نیاز داریم، زیرا از تابع فعال سازی softmax در لایه متراکم استفاده خواهیم کرد. برای ایجاد چنین خروجی کدگذاری شده یک داغ، مرحله بعدی اختصاص 1 به شماره ستون است که با نمایش عدد صحیح کلمه مطابقت دارد. به عنوان مثال، نمایش عدد صحیح برای <sos> je suis malade است ( 2 3 6 188 0 0 0 0 0 0 0 ). در decoder_targets_one_hot آرایه خروجی، در ستون دوم سطر اول، 1 درج خواهد شد. به همین ترتیب، در شاخص سوم از ردیف دوم، 1 دیگر درج خواهد شد، و به همین ترتیب روی.
به اسکریپت زیر نگاه کنید:
for i, d in enumerate(decoder_output_sequences):
for t, word in enumerate(d):
decoder_targets_one_hot(i, t, word) = 1
بعد، ما باید رمزگذار و رمزگشا را ایجاد کنیم. ورودی رمزگذار عبارت به زبان انگلیسی و خروجی حالت مخفی و حالت سلولی LSTM خواهد بود.
اسکریپت زیر رمزگذار را تعریف می کند:
encoder_inputs_placeholder = Input(shape=(max_input_len,))
x = embedding_layer(encoder_inputs_placeholder)
encoder = LSTM(LSTM_NODES, return_state=True)
encoder_outputs, h, c = encoder(x)
encoder_states = (h, c)
مرحله بعدی تعریف رمزگشا است. رمزگشا دو ورودی خواهد داشت: حالت پنهان و حالت سلول از رمزگذار و جمله ورودی که در واقع جمله خروجی با یک خواهد بود. <sos> توکن در ابتدا ضمیمه شده است.
اسکریپت زیر رمزگشا LSTM را ایجاد می کند:
decoder_inputs_placeholder = Input(shape=(max_out_len,))
decoder_embedding = Embedding(num_words_output, LSTM_NODES)
decoder_inputs_x = decoder_embedding(decoder_inputs_placeholder)
decoder_lstm = LSTM(LSTM_NODES, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs_x, initial_state=encoder_states)
در نهایت، خروجی از رمزگشا LSTM از یک لایه متراکم عبور می کند تا خروجی های رمزگشا را پیش بینی کند، همانطور که در اینجا نشان داده شده است:
decoder_dense = Dense(num_words_output, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
مرحله بعدی کامپایل مدل است:
model = Model((encoder_inputs_placeholder,
decoder_inputs_placeholder), decoder_outputs)
model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=('accuracy')
)
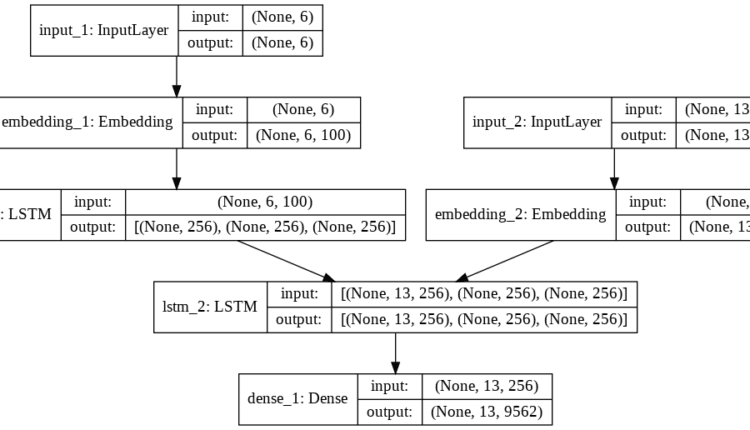
بیایید مدل خود را ترسیم کنیم تا ببینیم چگونه به نظر می رسد:
from keras.utils import plot_model
plot_model(model, to_file='model_plot4a.png', show_shapes=True, show_layer_names=True)
خروجی:

از خروجی می بینید که دو نوع ورودی داریم. input_1 محل ورودی برای رمزگذار است که تعبیه شده و از آن عبور می کند lstm_1 لایه، که اساسا رمزگذار LSTM است. سه خروجی از lstm_1 لایه: خروجی، لایه پنهان و حالت سلول. با این حال، تنها حالت سلول و حالت پنهان به رمزگشا منتقل می شود.
اینجا lstm_2 لایه رمزگشا LSTM است. را input_2 شامل جملات خروجی با <sos> نشانه اضافه شده در ابتدا را input_2 همچنین از یک لایه تعبیه شده عبور می کند و به عنوان ورودی رمزگشا LSTM استفاده می شود. lstm_2. در نهایت، خروجی از رمزگشا LSTM از لایه متراکم عبور داده می شود تا پیش بینی شود.
مرحله بعدی آموزش مدل با استفاده از fit() روش:
r = model.fit(
(encoder_input_sequences, decoder_input_sequences),
decoder_targets_one_hot,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_split=0.1,
)
مدل آموزش دیده است روی 18000 رکورد و تست شده روی 2000 رکورد باقی مانده این مدل برای 20 دوره آموزش داده شده است، می توانید تعداد دوره ها را تغییر دهید تا ببینید آیا می توانید نتایج بهتری بگیرید. پس از 20 دوره، دقت آموزش 90.99٪ و دقت اعتبار 79.11٪ را دریافت کردم که نشان می دهد مدل بیش از حد برازش است. برای کاهش اضافه برازش، میتوانید ترک تحصیل یا رکوردهای بیشتری را اضافه کنید. ما فقط در حال تمرین هستیم روی 200000 رکورد، بنابراین می توانید رکوردهای بیشتری را برای کاهش بیش از حد برازش اضافه کنید.
اصلاح مدل برای پیش بینی ها
در حین آموزش، ما ورودی های واقعی رمزگشا را برای همه کلمات خروجی در دنباله می دانیم. نمونه ای از اتفاقاتی که در طول تمرین می افتد به شرح زیر است. فرض کنید یک جمله داریم i'm ill. جمله به صورت زیر ترجمه می شود:
// Inputs روی the left of Encoder/Decoder, outputs روی the right.
Step 1:
I'm ill -> Encoder -> enc(h1,c1)
enc(h1,c1) + <sos> -> Decoder -> je + dec(h1,c1)
step 2:
enc(h1,c1) + je -> Decoder -> suis + dec(h2,c2)
step 3:
enc(h2,c2) + suis -> Decoder -> malade. + dec(h3,c3)
step 3:
enc(h3,c3) + malade. -> Decoder -> <eos> + dec(h4,c4)
می بینید که ورودی رسیور و خروجی از رسیور مشخص است و مدل آموزش دیده است. روی اساس این ورودی ها و خروجی ها است.
با این حال، در طول پیش بینی کلمه بعدی پیش بینی می شود روی اساس کلمه قبلی که به نوبه خود در مرحله زمانی قبلی نیز پیش بینی شده است. حالا هدف را متوجه خواهید شد <sos> و <eos> توکن ها در حین انجام پیش بینی های واقعی، توالی خروجی کامل در دسترس نیست، در واقع این چیزی است که ما باید پیش بینی کنیم. در طول پیش بینی تنها کلمه ای که در دسترس ماست این است <sos> از آنجایی که تمام جملات خروجی با شروع می شوند <sos>.
نمونه ای از آنچه در حین پیش بینی اتفاق می افتد به شرح زیر است. ما دوباره جمله را ترجمه می کنیم i'm ill:
// Inputs روی the left of Encoder/Decoder, outputs روی the right.
Step 1:
I'm ill -> Encoder -> enc(h1,c1)
enc(h1,c1) + <sos> -> Decoder -> y1(je) + dec(h1,c1)
step 2:
enc(h1,c1) + y1 -> Decoder -> y2(suis) + dec(h2,c2)
step 3:
enc(h2,c2) + y2 -> Decoder -> y3(malade.) + dec(h3,c3)
step 3:
enc(h3,c3) + y3 -> Decoder -> y4(<eos>) + dec(h4,c4)
می بینید که عملکرد رمزگذار ثابت می ماند. جمله در زبان اصلی از رمزگذار و حالت پنهان عبور داده می شود و حالت سلول خروجی از رمزگذار است.
در مرحله 1، وضعیت پنهان و وضعیت سلول رمزگذار، و <sos>، به عنوان ورودی رمزگشا استفاده می شود. رمزگشا یک کلمه را پیش بینی می کند y1 که ممکن است درست باشد یا نباشد. با این حال، طبق مدل ما، احتمال پیشبینی صحیح 0.7911 است. در مرحله 2، رسیور حالت پنهان و وضعیت سلول از مرحله 1، همراه با y1، به عنوان ورودی رمزگشا استفاده می شود که پیش بینی می کند y2. را process ادامه دارد تا اینکه <eos> نشانه مواجه می شود. سپس تمام خروجی های پیش بینی شده از رمزگشا به هم متصل می شوند تا جمله خروجی نهایی را تشکیل دهند. بیایید مدل خود را برای اجرای این منطق اصلاح کنیم.
مدل رمزگذار ثابت می ماند:
encoder_model = Model(encoder_inputs_placeholder, encoder_states)
از آنجایی که اکنون در هر مرحله به رسیور مخفی و حالت سلولی نیاز داریم، مدل خود را طوری تغییر می دهیم که حالت های مخفی و سلولی را مطابق شکل زیر بپذیرد:
decoder_state_input_h = Input(shape=(LSTM_NODES,))
decoder_state_input_c = Input(shape=(LSTM_NODES,))
decoder_states_inputs = (decoder_state_input_h, decoder_state_input_c)
اکنون در هر مرحله زمانی، تنها یک کلمه در ورودی رمزگشا وجود خواهد داشت، ما باید لایه تعبیه رمزگشا را به صورت زیر تغییر دهیم:
decoder_inputs_single = Input(shape=(1,))
decoder_inputs_single_x = decoder_embedding(decoder_inputs_single)
در مرحله بعد، ما باید یک مکان نگهدار برای خروجی های رمزگشا ایجاد کنیم:
decoder_outputs, h, c = decoder_lstm(decoder_inputs_single_x, initial_state=decoder_states_inputs)
برای انجام پیشبینی، خروجی رمزگشا از لایه متراکم عبور میکند:
decoder_states = (h, c)
decoder_outputs = decoder_dense(decoder_outputs)
مرحله نهایی تعریف مدل رمزگشای به روز شده است، همانطور که در اینجا نشان داده شده است:
decoder_model = Model(
(decoder_inputs_single) + decoder_states_inputs,
(decoder_outputs) + decoder_states
)
بیایید اکنون رمزگشای اصلاح شده LSTM را ترسیم کنیم که پیش بینی می کند:
from keras.utils import plot_model
plot_model(decoder_model, to_file='model_plot_dec.png', show_shapes=True, show_layer_names=True)
خروجی:

در تصویر بالا lstm_2 رمزگشای اصلاح شده LSTM است. می بینید که جمله را با یک کلمه می پذیرد همانطور که در نشان داده شده است input_5و حالت های مخفی و سلولی از خروجی قبلی (input_3 و input_4). می بینید که شکل جمله ورودی اکنون است (none,1) زیرا تنها یک کلمه در ورودی رمزگشا وجود خواهد داشت. برعکس، در طول آموزش شکل جمله ورودی بود (None,6) از آنجایی که ورودی حاوی یک جمله کامل با طول حداکثر 6 بود.
پیشگویی
در این مرحله روش پیش بینی را با استفاده از جملات انگلیسی به عنوان ورودی خواهید دید.
در مراحل توکن سازی، کلمات را به اعداد صحیح تبدیل کردیم. خروجی های رسیور نیز اعداد صحیح خواهند بود. با این حال، ما می خواهیم خروجی ما دنباله ای از کلمات در زبان فرانسوی باشد. برای انجام این کار، باید اعداد صحیح را به کلمات تبدیل کنیم. ما دیکشنری های جدیدی برای ورودی ها و خروجی ها ایجاد خواهیم کرد که در آن کلیدها اعداد صحیح و مقادیر مربوطه کلمات خواهند بود.
idx2word_input = {v:k for k, v in word2idx_inputs.items()}
idx2word_target = {v:k for k, v in word2idx_outputs.items()}
بعد ما یک متد ایجاد می کنیم، یعنی translate_sentence(). این روش یک جمله انگلیسی دنباله دار با ورودی (به شکل عدد صحیح) را می پذیرد و جمله فرانسوی ترجمه شده را برمی گرداند. نگاه کن به translate_sentence() روش:
def translate_sentence(input_seq):
states_value = encoder_model.predict(input_seq)
target_seq = np.zeros((1, 1))
target_seq(0, 0) = word2idx_outputs('<sos>')
eos = word2idx_outputs('<eos>')
output_sentence = ()
for _ in range(max_out_len):
output_tokens, h, c = decoder_model.predict((target_seq) + states_value)
idx = np.argmax(output_tokens(0, 0, :))
if eos == idx:
break
word = ''
if idx > 0:
word = idx2word_target(idx)
output_sentence.append(word)
target_seq(0, 0) = idx
states_value = (h, c)
return ' '.join(output_sentence)
در اسکریپت بالا دنباله ورودی را به encoder_model، که حالت پنهان و حالت سلول را پیش بینی می کند که در ذخیره می شود states_value متغیر.
سپس یک متغیر تعریف می کنیم target_seq، که یک است 1 x 1 ماتریس تمام صفرها را target_seq متغیر شامل اولین کلمه مدل رمزگشا می باشد که عبارت است از <sos>.
پس از آن، eos متغیر مقداردهی اولیه را ذخیره می کند <eos> نشانه در خط بعدی، output_sentence لیستی تعریف شده است که حاوی ترجمه پیش بینی شده است.
بعد، a را اجرا می کنیم for حلقه تعداد چرخه های اجرا برای for حلقه برابر است با طول طولانی ترین جمله در خروجی. در داخل حلقه، در اولین تکرار، the decoder_model خروجی و حالت های مخفی و سلولی را با استفاده از حالت مخفی و سلولی رمزگذار و رمز ورودی، یعنی <sos>. شاخص کلمه پیش بینی شده در ذخیره می شود idx متغیر. اگر مقدار شاخص پیش بینی شده برابر باشد <eos> نشانه، حلقه خاتمه می یابد. در غیر این صورت اگر شاخص پیش بینی شده بزرگتر از صفر باشد، کلمه مربوطه از آن بازیابی می شود idx2word فرهنگ لغت و در ذخیره می شود word متغیر، که سپس به ضمیمه می شود output_sentence فهرست را states_value متغیر با وضعیت جدید مخفی و سلولی رمزگشا به روز می شود و شاخص کلمه پیش بینی شده در آن ذخیره می شود. target_seq متغیر. در چرخه حلقه بعدی، حالت های مخفی و سلولی به روز شده، همراه با شاخص کلمه پیش بینی شده قبلی، برای پیش بینی های جدید استفاده می شود. حلقه تا رسیدن به حداکثر طول دنباله خروجی ادامه می یابد <eos> نشانه مواجه می شود.
در نهایت، کلمات در output_sentence لیست ها با استفاده از یک فاصله به هم متصل می شوند و رشته حاصل به تابع فراخوانی بازگردانده می شود.
تست مدل
برای تست کد، به صورت تصادفی یک جمله از کد را انتخاب می کنیم input_sentences لیست، دنباله مربوط به padded جمله را بازیابی کرده و به آن ارسال می کند translate_sentence() روش. متد جمله ترجمه شده را مطابق شکل زیر برمی گرداند.
در اینجا اسکریپت برای آزمایش عملکرد مدل آمده است:
i = np.random.choice(len(input_sentences))
input_seq = encoder_input_sequences(i:i+1)
translation = translate_sentence(input_seq)
print('-')
print('Input:', input_sentences(i))
print('Response:', translation)
در اینجا خروجی است:
-
Input: You're not fired.
Response: vous n'êtes pas viré.
درخشان، اینطور نیست؟ مدل ما این جمله را با موفقیت ترجمه کرده است You're not fired به زبان فرانسه شما می توانید آن را تأیید کنید روی مترجم گوگل هم بیایید یکی دیگر را امتحان کنیم.
توجه داشته باشید: از آنجایی که جملات به صورت تصادفی انتخاب می شوند، به احتمال زیاد یک جمله انگلیسی متفاوتی خواهید داشت که به فرانسوی ترجمه شده است.
اسکریپت بالا را یک بار دیگر اجرا کنید تا برخی از جمله های انگلیسی دیگر را به زبان فرانسوی ترجمه کنید. من نتایج زیر را گرفتم:
-
Input: I'm not a lawyer.
Response: je ne suis pas avocat.
این مدل با موفقیت یک جمله انگلیسی دیگر را به فرانسوی ترجمه کرده است.
نتیجه گیری و دیدگاه
ترجمه ماشین عصبی یک کاربرد نسبتاً پیشرفته از پردازش زبان طبیعی است و شامل یک معماری بسیار پیچیده است.
این مقاله روش انجام ترجمه ماشین عصبی را از طریق معماری seq2seq توضیح می دهد که به نوبه خود مبتنی بر آن است روی مدل رمزگذار-رمزگشا رمزگذار یک LSTM است که جملات ورودی را رمزگذاری می کند در حالی که رمزگشا ورودی ها را رمزگشایی می کند و خروجی های مربوطه را تولید می کند. تکنیک توضیح داده شده در این مقاله را می توان برای ایجاد هر مدل ترجمه ماشینی استفاده کرد، تا زمانی که مجموعه داده در قالبی مشابه با فرمت مورد استفاده در این مقاله باشد. همچنین می توانید از معماری seq2seq برای توسعه ربات های چت استفاده کنید.
معماری seq2seq در نگاشت روابط ورودی به خروجی بسیار موفق است. با این حال، یک محدودیت برای معماری seq2seq وجود دارد. معماری seq2seq وانیلی که در این مقاله توضیح داده شده است قادر به گرفتن زمینه نیست. به سادگی یاد می گیرد که ورودی های مستقل را به خروجی های مستقل نگاشت کند. مکالمات بیدرنگ مبتنی است روی زمینه و گفتگوهای بین دو یا چند کاربر مبتنی است روی هر چه در گذشته گفته شد بنابراین، اگر میخواهید یک ربات چت نسبتاً پیشرفته ایجاد کنید، نباید از یک مدل seq2seq مبتنی بر رمزگشای رمزگذار ساده استفاده کنید.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-20 02:07:03
