از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
یادگیری انتقالی یک تکنیک قدرتمند برای آموزش شبکه های عصبی عمیق است که به فرد امکان می دهد دانش آموخته شده در مورد یک مسئله یادگیری عمیق را دریافت کرده و آن را برای یک مشکل یادگیری متفاوت و در عین حال مشابه به کار گیرد.
استفاده از یادگیری انتقال می تواند به طور چشمگیری سرعت استقرار برنامه ای را که در حال طراحی آن هستید افزایش دهد و آموزش و اجرای شبکه عصبی عمیق شما را ساده تر و آسان تر کند.
در این مقاله به تئوری یادگیری انتقالی می پردازیم و روش اجرای نمونه ای از یادگیری انتقالی را می بینیم روی شبکه های عصبی کانولوشن (CNN) در PyTorch.
PyTorch چیست؟
Pytorch یک کتابخانه توسعه یافته برای پایتون است که در یادگیری عمیق و پردازش زبان طبیعی تخصص دارد. PyTorch از قدرت واحدهای پردازش گرافیکی (GPU) برای پیاده سازی یک شبکه عصبی عمیق سریعتر از آموزش شبکه استفاده می کند. روی یک CPU
PyTorch به لطف سرعت و انعطاف پذیری خود، محبوبیت فزاینده ای در بین محققان یادگیری عمیق داشته است. PyTorch خود را می فروشد روی سه ویژگی مختلف:
- یک رابط کاربری ساده و آسان برای استفاده
- ادغام کامل با پشته علم داده پایتون
- نمودارهای محاسباتی منعطف / پویا که می توانند در طول زمان اجرا تغییر کنند (که آموزش شبکه عصبی را به طور قابل توجهی آسان تر می کند، زمانی که شما نمی دانید چقدر حافظه برای مشکل شما مورد نیاز است).
PyTorch با NumPy سازگار است و به آرایه های NumPy اجازه می دهد تا به تانسور تبدیل شوند و بالعکس.
تعریف اصطلاحات ضروری
قبل از اینکه جلوتر برویم، اجازه دهید چند لحظه به تعریف برخی از اصطلاحات مربوط به آموزش انتقالی بپردازیم. روشن شدن روی تعاریف ما درک نظریه پشت یادگیری انتقالی و اجرای نمونه ای از یادگیری انتقالی را برای درک و تکرار آسان تر می کند.
یادگیری عمیق چیست؟

یادگیری عمیق زیربخشی از یادگیری ماشین است و یادگیری ماشین را می توان به سادگی به عنوان عملی که رایانه ها را قادر می سازد وظایف را بدون برنامه ریزی صریح برای انجام این کار انجام دهند، توصیف کرد.
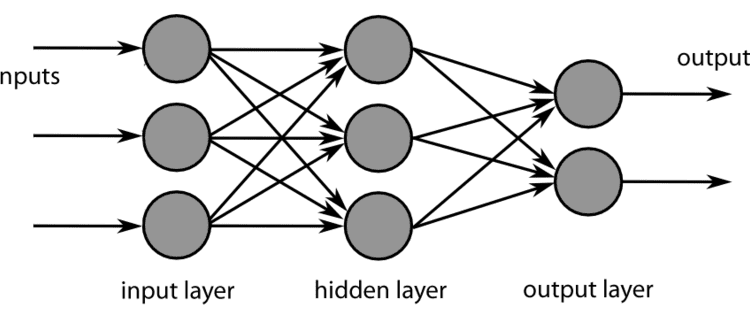
سیستمهای یادگیری عمیق از شبکههای عصبی استفاده میکنند که چارچوبهای محاسباتی از مغز انسان مدلسازی شدهاند.
شبکه های عصبی سه جزء مختلف دارند: An لایه ورودی، آ لایه پنهان یا لایه میانی و یک لایه خروجی.
را لایه ورودی به سادگی جایی است که داده هایی که به شبکه عصبی ارسال می شوند پردازش می شوند، در حالی که لایه های میانی / لایه های پنهان از ساختاری به نام a تشکیل شده اند node یا نورون
این گره ها توابع ریاضی هستند که اطلاعات ورودی را به نوعی تغییر می دهند و پاس می دهند روی داده های تغییر یافته به لایه نهایی، یا لایه خروجی. شبکههای عصبی ساده میتوانند الگوهای ساده را در دادههای ورودی با تنظیم مفروضات یا وزنها درباره روش ارتباط نقاط داده با یکدیگر تشخیص دهند.
آ شبکه عصبی عمیق نام خود را از این واقعیت گرفته است که از بسیاری از شبکه های عصبی منظم به هم پیوسته ساخته شده است. هر چه شبکههای عصبی بیشتر به هم مرتبط باشند، شبکه عصبی عمیقتر میتواند الگوهای پیچیدهتری را تشخیص دهد و بیشتر استفاده می کند این دارد. انواع مختلفی از شبکه های عصبی وجود دارد که هر یک از آنها تخصص خاص خود را دارد.
مثلا، حافظه کوتاه مدت بلند مدت شبکههای عصبی عمیق شبکههایی هستند که هنگام رسیدگی به وظایف حساس به زمان، که ترتیب زمانی دادهها مهم است، مانند دادههای متنی یا گفتاری، بسیار خوب کار میکنند.
شبکه عصبی کانولوشن چیست؟
این مقاله به این موضوع خواهد پرداخت شبکه های عصبی کانولوشنال، نوعی شبکه عصبی است که در دستکاری داده های تصویر برتری دارد.
شبکه های عصبی کانولوشنال (CNN) انواع خاصی از شبکه های عصبی هستند که در ایجاد نمایش داده های بصری مهارت دارند. داده های یک CNN است به عنوان یک شبکه نمایش داده می شود که حاوی مقادیری است که نشان می دهد هر پیکسل در تصویر چقدر روشن و چه رنگی است.
یک CNN به سه قسمت مختلف تقسیم می شود اجزاء: لایه های کانولوشن، لایه های ادغام، و لایه های کاملا متصل.

مسئولیت از لایه کانولوشن ایجاد نمایشی از تصویر با گرفتن حاصل ضرب نقطه ای دو ماتریس است.
ماتریس اول مجموعه ای از پارامترهای قابل یادگیری است که به آن هسته می گویند. ماتریس دیگر بخشی از تصویر مورد تجزیه و تحلیل است که دارای ارتفاع، عرض و کانال های رنگی است. لایه های کانولوشن جایی هستند که بیشترین محاسبات در CNN انجام می شود. هسته در تمام عرض و ارتفاع تصویر جابهجا میشود و در نهایت نمایشی از کل تصویر را تولید میکند که دو بعدی است، نمایشی که به عنوان نقشه فعالسازی شناخته میشود.
با توجه به حجم انبوه اطلاعات موجود در لایه های کانولوشن سی ان ان، آموزش شبکه می تواند زمان بسیار زیادی طول بکشد. عملکرد از لایه های ادغام این است که مقدار اطلاعات موجود در لایه های کانولوشن CNN را کاهش دهیم، خروجی را از یک لایه کانولوشن بگیریم و آن را کوچک کنیم تا نمایش ساده تر شود.
لایه ادغام این کار را با نگاه کردن به نقاط مختلف در خروجی های شبکه و “تجمع کردن” مقادیر نزدیک انجام می دهد و به یک مقدار واحد می رسد که همه مقادیر نزدیک را نشان می دهد. به عبارت دیگر، یک آمار خلاصه از مقادیر در یک منطقه انتخاب شده را می گیرد.
خلاصه کردن مقادیر در یک منطقه به این معنی است که شبکه می تواند اندازه و پیچیدگی نمایش خود را تا حد زیادی کاهش دهد در حالی که همچنان اطلاعات مربوطه را حفظ می کند که شبکه را قادر می سازد آن اطلاعات را تشخیص دهد و الگوهای معناداری را از تصویر ترسیم کند.
توابع مختلفی وجود دارد که می توان از آنها برای خلاصه کردن مقادیر یک منطقه استفاده کرد، مانند گرفتن میانگین یک محله – یا Average Pooling. همچنین می توان میانگین وزنی محله را نیز در نظر گرفت، همانطور که می توان هنجار L2 منطقه را نیز در نظر گرفت. رایج ترین تکنیک ادغام است حداکثر پولینگ، که در آن حداکثر مقدار منطقه گرفته شده و برای نشان دادن محله استفاده می شود.
را لایه کاملا متصل جایی است که تمام نورون ها با اتصالات بین هر لایه قبلی و بعدی در شبکه به هم مرتبط می شوند. اینجاست که اطلاعاتی که توسط لایههای کانولوشن استخراج شده و توسط لایههای ادغام شده است، تجزیه و تحلیل میشود و الگوهای موجود در دادهها یاد میگیرند. محاسبات در اینجا از طریق ضرب ماتریس همراه با یک اثر سوگیری انجام می شود.
چندین غیرخطی نیز در CNN وجود دارد. هنگامی که تصور می شود که تصاویر به خودی خود چیزهای غیر خطی هستند، شبکه باید دارای اجزای غیرخطی باشد تا بتواند داده های تصویر را تفسیر کند. لایههای غیرخطی معمولاً مستقیماً بعد از لایههای کانولوشن وارد شبکه میشوند، زیرا این به نقشه فعالسازی غیرخطی میدهد.
توابع فعالسازی غیرخطی مختلفی وجود دارد که میتوان از آنها برای قادر ساختن شبکه به تفسیر صحیح دادههای تصویر استفاده کرد. محبوب ترین تابع فعال سازی غیرخطی ReLu یا همان است واحد خطی اصلاح شده. تابع ReLu ورودی های غیرخطی را با فشرده کردن مقادیر واقعی به مقادیر مثبت بالای 0 به یک نمایش خطی تبدیل می کند. به عبارت دیگر، تابع ReLu هر مقداری را که بالای صفر است می گیرد و آن را به همان صورت برمی گرداند، در حالی که اگر مقدار زیر صفر باشد، این مقدار است. به صورت صفر برگردانده شد.
عملکرد ReLu به دلیل قابلیت اطمینان و سرعت آن محبوب است و تقریباً شش برابر سریعتر از سایر عملکردهای فعال سازی عمل می کند. نقطه ضعف ReLu این است که می تواند به راحتی در هنگام کار با گرادیان های بزرگ گیر کند و هرگز نورون ها را به روز نمی کند. این مشکل را می توان با تنظیم نرخ یادگیری برای تابع حل کرد.
دو تابع غیر خطی محبوب دیگر عبارتند از تابع سیگموئید و تابع تان.
تابع سیگموئید با گرفتن مقادیر واقعی و له کردن آنها به محدوده بین 0 و 1 کار می کند، اگرچه در مدیریت فعال سازی هایی که نزدیک به حداکثر گرادیان هستند، مشکل دارد، زیرا مقادیر تقریباً صفر می شوند.
در همین حال، تابع Tanh مشابه Sigmoid عمل می کند، با این تفاوت که خروجی آن نزدیک به صفر است و مقادیر را بین 1- و 1 کاهش می دهد.
آموزش و تست
دو فاز مختلف برای ایجاد و پیاده سازی یک شبکه عصبی عمیق وجود دارد: آموزش و تست.
مرحله آموزش جایی است که شبکه از داده ها تغذیه می کند و شروع به یادگیری الگوهای موجود در داده ها می کند، وزن شبکه را تنظیم می کند، که فرضیاتی در مورد چگونگی ارتباط نقاط داده با یکدیگر است. به بیان دیگر، مرحله آموزش جایی است که شبکه در مورد داده ها “یاد می گیرد” تغذیه شده است.
مرحله آزمایش جایی است که آنچه شبکه یاد گرفته است ارزیابی می شود. به شبکه مجموعه جدیدی از داده ها داده می شود، داده هایی که قبلاً ندیده است، و سپس از شبکه خواسته می شود تا حدس های خود را در مورد الگوهایی که آموخته است در داده های جدید اعمال کند. دقت مدل ارزیابی می شود و به طور معمول مدل بهینه سازی شده و دوباره آموزش داده می شود، سپس دوباره آزمایش می شود تا زمانی که معمار از عملکرد مدل راضی شود.
در مورد یادگیری انتقالی، شبکه ای که استفاده می شود از قبل آموزش داده شده است. وزنهای شبکه قبلاً تنظیم و ذخیره شدهاند، بنابراین دلیلی برای آموزش مجدد کل شبکه از ابتدا وجود ندارد. این بدان معناست که می توان بلافاصله از شبکه برای آزمایش استفاده کرد یا فقط لایه های خاصی از شبکه را می توان بهینه سازی کرد و سپس دوباره آموزش داد. این امر استقرار شبکه عصبی عمیق را تا حد زیادی سرعت می بخشد.
آموزش انتقالی چیست؟

ایده پشت یادگیری انتقالی در حال گرفتن یک مدل آموزش دیده است روی یک کار و اعمال برای کار دوم مشابه. این واقعیت که یک مدل قبلاً برخی یا همه وزنها را برای کار دوم آموزش دیده داشته است به این معنی است که مدل میتواند بسیار سریعتر پیادهسازی شود. این امکان ارزیابی عملکرد سریع و تنظیم مدل را فراهم می کند و به طور کلی امکان استقرار سریعتر را فراهم می کند. یادگیری انتقالی به لطف حجم گسترده منابع محاسباتی و زمان مورد نیاز برای آموزش مدل های یادگیری عمیق، علاوه بر مجموعه داده های بزرگ و پیچیده، به طور فزاینده ای در زمینه یادگیری عمیق محبوب می شود.
محدودیت اولیه یادگیری انتقالی این است که ویژگیهای مدلی که در اولین کار آموخته میشوند کلی هستند و مختص اولین کار نیستند. در عمل، این بدان معناست که مدلهایی که برای تشخیص انواع خاصی از تصاویر آموزش دیدهاند، میتوانند برای تشخیص تصاویر دیگر مورد استفاده مجدد قرار گیرند، تا زمانی که ویژگیهای کلی تصاویر مشابه باشند.
تئوری یادگیری انتقالی
استفاده از یادگیری انتقالی چندین مفهوم مهم دارد. برای درک اجرای آموزش انتقال، باید به این بپردازیم که یک مدل از پیش آموزش دیده چگونه به نظر می رسد و چگونه می توان آن مدل را برای نیازهای شما تنظیم کرد.
دو راه برای انتخاب مدل برای یادگیری انتقالی وجود دارد. این امکان وجود دارد که برای نیازهای خود یک مدل از ابتدا ایجاد کنید، پارامترها و ساختار مدل را ذخیره کنید و بعداً از مدل مجدد استفاده کنید.
راه دوم برای پیاده سازی یادگیری انتقال این است که به سادگی یک مدل از قبل موجود را بگیرید و دوباره از آن استفاده کنید و پارامترها و فراپارامترهای آن را در حین انجام این کار تنظیم کنید. در این مثال، ما از یک مدل از پیش آموزش دیده استفاده می کنیم و آن را اصلاح می کنیم. بعد از اینکه تصمیم گرفتید از چه رویکردی می خواهید استفاده کنید، یک مدل را انتخاب کنید (اگر از یک مدل از پیش آموزش دیده استفاده می کنید).
انواع زیادی از مدل های از پیش آموزش دیده وجود دارد که می توانند در PyTorch استفاده شوند. برخی از CNN های از پیش آموزش دیده عبارتند از:
- الکس نت
- CaffeResNet
- آغاز
- سری ResNet
- سری VGG
این مدل های از پیش آموزش دیده از طریق API PyTorch قابل دسترسی هستند و در صورت آموزش، PyTorch مشخصات آنها را در دستگاه شما دانلود می کند. مدل خاصی که قرار است از آن استفاده کنیم این است ResNet34، بخشی از مجموعه Resnet.
را Resnet مدل توسعه و آموزش داده شد روی یک ImageNet مجموعه داده و همچنین CIFAR-10 مجموعه داده به این ترتیب برای کارهای تشخیص بصری بهینه شده است و پیشرفت قابل توجهی نسبت به سری VGG نشان داده است، به همین دلیل است که از آن استفاده خواهیم کرد.
با این حال، مدل های از قبل آموزش دیده دیگری وجود دارد، و ممکن است بخواهید با آنها آزمایش کنید تا ببینید چگونه آنها مقایسه می شوند.
به عنوان مستندات PyTorch روی انتقال یادگیری را توضیح می دهد، دو روش عمده برای استفاده از یادگیری انتقال وجود دارد: تنظیم دقیق یک CNN یا استفاده از CNN به عنوان یک استخراج کننده ویژگی ثابت.
هنگام تنظیم دقیق یک CNN، از وزنه هایی که شبکه از قبل آموزش دیده است به جای مقداردهی اولیه تصادفی آنها استفاده می کنید و سپس مانند حالت عادی تمرین می کنید. در مقابل، یک رویکرد استخراج ویژگی به این معنی است که شما تمام وزنهای CNN را حفظ خواهید کرد، به جز مواردی که در چند لایه آخر هستند، که بهطور تصادفی مقداردهی اولیه میشوند و به طور معمول آموزش داده میشوند.
تنظیم دقیق یک مدل مهم است زیرا اگرچه مدل از قبل آموزش داده شده است، اما آموزش دیده است روی یک کار متفاوت (هر چند امیدوارم مشابه). وزنه های متصل متراکم که مدل از پیش آموزش دیده با آن ارائه می شود احتمالاً تا حدودی برای نیازهای شما ناکافی خواهد بود، بنابراین احتمالاً می خواهید چند لایه آخر شبکه را مجدداً آموزش دهید.
در مقابل، چون چند لایه اول شبکه فقط لایه های استخراج ویژگی هستند و عملکرد مشابهی خواهند داشت روی تصاویر مشابه، آنها را می توان همانطور که هستند رها کرد. بنابراین، اگر مجموعه داده کوچک و مشابه باشد، تنها آموزشی که باید انجام شود آموزش چند لایه نهایی است. هرچه مجموعه داده بزرگتر و پیچیده تر شود، مدل نیاز به آموزش مجدد بیشتری خواهد داشت. به یاد داشته باشید که یادگیری انتقال زمانی بهترین کار را انجام می دهد که مجموعه داده ای که استفاده می کنید کوچکتر از مدل اصلی از پیش آموزش دیده باشد و شبیه به تصاویر ارائه شده به مدل از پیش آموزش دیده باشد.
کار با مدل های یادگیری انتقال در Pytorch به معنای انتخاب لایه ها است یخ زدگی و به کدام منجمد کردن. فریز کردن یک مدل به این معنی است که به PyTorch بگویید پارامترها (وزن ها) را در لایه هایی که شما مشخص کرده اید حفظ کند. انجماد کردن یک مدل به این معنی است که به PyTorch بگویید میخواهید لایههایی که مشخص کردهاید برای آموزش در دسترس باشند و وزنهایشان قابل آموزش باشند.
پس از پایان آموزش لایه های انتخابی خود از مدل از پیش تمرین شده، احتمالاً می خواهید وزنه های تازه تمرین شده را برای استفاده در آینده ذخیره کنید. حتی اگر استفاده از مدلهای از پیش آموزشدیده سریعتر از و آموزش یک مدل از ابتدا باشد، هنوز هم زمان میبرد تا تمرین کنید، بنابراین میخواهید بهترین وزنههای مدل را کپی کنید.
طبقه بندی تصاویر با آموزش انتقال در PyTorch
ما آماده شروع پیاده سازی آموزش انتقال هستیم روی یک مجموعه داده ما هم تنظیم دقیق ConvNet و هم استفاده از شبکه را به عنوان یک استخراج کننده ویژگی ثابت پوشش خواهیم داد.
پیش پردازش داده ها
اول از همه، ما باید تصمیم بگیریم روی یک مجموعه داده برای استفاده بیایید چیزی را انتخاب کنیم که تصاویر بسیار واضحی برای آموزش داشته باشد روی. مجموعه داده گربهها و سگهای استنفورد یک مجموعه داده بسیار رایج است که به دلیل ساده و در عین حال گویا بودن مجموعه انتخاب شده است. می توانید این را دانلود کنید درست همین جا.
مطمئن شوید که مجموعه داده را به دو مجموعه با اندازه مساوی تقسیم کنید: “train” و “val”.
شما می توانید این کار را هر طور که دوست دارید انجام دهید، با جابجایی دستی فایل ها یا نوشتن یک تابع برای مدیریت آن. همچنین ممکن است بخواهید مجموعه داده را به اندازه کوچکتر محدود کنید، زیرا با تقریباً 12000 تصویر در هر دسته ارائه می شود و آموزش این کار زمان زیادی می برد. ممکن است بخواهید این عدد را به حدود 5000 در هر دسته کاهش دهید و 1000 عدد برای اعتبار سنجی کنار گذاشته شود. با این حال، تعداد تصاویری که می خواهید برای آموزش استفاده کنید به شما بستگی دارد.
در اینجا یک راه برای آماده سازی داده ها برای استفاده وجود دارد:
import os
import shutil
import re
base_dir = "PetImages/"
files = os.listdir(base_dir)
def train_maker(name):
train_dir = f"{base_dir}/train/{name}"
for f in files:
search_object = re.search(name, f)
if search_object:
shutil.move(f'{base_dir}/{name}', train_dir)
train_maker("Cat")
train_maker("Dog")
try:
os.makedirs("val/Cat")
os.makedirs("val/Dog")
except OSError:
print ("Creation of the directory %s failed")
else:
print ("Successfully created the directory %s ")
cat_train = base_dir + "train/Cat/"
cat_val = base_dir + "val/Cat/"
dog_train = base_dir + "train/Dog/"
dog_val = base_dir + "val/Dog/"
cat_files = os.listdir(cat_train)
dog_files = os.listdir(dog_train)
for f in cat_files:
validationCatsSearchObj = re.search("5\d\d\d", f)
if validationCatsSearchObj:
shutil.move(f'{cat_train}/{f}', cat_val)
for f in dog_files:
validationCatsSearchObj = re.search("5\d\d\d", f)
if validationCatsSearchObj:
shutil.move(f'{dog_train}/{f}', dog_val)
در حال بارگیری داده ها
پس از انتخاب و آماده سازی داده ها، می توانیم با وارد کردن تمام کتابخانه های لازم شروع به کار کنیم. ما به بسیاری از بسته های Torch نیاز خواهیم داشت nn شبکه عصبی، بهینه سازها و DataLoaders. ما نیز می خواهیم matplotlib برای تجسم برخی از نمونه های آموزشی ما.
نیاز داریم numpy برای مدیریت ایجاد آرایه های داده، و همچنین چند ماژول متفرقه دیگر:
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import numpy as np
import time
import os
import copy
برای شروع، باید داده های آموزشی خود را بارگذاری کنیم و آنها را برای استفاده توسط شبکه عصبی خود آماده کنیم. ما از Pytorch استفاده خواهیم کرد transforms برای این منظور. ما باید مطمئن شویم که تصاویر در مجموعه آموزشی و مجموعه اعتبار سنجی یک اندازه هستند، بنابراین از آن استفاده خواهیم کرد transforms.Resize.
ما همچنین کمی دادهها را تقویت میکنیم و سعی میکنیم عملکرد مدل خود را با وادار کردن آن به یادگیری در مورد تصاویر در زوایای مختلف و برشها بهبود دهیم، بنابراین بهطور تصادفی تصاویر را برش میدهیم و میچرخانیم.
در مرحله بعد، ما از تصاویر تانسور میسازیم، زیرا PyTorch با تانسورها کار میکند. در نهایت، تصاویر را عادی می کنیم، که به شبکه کمک می کند با مقادیری کار کند که ممکن است طیف گسترده ای از مقادیر مختلف داشته باشند.
سپس ما compose همه دگرگونی های انتخابی ما توجه داشته باشید که تبدیلهای اعتبارسنجی هیچ گونه چرخشی یا چرخشی ندارند، زیرا بخشی از مجموعه آموزشی ما نیستند، بنابراین شبکه در مورد آنها یاد نمیگیرد:
mean_nums = (0.485, 0.456, 0.406)
std_nums = (0.229, 0.224, 0.225)
chosen_transforms = {'train': transforms.Compose((
transforms.RandomResizedCrop(size=256),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
)), 'val': transforms.Compose((
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
)),
}
اکنون دایرکتوری را برای داده های خود تنظیم می کنیم و از PyTorch استفاده می کنیم ImageFolder عملکرد ایجاد مجموعه داده ها:
data_dir = '/data/'
chosen_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
chosen_transforms(x))
for x in ('train', 'val')}
اکنون که پوشه های تصویر مورد نظر خود را انتخاب کرده ایم، باید این کار را انجام دهیم از DataLoader ها استفاده کنید برای ایجاد اشیاء تکرارپذیر برای کار با ما. ما به آن می گوییم که از چه مجموعه داده هایی می خواهیم استفاده کنیم، به آن اندازه دسته ای می دهیم و داده ها را به هم می زنیم.
dataloaders = {x: torch.utils.data.DataLoader(chosen_datasets(x), batch_size=4,
shuffle=True, num_workers=4)
for x in ('train', 'val')}
ما باید برخی از اطلاعات را در مورد مجموعه داده خود حفظ کنیم، به ویژه اندازه مجموعه داده و نام کلاس های موجود در مجموعه داده ما. همچنین باید مشخص کنیم که با چه نوع دستگاهی کار می کنیم، CPU یا GPU. تنظیمات زیر در صورت وجود از GPU استفاده می کند، در غیر این صورت از CPU استفاده می شود:
dataset_sizes = {x: len(chosen_datasets(x)) for x in ('train', 'val')}
class_names = chosen_datasets('train').classes
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
حالا بیایید سعی کنیم برخی از تصاویر خود را با یک تابع تجسم کنیم. ما یک ورودی می گیریم، یک آرایه Numpy از آن ایجاد می کنیم و آن را جابه جا می کنیم. سپس ورودی را با استفاده از میانگین و انحراف استاندارد نرمال می کنیم. در نهایت، ما مقادیر را بین 0 و 1 برش میدهیم تا محدوده وسیعی در مقادیر ممکن آرایه وجود نداشته باشد، و سپس تصویر را نشان میدهیم:

def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array((mean_nums))
std = np.array((std_nums))
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
حالا بیایید از آن تابع استفاده کنیم و در واقع برخی از داده ها را تجسم کنیم. ورودی ها و نام کلاس ها را از آن دریافت می کنیم DataLoader و آنها را برای استفاده بعدی ذخیره کنید. سپس یک شبکه برای نمایش ورودی ها می سازیم روی و نمایش آنها:
inputs, classes = next(iter(dataloaders('train')))
out = torchvision.utils.make_grid(inputs)
imshow(out, title=(class_names(x) for x in classes))
راه اندازی یک مدل از پیش آموزش دیده
اکنون باید مدل از پیش آموزشدیدهای را که میخواهیم برای یادگیری انتقال استفاده کنیم، تنظیم کنیم. در این مورد، ما میخواهیم از مدل همانطور که هست استفاده کنیم و لایه نهایی کاملا متصل را بازنشانی کنیم و تعداد ویژگیها و کلاسهای خود را در اختیار آن قرار دهیم.
هنگام استفاده از مدلهای از پیش آموزشدیده، PyTorch مدل را بهطور پیشفرض تنظیم میکند تا unfrozen شود (وزنهای آن تنظیم میشود). بنابراین ما کل مدل را آموزش خواهیم داد:
res_mod = models.resnet34(pretrained=True)
num_ftrs = res_mod.fc.in_features
res_mod.fc = nn.Linear(num_ftrs, 2)
اگر این هنوز تا حدودی نامشخص به نظر می رسد، تجسم ترکیب مدل ممکن است کمک کند.
for name, child in res_mod.named_children():
print(name)
این چیزی است که برمی گرداند:
conv1
bn1
relu
maxpool
layer1
layer2
layer3
layer4
avgpool
fc
توجه داشته باشید که بخش پایانی است fc، یا “کاملاً متصل”. این تنها لایه ای است که ما شکل آن را تغییر می دهیم و دو کلاس خود را به خروجی می دهیم.
اساساً، ما خروجیهای بخش کاملاً متصل نهایی را فقط به دو کلاس تغییر میدهیم و وزنها را برای تمام لایههای دیگر تنظیم میکنیم.
اکنون باید مدل خود را به دستگاه آموزشی خود ارسال کنیم. همچنین باید معیار ضرر و بهینهسازی را که میخواهیم با مدل استفاده کنیم، انتخاب کنیم. CrossEntropyLoss و SGD بهینه سازها انتخاب های خوبی هستند، اگرچه بسیاری دیگر وجود دارد.
ما همچنین یک زمانبندی نرخ یادگیری را انتخاب میکنیم، که نرخ یادگیری اضافهکاری بهینهساز را کاهش میدهد و به جلوگیری از عدم همگرایی به دلیل نرخهای زیاد یادگیری کمک میکند. میتوانید درباره زمانبندیهای نرخ یادگیری بیشتر بدانید اینجا اگر کنجکاو هستید:
res_mod = res_mod.to(device)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(res_mod.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
اکنون فقط باید توابعی را تعریف کنیم که مدل را آموزش میدهند و پیشبینیها را تجسم میکنند.
بیایید با عملکرد آموزشی شروع کنیم. مدل انتخابی ما و همچنین بهینهساز، معیار و زمانبندی انتخابی ما را در بر میگیرد. ما همچنین تعداد پیشفرض دورههای آموزشی را مشخص میکنیم.
هر دوره یک مرحله آموزش و اعتبار خواهد داشت. برای شروع، با استفاده از آن، بهترین وزنه های اولیه مدل را روی وزن های حالت از پیش آموزش دیده قرار می دهیم state_dict.
حال، برای هر دوره در تعداد دوره های انتخاب شده، اگر در مرحله آموزش باشیم، خواهیم داشت:
- میزان یادگیری را کاهش دهید
- گرادیان ها را صفر کنید
- پاس آموزشی رو به جلو را انجام دهید
- ضرر را محاسبه کنید
- انتشار به عقب انجام دهید و وزن ها را با بهینه ساز به روز کنید
ما همچنین دقت مدل را در مرحله آموزش پیگیری خواهیم کرد و اگر به مرحله اعتبار سنجی برویم و دقت بهبود یافته باشد، وزنهای فعلی را به عنوان بهترین وزنهای مدل ذخیره میکنیم:
def train_model(model, criterion, optimizer, scheduler, num_epochs=10):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ('train', 'val'):
if phase == 'train':
scheduler.step()
model.train()
else:
model.eval()
current_loss = 0.0
current_corrects = 0
print('Iterating through data...')
for inputs, labels in dataloaders(phase):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
current_loss += loss.item() * inputs.size(0)
current_corrects += torch.sum(preds == labels.data)
epoch_loss = current_loss / dataset_sizes(phase)
epoch_acc = current_corrects.double() / dataset_sizes(phase)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_since = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_since // 60, time_since % 60))
print('Best val Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model
پرینت های آموزشی ما باید چیزی شبیه به این باشد:
Epoch 0/25
----------
Iterating through data...
train Loss: 0.5654 Acc: 0.7090
Iterating through data...
val Loss: 0.2726 Acc: 0.8889
Epoch 1/25
----------
Iterating through data...
train Loss: 0.5975 Acc: 0.7090
Iterating through data...
val Loss: 0.2793 Acc: 0.8889
Epoch 2/25
----------
Iterating through data...
train Loss: 0.5919 Acc: 0.7664
Iterating through data...
val Loss: 0.3992 Acc: 0.8627
تجسم
اکنون تابعی ایجاد می کنیم که به ما امکان می دهد پیش بینی هایی را که مدلمان انجام داده است ببینیم.
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_handeled = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders('val')):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()(0)):
images_handeled += 1
ax = plt.subplot(num_images//2, 2, images_handeled)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names(preds(j))))
imshow(inputs.cpu().data(j))
if images_handeled == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
حالا می توانیم همه چیز را به هم گره بزنیم. ما مدل را آموزش خواهیم داد روی تصاویر ما و نشان دادن پیش بینی ها:

base_model = train_model(res_mod, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=3)
visualize_model(base_model)
plt.show()
اگر از CPU و نه GPU استفاده می کنید، احتمالاً این آموزش زمان زیادی از شما خواهد گرفت. حتی اگر از GPU استفاده کنید، باز هم کمی طول می کشد.
به دلیل زمان طولانی آموزش است که بسیاری از افراد ترجیح می دهند به سادگی از مدل از پیش آموزش دیده به عنوان استخراج کننده ویژگی های ثابت استفاده کنند و فقط آخرین لایه یا بیشتر را آموزش دهند. این به طور قابل توجهی زمان تمرین را افزایش می دهد. برای انجام این کار، باید مدلی را که ما ساخته ایم جایگزین کنید. پیوندی به مخزن GitHub برای هر دو نسخه پیادهسازی ResNet وجود خواهد داشت.
بخشی را که در آن مدل از پیش آموزش دیده تعریف شده است، با نسخه ای جایگزین کنید که وزن ها را ثابت می کند و محاسبات گرادیان یا پشتیبان ما را انجام نمی دهد.
به نظر کاملاً شبیه قبل است، با این تفاوت که ما مشخص می کنیم که گرادیان ها نیازی به محاسبه ندارند:
res_mod = models.resnet34(pretrained=True)
for param in res_mod.parameters():
param.requires_grad = False
num_ftrs = res_mod.fc.in_features
res_mod.fc = nn.Linear(num_ftrs, 2)
res_mod = res_mod.to(device)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(res_mod.fc.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
اگر بخواهیم به طور انتخابی لایه ها را از حالت انجماد خارج کنیم و گرادیان ها را فقط برای چند لایه انتخاب شده محاسبه کنیم، چه می شود. آیا این امکان پذیر است؟ بله همینطور است.
اجازه دهید print دوباره بچه های مدل را بیرون بیاورید تا به خاطر بیاورید که چه لایه ها / مؤلفه هایی دارد:
for name, child in res_mod.named_children():
print(name)
این لایه هاست:
conv1
bn1
relu
maxpool
layer1
layer2
layer3
layer4
avgpool
fc
اکنون که میدانیم لایهها چیست، میتوانیم لایههایی را که میخواهیم از حالت انجماد خارج کنیم، مانند لایههای ۳ و ۴:
for name, child in res_mod.named_children():
if name in ('layer3', 'layer4'):
print(name + 'has been unfrozen.')
for param in child.parameters():
param.requires_grad = True
else:
for param in child.parameters():
param.requires_grad = False
البته، ما همچنین باید بهینه ساز را به روز کنیم تا این واقعیت را منعکس کنیم که ما فقط می خواهیم لایه های خاصی را بهینه کنیم.
optimizer_conv = torch.optim.SGD(filter(lambda x: x.requires_grad, res_mod.parameters()), lr=0.001, momentum=0.9)
بنابراین اکنون می دانید که می توانید کل شبکه را تنظیم کنید، فقط آخرین لایه، یا چیزی در بین.
نتیجه
تبریک میگوییم، شما اکنون آموزش انتقال را در PyTorch پیادهسازی کردهاید. بهتر است اجرای یک شبکه تنظیم شده را با استفاده از یک استخراج کننده ویژگی ثابت مقایسه کنید تا ببینید عملکرد چقدر متفاوت است. آزمایش انجماد و بازکردن لایههای خاص نیز تشویق میشود، زیرا به شما امکان میدهد درک بهتری از اینکه چگونه میتوانید مدل را مطابق با نیازهای خود سفارشی کنید، داشته باشید.
در اینجا موارد دیگری وجود دارد که می توانید امتحان کنید:
- استفاده از مدل های مختلف از قبل آموزش دیده برای دیدن اینکه کدام یک در شرایط مختلف عملکرد بهتری دارند
- تغییر برخی از استدلال های مدل، مانند تنظیم نرخ یادگیری و حرکت
- طبقه بندی را امتحان کنید روی مجموعه داده ای با بیش از دو کلاس
اگر کنجکاو هستید که درباره برنامه های مختلف یادگیری انتقال و تئوری پشت آن اطلاعات بیشتری کسب کنید، یک تفکیک عالی از برخی از ریاضیات پشت آن و همچنین موارد استفاده وجود دارد.
اینجا.
کد این مقاله را می توانید در اینجا پیدا کنید این مخزن GitHub.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-21 05:55:04
