از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
طبقه بندی کننده های تقویت کننده گرادیان گروهی از الگوریتم های یادگیری ماشین هستند که بسیاری از مدل های یادگیری ضعیف را با هم ترکیب می کنند تا یک مدل پیش بینی قوی ایجاد کنند. معمولاً هنگام انجام تقویت گرادیان از درختان تصمیم استفاده می شود. مدلهای تقویت گرادیان به دلیل اثربخشی آنها در طبقهبندی مجموعه دادههای پیچیده محبوب شدهاند و اخیراً برای به دست آوردن بسیاری از دادهها استفاده شدهاند. کاگل مسابقات علم داده
کتابخانه یادگیری ماشین پایتون، Scikit-Learn، از پیاده سازی های مختلف طبقه بندی کننده های تقویت کننده گرادیان، از جمله XGBoost.
در این مقاله به تئوری مدلها/ طبقهبندیکنندههای تقویت گرادیان میپردازیم و به دو روش مختلف برای انجام طبقهبندی با طبقهبندیکنندههای تقویت گرادیان در Scikit-Learn نگاه میکنیم.
تعریف اصطلاحات
بیایید با تعریف برخی اصطلاحات در رابطه با کلاسبندیکنندههای یادگیری ماشین و تقویت گرادیان شروع کنیم.
برای شروع، طبقه بندی چیست؟ در یادگیری ماشینی دو نوع وجود دارد یادگیری تحت نظارت چالش ها و مسائل: طبقه بندی و پسرفت.
طبقه بندی به وظیفه دادن ویژگیهای الگوریتم یادگیری ماشین و قرار دادن نمونهها/نقاط داده در یکی از بسیاری از الگوریتمها اشاره دارد. گسسته کلاس ها. کلاسها ماهیت طبقهبندی دارند، نمیتوان یک نمونه را تا حدی به عنوان یک کلاس و تا حدی کلاس دیگر طبقهبندی کرد. یک مثال کلاسیک از کار طبقهبندی، طبقهبندی ایمیلها بهعنوان «هرزنامه» یا «غیر هرزنامه» است – هیچ ایمیل «کمی هرزنامه» وجود ندارد.
رگرسیون ها زمانی انجام می شود که خروجی مدل یادگیری ماشین یک مقدار واقعی یا یک مقدار پیوسته باشد. چنین مثالی از این مقادیر پیوسته «وزن» یا «طول» خواهد بود. نمونه ای از یک کار رگرسیون پیش بینی سن یک فرد بر اساس ویژگی هایی مانند قد، وزن، درآمد و غیره است.
طبقه بندی کننده های تقویت کننده گرادیان انواع خاصی از الگوریتم ها هستند که همانطور که از نام آن پیداست برای کارهای طبقه بندی استفاده می شوند.
امکانات ورودی هایی هستند که به الگوریتم یادگیری ماشین داده می شوند، ورودی هایی که برای محاسبه یک مقدار خروجی استفاده می شوند. در مفهوم ریاضی، ویژگی های مجموعه داده متغیرهایی هستند که برای حل معادله استفاده می شوند. قسمت دیگر معادله است برچسب یا target، که کلاس هایی هستند که نمونه ها در آنها طبقه بندی می شوند. از آنجا که برچسب ها حاوی مقادیر هدف برای طبقه بندی کننده یادگیری ماشین هستند، هنگام آموزش یک طبقه بندی کننده باید داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنید. مجموعه آموزشی دارای اهداف/برچسبها خواهد بود، در حالی که مجموعه آزمایشی حاوی این مقادیر نخواهد بود.
Scikit-Learn یا “sklearn” یک کتابخانه یادگیری ماشینی است که برای Python ایجاد شده است و هدف آن تسریع در انجام وظایف یادگیری ماشین با تسهیل اجرای الگوریتم های یادگیری ماشین است. دارای عملکردهای آسان برای کمک به تقسیم داده ها به مجموعه های آموزشی و آزمایشی و همچنین آموزش یک مدل، پیش بینی و ارزیابی مدل است.
چگونه افزایش گرادیان به وجود آمد
ایده پشت “تقویت گرادیان” این است که یک فرضیه ضعیف یا الگوریتم یادگیری ضعیف را در نظر بگیرید و یک سری تغییرات در آن ایجاد کنید که قدرت فرضیه / یادگیرنده را بهبود بخشد. این نوع تقویت فرضیه مبتنی است روی ایده از احتمال یادگیری تقریباً صحیح (PAC).
این روش یادگیری PAC مشکلات یادگیری ماشین را بررسی میکند تا پیچیدگی آنها را تفسیر کند و روش مشابهی برای آن اعمال میشود تقویت فرضیه.
در تقویت فرضیه، شما به تمام مشاهداتی که الگوریتم یادگیری ماشین آموزش داده شده است نگاه می کنید روی، و فقط مشاهداتی را که روش یادگیری ماشینی با موفقیت طبقه بندی کرده است، پشت سر می گذارید و مشاهدات دیگر را حذف می کنید. یک یادگیرنده ضعیف جدید ایجاد می شود و مورد آزمایش قرار می گیرد روی مجموعهای از دادههایی که طبقهبندی ضعیفی داشتند و سپس فقط نمونههایی که با موفقیت طبقهبندی شدند نگهداری میشوند.
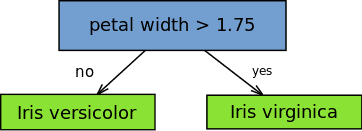
این ایده در تقویت تطبیقی (AdaBoost) الگوریتم برای AdaBoost، بسیاری از یادگیرندگان ضعیف با مقداردهی اولیه الگوریتم های درخت تصمیم ایجاد می شوند که فقط یک تقسیم دارند، مانند “استامپ” در تصویر زیر.

نمونه ها/مشاهدات در مجموعه آموزشی توسط الگوریتم وزن می شوند و وزن بیشتری به نمونه هایی که طبقه بندی آنها دشوار است اختصاص می یابد. زبان آموزان ضعیف بیشتری به ترتیب به سیستم اضافه می شوند و به سخت ترین نمونه های آموزشی اختصاص داده می شوند.
در AdaBoost، پیشبینیها از طریق اکثریت آرا انجام میشود، و نمونههایی طبقهبندی میشوند که طبق آن کلاس بیشترین رای را از زبانآموزان ضعیف دریافت میکند.

طبقهبندیکنندههای تقویت گرادیان، روش AdaBoosting هستند که با کمینهسازی وزنی ترکیب میشوند، پس از آن طبقهبندیکنندهها و ورودیهای وزندار دوباره محاسبه میشوند. هدف طبقهبندیکنندههای Gradient Boosting به حداقل رساندن ضرر یا تفاوت بین ارزش کلاس واقعی مثال آموزشی و مقدار کلاس پیشبینیشده است. نیازی به درک آن نیست process برای کاهش تلفات طبقه بندی کننده، اما به طور مشابه عمل می کند شیب نزول در یک شبکه عصبی
اصلاحات در این مورد process ساخته شدند و ماشین های افزایش گرادیان ایجاد شدند.
در مورد ماشینهای تقویت گرادیان، هر بار که یک یادگیرنده ضعیف جدید به مدل اضافه میشود، وزنهای یادگیرندههای قبلی منجمد میشوند یا در جای خود ثابت میشوند و با معرفی لایههای جدید بدون تغییر باقی میمانند. این متمایز از رویکردهای مورد استفاده در AdaBoosting است که در آن مقادیر با اضافه شدن یادگیرندگان جدید تنظیم می شوند.
قدرت ماشین های تقویت گرادیان از این واقعیت ناشی می شود که می توان از آنها استفاده کرد روی بیشتر از مسائل طبقه بندی باینری، می توان از آنها استفاده کرد روی مسائل طبقه بندی چند طبقه و حتی مشکلات رگرسیون.
نظریه پشت افزایش گرادیان
طبقه بندی تقویت کننده گرادیان بستگی دارد روی آ عملکرد از دست دادن. می توان از یک تابع ضرر سفارشی استفاده کرد و بسیاری از توابع ضرر استاندارد شده توسط طبقه بندی کننده های تقویت کننده گرادیان پشتیبانی می شوند، اما تابع ضرر باید قابل تمایز باشد.
الگوریتمهای طبقهبندی اغلب از تلفات لگاریتمی استفاده میکنند، در حالی که الگوریتمهای رگرسیون میتوانند از مربعات خطا استفاده کنند. سیستم های تقویت گرادیان لازم نیست هر بار که الگوریتم تقویت کننده اضافه می شود یک تابع ضرر جدید استخراج کنند، بلکه هر تابع تلفات قابل تمایز را می توان در سیستم اعمال کرد.
سیستم های افزایش گرادیان دو بخش ضروری دیگر دارند: یک یادگیرنده ضعیف و یک جزء افزایشی. سیستم های تقویت گرادیان از درخت های تصمیم به عنوان یادگیرندگان ضعیف خود استفاده می کنند. درختان رگرسیون برای یادگیرندگان ضعیف استفاده می شوند و این درختان رگرسیون مقادیر واقعی را تولید می کنند. از آنجایی که خروجی ها مقادیر واقعی هستند، با اضافه شدن یادگیرندگان جدید به مدل، خروجی درختان رگرسیون را می توان با هم جمع کرد تا خطاها در پیش بینی ها تصحیح شود.
مؤلفه افزایشی یک مدل تقویت گرادیان از این واقعیت ناشی می شود که درختان در طول زمان به مدل اضافه می شوند و وقتی این اتفاق می افتد درختان موجود دستکاری نمی شوند، مقادیر آنها ثابت می ماند.
برای به حداقل رساندن خطا بین پارامترهای داده شده از روشی شبیه به گرادیان نزول استفاده می شود. این با در نظر گرفتن تلفات محاسبه شده و انجام نزول گرادیان برای کاهش آن تلفات انجام می شود. پس از آن، پارامترهای درخت برای کاهش تلفات باقی مانده اصلاح می شوند.
سپس خروجی درخت جدید به خروجی درخت های قبلی استفاده شده در مدل اضافه می شود. این process تکرار می شود تا زمانی که به تعداد مشخص شده قبلی درخت برسد، یا تلفات زیر یک آستانه مشخص کاهش یابد.
مراحل افزایش گرادیان

به منظور پیاده سازی یک طبقه بندی تقویت کننده گرادیان، ما باید چندین مرحله مختلف را انجام دهیم. ما نیاز خواهیم داشت:
- مدل را برازش کنید
- پارامترهای مدل و Hyperparameters را تنظیم کنید
- پیش بینی کنید
- نتایج را تفسیر کنید
تطبیق مدلها با Scikit-Learn نسبتاً آسان است، زیرا معمولاً فقط باید آن را فراخوانی کنیم fit() دستور بعد از تنظیم مدل
با این حال، تنظیم فراپارامترهای مدل نیاز به تصمیم گیری فعال دارد روی قسمت ما آرگومان/هایپرپارامترهای مختلفی وجود دارد که میتوانیم آن را تنظیم کنیم تا بهترین دقت را برای مدل بدست آوریم. یکی از راه هایی که می توانیم این کار را انجام دهیم، تغییر نرخ یادگیری مدل است. ما می خواهیم عملکرد مدل را بررسی کنیم روی آموزش با نرخ های مختلف یادگیری تنظیم شده و سپس از بهترین نرخ یادگیری برای پیش بینی استفاده کنید.
پیش بینی ها را می توان در Scikit-Learn بسیار ساده با استفاده از predict() عملکرد پس از برازش طبقه بندی کننده. شما می خواهید پیش بینی کنید روی ویژگی های مجموعه داده آزمایشی، و سپس پیش بینی ها را با برچسب های واقعی مقایسه کنید. این process ارزیابی یک طبقهبندیکننده معمولاً شامل بررسی دقت طبقهبندیکننده و سپس تغییر پارامترها/هیپرپارامترهای مدل است تا زمانی که طبقهبندیکننده دقتی داشته باشد که کاربر از آن راضی است.
طبقه بندی کننده های مختلف بهبود یافته تقویت کننده گرادیان
به دلیل این واقعیت که الگوریتم های تقویت درجه بندی به راحتی می توانند بیش از حد برازش شوند روی مجموعه داده های آموزشی، محدودیت های مختلف یا روش های منظم سازی می تواند برای بهبود عملکرد الگوریتم و مبارزه با بیش از حد مناسب استفاده شود. یادگیری جریمهشده، محدودیتهای درختی، نمونهبرداری تصادفی و انقباض را میتوان برای مبارزه با بیش از حد مناسب استفاده کرد.
یادگیری جریمه شده
بسته به این که می توان از محدودیت های خاصی برای جلوگیری از برازش بیش از حد استفاده کرد روی ساختار درخت تصمیم نوع درخت تصمیم مورد استفاده در تقویت گرادیان، درخت رگرسیون است که دارای مقادیر عددی به صورت برگ یا وزن است. این مقادیر وزن را میتوان با استفاده از روشهای منظمسازی مختلف، مانند وزنهای تنظیم L1 یا L2، که الگوریتم تقویت تابشی را جریمه میکند، تنظیم کرد.
محدودیت های درختی
درخت تصمیم را می توان به روش های متعددی محدود کرد، مانند محدود کردن عمق درخت، اعمال محدودیت روی تعداد برگ ها یا گره های درخت، محدود کردن تعداد مشاهدات در هر تقسیم، و محدود کردن تعداد مشاهدات آموزش دیده روی. به طور کلی، هر چه محدودیتهای بیشتری در هنگام ایجاد درختها استفاده کنید، مدل به درختهای بیشتری نیاز دارد تا به درستی دادهها را تطبیق دهد.
نمونه گیری تصادفی/تقویت تصادفی
گرفتن نمونههای فرعی تصادفی از مجموعه دادههای آموزشی، تکنیکی که به عنوان تقویت گرادیان تصادفی شناخته میشود، میتواند به جلوگیری از برازش بیش از حد کمک کند. این تکنیک اساساً قدرت همبستگی بین درختان را کاهش می دهد.
روشهای متعددی برای نمونهبرداری از مجموعه دادهها وجود دارد، مانند نمونهبرداری از ستونها قبل از هر تقسیم، نمونهبرداری از ستونها قبل از ایجاد درخت، به عنوان نمونهبرداری از ردیفها قبل از ایجاد درخت. به طور کلی، به نظر می رسد نمونه گیری فرعی با نرخ های زیاد که از 50 درصد داده ها تجاوز نمی کند برای مدل مفید باشد.
انقباض / به روز رسانی وزن
از آنجایی که پیشبینیهای هر درخت با هم جمع میشوند، مشارکت درختان را میتوان با استفاده از تکنیکی به نام انقباض مهار یا کاهش داد. یک “نرخ یادگیری” تنظیم می شود و زمانی که میزان یادگیری کاهش می یابد درختان بیشتری باید به مدل اضافه شوند. این باعث می شود که مدل به زمان بیشتری برای آموزش نیاز داشته باشد.
بین نرخ یادگیری و تعداد درختان مورد نیاز یک مبادله وجود دارد، بنابراین باید برای یافتن بهترین مقادیر برای هر یک از پارامترها آزمایش کنید، اما مقادیر کوچک کمتر از 0.1 یا مقادیر بین 0.1 و 0.3 اغلب به خوبی کار می کنند.
XGBoost
XGBoost یک نسخه تصفیه شده و سفارشی شده از سیستم درخت تصمیم تقویت کننده گرادیان است که با در نظر گرفتن عملکرد و سرعت ایجاد شده است. XGBoost در واقع مخفف “افزایش گرادیان فوق العاده“، و اشاره به این واقعیت دارد که الگوریتمها و روشها سفارشی شدهاند تا حد امکان برای الگوریتمهای تقویت گرادیان را افزایش دهند.
ما یک طبقهبندیکننده تقویتکننده معمولی و یک طبقهبندیکننده XGBoost را در بخش زیر مقایسه میکنیم.
پیاده سازی یک طبقه بندی تقویت کننده گرادیان
اکنون به پیاده سازی یک طبقه بندی کننده ساده تقویت کننده گرادیان و یک طبقه بندی کننده XGBoost می پردازیم. ما با طبقه بندی کننده ساده تقویت کننده شروع می کنیم.
طبقه بندی تقویت کننده منظم
برای شروع، باید یک مجموعه داده را برای کار انتخاب کنیم onو برای این مثال از مجموعه داده تایتانیک استفاده خواهیم کرد. می توانید داده ها را دانلود کنید اینجا.
بیایید با وارد کردن همه کتابخانههایمان شروع کنیم:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.ensemble import GradientBoostingClassifier
حالا بیایید داده های آموزشی خود را بارگذاری کنیم:
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
ممکن است نیاز به انجام پیش پردازش داده ها داشته باشیم. بیایید شاخص را به عنوان تنظیم کنیم PassengerId و سپس ویژگی ها و برچسب های ما را انتخاب کنید. دادههای برچسب ما، y داده است Survived ستون بنابراین ما آن را دیتافریم خود می کنیم و سپس آن را از ویژگی ها حذف می کنیم:
y_train = train_data("Survived")
train_data.drop(labels="Survived", axis=1, inplace=True)
اکنون باید یک مجموعه داده جدید الحاقی ایجاد کنیم:
full_data = train_data.append(test_data)
بیایید ستونهایی را که برای آموزش ضروری یا مفید نیستند، رها کنیم، اگرچه میتوانید آنها را رها کنید و ببینید چگونه روی چیزها تأثیر میگذارند:
drop_columns = ("Name", "Age", "SibSp", "Ticket", "Cabin", "Parch", "Embarked")
full_data.drop(labels=drop_columns, axis=1, inplace=True)
هر داده متنی باید به اعدادی تبدیل شود که مدل ما بتواند از آن استفاده کند، بنابراین بیایید اکنون آن را تغییر دهیم. همچنین هر سلول خالی را با 0 پر می کنیم:
full_data = pd.get_dummies(full_data, columns=("Sex"))
full_data.fillna(value=0.0, inplace=True)
بیایید داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنیم:
X_train = full_data.values(0:891)
X_test = full_data.values(891:)
اکنون دادههای خود را با ایجاد یک نمونه از مقیاسکننده و مقیاسگذاری آن، مقیاسبندی میکنیم:
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
اکنون می توانیم داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنیم. بیایید همچنین یک دانه تنظیم کنیم (تا بتوانید نتایج را تکرار کنید) و درصد داده ها را برای آزمایش انتخاب کنید روی:
state = 12
test_size = 0.30
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train,
test_size=test_size, random_state=state)
اکنون میتوانیم نرخهای یادگیری متفاوتی را تنظیم کنیم تا بتوانیم عملکرد طبقهبندی کننده را در نرخهای مختلف یادگیری مقایسه کنیم.
lr_list = (0.05, 0.075, 0.1, 0.25, 0.5, 0.75, 1)
for learning_rate in lr_list:
gb_clf = GradientBoostingClassifier(n_estimators=20, learning_rate=learning_rate, max_features=2, max_depth=2, random_state=0)
gb_clf.fit(X_train, y_train)
print("Learning rate: ", learning_rate)
print("Accuracy score (training): {0:.3f}".format(gb_clf.score(X_train, y_train)))
print("Accuracy score (validation): {0:.3f}".format(gb_clf.score(X_val, y_val)))
بیایید ببینیم عملکرد برای نرخ های مختلف یادگیری چگونه بود:
Learning rate: 0.05
Accuracy score (training): 0.801
Accuracy score (validation): 0.731
Learning rate: 0.075
Accuracy score (training): 0.814
Accuracy score (validation): 0.731
Learning rate: 0.1
Accuracy score (training): 0.812
Accuracy score (validation): 0.724
Learning rate: 0.25
Accuracy score (training): 0.835
Accuracy score (validation): 0.750
Learning rate: 0.5
Accuracy score (training): 0.864
Accuracy score (validation): 0.772
Learning rate: 0.75
Accuracy score (training): 0.875
Accuracy score (validation): 0.754
Learning rate: 1
Accuracy score (training): 0.875
Accuracy score (validation): 0.739
ما عمدتاً به دقت طبقه بندی کننده علاقه مندیم روی مجموعه اعتبار سنجی، اما به نظر می رسد نرخ یادگیری 0.5 بهترین عملکرد را به ما می دهد روی مجموعه اعتبار سنجی و عملکرد خوب روی مجموعه آموزشی
اکنون میتوانیم طبقهبندیکننده را با بررسی صحت آن و ایجاد یک ماتریس سردرگمی ارزیابی کنیم. بیایید یک طبقهبندیکننده جدید ایجاد کنیم و بهترین نرخ یادگیری را که کشف کردهایم مشخص کنیم.
gb_clf2 = GradientBoostingClassifier(n_estimators=20, learning_rate=0.5, max_features=2, max_depth=2, random_state=0)
gb_clf2.fit(X_train, y_train)
predictions = gb_clf2.predict(X_val)
print("Confusion Matrix:")
print(confusion_matrix(y_val, predictions))
print("Classification Report")
print(classification_report(y_val, predictions))
در اینجا خروجی طبقه بندی کننده تنظیم شده ما آمده است:
Confusion Matrix:
((142 19)
( 42 65))
Classification Report
precision recall f1-score support
0 0.77 0.88 0.82 161
1 0.77 0.61 0.68 107
accuracy 0.77 268
macro avg 0.77 0.74 0.75 268
weighted avg 0.77 0.77 0.77 268
طبقه بندی XGBoost
اکنون ما با طبقهبندیکننده XGBoost آزمایش میکنیم.
مانند قبل، بیایید با وارد کردن کتابخانه های مورد نیاز خود شروع کنیم.
from xgboost import XGBClassifier
از آنجایی که داده های ما از قبل آماده شده است، فقط باید طبقه بندی کننده را با داده های آموزشی مطابقت دهیم:
xgb_clf = XGBClassifier()
xgb_clf.fit(X_train, y_train)
اکنون که طبقه بندی کننده مناسب و آموزش دیده است، می توانیم امتیاز کسب شده را بررسی کنیم روی تنظیم اعتبار با استفاده از score فرمان
score = xgb_clf.score(X_val, y_val)
print(score)
در اینجا خروجی است:
0.7761194029850746
از طرف دیگر، می توانید آن را پیش بینی کنید X_val داده ها را بررسی کنید و سپس صحت آن را بررسی کنید y_val با استفاده از accuracy_score. باید همین نوع نتیجه را به شما بدهد.
مقایسه دقت XGboost با دقت طبقهبندیگر گرادیان معمولی نشان میدهد که در این مورد، نتایج بسیار مشابه بودند. با این حال، همیشه اینطور نخواهد بود و در شرایط مختلف، یکی از طبقه بندی کننده ها به راحتی می تواند بهتر از دیگری عمل کند. سعی کنید آرگومان های این مدل را تغییر دهید تا ببینید نتیجه چگونه متفاوت است.
نتیجه
مدلهای تقویت گرادیان الگوریتمهای قدرتمندی هستند که میتوانند هم برای طبقهبندی و هم برای کارهای رگرسیون استفاده شوند. مدل های تقویت کننده گرادیان می توانند عملکرد فوق العاده خوبی داشته باشند روی مجموعه داده های بسیار پیچیده، اما آنها همچنین مستعد برازش بیش از حد هستند، که می توان با چندین روش توضیح داده شده در بالا مبارزه کرد. طبقهبندیکنندههای افزایش گرادیان نیز در Scikit-Learn به راحتی قابل پیادهسازی هستند.
اکنون که هم یک طبقهبندیکننده تقویتکننده معمولی و هم یک طبقهبندیکننده XGBoost را پیادهسازی کردهایم، سعی کنید هر دو را پیادهسازی کنید. روی همان مجموعه داده را مشاهده کنید و ببینید عملکرد دو طبقه بندی کننده چگونه با هم مقایسه می شود.
اگر میخواهید درباره تئوری تقویت گرادیان بیشتر بدانید، میتوانید درباره آن بیشتر بخوانید اینجا. همچنین ممکن است بخواهید درباره سایر طبقهبندیکنندههایی که Scikit-Learn پشتیبانی میکند بیشتر بدانید، بنابراین میتوانید عملکرد آنها را با هم مقایسه کنید. درباره طبقه بندی کننده های Scikit-Learn بیشتر بدانید اینجا.
اگر می خواهید با کد بازی کنید، تمام است روی GitHub!
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-21 13:13:03
