از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
معرفی
مدلهای مولد خانوادهای از معماریهای هوش مصنوعی هستند که هدفشان ایجاد نمونههای داده از ابتدا است. آنها با گرفتن توزیع دادههای نوع چیزهایی که میخواهیم تولید کنیم به این امر دست مییابند.
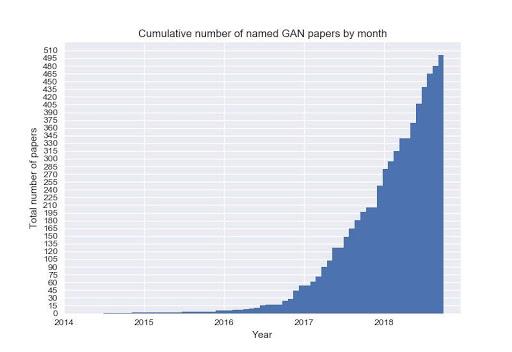
این نوع مدل ها به شدت در حال تحقیق هستند و حجم زیادی از تبلیغات در اطراف آنها وجود دارد. فقط به نموداری نگاه کنید که تعداد مقالات منتشر شده در این زمینه را در چند سال گذشته نشان می دهد:

از سال 2014، زمانی که اولین کاغذ روی شبکه های متخاصم مولد منتشر شد، مدلهای مولد بهطور باورنکردنی قدرتمند میشوند، و ما اکنون میتوانیم نمونههای دادههای فوق واقعی را برای طیف گستردهای از توزیعها تولید کنیم: تصاویر، ویدئوها، موسیقی، قطعات نوشته و غیره.
در اینجا چند نمونه از تصاویر تولید شده توسط a GAN:


مدل های مولد چیست؟
چارچوب GANs
موفق ترین چارچوب پیشنهادی برای مدل های مولد، حداقل در سال های اخیر، نام دارد شبکه های متخاصم مولد (GAN ها).
به بیان ساده، یک GAN از دو مدل مجزا تشکیل شده است که توسط شبکه های عصبی نشان داده می شود: یک ژنراتور. جی و یک تبعیض کننده D. هدف تمایزگر این است که بگوید آیا یک نمونه داده از یک توزیع داده واقعی می آید یا اینکه در عوض توسط جی.
هدف مولد تولید نمونههای دادهای است که متمایزکننده را فریب دهد.
مولد چیزی جز یک شبکه عصبی عمیق نیست. یک بردار نویز تصادفی (معمولاً گاوسی یا از توزیع یکنواخت) را به عنوان ورودی می گیرد و نمونه داده ای را از توزیعی که می خواهیم ضبط کنیم، خروجی می گیرد.
تمایز کننده، دوباره، فقط یک شبکه عصبی است. هدف آن همانطور که از نامش مشخص است به تبعیض قائل شدن بین نمونه های واقعی و تقلبی در نتیجه، ورودی آن یک نمونه داده است که یا از مولد یا از توزیع واقعی داده می آید.
خروجی یک عدد ساده است که نشان دهنده احتمال واقعی بودن ورودی است. احتمال زیاد به این معنی است که متمایز کننده مطمئن است که نمونه هایی که به او داده می شود واقعی هستند. برعکس، یک احتمال کم اطمینان بالایی را در این واقعیت نشان می دهد که نمونه از شبکه ژنراتور آمده است:

یک جاعل هنری را تصور کنید که سعی دارد آثار هنری جعلی خلق کند، و یک منتقد هنری که باید بین نقاشی های درست و تقلبی تمایز قائل شود.
در این سناریو، منتقد مانند تمایزکننده ما عمل میکند و جاعل عاملی است که از منتقد بازخورد میگیرد تا مهارتهایش را بهبود بخشد و هنر جعلی او را قانعکنندهتر نشان دهد:

آموزش
آموزش GAN می تواند یک چیز دردناک باشد. بی ثباتی تمرین همیشه یک موضوع بوده است و تحقیقات زیادی بر آن متمرکز بوده است روی ایجاد ثبات بیشتر در تمرین
تابع هدف اصلی یک مدل GAN وانیلی به شرح زیر است:

اینجا، D اشاره به شبکه تبعیض کننده دارد، در حالی که جی بدیهی است که به ژنراتور اشاره دارد.
همانطور که فرمول نشان می دهد، مولد برای گیج کردن حداکثری تمایزگر، با تلاش برای خروجی احتمالی بالا برای نمونه های داده جعلی، بهینه سازی می کند.
برعکس، تمایزکننده سعی میکند در تشخیص نمونههایی که از آنها میآیند بهتر شود جی از نمونه هایی که از توزیع واقعی به دست می آیند.
عبارت متخاصم دقیقاً از روش آموزش GANS ناشی می شود و این دو شبکه را در مقابل یکدیگر قرار می دهد.
وقتی مدل خود را آموزش دادیم، دیگر نیازی به تمایز نیست. تنها کاری که باید انجام دهیم این است که یک بردار نویز تصادفی را به ژنراتور تغذیه کنیم و امیدواریم در نتیجه یک نمونه داده مصنوعی واقعی و واقعی به دست آوریم.
مسائل GANs
بنابراین، چرا آموزش GAN ها اینقدر سخت است؟ همانطور که قبلا گفته شد، آموزش GAN ها به شکل وانیلی بسیار سخت است. ما به طور خلاصه به چرایی این موضوع خواهیم پرداخت.
تعادل نش سخت در دسترس
از آنجایی که این دو شبکه اطلاعات را به یکدیگر شلیک می کنند، می توان آن را به عنوان یک بازی به تصویر کشید که در آن حدس می زنیم که ورودی واقعی است یا نه.
چارچوب GAN یک بازی غیر محدب، دو نفره و غیرهمکاری با پارامترهای پیوسته و با ابعاد بالا است که در آن هر بازیکن می خواهد تابع هزینه خود را به حداقل برساند. بهینه این process نام را می گیرد تعادل نش – جایی که هر بازیکن با تغییر استراتژی عملکرد بهتری نخواهد داشت، با توجه به اینکه بازیکن دیگر استراتژی خود را تغییر نمی دهد.
با این حال، GAN ها معمولاً با استفاده از آموزش داده می شوند گرادیان-نزولی تکنیک هایی که برای یافتن مقدار کم a طراحی شده اند تابع هزینه و پیدا نکردن تعادل نش از یک بازی
سقوط حالت
اکثر توزیع های داده چند وجهی هستند. را بگیرید مجموعه داده MNIST: 10 “حالت” داده وجود دارد که به ارقام مختلف بین 0 و 9 اشاره دارد.
یک مدل مولد خوب میتواند نمونههایی با تنوع کافی تولید کند، بنابراین میتواند نمونههایی را از تمام کلاسهای مختلف تولید کند.
با این حال، همیشه این اتفاق نمی افتد.
بیایید بگوییم که ژنراتور در تولید رقم “3” واقعاً خوب می شود. اگر نمونه های تولید شده به اندازه کافی قانع کننده باشند، متمایز کننده احتمالاً احتمالات بالایی را به آنها اختصاص می دهد.
در نتیجه، ژنراتور به سمت تولید نمونههایی سوق داده میشود که از آن حالت خاص میآیند و در بیشتر مواقع کلاسهای دیگر را نادیده میگیرند. اساساً همان شماره را هرزنامه میفرستد و با هر عددی که از تشخیصدهنده عبور میکند، این رفتار فقط بیشتر اعمال میشود.

کاهش گرادیان
بسیار شبیه به مثال قبلی، تشخیص دهنده ممکن است در تشخیص نمونه های داده بسیار موفق باشد. وقتی این درست باشد، گرادیان ژنراتور ناپدید می شود، شروع به یادگیری کمتر و کمتر می کند، و نمی تواند همگرا شود.
اگر شبکه ها را جداگانه آموزش دهیم، این عدم تعادل مانند قبلی می تواند ایجاد شود. تکامل شبکههای عصبی میتواند کاملاً غیرقابل پیشبینی باشد، که میتواند منجر به جلوتر بودن یکی از دیگری به میزان یک مایل شود. اگر آنها را با هم آموزش دهیم، بیشتر تضمین می کنیم که این چیزها اتفاق نمی افتد.
مدرن
ارائه یک دید جامع از همه پیشرفتها و پیشرفتهایی که GANها را در سالهای گذشته قدرتمندتر و پایدارتر کردهاند غیرممکن است.
کاری که من در عوض انجام خواهم داد این است که فهرستی از موفق ترین معماری ها و تکنیک ها را گردآوری کنم و پیوندهایی به منابع مربوطه ارائه کنم تا عمیق تر شویم.
DCGAN ها
GAN های کانولوشنال عمیق (DCGAN ها) کانولوشن هایی را به شبکه های مولد و تفکیک کننده معرفی کردند.
با این حال، این موضوع صرفاً اضافه کردن لایههای کانولوشن به مدل نبود، زیرا آموزش حتی ناپایدارتر شد.
چندین ترفند برای مفید کردن DCGAN ها باید اعمال می شد:
- نرمال سازی دسته ای هم برای شبکه مولد و هم برای شبکه تفکیک کننده اعمال شد
- ترک تحصیل به عنوان یک تکنیک منظم سازی استفاده می شود
- ژنراتور به راهی برای نمونهبرداری از بردار ورودی تصادفی به یک تصویر خروجی نیاز داشت. در اینجا از جابجایی لایه های کانولوشنال استفاده می شود
- LeakyRelu و TanH فعال سازی در هر دو شبکه استفاده می شود

WGAN ها
Wasserstein GANs (WGANs) با هدف بهبود پایداری تمرین است. حجم زیادی از ریاضیات پشت این نوع مدل وجود دارد. توضیح قابل دسترس تری را می توان یافت اینجا.
ایده اصلی در اینجا پیشنهاد یک تابع هزینه جدید بود که در همه جا شیب نرمتری دارد.
تابع هزینه جدید از متریکی به نام استفاده می کند فاصله واسرشتاین، که در همه جا شیب صاف تری دارد.
در نتیجه، ممیز که اکنون نامیده می شود منتقد، مقادیر اطمینان را به دست می دهد که دیگر به عنوان یک احتمال تفسیر نمی شوند. مقادیر بالا به این معنی است که مدل مطمئن است که ورودی واقعی است.
دو پیشرفت قابل توجه برای WGAN عبارتند از:
- هیچ نشانه ای از فروپاشی حالت در آزمایش ها ندارد
- وقتی منتقد عملکرد خوبی داشته باشد، مولد هنوز می تواند یاد بگیرد
ساگان ها
GAN های خودتوجهی (SAGANs) یک مکانیسم توجه را به چارچوب GAN معرفی می کند.
مکانیسم های توجه اجازه می دهد تا از اطلاعات جهانی به صورت محلی استفاده کنید. این بدان معناست که ما میتوانیم از قسمتهای مختلف یک تصویر معنا را دریافت کنیم و از آن اطلاعات برای تولید نمونههای بهتر استفاده کنیم.
این از مشاهدات ناشی می شود که پیچش ها در گرفتن وابستگی های طولانی مدت در نمونه های ورودی بسیار بد هستند، زیرا پیچیدگی یک عملیات محلی است که میدان دریافت آن بستگی دارد. روی اندازه فضایی هسته
یعنی مثلاً خروجی امکان پذیر نیست روی موقعیت بالای سمت چپ یک تصویر برای داشتن هر ارتباطی با خروجی در پایین سمت راست.
یکی از راههای حل این مشکل، استفاده از هستههایی با اندازههای بزرگتر برای گرفتن اطلاعات بیشتر است. با این حال، این باعث می شود که مدل از نظر محاسباتی ناکارآمد باشد و آموزش آن بسیار کند باشد.
توجه به خود این مشکل را حل میکند و راهی کارآمد برای گرفتن اطلاعات جهانی و استفاده محلی از آن در صورت مفید بودن ارائه میکند.
BigGAN ها
BigGAN ها تا آنجا که به کیفیت نمونه های تولید شده مربوط می شود، در زمان نگارش، کم و بیش پیشرفته ترین در نظر گرفته می شوند.
کاری که محققان در اینجا انجام دادند این بود که همه چیزهایی را که تا آن مرحله کار کرده بود جمع آوری کردند و سپس آن را به طور انبوه افزایش دادند.
مدل پایه آنها در واقع یک SAGAN بود که به آن ترفندهایی برای بهبود پایداری اضافه کردند.
آنها ثابت کردند که GANها به طور چشمگیری از مقیاسبندی سود میبرند، حتی زمانی که هیچ بهبود عملکردی بیشتری در مدل ارائه نشده است، همانطور که در مقاله اصلی ذکر شد:
ما نشان دادهایم که شبکههای متخاصم مولد که برای مدلسازی تصاویر طبیعی دستههای مختلف آموزش دیدهاند، هم از نظر وفاداری و هم از نظر تنوع نمونههای تولید شده، از مقیاسبندی بسیار سود میبرند. در نتیجه، مدلهای ما سطح جدیدی از عملکرد را در بین مدلهای ImageNet GAN تنظیم میکنند و بهبود مییابند روی وضعیت هنر با اختلاف زیادی
یک GAN ساده در پایتون
پیاده سازی کد
با تمام آنچه گفته شد، بیایید جلو برویم و یک GAN ساده را پیاده سازی کنیم که ارقام 0-9 را تولید می کند، یک مثال بسیار کلاسیک:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
def sample_Z(m, n):
return np.random.uniform(-1., 1., size=(m, n))
def plot(samples):
fig = plt.figure(figsize=(4, 4))
gs = gridspec.GridSpec(4, 4)
gs.update(wspace=0.05, hspace=0.05)
for i, sample in enumerate(samples):
ax = plt.subplot(gs(i))
plt.axis('off')
ax.set_xticklabels(())
ax.set_yticklabels(())
ax.set_aspect('equal')
plt.imshow(sample.reshape(28, 28), cmap='Greys_r')
return fig
اکنون می توانیم مکان نگهدار را برای نمونه های ورودی و بردارهای نویز خود تعریف کنیم:
X = tf.placeholder(tf.float32, shape=(None, 784))
Z = tf.placeholder(tf.float32, shape=(None, 100))
اکنون، شبکه های مولد و متمایز کننده خود را تعریف می کنیم. آنها پرسپترون های ساده ای هستند که تنها یک لایه پنهان دارند.
ما استفاده می کنیم relu فعال سازی در نورون های لایه پنهان و سیگموئیدها برای لایه های خروجی
def generator(z):
with tf.variable_scope("generator", reuse=tf.AUTO_REUSE):
x = tf.layers.dense(z, 128, activation=tf.nn.relu)
x = tf.layers.dense(z, 784)
x = tf.nn.sigmoid(x)
return x
def discriminator(x):
with tf.variable_scope("discriminator", reuse=tf.AUTO_REUSE):
x = tf.layers.dense(x, 128, activation=tf.nn.relu)
x = tf.layers.dense(x, 1)
x = tf.nn.sigmoid(x)
return x
اکنون میتوانیم مدلها، توابع ضرر و بهینهسازهای خود را تعریف کنیم:
G_sample = generator(Z)
D_real = discriminator(X)
D_fake = discriminator(G_sample)
D_loss = -tf.reduce_mean(tf.log(D_real) + tf.log(1. - D_fake))
G_loss = -tf.reduce_mean(tf.log(D_fake))
disc_vars = (var for var in tf.trainable_variables() if var.name.startswith("disc"))
gen_vars = (var for var in tf.trainable_variables() if var.name.startswith("gen"))
D_solver = tf.train.AdamOptimizer().minimize(D_loss, var_list=disc_vars)
G_solver = tf.train.AdamOptimizer().minimize(G_loss, var_list=gen_vars)
در نهایت می توانیم روال تمرینی خود را بنویسیم. در هر تکرار، یک مرحله بهینه سازی را برای تشخیص دهنده و یک مرحله برای مولد انجام می دهیم.
هر 100 بار تکرار، تعدادی نمونه تولید شده را ذخیره می کنیم تا بتوانیم به پیشرفت خود نگاهی بیندازیم.
mb_size = 128
Z_dim = 100
mnist = input_data.read_data_sets('../../MNIST_data', one_hot=True)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
if not os.path.exists('out2/'):
os.makedirs('out2/')
i = 0
for it in range(1000000):
if it % 1000 == 0:
samples = sess.run(G_sample, feed_dict={Z: sample_Z(16, Z_dim)})
fig = plot(samples)
plt.savefig('out2/{}.png'.format(str(i).zfill(3)), bbox_inches='tight')
i += 1
plt.close(fig)
X_mb, _ = mnist.train.next_batch(mb_size)
_, D_loss_curr = sess.run((D_solver, D_loss), feed_dict={X: X_mb, Z: sample_Z(mb_size, Z_dim)})
_, G_loss_curr = sess.run((G_solver, G_loss), feed_dict={Z: sample_Z(mb_size, Z_dim)})
if it % 1000 == 0:
print('Iter: {}'.format(it))
print('D loss: {:.4}'. format(D_loss_curr))
نتایج و بهبودهای احتمالی
در طول اولین تکرار، تنها چیزی که می بینیم نویز تصادفی است:

اینجا شبکه ها هنوز چیزی یاد نگرفتند. اگرچه، تنها پس از چند دقیقه، ما می توانیم ببینیم که چگونه رقم های ما در حال شکل گیری است!

منابع
اگر می خواهید با کد بازی کنید، تمام است روی GitHub!
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-21 23:00:09
