از طریق منوی جستجو مطلب مورد نظر خود در وبلاگ را به سرعت پیدا کنید



سرفصلهای مطلب
این دوازدهمین مقاله از سری مقالات من است روی پایتون برای NLP. در مقاله قبلی به طور مختصر عملکردهای مختلف پایتون را توضیح دادم کتابخانه جنسیم. تاکنون، در این مجموعه، تقریباً تمام کتابخانه های پرکاربرد NLP مانند NLTK، SpaCy، Gensim، StanfordCoreNLP، Pattern، TextBlob و غیره را پوشش داده ایم.
در این مقاله قصد نداریم هیچ کتابخانه NLP را بررسی کنیم. در عوض، ما یک ربات چت بسیار ساده مبتنی بر قانون ایجاد خواهیم کرد که قادر به پاسخگویی به سوالات کاربران در مورد ورزش تنیس است. اما قبل از شروع کدنویسی واقعی، اجازه دهید ابتدا به طور خلاصه در مورد چیستی رباتهای چت و روش استفاده از آنها صحبت کنیم.
چت بات چیست؟
چت بات یک عامل مکالمه است که قادر به پاسخگویی به سوالات کاربر در قالب متن، گفتار یا از طریق یک رابط کاربری گرافیکی است. به زبان ساده، چت بات یک نرم افزار کاربردی است که می تواند با کاربر چت کند روی هر موضوعی. چت بات ها را می توان به طور کلی به دو نوع دسته بندی کرد: چت ربات های وظیفه گرا و چت بات های عمومی.
چت ربات های وظیفه گرا برای انجام وظایف خاص طراحی شده اند. به عنوان مثال، یک ربات گفتگوی وظیفه محور می تواند به سوالات مربوط به رزرو قطار، تحویل پیتزا پاسخ دهد. همچنین می تواند به عنوان یک درمانگر پزشکی شخصی یا دستیار شخصی کار کند.
از سوی دیگر، چت ربات های عمومی می توانند بحث های پایانی با کاربران داشته باشند.
نوع سومی از چتباتها به نام چتباتهای ترکیبی نیز وجود دارد که میتوانند هم در بحث وظیفهمحور و هم در بحثهای پایان باز با کاربران شرکت کنند.
رویکردهای توسعه چت بات
رویکردهای توسعه چت بات به دو دسته تقسیم می شوند: چت بات های مبتنی بر قانون و چت بات های مبتنی بر یادگیری.
چت ربات های مبتنی بر یادگیری
چت ربات های مبتنی بر یادگیری نوعی از چت ربات ها هستند که از تکنیک های یادگیری ماشینی و مجموعه داده ای برای یادگیری ایجاد پاسخ به پرسش های کاربر استفاده می کنند. چت ربات های مبتنی بر یادگیری را می توان به دو دسته تقسیم کرد: چت ربات های مبتنی بر بازیابی و چت ربات های تولیدی.
چت رباتهای مبتنی بر بازیابی یاد میگیرند که پاسخ خاصی را به پرسشهای کاربر انتخاب کنند. از سوی دیگر، چت رباتهای مولد یاد میگیرند که یک پاسخ تولید کنند روی پرواز.
یکی از مزیت های اصلی چت ربات های مبتنی بر یادگیری، انعطاف پذیری آنها برای پاسخگویی به سوالات مختلف کاربران است. اگرچه پاسخ ممکن است همیشه صحیح نباشد، چت ربات های مبتنی بر یادگیری قادر به پاسخگویی به هر نوع درخواست کاربر هستند. یکی از اشکالات عمده این چت بات ها این است که ممکن است برای آموزش به زمان و داده زیادی نیاز داشته باشند.
چت ربات های مبتنی بر قانون
چت ربات های مبتنی بر قانون در مقایسه با چت ربات های مبتنی بر یادگیری بسیار ساده هستند. یک سری قوانین خاص وجود دارد. اگر پرس و جو کاربر با هر قانون مطابقت داشته باشد، پاسخ پرسش ایجاد می شود، در غیر این صورت به کاربر اطلاع داده می شود که پاسخ به درخواست کاربر وجود ندارد.
یکی از مزایای چت ربات های مبتنی بر قانون این است که همیشه نتایج دقیقی ارائه می دهند. با این حال، روی جنبه منفی، آنها به خوبی مقیاس نمی شوند. برای افزودن پاسخ های بیشتر، باید قوانین جدیدی را تعریف کنید.
در بخش بعدی، روش ایجاد یک ربات چت مبتنی بر قانون را توضیح خواهم داد که به سوالات ساده کاربران در مورد ورزش تنیس پاسخ می دهد.
توسعه چت بات مبتنی بر قانون با پایتون
چت باتی که ما می خواهیم توسعه دهیم بسیار ساده خواهد بود. ابتدا به مجموعه ای نیاز داریم که حاوی اطلاعات زیادی در مورد ورزش تنیس باشد. ما با پاک کردن مقاله ویکیپدیا، چنین مجموعهای را توسعه خواهیم داد روی تنیس در مرحله بعد، مقداری پیش پردازش را انجام خواهیم داد روی بدنه و سپس پیکره را به جملات تقسیم می کند.
هنگامی که کاربر یک پرس و جو را وارد می کند، پرس و جو به شکل برداری تبدیل می شود. تمام جملات موجود در پیکره نیز به اشکال بردار متناظر خود تبدیل خواهند شد. بعد جمله با بالاترین شباهت کسینوس با بردار ورودی کاربر به عنوان پاسخی به ورودی کاربر انتخاب خواهد شد.
برای توسعه ربات چت این مراحل را دنبال کنید:
واردات کتابخانه های مورد نیاز
import nltk
import numpy as np
import random
import string
import bs4 as bs
import urllib.request
import re
ما استفاده خواهیم کرد سوپ زیبا4 کتابخانه برای تجزیه داده های ویکی پدیا. علاوه بر این، کتابخانه regex پایتون، re، برای برخی از کارهای پیش پردازش استفاده خواهد شد روی متن.
ایجاد Corpus
همانطور که قبلا گفتیم از مقاله ویکی پدیا استفاده خواهیم کرد روی تنیس برای ایجاد مجموعه ما. اسکریپت زیر مقاله ویکیپدیا را بازیابی میکند و تمام پاراگرافها را از متن مقاله استخراج میکند. در نهایت متن برای پردازش آسان تر به حروف کوچک تبدیل می شود.
raw_html = urllib.request.urlopen('https://en.wikipedia.org/wiki/Tennis')
raw_html = raw_html.read()
article_html = bs.BeautifulSoup(raw_html, 'lxml')
article_paragraphs = article_html.find_all('p')
article_text = ''
for para in article_paragraphs:
article_text += para.text
article_text = article_text.lower()
پیش پردازش متن و تابع کمکی
در مرحله بعد، باید متن خود را از قبل پردازش کنیم تا تمام کاراکترهای خاص و فضاهای خالی را از متن خود حذف کنیم. عبارت منظم زیر این کار را انجام می دهد:
article_text = re.sub(r'\((0-9)*\)', ' ', article_text)
article_text = re.sub(r'\s+', ' ', article_text)
ما باید متن خود را به جملات و کلمات تقسیم کنیم زیرا شباهت کسینوس ورودی کاربر در واقع با هر جمله مقایسه می شود. اسکریپت زیر را اجرا کنید:
article_sentences = nltk.sent_tokenize(article_text)
article_words = nltk.word_tokenize(article_text)
در نهایت، ما باید توابع کمکی ایجاد کنیم که علائم نگارشی را از متن ورودی کاربر حذف کرده و متن را نیز به صورت یکپارچه کند. Lemmatization به کاهش یک کلمه به آن اشاره دارد root فرم. به عنوان مثال، کلمه “خورد” را برمی گرداند بخور، کلمه “پرتاب” تبدیل به پرتاب می شود و کلمه “بدتر” به “بد” کاهش می یابد.
کد زیر را اجرا کنید:
wnlemmatizer = nltk.stem.WordNetLemmatizer()
def perform_lemmatization(tokens):
return (wnlemmatizer.lemmatize(token) for token in tokens)
punctuation_removal = dict((ord(punctuation), None) for punctuation in string.punctuation)
def get_processed_text(document):
return perform_lemmatization(nltk.word_tokenize(document.lower().translate(punctuation_removal)))
در اسکریپت بالا ما ابتدا نمونه سازی می کنیم WordNetLemmatizer از NTLK کتابخانه سپس یک تابع تعریف می کنیم perform_lemmatization، که فهرستی از کلمات را به عنوان ورودی دریافت می کند و فهرست کلمه ای متناظر از کلمات را به صورت کلمه ای می کند. این punctuation_removal لیست علائم نگارشی را از متن ارسال شده حذف می کند. در نهایت، get_processed_text متد یک جمله را به عنوان ورودی می گیرد، آن را نشانه گذاری می کند، آن را اصطلاحی می کند و سپس علائم نگارشی را از جمله حذف می کند.
پاسخ به سلام
از آنجایی که ما در حال توسعه یک ربات چت مبتنی بر قانون هستیم، باید انواع مختلف ورودی های کاربر را به روشی متفاوت مدیریت کنیم. به عنوان مثال، برای احوالپرسی، یک تابع اختصاصی تعریف خواهیم کرد. برای رسیدگی به احوالپرسی، دو لیست ایجاد می کنیم: greeting_inputs و greeting_outputs. هنگامی که کاربر یک تبریک وارد می کند، سعی می کنیم آن را در آن جستجو کنیم greetings_inputs در لیست، اگر خوشامدگویی پیدا شد، به طور تصادفی پاسخی را از بین انتخاب می کنیم greeting_outputs فهرست
به اسکریپت زیر نگاه کنید:
greeting_inputs = ("hey", "good morning", "good evening", "morning", "evening", "hi", "whatsup")
greeting_responses = ("hey", "hey hows you?", "*nods*", "hello, how you doing", "hello", "Welcome, I am good and you")
def generate_greeting_response(greeting):
for token in greeting.split():
if token.lower() in greeting_inputs:
return random.choice(greeting_responses)
اینجا generate_greeting_response() متد اساساً مسئول اعتبار پیام تبریک و ایجاد پاسخ مربوطه است.
پاسخگویی به سوالات کاربران
همانطور که قبلاً گفتیم، پاسخ بر اساس شباهت کسینوس شکل بردار جمله ورودی و جملات موجود در بدنه ها ایجاد می شود. اسکریپت زیر را وارد می کند TfidfVectorizer و cosine_similarity کارکرد:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
اکنون ما همه چیز را تنظیم کرده ایم که برای ایجاد پاسخ به سؤالات کاربر مربوط به تنیس نیاز داریم. ما روشی ایجاد خواهیم کرد که ورودی کاربر را می گیرد، شباهت کسینوس ورودی کاربر را پیدا می کند و آن را با جملات موجود در پیکره مقایسه می کند.
به اسکریپت زیر نگاه کنید:
def generate_response(user_input):
tennisrobo_response = ''
article_sentences.append(user_input)
word_vectorizer = TfidfVectorizer(tokenizer=get_processed_text, stop_words='english')
all_word_vectors = word_vectorizer.fit_transform(article_sentences)
similar_vector_values = cosine_similarity(all_word_vectors(-1), all_word_vectors)
similar_sentence_number = similar_vector_values.argsort()(0)(-2)
matched_vector = similar_vector_values.flatten()
matched_vector.sort()
vector_matched = matched_vector(-2)
if vector_matched == 0:
tennisrobo_response = tennisrobo_response + "I am sorry, I could not understand you"
return tennisrobo_response
else:
tennisrobo_response = tennisrobo_response + article_sentences(similar_sentence_number)
return tennisrobo_response
می توانید ببینید که generate_response() متد یک پارامتر را می پذیرد که ورودی کاربر است. در مرحله بعد یک رشته خالی تعریف می کنیم tennisrobo_response. سپس ورودی کاربر را به لیست جملات موجود اضافه می کنیم. پس از آن در سطرهای زیر:
word_vectorizer = TfidfVectorizer(tokenizer=get_processed_text, stop_words='english')
all_word_vectors = word_vectorizer.fit_transform(article_sentences)
را مقداردهی اولیه می کنیم tfidfvectorizer و سپس تمام جملات موجود در پیکره را به همراه جمله ورودی به شکل بردار متناظر خود تبدیل کنید.
در خط زیر:
similar_vector_values = cosine_similarity(all_word_vectors(-1), all_word_vectors)
ما استفاده می کنیم cosine_similarity تابع برای یافتن شباهت کسینوس بین آخرین مورد در all_word_vectors لیست (که در واقع کلمه برداری برای ورودی کاربر است زیرا در انتها اضافه شده است) و کلمه بردار برای تمام جملات موجود در مجموعه.
بعد، در خط زیر:
similar_sentence_number = similar_vector_values.argsort()(0)(-2)
ما لیستی را که حاوی شباهت های کسینوس بردارها است مرتب می کنیم، دومین مورد آخر لیست در واقع بالاترین کسینوس را (پس از مرتب سازی) با ورودی کاربر خواهد داشت. آخرین مورد، خود ورودی کاربر است، بنابراین ما آن را انتخاب نکردیم.
در نهایت، شباهت کسینوس بازیابی شده را صاف می کنیم و بررسی می کنیم که آیا شباهت برابر با صفر است یا خیر. اگر شباهت کسینوس بردار منطبق 0 باشد، به این معنی است که پرسش ما پاسخی ندارد. در آن صورت، ما به سادگی print که ما پرس و جو کاربر را درک نمی کنیم.
در غیر این صورت، اگر شباهت کسینوس برابر با صفر نباشد، به این معنی است که ما یک جمله مشابه ورودی را در پیکره خود پیدا کردیم. در آن صورت، ما فقط نمایه جمله منطبق را به لیست “article_sentences” خود که شامل مجموعه تمام جملات است ارسال می کنیم.
چت با چت بات
به عنوان آخرین مرحله، باید تابعی ایجاد کنیم که به ما امکان می دهد با چت باتی که به تازگی طراحی کرده ایم چت کنیم. برای انجام این کار، یک تابع کمکی دیگر می نویسیم که تا زمانی که کاربر «Bye» را تایپ کند، به اجرا ادامه خواهد داد.
به اسکریپت زیر نگاه کنید، کد بعد از آن توضیح داده شده است:
continue_dialogue = True
print("Hello, I am your friend TennisRobo. You can ask me any question regarding tennis:")
while(continue_dialogue == True):
human_text = input()
human_text = human_text.lower()
if human_text != 'bye':
if human_text == 'thanks' or human_text == 'thank you very much' or human_text == 'thank you':
continue_dialogue = False
print("TennisRobo: Most welcome")
else:
if generate_greeting_response(human_text) != None:
print("TennisRobo: " + generate_greeting_response(human_text))
else:
print("TennisRobo: ", end="")
print(generate_response(human_text))
article_sentences.remove(human_text)
else:
continue_dialogue = False
print("TennisRobo: Good bye and take care of yourself...")
در اسکریپت بالا، ابتدا پرچم را تنظیم کردیم continue_dialogue به درستی پس از آن، ما print یک پیام خوشامدگویی به کاربر که درخواست هرگونه ورودی را دارد. بعد، یک حلقه while را مقداردهی اولیه می کنیم که تا زمانی که به اجرا ادامه می دهد continue_dialogue پرچم درست است در داخل حلقه، ورودی کاربر دریافت می شود که سپس به حروف کوچک تبدیل می شود. ورودی کاربر در human_text متغیر. اگر کاربر کلمه “بای” را وارد کند، continue_dialogue روی false تنظیم شده و پیام خداحافظی برای کاربر چاپ می شود.
از طرف دیگر، اگر متن ورودی برابر با «بای» نباشد، بررسی می شود که آیا ورودی کلماتی مانند «متشکرم»، «متشکرم» و غیره دارد یا خیر. در صورت یافتن چنین کلماتی، یک پاسخ “بسیار خوش آمدید” ایجاد می شود. در غیر این صورت، اگر ورودی کاربر برابر نباشد None، generate_response روشی نامیده می شود که بر اساس پاسخ کاربر واکشی می کند روی شباهت کسینوس همانطور که در بخش آخر توضیح داده شد.
هنگامی که پاسخ تولید شد، ورودی کاربر از مجموعه جملات حذف می شود زیرا ما نمی خواهیم ورودی کاربر بخشی از مجموعه باشد. این process ادامه می یابد تا زمانی که کاربر «بای» را تایپ کند. می توانید ببینید که چرا این نوع ربات چت، چت ربات مبتنی بر قانون نامیده می شود. قوانین زیادی برای پیروی وجود دارد و اگر بخواهیم قابلیت های بیشتری را به چت بات اضافه کنیم، باید قوانین بیشتری اضافه کنیم.
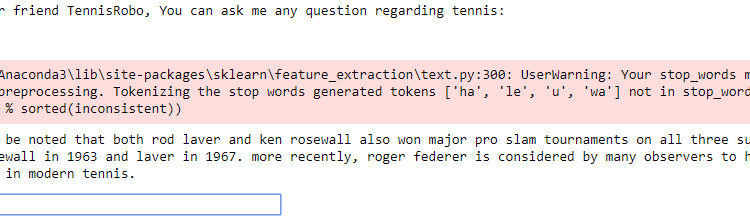
خروجی اسکریپت chatbot به شکل زیر است:

در تصویر بالا می بینید که من ورودی “roger federer” را وارد کردم و پاسخ ایجاد شده به این صورت است:
However, it must be noted that both rod laver and ken rosewall also won major pro slam tournaments روی all three surfaces (grass, clay, wood) rosewall in 1963 and laver in 1967. More recently, Roger Federer is considered by many observers to have the most "complete" game in modern tennis."
پاسخ ممکن است دقیق نباشد، با این حال، هنوز منطقی است.
ذکر این نکته ضروری است که ایده این مقاله توسعه یک چت بات بی نقص نیست، بلکه توضیح اصل کار چت بات های مبتنی بر قانون است.
نتیجه
چت بات ها عوامل مکالمه ای هستند که در انواع مختلف مکالمه با انسان ها شرکت می کنند. چت بات ها جایگاه خود را در لایه های مختلف زندگی از دستیار شخصی گرفته تا سیستم های رزرو بلیط و درمانگران فیزیولوژیکی پیدا می کنند. داشتن یک چت بات به جای انسان در واقع می تواند بسیار مقرون به صرفه باشد. با این حال، توسعه یک چت بات با کارایی مشابه انسان می تواند بسیار پیچیده باشد.
در این مقاله، روش ایجاد یک چت بات ساده مبتنی بر قانون با استفاده از شباهت کسینوس را نشان میدهیم. در مقاله بعدی، برخی دیگر از عرصه های پردازش زبان طبیعی را بررسی می کنیم.
(برچسبها به ترجمه)# python
منتشر شده در 1403-01-22 00:06:06
